 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
In Situ Framework for Coupling Simulation and Machine Learning with Application to CFD
Jun 22, 2023
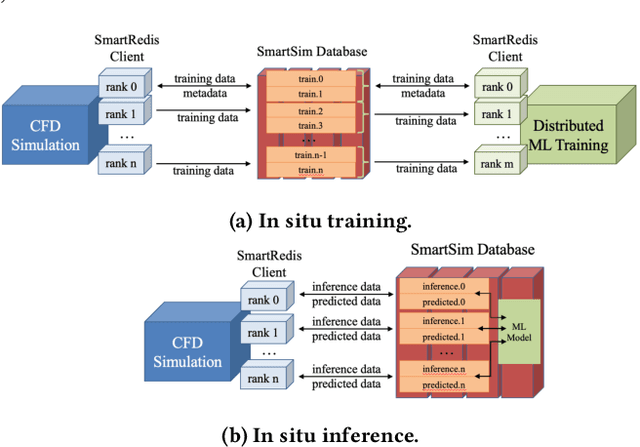
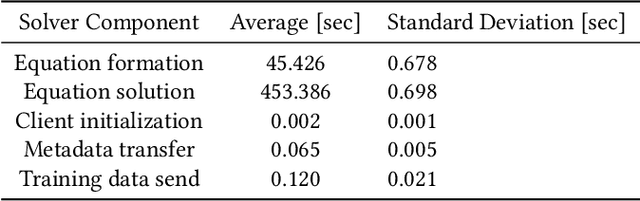
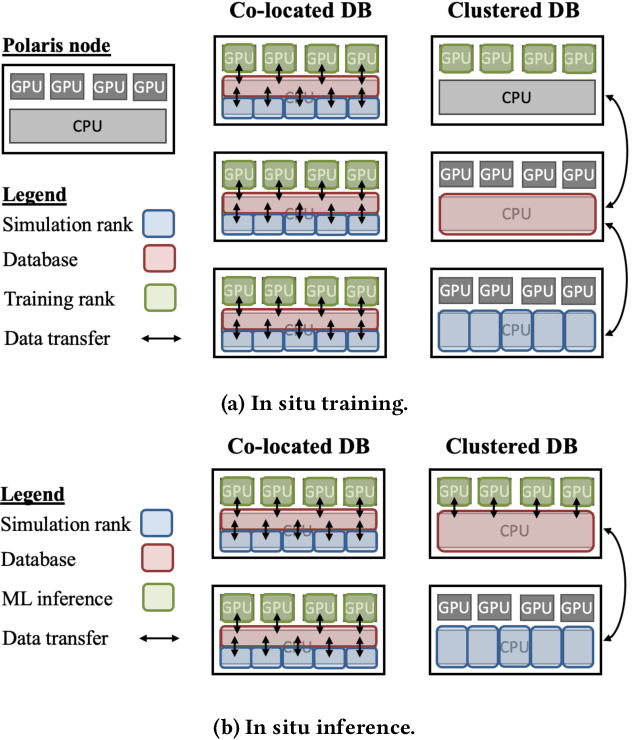
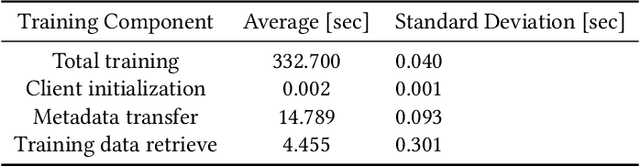
Recent years have seen many successful applications of machine learning (ML) to facilitate fluid dynamic computations. As simulations grow, generating new training datasets for traditional offline learning creates I/O and storage bottlenecks. Additionally, performing inference at runtime requires non-trivial coupling of ML framework libraries with simulation codes. This work offers a solution to both limitations by simplifying this coupling and enabling in situ training and inference workflows on heterogeneous clusters. Leveraging SmartSim, the presented framework deploys a database to store data and ML models in memory, thus circumventing the file system. On the Polaris supercomputer, we demonstrate perfect scaling efficiency to the full machine size of the data transfer and inference costs thanks to a novel co-located deployment of the database. Moreover, we train an autoencoder in situ from a turbulent flow simulation, showing that the framework overhead is negligible relative to a solver time step and training epoch.
