 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modeling Time-Series and Spatial Data for Recommendations and Other Applications
Dec 25, 2022


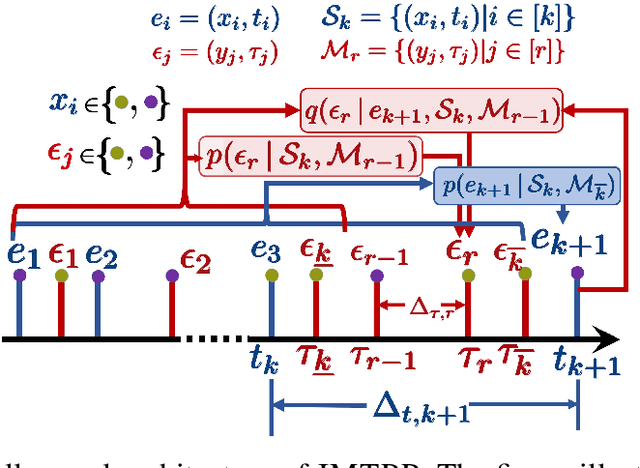

With the research directions described in this thesis, we seek to address the critical challenges in designing recommender systems that can understand the dynamics of continuous-time event sequences. We follow a ground-up approach, i.e., first, we address the problems that may arise due to the poor quality of CTES data being fed into a recommender system. Later, we handle the task of designing accurate recommender systems. To improve the quality of the CTES data, we address a fundamental problem of overcoming missing events in temporal sequences. Moreover, to provide accurate sequence modeling frameworks, we design solutions for points-of-interest recommendation, i.e., models that can handle spatial mobility data of users to various POI check-ins and recommend candidate locations for the next check-in. Lastly, we highlight that the capabilities of the proposed models can have applications beyond recommender systems, and we extend their abilities to design solutions for large-scale CTES retrieval and human activity prediction. A significant part of this thesis uses the idea of modeling the underlying distribution of CTES via neural marked temporal point processes (MTPP). Traditional MTPP models are stochastic processes that utilize a fixed formulation to capture