 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Longitudinal Multimodal Transformer Integrating Imaging and Latent Clinical Signatures From Routine EHRs for Pulmonary Nodule Classification
Apr 10, 2023
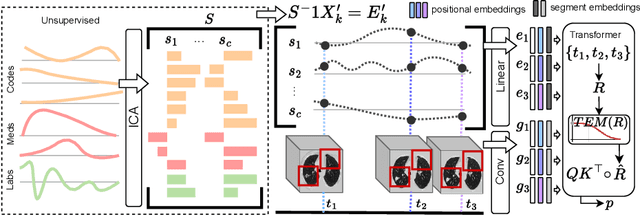
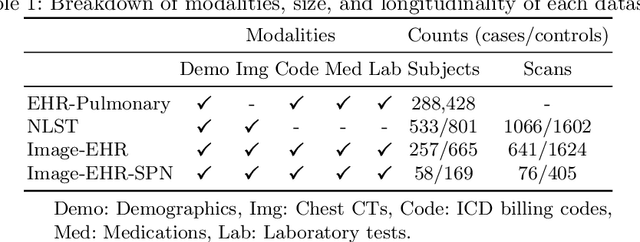
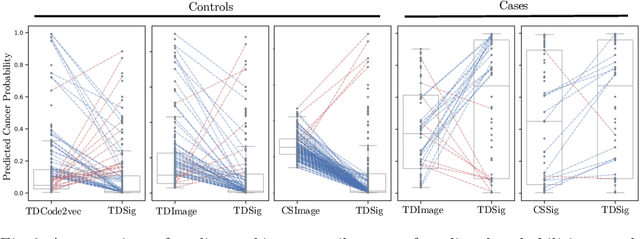
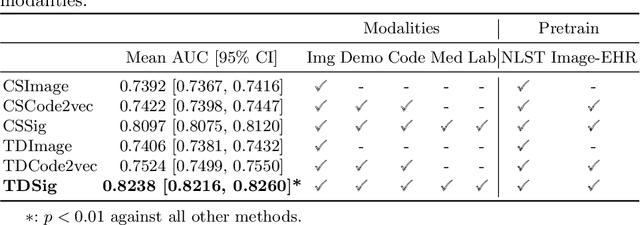
The accuracy of predictive models for solitary pulmonary nodule (SPN) diagnosis can be greatly increased by incorporating repeat imaging and medical context, such as electronic health records (EHRs). However, clinically routine modalities such as imaging and diagnostic codes can be asynchronous and irregularly sampled over different time scales which are obstacles to longitudinal multimodal learning. In this work, we propose a transformer-based multimodal strategy to integrate repeat imaging with longitudinal clinical signatures from routinely collected EHRs for SPN classification. We perform unsupervised disentanglement of latent clinical signatures and leverage time-distance scaled self-attention to jointly learn from clinical signatures expressions and chest computed tomography (CT) scans. Our classifier is pretrained on 2,668 scans from a public dataset and 1,149 subjects with longitudinal chest CTs, billing codes, medications, and laboratory tests from EHRs of our home institution. Evaluation on 227 subjects with challenging SPNs revealed a significant AUC improvement over a longitudinal multimodal baseline (0.824 vs 0.752 AUC), as well as improvements over a single cross-section multimodal scenario (0.809 AUC) and a longitudinal imaging-only scenario (0.741 AUC). This work demonstrates significant advantages with a novel approach for co-learning longitudinal imaging and non-imaging phenotypes with transformers.
