 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Theoretical and Practical Perspectives on what Influence Functions Do
May 26, 2023
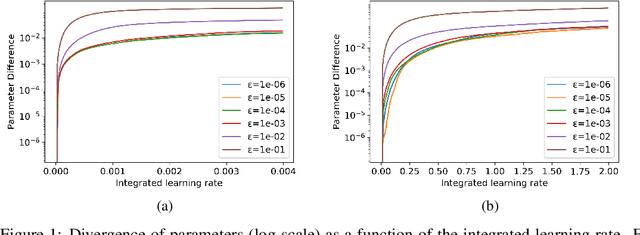
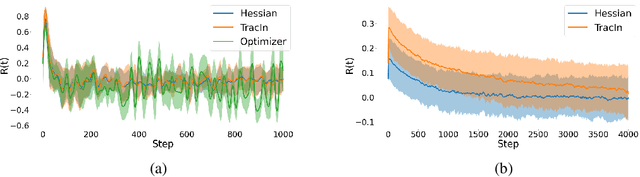

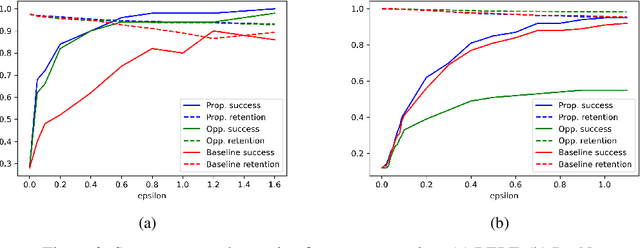
Influence functions (IF) have been seen as a technique for explaining model predictions through the lens of the training data. Their utility is assumed to be in identifying training examples "responsible" for a prediction so that, for example, correcting a prediction is possible by intervening on those examples (removing or editing them) and retraining the model. However, recent empirical studies have shown that the existing methods of estimating IF predict the leave-one-out-and-retrain effect poorly. In order to understand the mismatch between the theoretical promise and the practical results, we analyse five assumptions made by IF methods which are problematic for modern-scale deep neural networks and which concern convexity, numeric stability, training trajectory and parameter divergence. This allows us to clarify what can be expected theoretically from IF. We show that while most assumptions can be addressed successfully, the parameter divergence poses a clear limitation on the predictive power of IF: influence fades over training time even with deterministic training. We illustrate this theoretical result with BERT and ResNet models. Another conclusion from the theoretical analysis is that IF are still useful for model debugging and correcting even though some of the assumptions made in prior work do not hold: using natural language processing and computer vision tasks, we verify that mis-predictions can be successfully corrected by taking only a few fine-tuning steps on influential examples.
