 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1-Bit Wonder: Improving QAT Performance in the Low-Bit Regime through K-Means Quantization
Feb 17, 2026Quantization-aware training (QAT) is an effective method to drastically reduce the memory footprint of LLMs while keeping performance degradation at an acceptable level. However, the optimal choice of quantization format and bit-width presents a challenge in practice. The full design space of quantization is not fully explored in the context of QAT, and the precise trade-off between quantization and downstream performance is poorly understood, as comparisons often rely solely on perplexity-based evaluations. In this work, we address these shortcomings with an empirical study of QAT in the low-bit regime. We show that k-means based weight quantization outperforms integer formats and can be implemented efficiently on standard hardware. Furthermore, we find that, under a fixed inference memory budget, the best performance on generative downstream tasks is achieved with $1$-bit quantized weights.
Optimal Formats for Weight Quantisation
May 19, 2025Weight quantisation is an essential technique for enabling efficient training and deployment of modern deep learning models. However, the recipe book of quantisation formats is large and the formats are often chosen empirically. In this paper, we propose a framework for systematic design and analysis of quantisation formats. By connecting the question of format design with the classical quantisation theory, we show that the strong practical performance of popular formats comes from their ability to represent values using variable-length codes. Framing the optimisation problem as minimising the KL divergence between the original and quantised model outputs, the objective is aligned with minimising the squared quantisation error of the model parameters. We therefore develop and evaluate squared-error-optimal formats for known distributions, observing significant improvement of variable-length codes over fixed-length codes. Uniform quantisation followed by lossless compression with a variable-length code is shown to be optimal. However, we find that commonly used block formats and sparse outlier formats also outperform fixed-length codes, implying they also exploit variable-length encoding. Finally, by using the relationship between the Fisher information and KL divergence, we derive the optimal allocation of bit-widths to individual parameter tensors across the model's layers, saving up to 0.25 bits per parameter when tested with direct-cast quantisation of language models.
Approximate Top-$k$ for Increased Parallelism
Dec 05, 2024



We present an evaluation of bucketed approximate top-$k$ algorithms. Computing top-$k$ exactly suffers from limited parallelism, because the $k$ largest values must be aggregated along the vector, thus is not well suited to computation on highly-parallel machine learning accelerators. By relaxing the requirement that the top-$k$ is exact, bucketed algorithms can dramatically increase the parallelism available by independently computing many smaller top-$k$ operations. We explore the design choices of this class of algorithms using both theoretical analysis and empirical evaluation on downstream tasks. Our motivating examples are sparsity algorithms for language models, which often use top-$k$ to select the most important parameters or activations. We also release a fast bucketed top-$k$ implementation for PyTorch.
u-$μ$P: The Unit-Scaled Maximal Update Parametrization
Jul 24, 2024The Maximal Update Parametrization ($\mu$P) aims to make the optimal hyperparameters (HPs) of a model independent of its size, allowing them to be swept using a cheap proxy model rather than the full-size target model. We present a new scheme, u-$\mu$P, which improves upon $\mu$P by combining it with Unit Scaling, a method for designing models that makes them easy to train in low-precision. The two techniques have a natural affinity: $\mu$P ensures that the scale of activations is independent of model size, and Unit Scaling ensures that activations, weights and gradients begin training with a scale of one. This synthesis opens the door to a simpler scheme, whose default values are near-optimal. This in turn facilitates a more efficient sweeping strategy, with u-$\mu$P models reaching a lower loss than comparable $\mu$P models and working out-of-the-box in FP8.
SparQ Attention: Bandwidth-Efficient LLM Inference
Dec 08, 2023Generative large language models (LLMs) have opened up numerous novel possibilities, but due to their significant computational requirements their ubiquitous use remains challenging. Some of the most useful applications require processing large numbers of samples at a time and using long contexts, both significantly increasing the memory communication load of the models. We introduce SparQ Attention, a technique for increasing the inference throughput of LLMs by reducing the memory bandwidth requirements within the attention blocks through selective fetching of the cached history. Our proposed technique can be applied directly to off-the-shelf LLMs during inference, without requiring any modification to the pre-training setup or additional fine-tuning. We show how SparQ Attention can decrease the attention memory bandwidth requirements up to eight times without any loss in accuracy by evaluating Llama 2 and Pythia models on a wide range of downstream tasks.