Accelerated deep self-supervised ptycho-laminography for three-dimensional nanoscale imaging of integrated circuits
Apr 10, 2023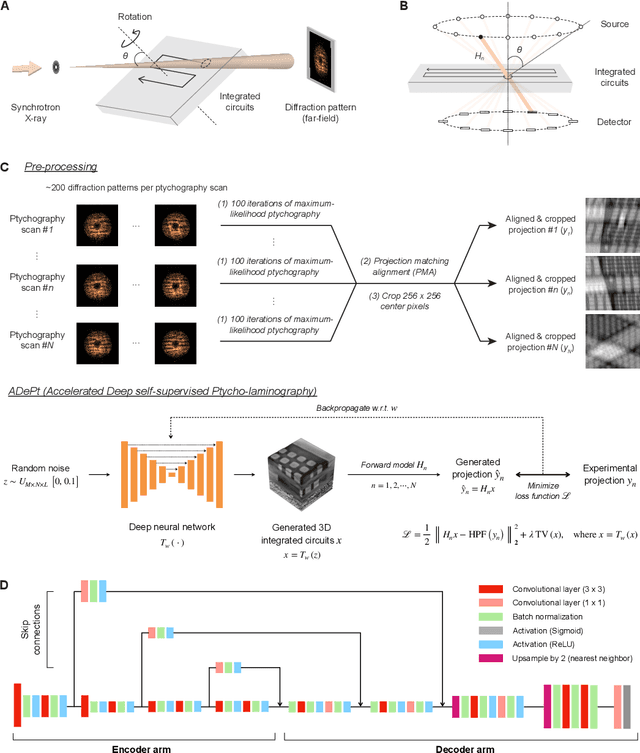
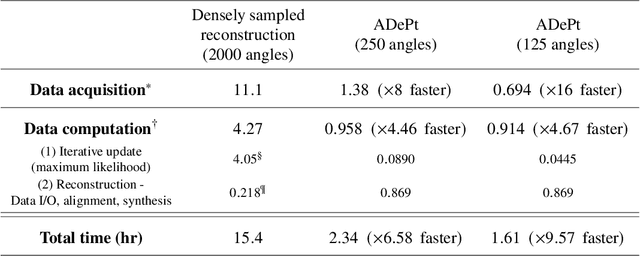
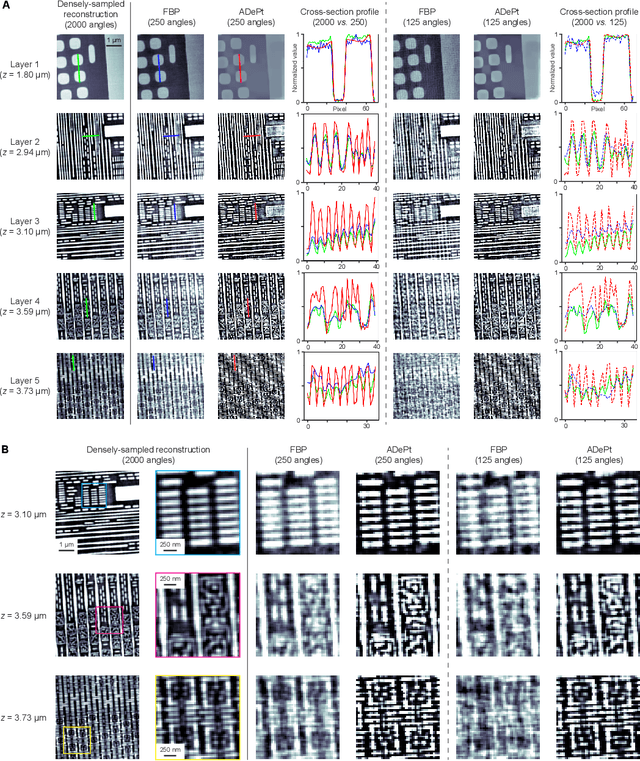
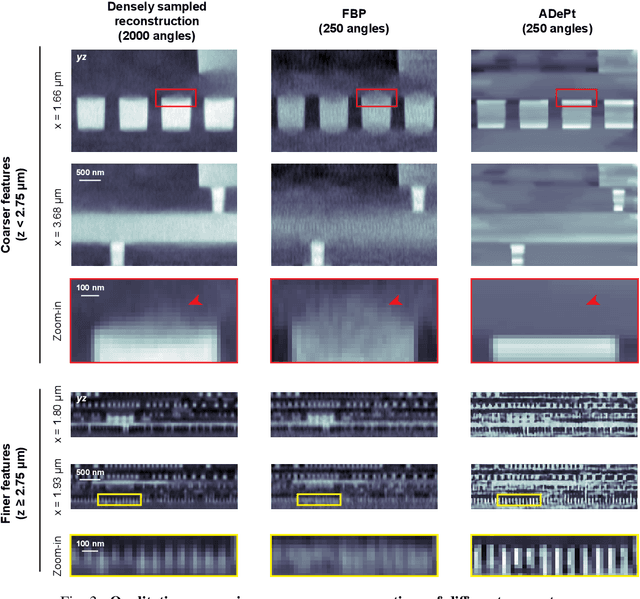
Three-dimensional inspection of nanostructures such as integrated circuits is important for security and reliability assurance. Two scanning operations are required: ptychographic to recover the complex transmissivity of the specimen; and rotation of the specimen to acquire multiple projections covering the 3D spatial frequency domain. Two types of rotational scanning are possible: tomographic and laminographic. For flat, extended samples, for which the full 180 degree coverage is not possible, the latter is preferable because it provides better coverage of the 3D spatial frequency domain compared to limited-angle tomography. It is also because the amount of attenuation through the sample is approximately the same for all projections. However, both techniques are time consuming because of extensive acquisition and computation time. Here, we demonstrate the acceleration of ptycho-laminographic reconstruction of integrated circuits with 16-times fewer angular samples and 4.67-times faster computation by using a physics-regularized deep self-supervised learning architecture. We check the fidelity of our reconstruction against a densely sampled reconstruction that uses full scanning and no learning. As already reported elsewhere [Zhou and Horstmeyer, Opt. Express, 28(9), pp. 12872-12896], we observe improvement of reconstruction quality even over the densely sampled reconstruction, due to the ability of the self-supervised learning kernel to fill the missing cone.