PromptNER: Prompt Locating and Typing for Named Entity Recognition
May 26, 2023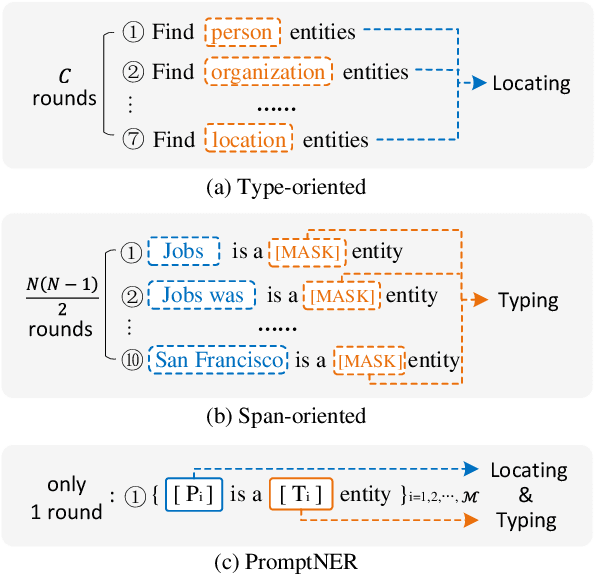
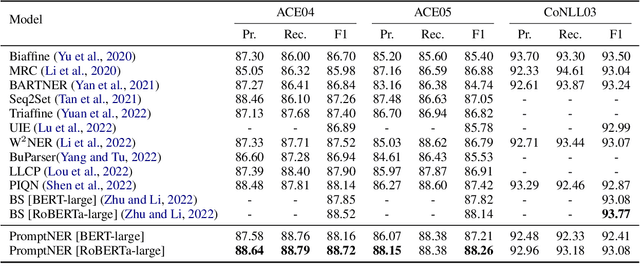
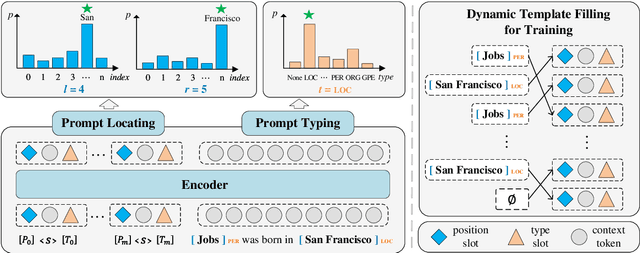
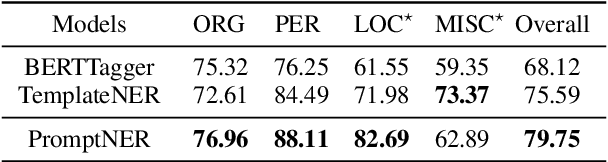
Prompt learning is a new paradigm for utilizing pre-trained language models and has achieved great success in many tasks. To adopt prompt learning in the NER task, two kinds of methods have been explored from a pair of symmetric perspectives, populating the template by enumerating spans to predict their entity types or constructing type-specific prompts to locate entities. However, these methods not only require a multi-round prompting manner with a high time overhead and computational cost, but also require elaborate prompt templates, that are difficult to apply in practical scenarios. In this paper, we unify entity locating and entity typing into prompt learning, and design a dual-slot multi-prompt template with the position slot and type slot to prompt locating and typing respectively. Multiple prompts can be input to the model simultaneously, and then the model extracts all entities by parallel predictions on the slots. To assign labels for the slots during training, we design a dynamic template filling mechanism that uses the extended bipartite graph matching between prompts and the ground-truth entities. We conduct experiments in various settings, including resource-rich flat and nested NER datasets and low-resource in-domain and cross-domain datasets. Experimental results show that the proposed model achieves a significant performance improvement, especially in the cross-domain few-shot setting, which outperforms the state-of-the-art model by +7.7% on average.
Local Search, Semantics, and Genetic Programming: a Global Analysis