the generative mechanism of a sequence of discrete events localized in continuous time. In contrast, neural MTPP combine the underlying ideas from the point process literature with modern deep learning architectures. The ability of deep-learning models as accurate function approximators has led to a significant gain in the predictive prowess of neural MTPP models. In this thesis, we utilize and present several neural network-based enhancements for the current MTPP frameworks for the aforementioned real-world applications.
Knowledge Distillation from 3D to Bird's-Eye-View for LiDAR Semantic Segmentation
Apr 22, 2023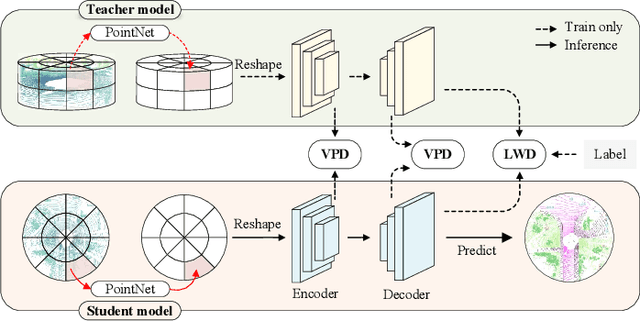
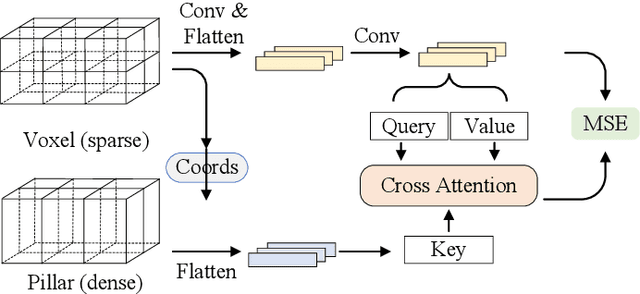
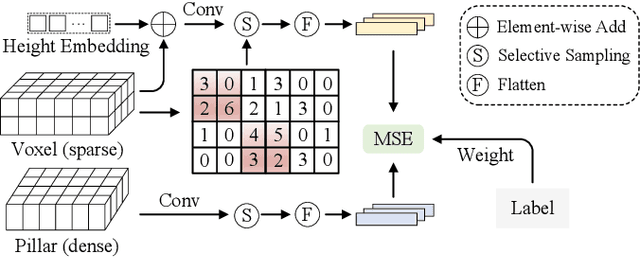
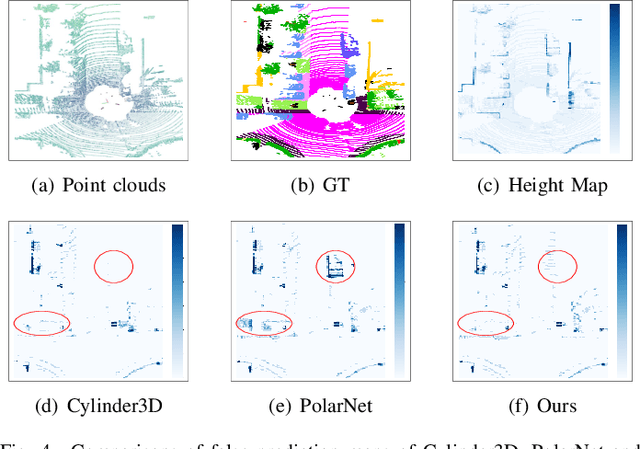
LiDAR point cloud segmentation is one of the most fundamental tasks for autonomous driving scene understanding. However, it is difficult for existing models to achieve both high inference speed and accuracy simultaneously. For example, voxel-based methods perform well in accuracy, while Bird's-Eye-View (BEV)-based methods can achieve real-time inference. To overcome this issue, we develop an effective 3D-to-BEV knowledge distillation method that transfers rich knowledge from 3D voxel-based models to BEV-based models. Our framework mainly consists of two modules: the voxel-to-pillar distillation module and the label-weight distillation module. Voxel-to-pillar distillation distills