Cellular EXchange Imaging (CEXI): Evaluation of a diffusion model including water exchange in cells using numerical phantoms of permeable spheres
Mar 28, 2023

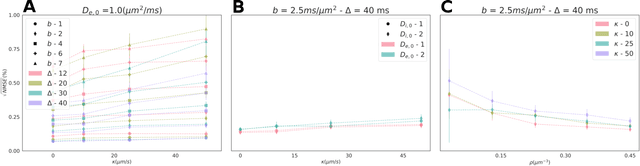
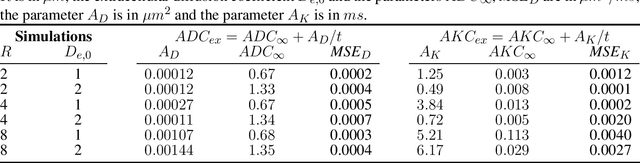
Purpose: Biophysical models of diffusion MRI have been developed to characterize microstructure in various tissues, but existing models are not suitable for tissue composed of permeable spherical cells. In this study we introduce Cellular Exchange Imaging (CEXI), a model tailored for permeable spherical cells, and compares its performance to a related Ball \& Sphere (BS) model that neglects permeability. Methods: We generated DW-MRI signals using Monte-Carlo simulations with a PGSE sequence in numerical substrates made of spherical cells and their extracellular space for a range of membrane permeability. From these signals, the properties of the substrates were inferred using both BS and CEXI models. Results: CEXI outperformed the impermeable model by providing more stable estimates cell size and intracellular volume fraction that were diffusion time-independent. Notably, CEXI accurately estimated the exchange time for low to moderate permeability levels previously reported in other studies ($\kappa<25\mu m/s$). However, in highly permeable substrates ($\kappa=50\mu m/s$), the estimated parameters were less stable, particularly the diffusion coefficients. Conclusion: This study highlights the importance of modeling the exchange time to accurately quantify microstructure properties in permeable cellular substrates. Future studies should evaluate CEXI in clinical applications such as lymph nodes, investigate exchange time as a potential biomarker of tumor severity, and develop more appropriate tissue models that account for anisotropic diffusion and highly permeable membranes.