May 26, 2023
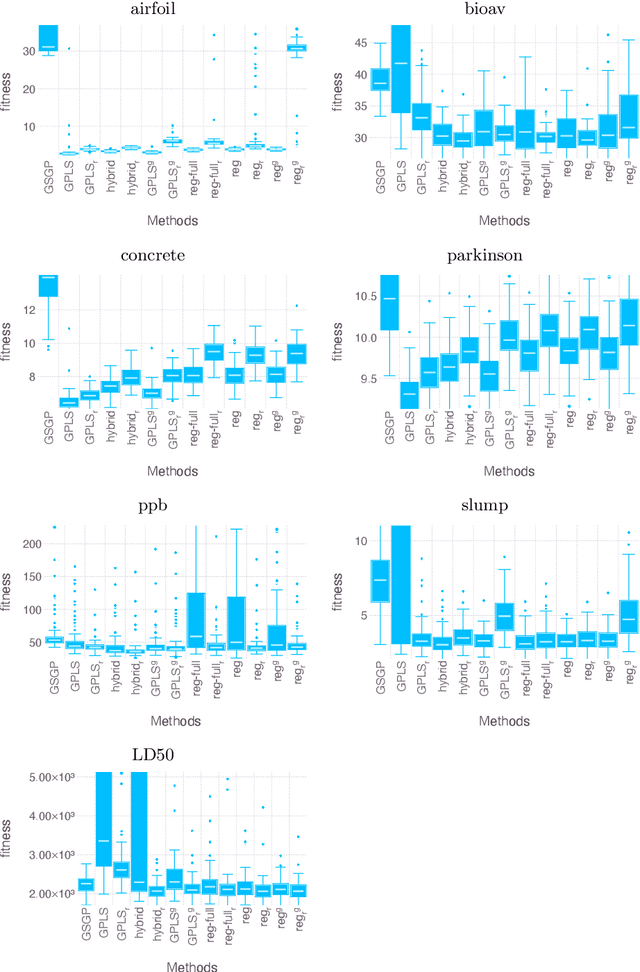
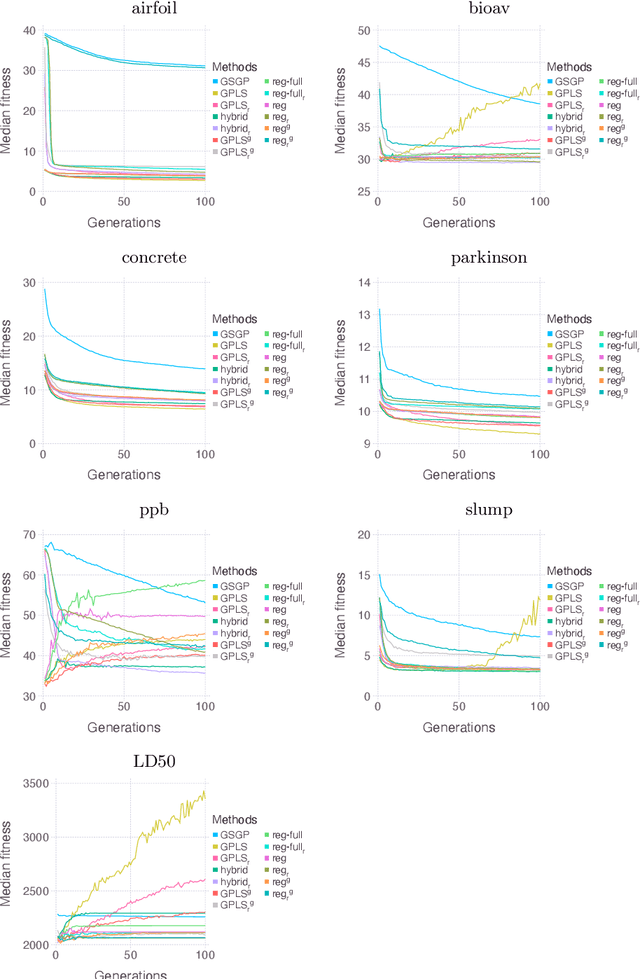
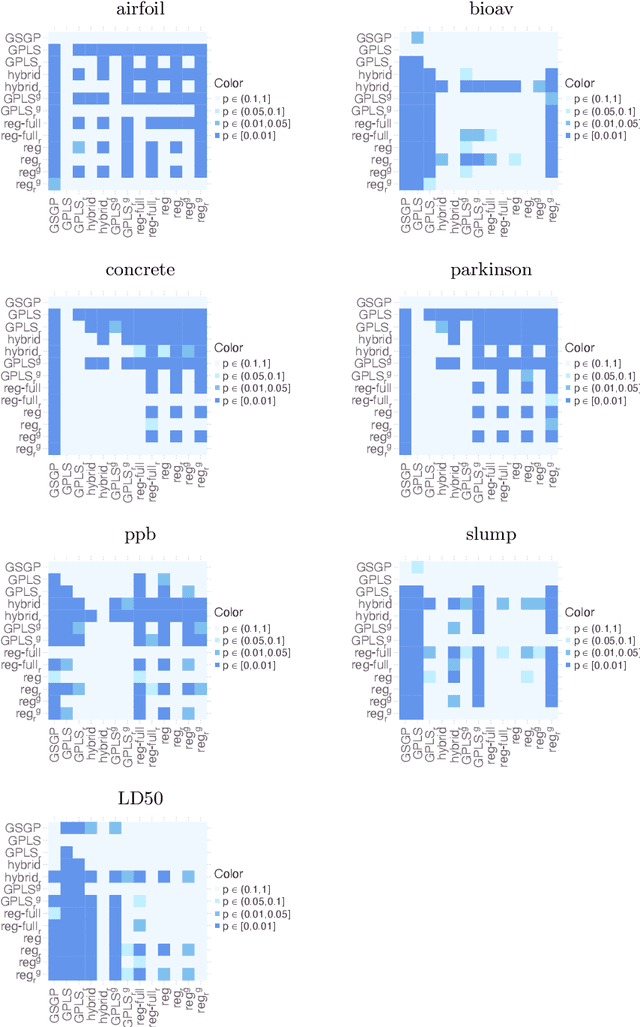
Geometric Semantic Geometric Programming (GSGP) is one of the most prominent Genetic Programming (GP) variants, thanks to its solid theoretical background, the excellent performance achieved, and the execution time significantly smaller than standard syntax-based GP. In recent years, a new mutation operator, Geometric Semantic Mutation with Local Search (GSM-LS), has been proposed to include a local search step in the mutation process based on the idea that performing a linear regression during the mutation can allow for a faster convergence to good-quality solutions. While GSM-LS helps the convergence of the evolutionary search, it is prone to overfitting. Thus, it was suggested to use GSM-LS only for a limited number of generations and, subsequently, to switch back to standard geometric semantic mutation. A more recently defined variant of GSGP (called GSGP-reg) also includes a local search step but shares similar strengths and weaknesses with GSM-LS. Here we explore multiple possibilities to limit the overfitting of GSM-LS and GSGP-reg, ranging from adaptive methods to estimate the risk of overfitting at each mutation to a simple regularized regression. The results show that the method used to limit overfitting is not that important: providing that a technique to control overfitting is used, it is possible to consistently outperform standard GSGP on both training and unseen data. The obtained results allow practitioners to better understand the role of local search in GSGP and demonstrate that simple regularization strategies are effective in controlling overfitting.