Iteratively Preconditioned Gradient-Descent Approach for Moving Horizon Estimation Problems
Jun 22, 2023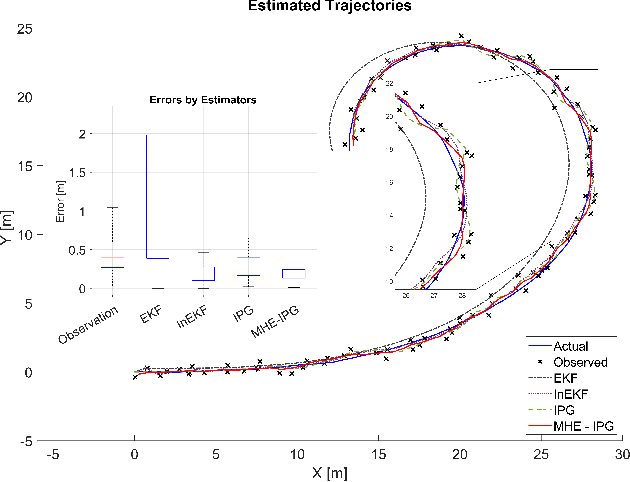
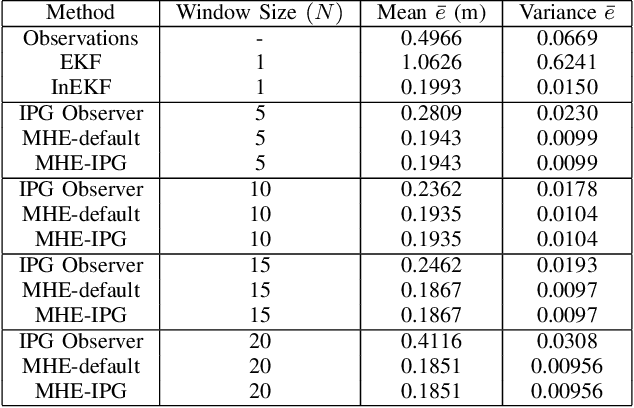
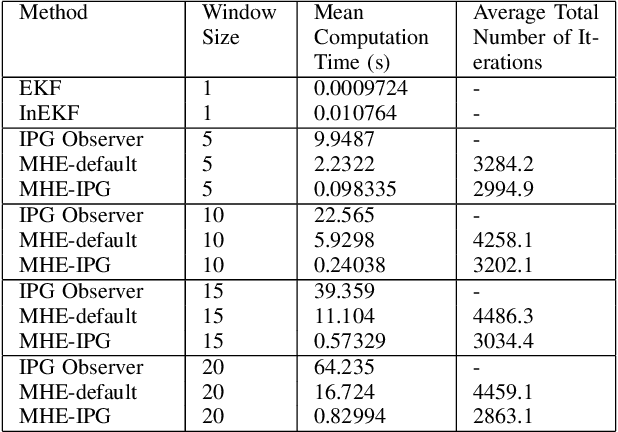
Moving horizon estimation (MHE) is a widely studied state estimation approach in several practical applications. In the MHE problem, the state estimates are obtained via the solution of an approximated nonlinear optimization problem. However, this optimization step is known to be computationally complex. Given this limitation, this paper investigates the idea of iteratively preconditioned gradient-descent (IPG) to solve MHE problem with the aim of an improved performance than the existing solution techniques. To our knowledge, the preconditioning technique is used for the first time in this paper to reduce the computational cost and accelerate the crucial optimization step for MHE. The convergence guarantee of the proposed iterative approach for a class of MHE problems is presented. Additionally, sufficient conditions for the MHE problem to be convex are also derived. Finally, the proposed method is implemented on a unicycle localization example. The simulation results demonstrate that the proposed approach can achieve better accuracy with reduced computational costs.