Continuous Time Analysis of Dynamic Matching in Heterogeneous Networks
Feb 20, 2023
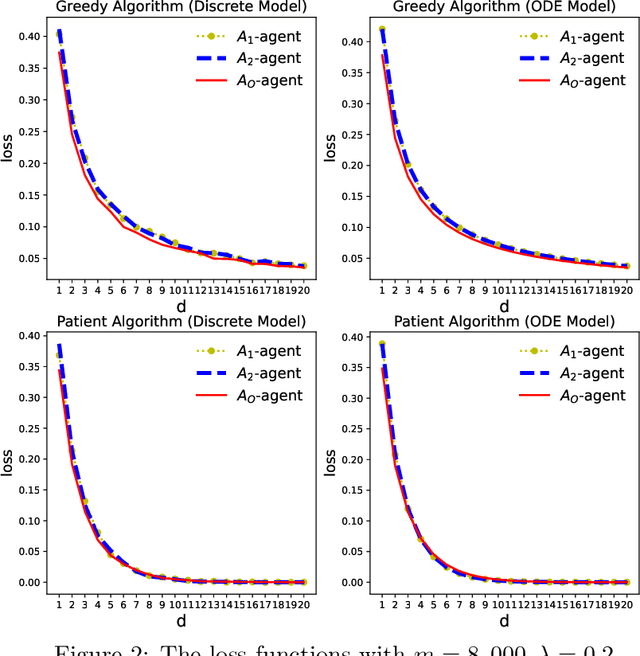
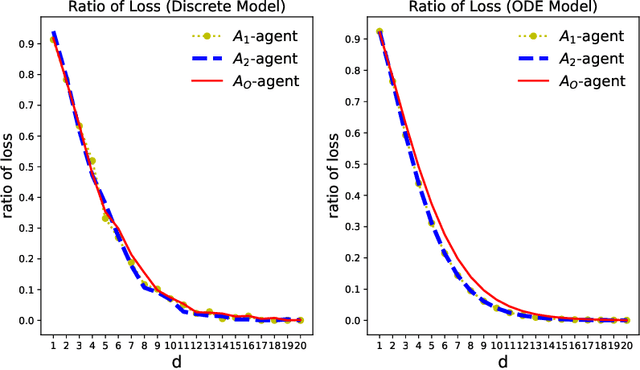
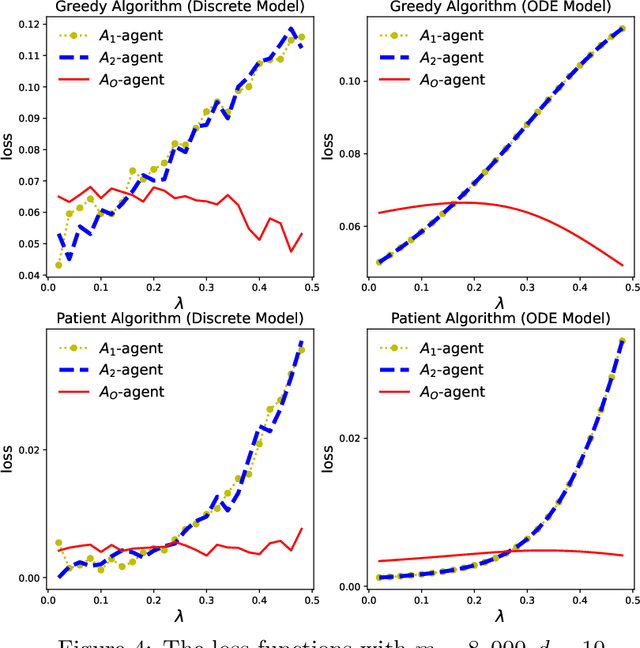
This paper addresses the problem of dynamic matching in heterogeneous networks, where agents are subject to compatibility restrictions and stochastic arrival and departure times. In particular, we consider networks with one type of easy-to-match agents and multiple types of hard-to-match agents, each subject to its own set of compatibility constraints. Such a setting arises in many real-world applications, including kidney exchange programs and carpooling platforms, where some participants may have more stringent compatibility requirements than others. We introduce a novel approach to modeling dynamic matching by establishing ordinary differential equation (ODE) models, offering a new perspective for evaluating various matching algorithms. We study two algorithms, the Greedy Algorithm and the Patient Algorithm, which prioritize the matching of compatible hard-to-match agents over easy-to-match agents in heterogeneous networks. Our results show the trade-off between the conflicting goals of matching agents quickly and optimally, offering insights into the design of real-world dynamic matching systems. We present simulations and a real-world case study using data from the Organ Procurement and Transplantation Network to validate theoretical predictions.