Im-Promptu: In-Context Composition from Image Prompts
May 26, 2023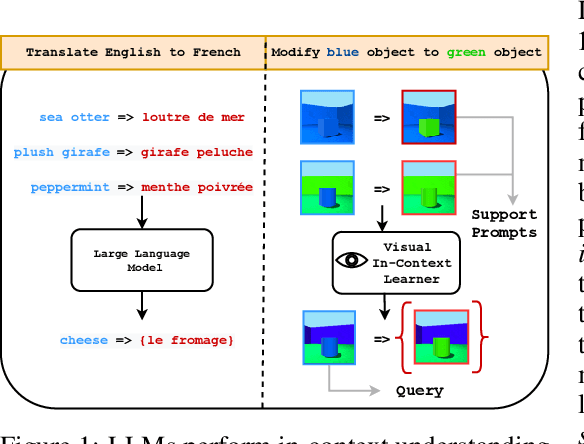

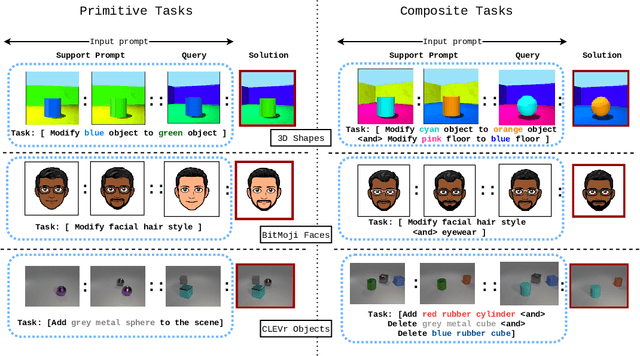
Large language models are few-shot learners that can solve diverse tasks from a handful of demonstrations. This implicit understanding of tasks suggests that the attention mechanisms over word tokens may play a role in analogical reasoning. In this work, we investigate whether analogical reasoning can enable in-context composition over composable elements of visual stimuli. First, we introduce a suite of three benchmarks to test the generalization properties of a visual in-context learner. We formalize the notion of an analogy-based in-context learner and use it to design a meta-learning framework called Im-Promptu. Whereas the requisite token granularity for language is well established, the appropriate compositional granularity for enabling in-context generalization in visual stimuli is usually unspecified. To this end, we use Im-Promptu to train multiple agents with different levels of compositionality, including vector representations, patch representations, and object slots. Our experiments reveal tradeoffs between extrapolation abilities and the degree of compositionality, with non-compositional representations extending learned composition rules to unseen domains but performing poorly on combinatorial tasks. Patch-based representations require patches to contain entire objects for robust extrapolation. At the same time, object-centric tokenizers coupled with a cross-attention module generate consistent and high-fidelity solutions, with these inductive biases being particularly crucial for compositional generalization. Lastly, we demonstrate a use case of Im-Promptu as an intuitive programming interface for image generation.