Improving Log-Cumulant Based Estimation of Roughness Information in SAR imagery
Jun 22, 2023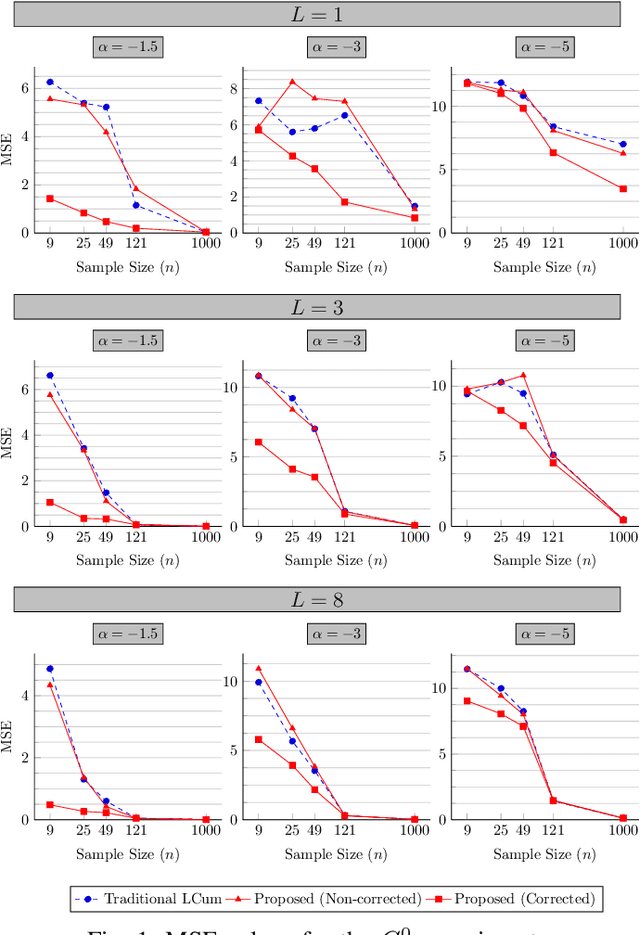
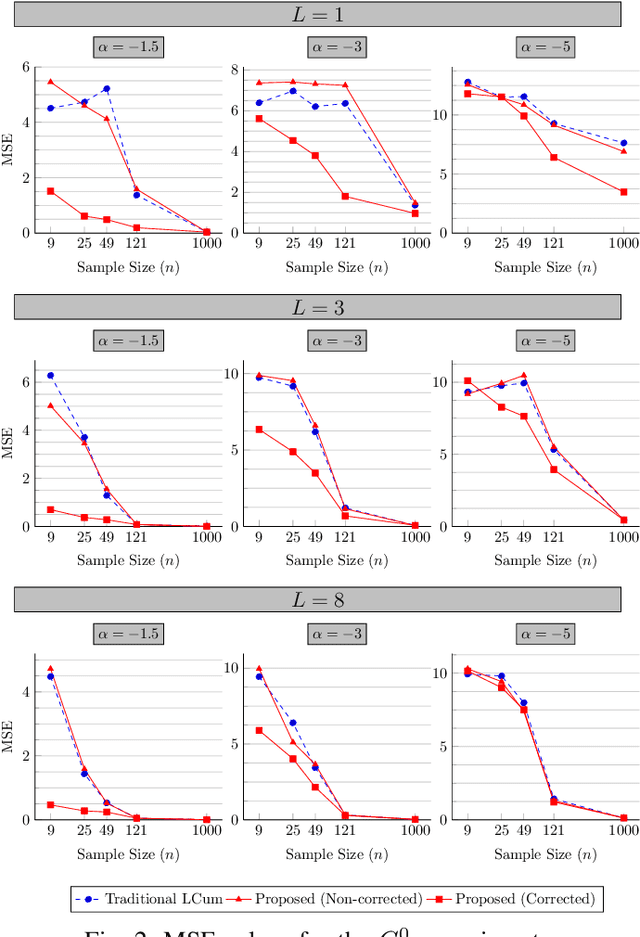

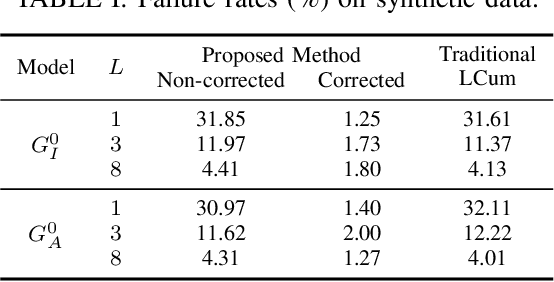
Synthetic Aperture Radar (SAR) image understanding is crucial in remote sensing applications, but it is hindered by its intrinsic noise contamination, called speckle. Sophisticated statistical models, such as the $\mathcal{G}^0$ family of distributions, have been employed to SAR data and many of the current advancements in processing this imagery have been accomplished through extracting information from these models. In this paper, we propose improvements to parameter estimation in $\mathcal{G}^0$ distributions using the Method of Log-Cumulants. First, using Bayesian modeling, we construct that regularly produce reliable roughness estimates under both $\mathcal{G}^0_A$ and $\mathcal{G}^0_I$ models. Second, we make use of an approximation of the Trigamma function to compute the estimated roughness in constant time, making it considerably faster