A framework for fully autonomous design of materials via multiobjective optimization and active learning: challenges and next steps
Apr 15, 2023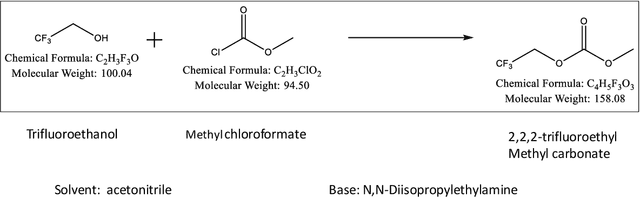
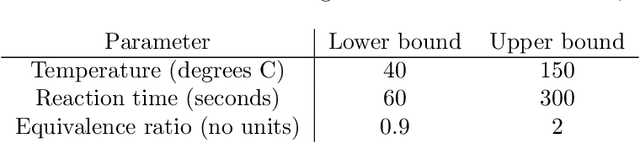
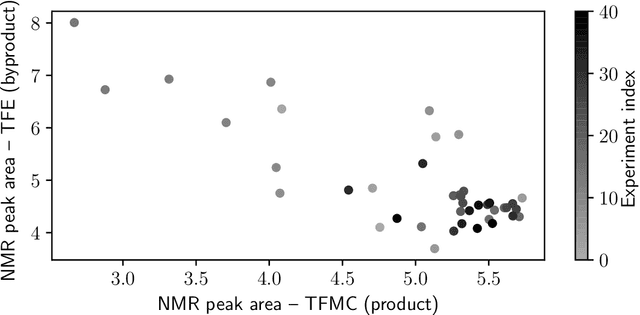
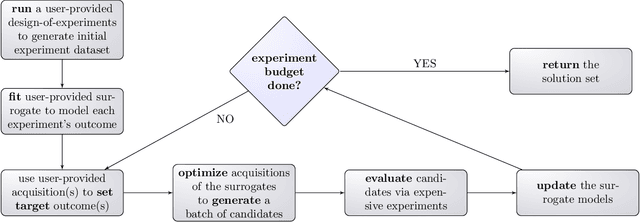
In order to deploy machine learning in a real-world self-driving laboratory where data acquisition is costly and there are multiple competing design criteria, systems need to be able to intelligently sample while balancing performance trade-offs and constraints. For these reasons, we present an active learning process based on multiobjective black-box optimization with continuously updated machine learning models. This workflow is built on open-source technologies for real-time data streaming and modular multiobjective optimization software development. We demonstrate a proof of concept for this workflow through the autonomous operation of a continuous-flow chemistry laboratory, which identifies ideal manufacturing conditions for the electrolyte 2,2,2-trifluoroethyl methyl carbonate.
Adaptive Data Augmentation for Contrastive Learning
Apr 19, 2023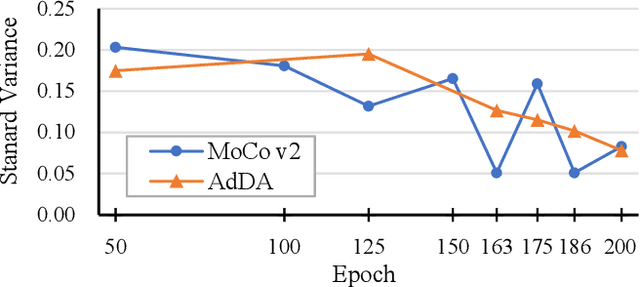
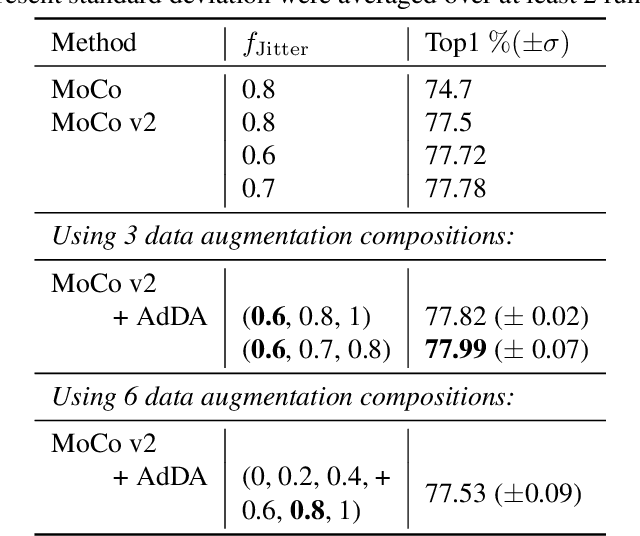
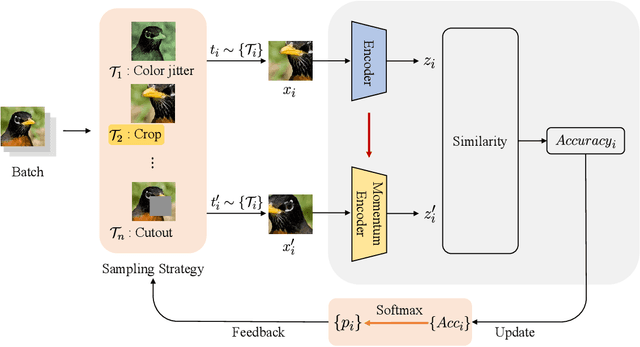
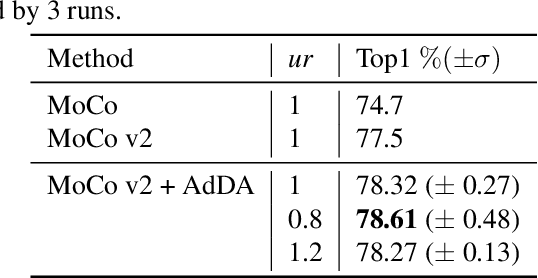
In computer vision, contrastive learning is the most advanced unsupervised learning framework. Yet most previous methods simply apply fixed composition of data augmentations to improve data efficiency, which ignores the changes in their optimal settings over training. Thus, the pre-determined parameters of augmentation operations cannot always fit well with an evolving network during the whole training period, which degrades the quality