TR3D: Towards Real-Time Indoor 3D Object Detection
Feb 06, 2023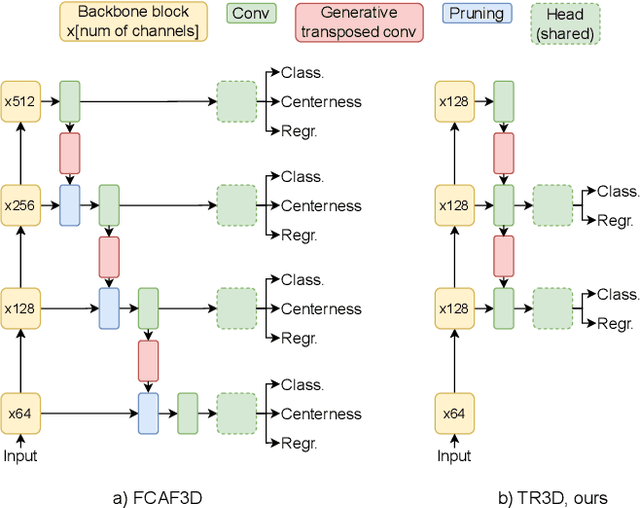
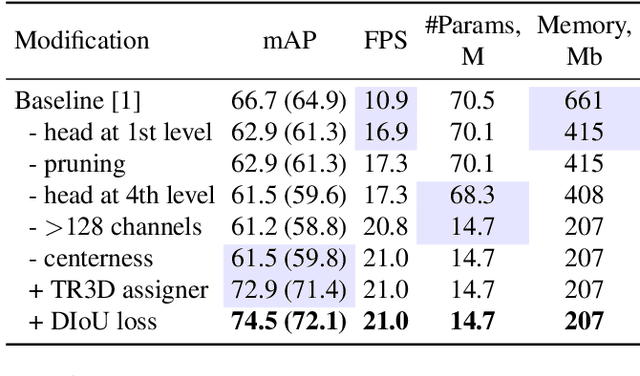

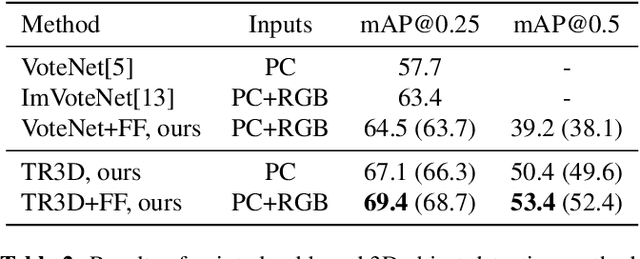
Recently, sparse 3D convolutions have changed 3D object detection. Performing on par with the voting-based approaches, 3D CNNs are memory-efficient and scale to large scenes better. However, there is still room for improvement. With a conscious, practice-oriented approach to problem-solving, we analyze the performance of such methods and localize the weaknesses. Applying modifications that resolve the found issues one by one, we end up with TR3D: a fast fully-convolutional 3D object detection model trained end-to-end, that achieves state-of-the-art results on the standard benchmarks, ScanNet v2, SUN RGB-D, and S3DIS. Moreover, to take advantage of both point cloud and RGB inputs, we introduce an early fusion of 2D and 3D features. We employ our fusion module to make conventional 3D object detection methods multimodal and demonstrate an impressive boost in performance. Our model with early feature fusion, which we refer to as TR3D+FF, outperforms existing 3D object detection approaches on the SUN RGB-D dataset. Overall, besides being accurate, both TR3D and TR3D+FF models are lightweight, memory-efficient, and fast, thereby marking another milestone on the way toward real-time 3D object detection. Code is available at https://github.com/SamsungLabs/tr3d .