sparse 3D features to BEV features for middle layers to make the BEV-based model aware of more structural and geometric information. Label-weight distillation helps the model pay more attention to regions with more height information. Finally, we conduct experiments on the SemanticKITTI dataset and Paris-Lille-3D. The results on SemanticKITTI show more than 5% improvement on the test set, especially for classes such as motorcycle and person, with more than 15% improvement. The code can be accessed at https://github.com/fengjiang5/Knowledge-Distillation-from-Cylinder3D-to-PolarNet.
Fast Diffusion Probabilistic Model Sampling through the lens of Backward Error Analysis
Apr 22, 2023
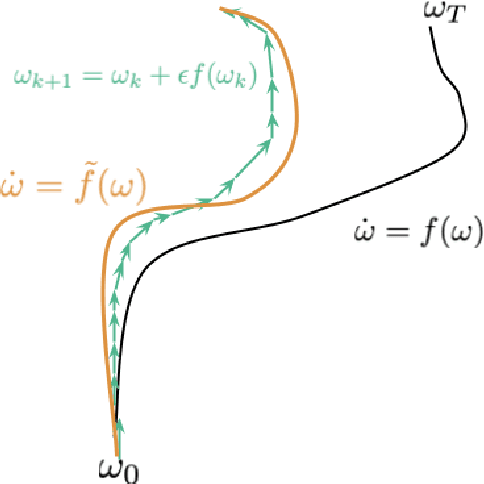
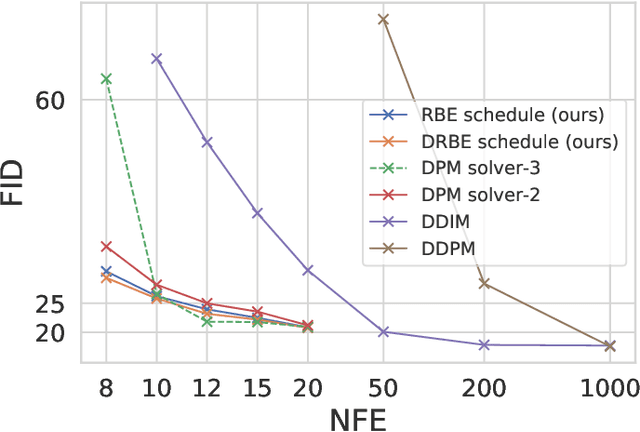
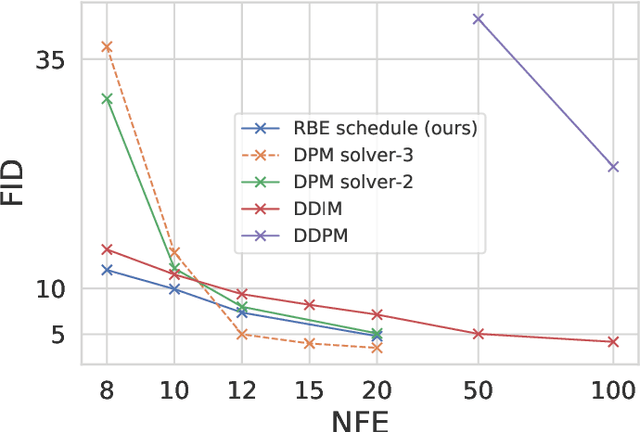
Denoising diffusion probabilistic models (DDPMs) are a class of powerful generative models. The past few years have witnessed the great success of DDPMs in generating high-fidelity samples. A significant limitation of the DDPMs is the slow sampling procedure. DDPMs generally need hundreds or thousands of sequential function evaluations (steps) of neural networks to generate a sample. This paper aims to develop a fast sampling method for DDPMs requiring much fewer steps while retaining high sample quality. The inference process of DDPMs approximates solving the corresponding diffusion ordinary differential equations (diffusion ODEs) in the continuous