PopSparse: Accelerated block sparse matrix multiplication on IPU
Apr 05, 2023



Reducing the computational cost of running large scale neural networks using sparsity has attracted great attention in the deep learning community. While much success has been achieved in reducing FLOP and parameter counts while maintaining acceptable task performance, achieving actual speed improvements has typically been much more difficult, particularly on general purpose accelerators (GPAs) such as NVIDIA GPUs using low precision number formats. In this work we introduce PopSparse, a library that enables fast sparse operations on Graphcore IPUs by leveraging both the unique hardware characteristics of IPUs as well as any block structure defined in the data. We target two different types of sparsity: static, where the sparsity pattern is fixed at compile-time; and dynamic, where it can change each time the model is run. We present benchmark results for matrix multiplication for both of these modes on IPU with a range of block sizes, matrix sizes and densities. Results indicate that the PopSparse implementations are faster than dense matrix multiplications on IPU at a range of sparsity levels with large matrix size and block size. Furthermore, static sparsity in general outperforms dynamic sparsity. While previous work on GPAs has shown speedups only for very high sparsity (typically 99\% and above), the present work demonstrates that our static sparse implementation outperforms equivalent dense calculations in FP16 at lower sparsity (around 90%). IPU code is available to view and run at ipu.dev/sparsity-benchmarks, GPU code will be made available shortly.
Unit Scaling: Out-of-the-Box Low-Precision Training
Mar 20, 2023We present unit scaling, a paradigm for designing deep learning models that simplifies the use of low-precision number formats. Training in FP16 or the recently proposed FP8 formats offers substantial efficiency gains, but can lack sufficient range for out-of-the-box training. Unit scaling addresses this by introducing a principled approach to model numerics: seeking unit variance of all weights, activations and gradients at initialisation. Unlike alternative methods, this approach neither requires multiple training runs to find a suitable scale nor has significant computational overhead. We demonstrate the efficacy of unit scaling across a range of models and optimisers. We further show that existing models can be adapted to be unit-scaled, training BERT-Large in FP16 and then FP8 with no degradation in accuracy.
BESS: Balanced Entity Sampling and Sharing for Large-Scale Knowledge Graph Completion
Nov 22, 2022