Sensing of inspiration events from speech: comparison of deep learning and linguistic methods
May 19, 2023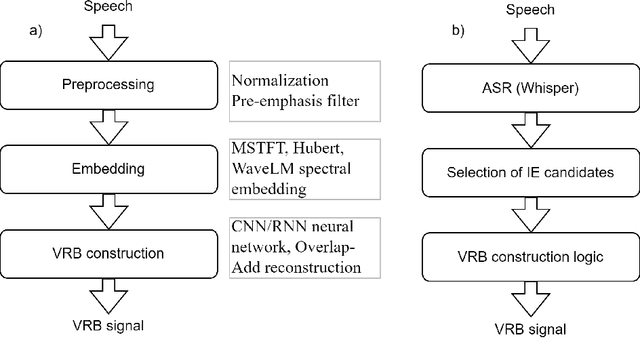
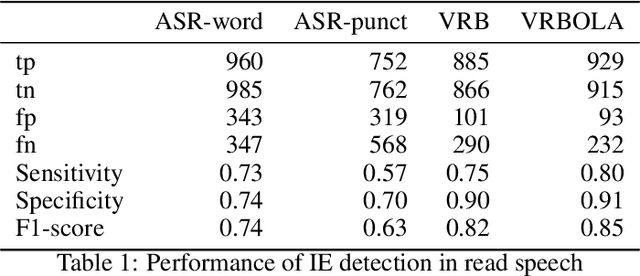
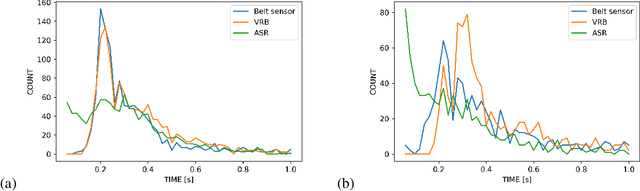
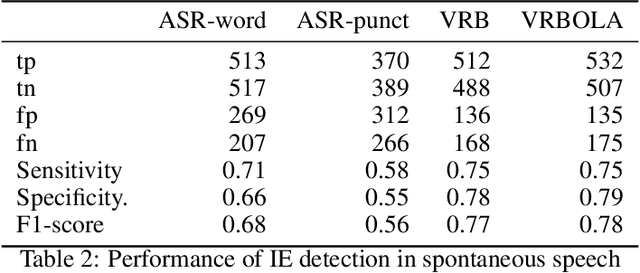
Respiratory chest belt sensor can be used to measure the respiratory rate and other respiratory health parameters. Virtual Respiratory Belt, VRB, algorithms estimate the belt sensor waveform from speech audio. In this paper we compare the detection of inspiration events (IE) from respiratory belt sensor data using a novel neural VRB algorithm and the detections based on time-aligned linguistic content. The results show the superiority of the VRB method over word pause detection or grammatical content segmentation. The comparison of the methods show that both read and spontaneous speech content has a significant amount of ungrammatical breathing, that is, breathing events that are not aligned with grammatically appropriate places in language. This study gives new insights into the development of VRB methods and adds to the general understanding of speech breathing behavior. Moreover, a new VRB method, VRBOLA, for the reconstruction of the continuous breathing waveform is demonstrated.