than the existing method for this task. Finally, we show how we can use this method to achieve fast and reliable SAR image understanding based on roughness information.
Label-efficient Time Series Representation Learning: A Review
Feb 13, 2023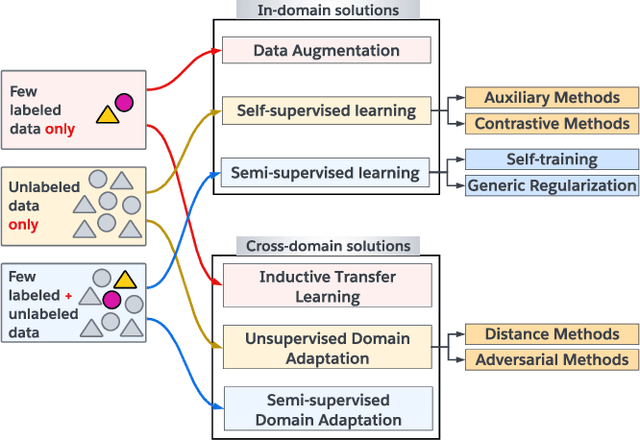
The scarcity of labeled data is one of the main challenges of applying deep learning models on time series data in the real world. Therefore, several approaches, e.g., transfer learning, self-supervised learning, and semi-supervised learning, have been recently developed to promote the learning capability of deep learning models from the limited time series labels. In this survey, for the first time, we provide a novel taxonomy to categorize existing approaches that address the scarcity of labeled data problem in time series data based on their reliance on external data sources. Moreover, we present a review of the recent advances in each approach and conclude the limitations of the current works and provide future directions that could yield better progress in the field.