limit. This work analyzes how the backward error affects the diffusion ODEs and the sample quality in DDPMs. We propose fast sampling through the \textbf{Restricting Backward Error schedule (RBE schedule)} based on dynamically moderating the long-time backward error. Our method accelerates DDPMs without any further training. Our experiments show that sampling with an RBE schedule generates high-quality samples within only 8 to 20 function evaluations on various benchmark datasets. We achieved 12.01 FID in 8 function evaluations on the ImageNet $128\times128$, and a $20\times$ speedup compared with previous baseline samplers.
Audio coding with unified noise shaping and phase contrast control
Apr 17, 2023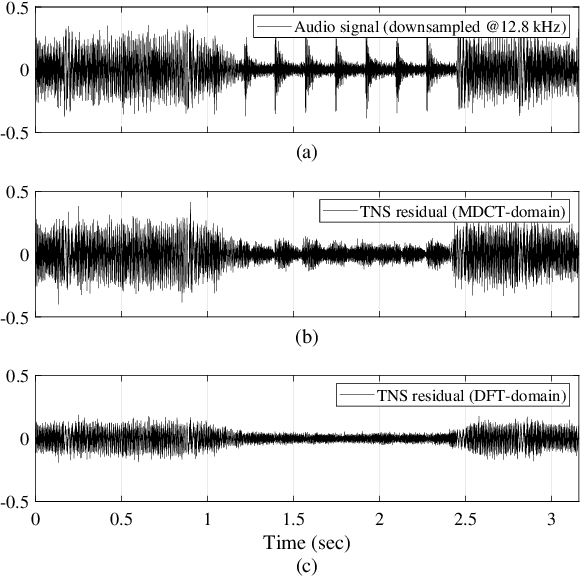
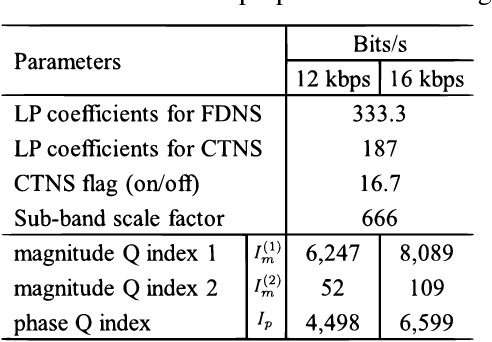
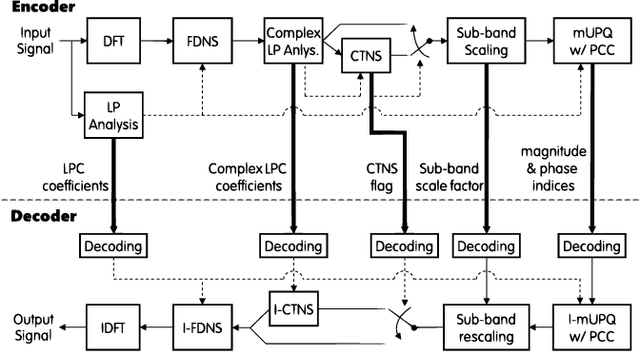
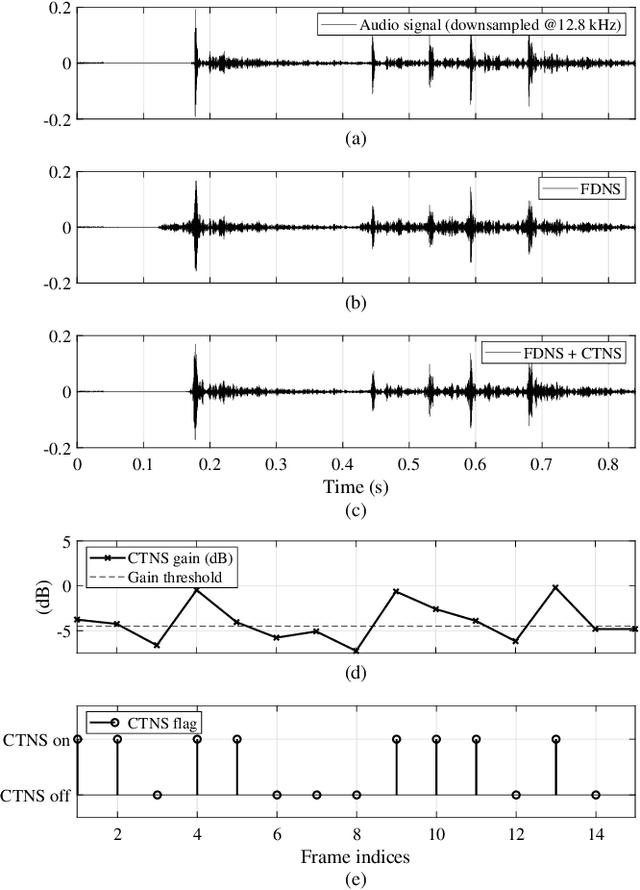
Over the past decade, audio coding technology has seen standardization and the development of many frameworks incorporated with linear predictive coding (LPC). As LPC reduces information in the frequency domain, LP-based frequency-domain noise-shaping (FDNS) was previously proposed. To code transient signals effectively, FDNS with temporal noise shaping (TNS) has emerged. However, these mainly operated in the modified discrete cosine transform domain, which essentially accompanies time domain aliasing. In this paper, a unified noise-shaping (UNS) framework including FDNS and complex LPC-based