of the learned representations. In this work, we propose AdDA, which implements a closed-loop feedback structure to a generic contrastive learning network. AdDA works by allowing the network to adaptively adjust the augmentation compositions according to the real-time feedback. This online adjustment helps maintain the dynamic optimal composition and enables the network to acquire more generalizable representations with minimal computational overhead. AdDA achieves competitive results under the common linear protocol on ImageNet-100 classification (+1.11% on MoCo v2).
Revisiting the Role of Similarity and Dissimilarity in Best Counter Argument Retrieval
Apr 19, 2023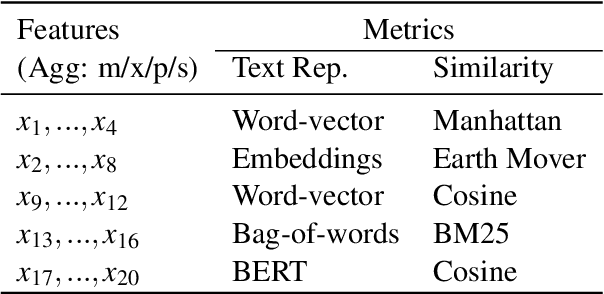
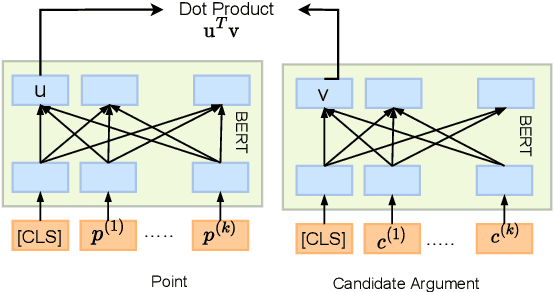
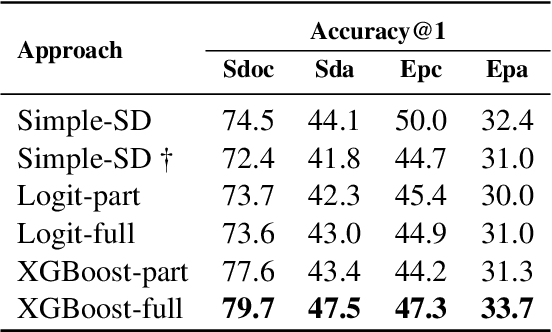
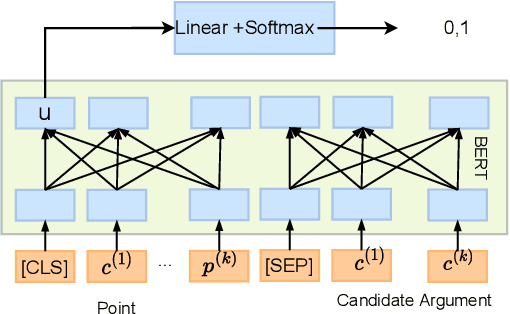
This paper studies the task of best counter-argument retrieval given an input argument. Following the definition that the best counter-argument addresses the same aspects as the input argument while having the opposite stance, we aim to develop an efficient and effective model for scoring counter-arguments based on similarity and dissimilarity metrics. We first conduct an experimental study on the effectiveness of available scoring methods, including traditional Learning-To-Rank (LTR) and recent neural scoring models. We then propose Bipolar-encoder, a novel BERT-based model to learn an optimal representation for simultaneous similarity and dissimilarity. Experimental results show that our proposed method can achieve the accuracy@1 of 49.04\%, which significantly outperforms other baselines by a large margin. When combined with an appropriate caching technique, Bipolar-encoder is comparably efficient at prediction time.