Learned spatial data partitioning
Jun 19, 2023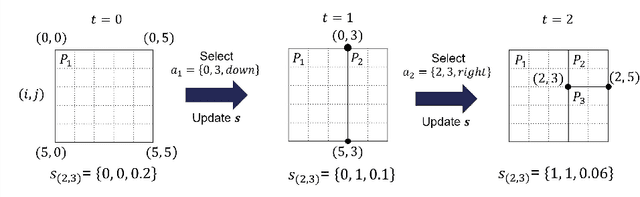
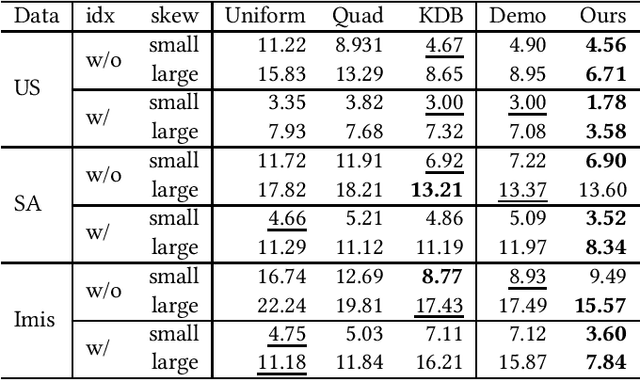
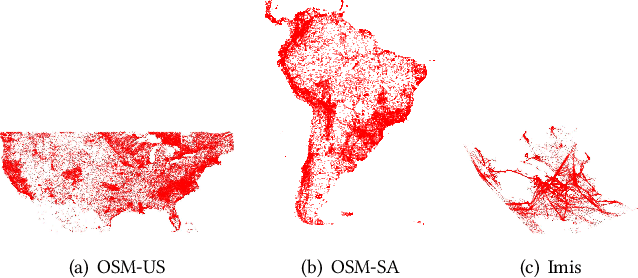
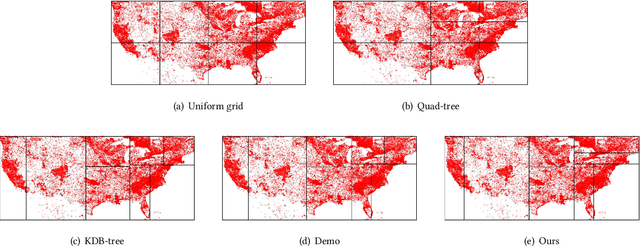
Due to the significant increase in the size of spatial data, it is essential to use distributed parallel processing systems to efficiently analyze spatial data. In this paper, we first study learned spatial data partitioning, which effectively assigns groups of big spatial data to computers based on locations of data by using machine learning techniques. We formalize spatial data partitioning in the context of reinforcement learning and develop a novel deep reinforcement learning algorithm. Our learning algorithm leverages features of spatial data partitioning and prunes ineffective learning processes to find optimal partitions efficiently. Our experimental study, which uses Apache Sedona and real-world spatial data, demonstrates that our method efficiently finds partitions for accelerating distance join queries and reduces the workload run time by up to 59.4%.
Weight Compander: A Simple Weight Reparameterization for Regularization
Jun 29, 2023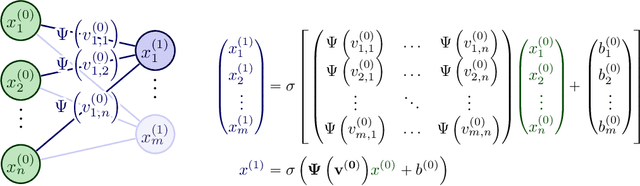
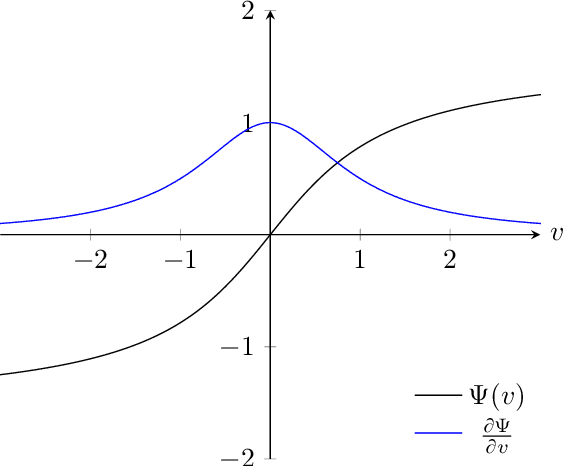
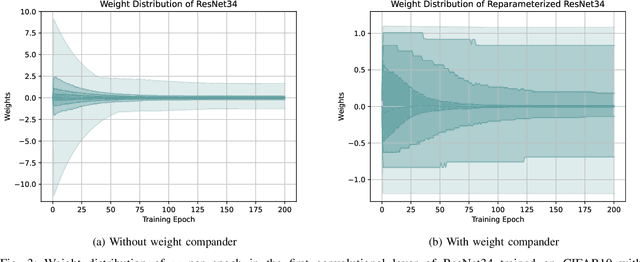
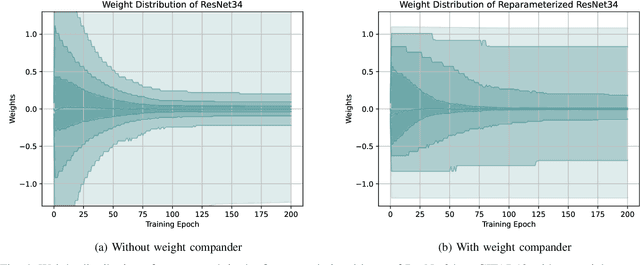
Regularization is a set of techniques that are used to improve the generalization ability of deep neural networks. In this paper, we introduce weight compander (WC), a novel effective method to improve generalization by reparameterizing each weight in deep neural networks using a nonlinear function. It is a general, intuitive, cheap and easy to implement method, which can be combined with various other regularization techniques. Large weights in deep neural networks are a sign of a more complex network that is overfitted