Differentially Private Adapters for Parameter Efficient Acoustic Modeling
May 19, 2023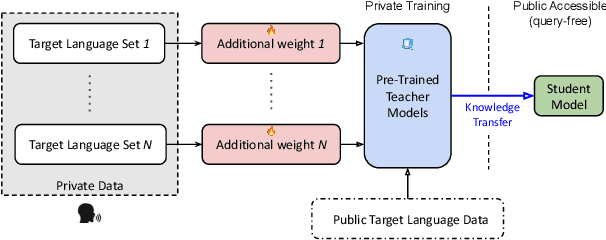
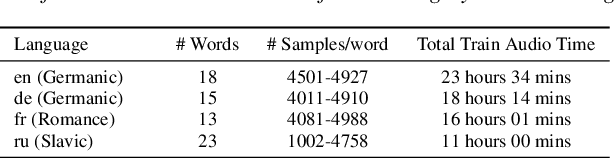
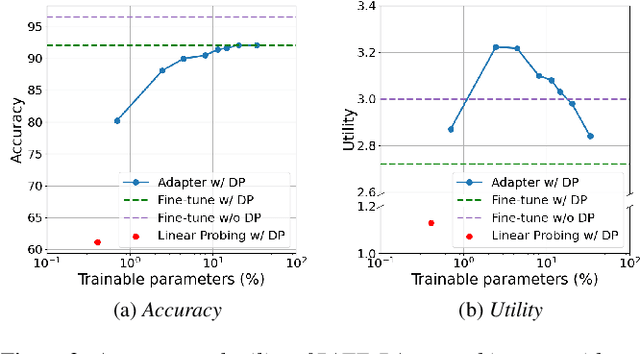
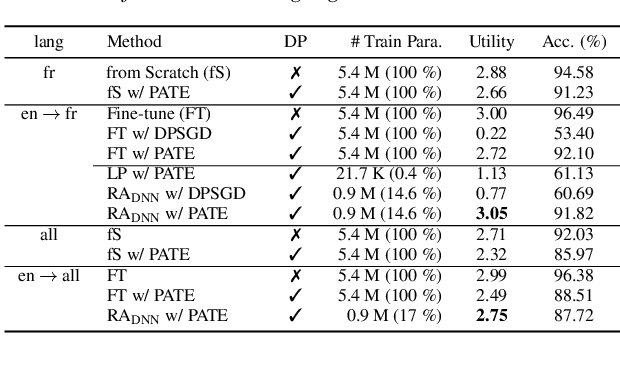
In this work, we devise a parameter-efficient solution to bring differential privacy (DP) guarantees into adaptation of a cross-lingual speech classifier. We investigate a new frozen pre-trained adaptation framework for DP-preserving speech modeling without full model fine-tuning. First, we introduce a noisy teacher-student ensemble into a conventional adaptation scheme leveraging a frozen pre-trained acoustic model and attain superior performance than DP-based stochastic gradient descent (DPSGD). Next, we insert residual adapters (RA) between layers of the frozen pre-trained acoustic model. The RAs reduce training cost and time significantly with a negligible performance drop. Evaluated on the open-access Multilingual Spoken Words (MLSW) dataset, our solution reduces the number of trainable parameters by 97.5% using the RAs with only a 4% performance drop with respect to fine-tuning the cross-lingual speech classifier while preserving DP guarantees.
Covariate-guided Bayesian mixture model for multivariate time series
Jan 03, 2023With rapid development of techniques to measure brain activity and structure, statistical methods for analyzing modern brain-imaging play an important role in the advancement of science. Imaging data that measure brain function are usually multivariate time series and are heterogeneous across both imaging sources and subjects, which lead to various statistical and computational challenges. In this paper, we propose a group-based method to cluster a collection of multivariate time series via a Bayesian mixture of smoothing splines. Our method assumes each multivariate time series is a mixture of multiple components with different mixing weights. Time-independent covariates are assumed to be associated with the mixture components and are incorporated via logistic weights of a mixture-of-experts model. We formulate this approach under a fully Bayesian framework using Gibbs sampling where the number of components is selected based on a deviance information criterion. The proposed method is compared to existing methods via simulation studies and is applied to a study on functional near-infrared spectroscopy (fNIRS), which aims to understand infant emotional reactivity and recovery from stress. The results reveal distinct patterns of brain activity, as well as associations between these patterns and selected covariates.