Distribution estimation and change-point detection for time series via DNN-based GANs
Nov 26, 2022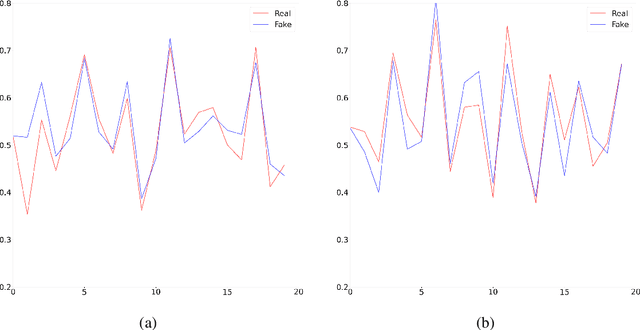
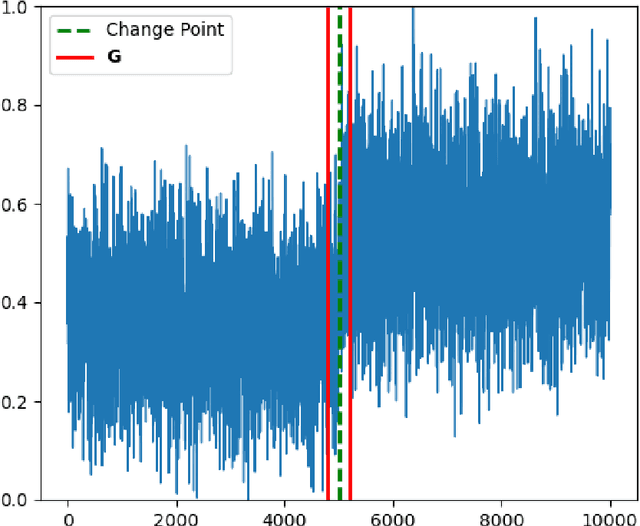
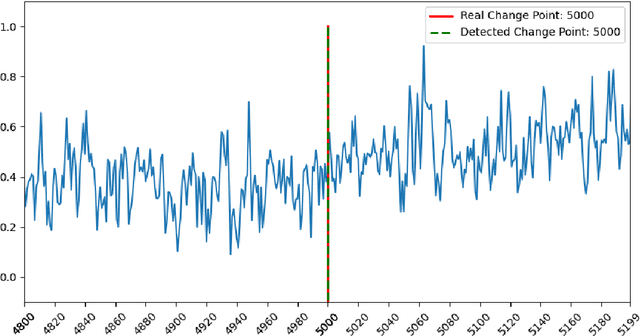
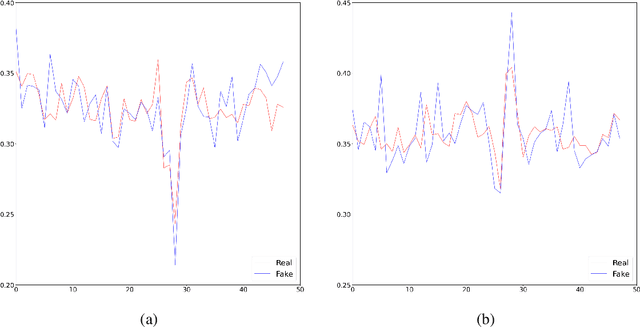
The generative adversarial networks (GANs) have recently been applied to estimating the distribution of independent and identically distributed data, and got excellent performances. In this paper, we use the blocking technique to demonstrate the effectiveness of GANs for estimating the distribution of stationary time series. Theoretically, we obtain a non-asymptotic error bound for the Deep Neural Network (DNN)-based GANs estimator for the stationary distribution of the time series. Based on our theoretical analysis, we put forward an algorithm for detecting the change-point in time series. We simulate in our first experiment a stationary time series by the multivariate autoregressive model to test our GAN estimator, while the second experiment is to use our proposed algorithm to detect the change-point in a time series sequence. Both perform very well. The third experiment is to use our GAN estimator to learn the distribution of a real financial time series data, which is not stationary, we can see from the experiment results that our estimator cannot match the distribution of the time series very well but give the right changing tendency.