to the training data. Moreover, regularized networks tend to have a greater range of weights around zero with fewer weights centered at zero. We introduce a weight reparameterization function which is applied to each weight and implicitly reduces overfitting by restricting the magnitude of the weights while forcing them away from zero at the same time. This leads to a more democratic decision-making in the network. Firstly, individual weights cannot have too much influence in the prediction process due to the restriction of their magnitude. Secondly, more weights are used in the prediction process, since they are forced away from zero during the training. This promotes the extraction of more features from the input data and increases the level of weight redundancy, which makes the network less sensitive to statistical differences between training and test data. We extend our method to learn the hyperparameters of the introduced weight reparameterization function. This avoids hyperparameter search and gives the network the opportunity to align the weight reparameterization with the training progress. We show experimentally that using weight compander in addition to standard regularization methods improves the performance of neural networks.
* Accepted by The International Joint Conference on Neural Network (IJCNN) 2023
Patterns Detection in Glucose Time Series by Domain Transformations and Deep Learning
Mar 30, 2023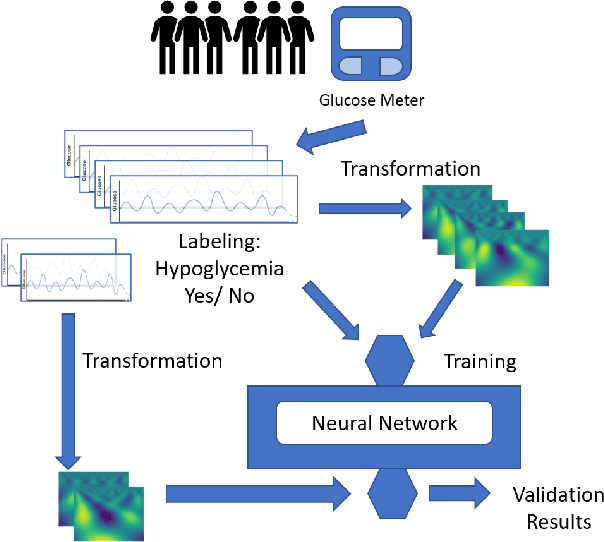
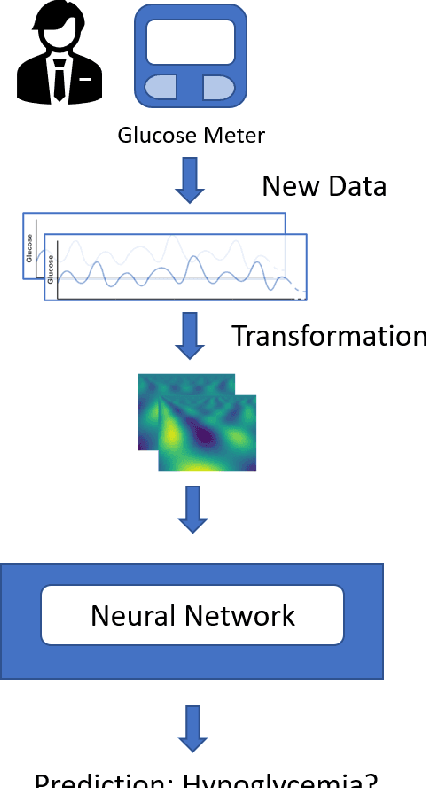
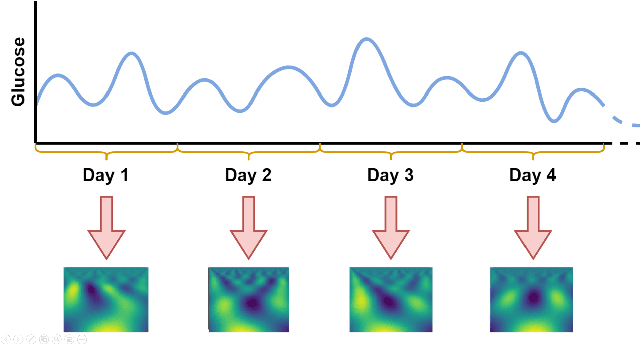
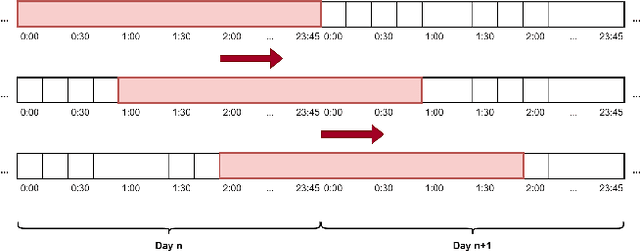