TNS (CTNS) in the DFT domain is proposed to overcome the aliasing issues. Additionally, a modified polar quantizer with phase contrast control is proposed, which saves phase bits depending on the frequency envelope information. The core coding feasibility at low bit rates is verified through various objective metrics and subjective listening evaluations.
Learning to Compress Prompts with Gist Tokens
Apr 17, 2023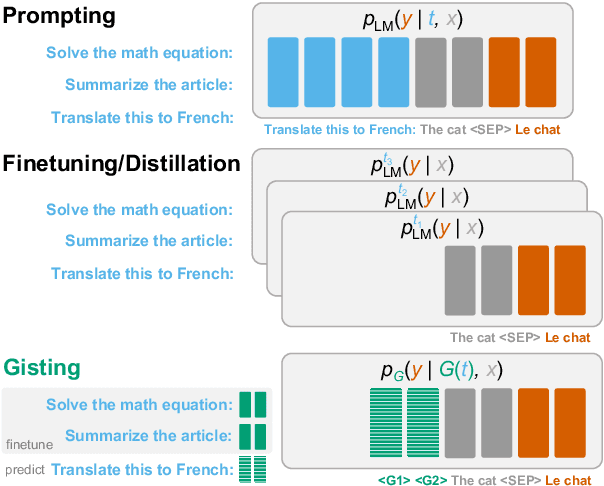
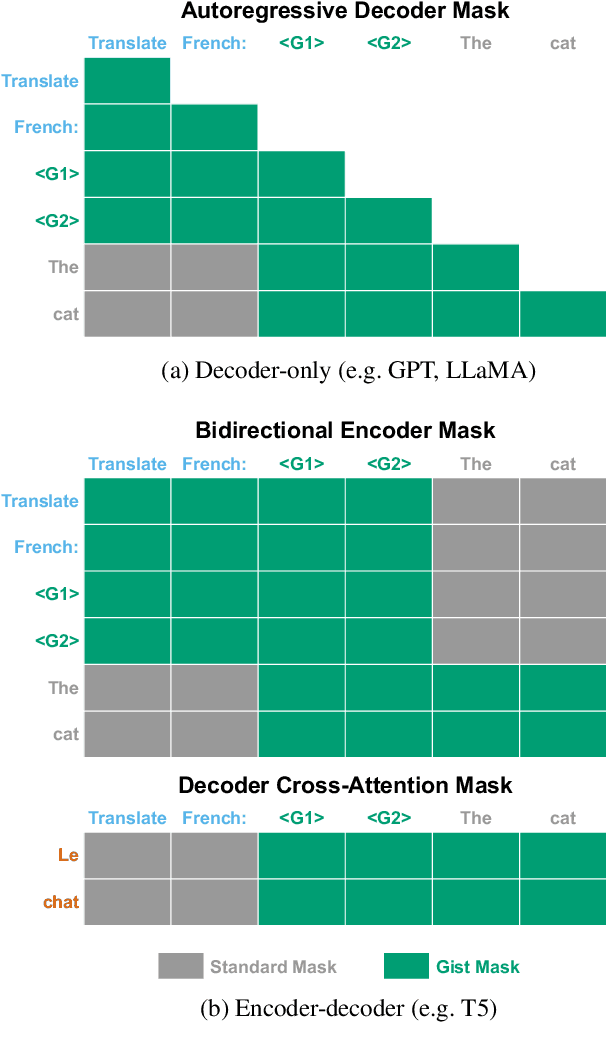
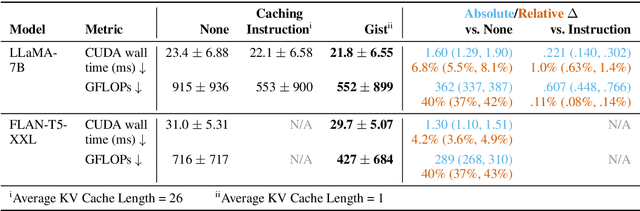
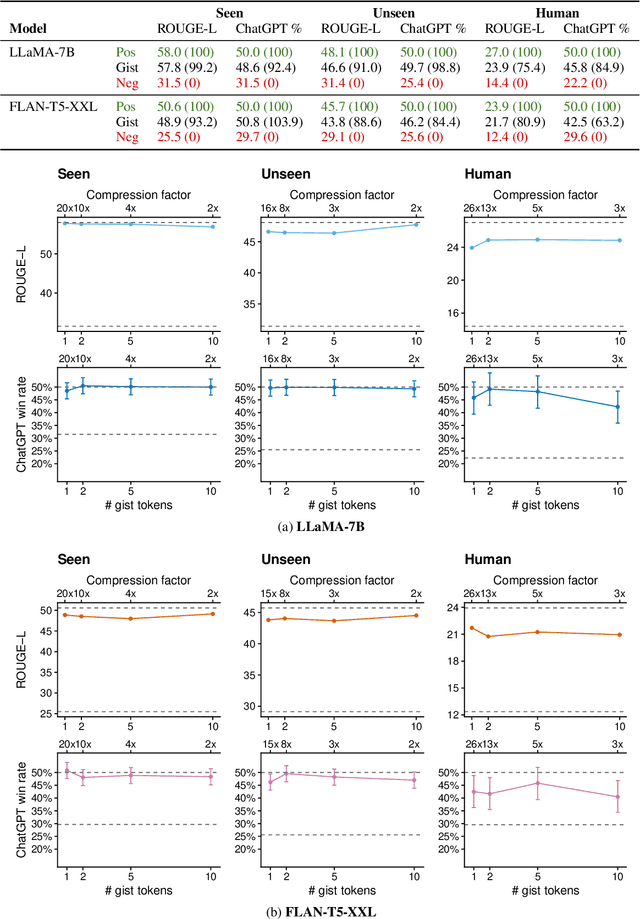
Prompting is now the primary way to utilize the multitask capabilities of language models (LMs), but prompts occupy valuable space in the input context window, and re-encoding the same prompt is computationally inefficient. Finetuning and distillation methods allow for specialization of LMs without prompting, but require retraining the model for each task. To avoid this trade-off entirely, we present gisting, which trains an LM to compress prompts into smaller sets of "gist" tokens which can be reused for compute efficiency. Gist models can be easily trained as part of instruction finetuning via a restricted attention mask that encourages prompt compression. On decoder (LLaMA-7B) and encoder-decoder (FLAN-T5-XXL) LMs, gisting enables up to 26x compression of prompts, resulting in up to 40% FLOPs reductions, 4.2% wall time speedups, storage savings, and minimal loss in output quality.