Optimizing Data Shapley Interaction Calculation from O(2^n) to O(t n^2) for KNN models
Apr 02, 2023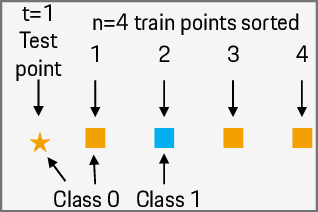
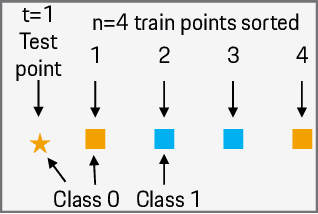
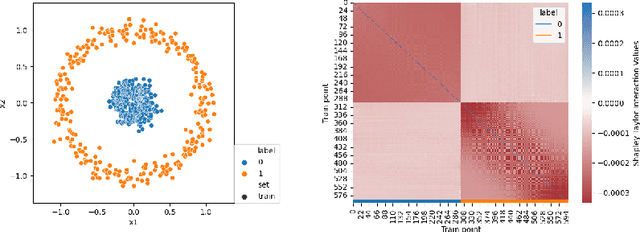
With the rapid growth of data availability and usage, quantifying the added value of each training data point has become a crucial process in the field of artificial intelligence. The Shapley values have been recognized as an effective method for data valuation, enabling efficient training set summarization, acquisition, and outlier removal. In this paper, we introduce "STI-KNN", an innovative algorithm that calculates the exact pair-interaction Shapley values for KNN models in O(t n^2) time, which is a significant improvement over the O(2^n)$ time complexity of baseline methods. By using STI-KNN, we can efficiently and accurately evaluate the value of individual data points, leading to improved training outcomes and ultimately enhancing the effectiveness of artificial intelligence applications.
Ensemble weather forecast post-processing with a flexible probabilistic neural network approach
Apr 07, 2023
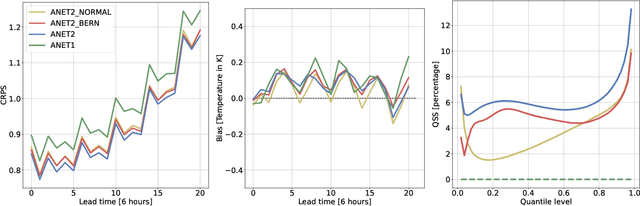
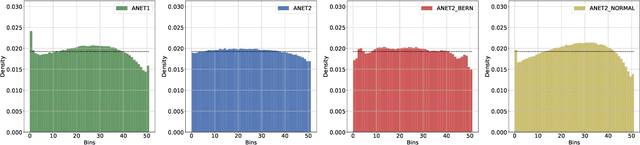
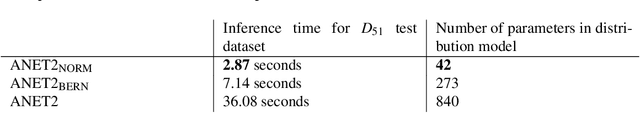
Ensemble forecast post-processing is a necessary step in producing accurate probabilistic forecasts. Conventional post-processing methods operate by estimating the parameters of a parametric distribution, frequently on a per-location or per-lead-time basis. We propose a novel, neural network-based method, which produces forecasts for all locations and lead times, jointly. To relax the distributional assumption of many post-processing methods, our approach incorporates normalizing flows as flexible parametric distribution estimators. This enables us to model varying forecast distributions in a mathematically exact way. We demonstrate the effectiveness of our method in the context of the EUPPBench benchmark, where we conduct temperature forecast post-processing for stations in a sub-region of western Europe. We show that our novel method exhibits state-of-the-art performance on the benchmark, outclassing our previous, well-performing entry. Additionally, by providing a detailed comparison of three variants of our novel post-processing method, we elucidate the reasons why our method outperforms per-lead-time-based approaches and approaches with distributional assumptions.