People with diabetes have to manage their blood glucose level to keep it within an appropriate range. Predicting whether future glucose values will be outside the healthy threshold is of vital importance in order to take corrective actions to avoid potential health damage. In this paper we describe our research with the aim of predicting the future behavior of blood glucose levels, so that hypoglycemic events may be anticipated. The approach of this work is the application of transformation functions on glucose time series, and their use in convolutional neural networks. We have tested our proposed method using real data from 4 different diabetes patients with promising results.
Estimating Treatment Effects in Continuous Time with Hidden Confounders
Feb 21, 2023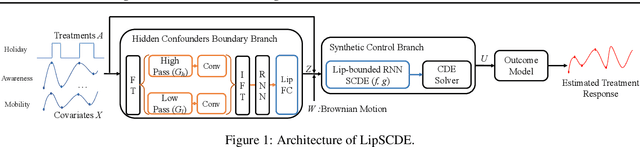
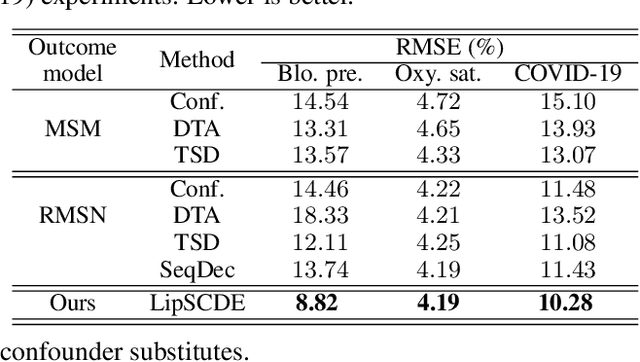
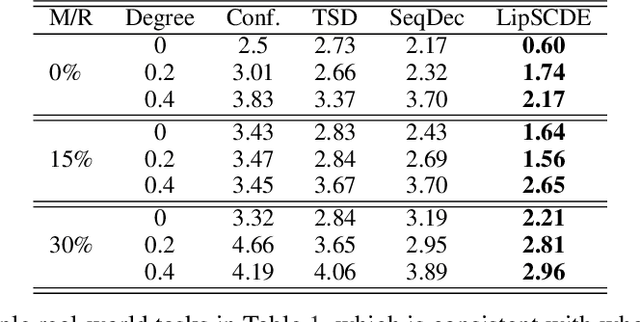
Estimating treatment effects plays a crucial role in causal inference, having many real-world applications like policy analysis and decision making. Nevertheless, estimating treatment effects in the longitudinal setting in the presence of hidden confounders remains an extremely challenging problem. Recently, there is a growing body of work attempting to obtain unbiased ITE estimates from time-dynamic observational data by ignoring the possible existence of hidden confounders. Additionally, many existing works handling hidden confounders are not applicable for continuous-time settings. In this paper, we extend the line of work focusing on deconfounding in the dynamic time setting in the presence of hidden confounders. We leverage recent advancements in neural differential equations to build a latent factor model using a stochastic controlled differential equation and Lipschitz constrained convolutional operation in order to continuously incorporate information about ongoing interventions and irregularly sampled observations. Experiments on both synthetic and real-world datasets highlight the promise of continuous time methods for estimating treatment effects in the presence of hidden confounders.