Tempo vs. Pitch: understanding self-supervised tempo estimation
Apr 14, 2023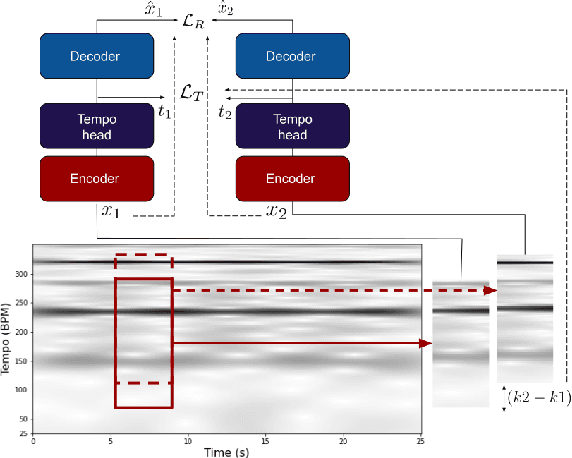
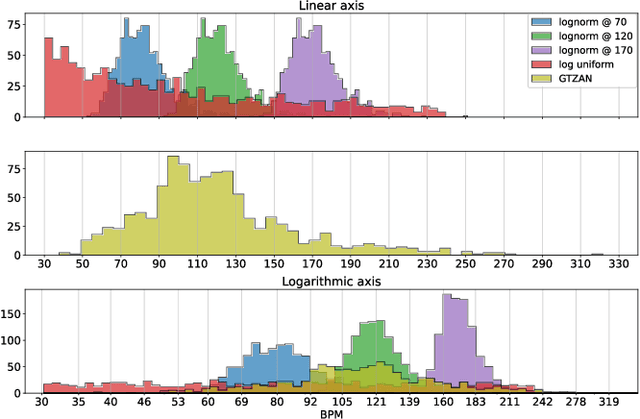
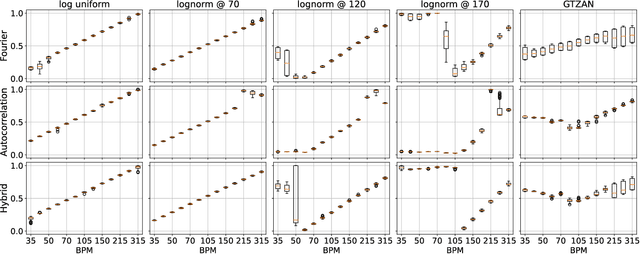
Self-supervision methods learn representations by solving pretext tasks that do not require human-generated labels, alleviating the need for time-consuming annotations. These methods have been applied in computer vision, natural language processing, environmental sound analysis, and recently in music information retrieval, e.g. for pitch estimation. Particularly in the context of music, there are few insights about the fragility of these models regarding different distributions of data, and how they could be mitigated. In this paper, we explore these questions by dissecting a self-supervised model for pitch estimation adapted for tempo estimation via rigorous experimentation with synthetic data. Specifically, we study the relationship between the input representation and data distribution for self-supervised tempo estimation.
Smart Watch Supported System for Health Care Monitoring
Apr 16, 2023This work presents a smartwatch attached to patients at remote locations, which would help in the navigation of wheel chair and monitor the vitals of patients and relay it through IoT. This wearable smartwatch is equipped with sensors to measure health parameters, namely, heartbeat, blood pressure, body temperature, and step count. An esp8266 Wi-Fi module uploads the health parameters into the thingspeak cloud platform with a time stamp. This smartwatch is equipped with a joystick for cruise and navigation control of the motor driver-enabled wheelchair. Additionally, an ultrasonic sensor mounted in front of the wheelchair continuously scans for any obstacles ahead and stops the motion of the wheelchair upon detection of an obstacle. The primary controller of the system is an Arduino UNO microcontroller, which interfaces the input and output modules.