We present the award-winning submission to the WikiKG90Mv2 track of OGB-LSC@NeurIPS 2022. The task is link-prediction on the large-scale knowledge graph WikiKG90Mv2, consisting of 90M+ nodes and 600M+ edges. Our solution uses a diverse ensemble of $85$ Knowledge Graph Embedding models combining five different scoring functions (TransE, TransH, RotatE, DistMult, ComplEx) and two different loss functions (log-sigmoid, sampled softmax cross-entropy). Each individual model is trained in parallel on a Graphcore Bow Pod$_{16}$ using BESS (Balanced Entity Sampling and Sharing), a new distribution framework for KGE training and inference based on balanced collective communications between workers. Our final model achieves a validation MRR of 0.2922 and a test-challenge MRR of 0.2562, winning the first place in the competition. The code is publicly available at: https://github.com/graphcore/distributed-kge-poplar/tree/2022-ogb-submission.
Towards Structured Dynamic Sparse Pre-Training of BERT
Aug 13, 2021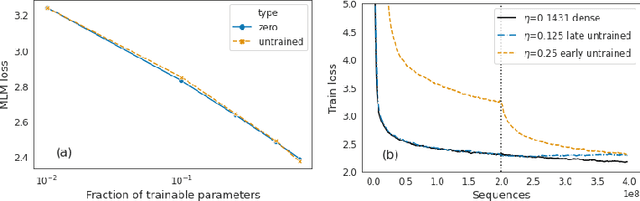
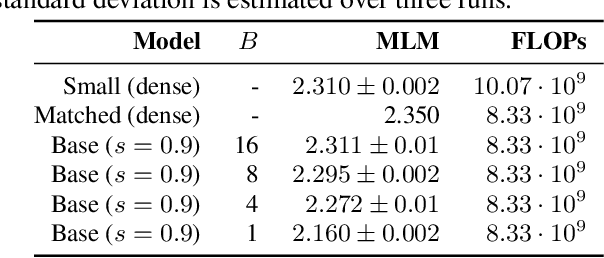
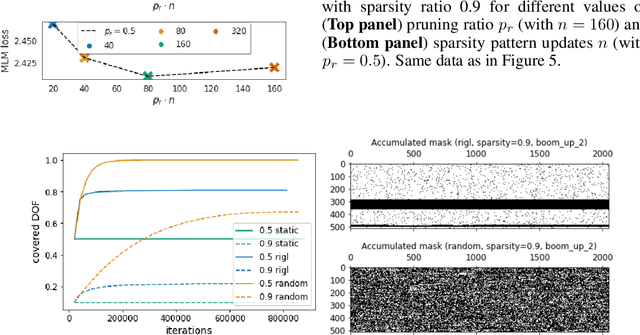
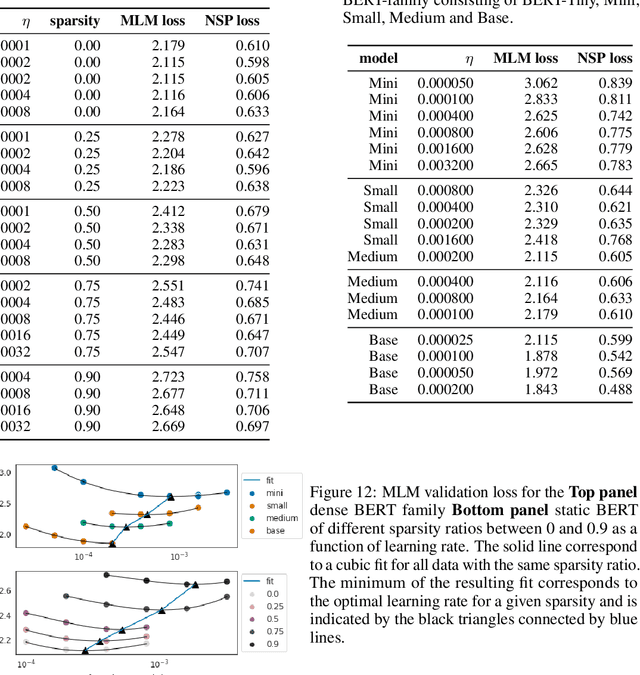
Identifying algorithms for computational efficient unsupervised training of large language models is an important and active area of research. In this work, we develop and study a straightforward, dynamic always-sparse pre-training approach for BERT language modeling task, which leverages periodic compression steps based on magnitude pruning followed by random parameter re-allocation. This approach enables us to achieve Pareto improvements in terms of the number of floating-point operations (FLOPs) over statically sparse and dense models across a broad spectrum of network sizes. Furthermore, we demonstrate that training remains FLOP-efficient when using coarse-grained block sparsity, making it particularly promising for efficient execution on modern hardware accelerators.
GroupBERT: Enhanced Transformer Architecture with Efficient Grouped Structures
Jun 10, 2021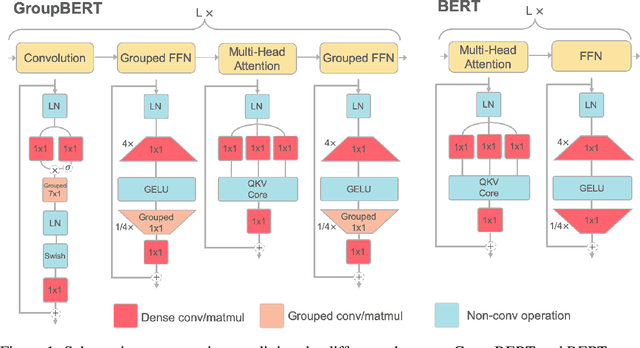
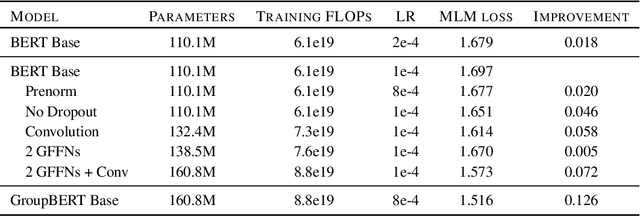

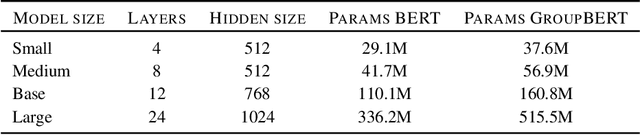
Attention based language models have become a critical component in state-of-the-art natural language processing systems. However, these models have significant computational requirements, due to long training times, dense operations and large parameter count. In this work we demonstrate a set of modifications to the structure of a Transformer layer, producing a more efficient architecture. First, we add a convolutional module to complement the self-attention module, decoupling the learning of local and global interactions. Secondly, we rely on grouped transformations to reduce the computational cost of dense feed-forward layers and convolutions, while preserving the expressivity of the model. We apply the resulting architecture to language representation learning and demonstrate its superior performance compared to BERT models of different scales. We further highlight its improved efficiency, both in terms of floating-point operations (FLOPs) and time-to-train.