Object-Centric Voxelization of Dynamic Scenes via Inverse Neural Rendering
Apr 30, 2023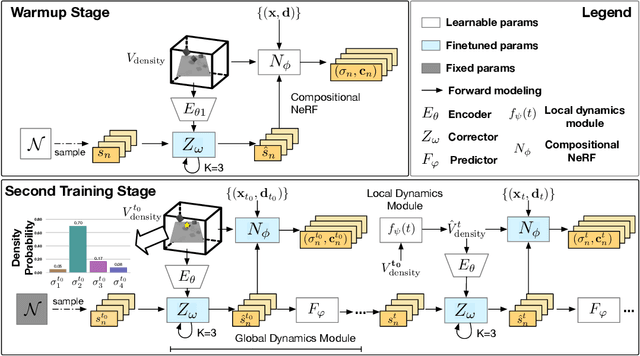
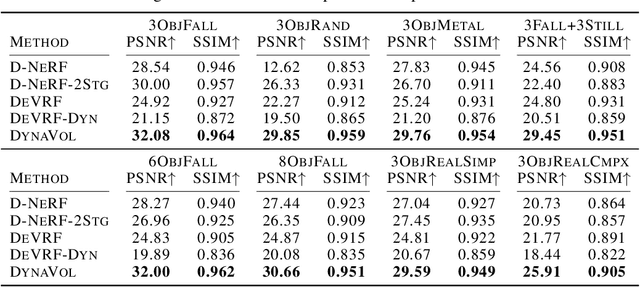
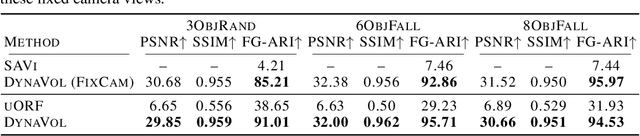
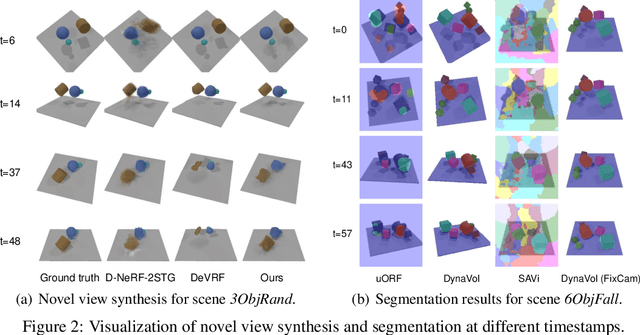
Understanding the compositional dynamics of the world in unsupervised 3D scenarios is challenging. Existing approaches either fail to make effective use of time cues or ignore the multi-view consistency of scene decomposition. In this paper, we propose DynaVol, an inverse neural rendering framework that provides a pilot study for learning time-varying volumetric representations for dynamic scenes with multiple entities (like objects). It has two main contributions. First, it maintains a time-dependent 3D grid, which dynamically and flexibly binds the spatial locations to different entities, thus encouraging the separation of information at a representational level. Second, our approach jointly learns grid-level local dynamics, object-level global dynamics, and the compositional neural radiance fields in an end-to-end architecture, thereby enhancing the spatiotemporal consistency of object-centric scene voxelization. We present a two-stage training scheme for DynaVol and validate its effectiveness on various benchmarks with multiple objects, diverse dynamics, and real-world shapes and textures. We present visualization at https://sites.google.com/view/dynavol-visual.
In-situ surface porosity prediction in DED (directed energy deposition) printed SS316L parts using multimodal sensor fusion
May 02, 2023This study aims to relate the time-frequency patterns of acoustic emission (AE) and other multi-modal sensor data collected in a hybrid directed energy deposition (DED) process to the pore formations at high spatial (0.5 mm) and time (< 1ms) resolutions. Adapting an explainable AI method in LIME (Local Interpretable Model-Agnostic Explanations), certain high-frequency waveform signatures of AE are to be attributed to two major pathways for pore formation in a DED process, namely, spatter events and insufficient fusion between adjacent printing tracks from low heat input. This approach opens an exciting possibility to predict, in real-time, the presence of a pore in every voxel (0.5 mm in size) as they are printed, a major leap forward compared to prior efforts. Synchronized multimodal sensor data including force, AE, vibration and temperature were gathered while an SS316L material sample was printed and subsequently machined. A deep convolution neural network classifier was used to identify the presence of pores on a voxel surface based on time-frequency patterns (spectrograms) of the sensor data collected during the process chain. The results suggest signals collected during DED were more sensitive compared to those from machining for detecting porosity in voxels (classification test accuracy of 87%). The underlying explanations drawn from LIME analysis suggests that energy captured in high frequency AE waveforms are 33% lower for porous voxels indicating a relatively lower laser-material interaction in the melt pool, and hence insufficient fusion and poor overlap between adjacent printing tracks. The porous voxels for which spatter events were prevalent during printing had about 27% higher energy contents in the high frequency AE band compared to other porous voxels. These signatures from AE signal can further the understanding of pore formation from spatter and insufficient fusion.