Sinkhorn-Flow: Predicting Probability Mass Flow in Dynamical Systems Using Optimal Transport
Mar 14, 2023
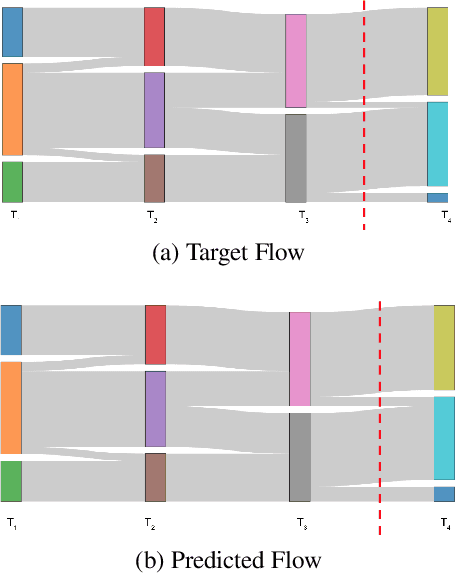
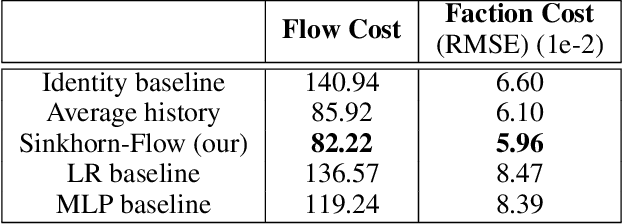
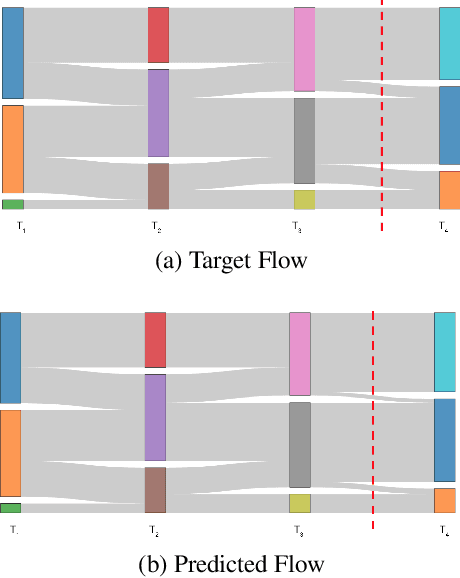
Predicting how distributions over discrete variables vary over time is a common task in time series forecasting. But whereas most approaches focus on merely predicting the distribution at subsequent time steps, a crucial piece of information in many settings is to determine how this probability mass flows between the different elements over time. We propose a new approach to predicting such mass flow over time using optimal transport. Specifically, we propose a generic approach to predicting transport matrices in end-to-end deep learning systems, replacing the standard softmax operation with Sinkhorn iterations. We apply our approach to the task of predicting how communities will evolve over time in social network settings, and show that the approach improves substantially over alternative prediction methods. We specifically highlight results on the task of predicting faction evolution in Ukrainian parliamentary voting.
Teacher Network Calibration Improves Cross-Quality Knowledge Distillation
Apr 15, 2023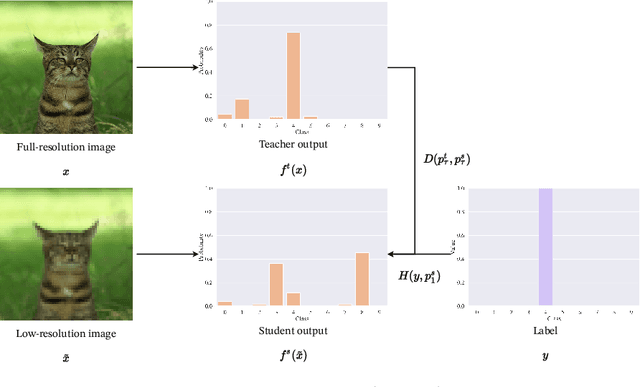
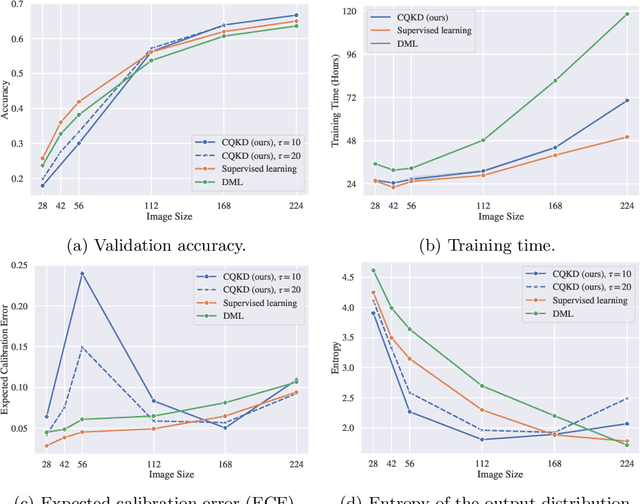
We investigate cross-quality knowledge distillation (CQKD), a knowledge distillation method where knowledge from a teacher network trained with full-resolution images is transferred to a student network that takes as input low-resolution images. As image size is a deciding factor for the computational load of computer vision applications, CQKD notably reduces the requirements by only using the student network at inference time. Our experimental results show that CQKD outperforms supervised learning in large-scale image classification problems. We also highlight the importance of calibrating neural networks: we show that with higher temperature smoothing of the teacher's output distribution, the student distribution exhibits a higher entropy, which leads to both, a lower calibration error and a higher network accuracy.
Robust Mean Teacher for Continual and Gradual Test-Time Adaptation
Nov 23, 2022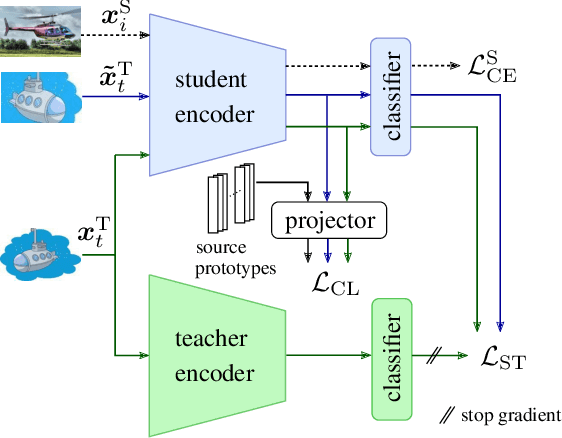
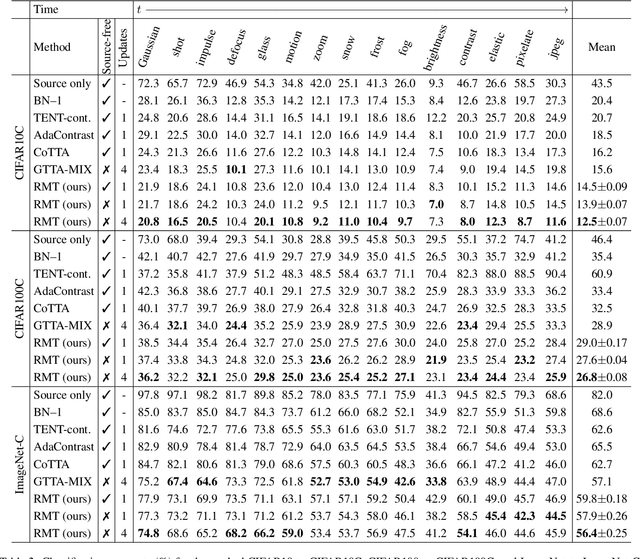
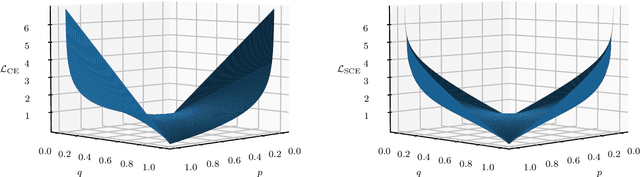
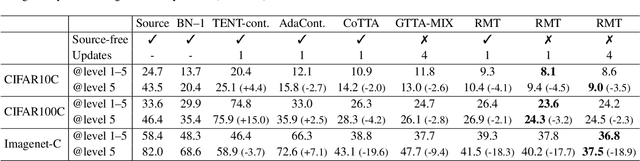
Since experiencing domain shifts during test-time is inevitable in practice, test-time adaption (TTA) continues to adapt the model during deployment. Recently, the area of continual and gradual test-time adaptation (TTA) emerged. In contrast to standard TTA, continual TTA considers not only a single domain shift, but a sequence of shifts. Gradual TTA further exploits the property that some shifts evolve gradually over time. Since in both settings long test sequences are present, error accumulation needs to be addressed for methods relying on self-training. In this work, we propose and show that in the setting of TTA, the symmetric cross-entropy is better suited as a consistency loss for mean teachers compared to the commonly used cross-entropy. This is justified by our analysis with respect to the (symmetric) cross-entropy's gradient properties. To pull the test feature space closer to the source domain, where the pre-trained model is well posed, contrastive learning is leveraged. Since applications differ in their requirements, we address different settings, namely having source data available and the more challenging source-free setting. We demonstrate the effectiveness of our proposed method 'robust mean teacher' (RMT) on the continual and gradual corruption benchmarks CIFAR10C, CIFAR100C, and Imagenet-C. We further consider ImageNet-R and propose a new continual DomainNet-126 benchmark. State-of-the-art results are achieved on all benchmarks.