Self-supervised Equality Embedded Deep Lagrange Dual for Approximate Constrained Optimization
Jun 11, 2023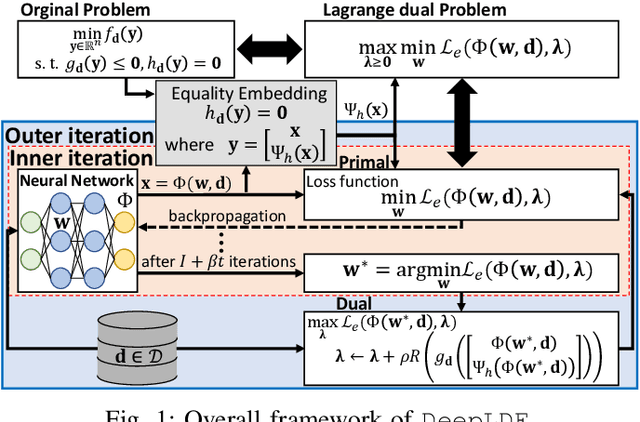
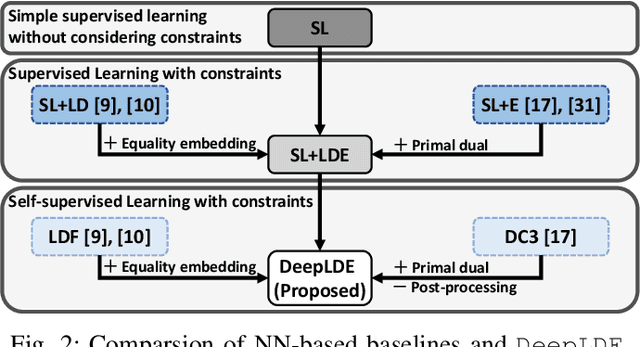
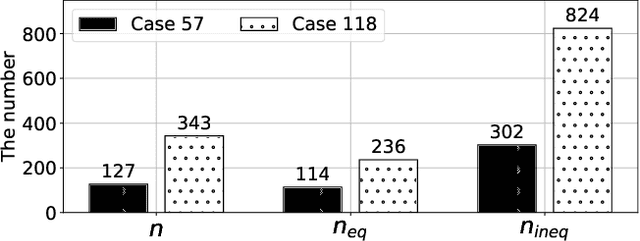
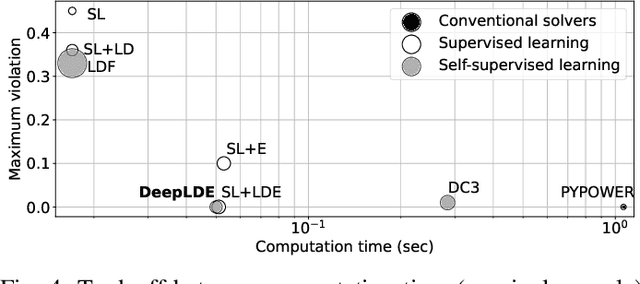
Conventional solvers are often computationally expensive for constrained optimization, particularly in large-scale and time-critical problems. While this leads to a growing interest in using neural networks (NNs) as fast optimal solution approximators, incorporating the constraints with NNs is challenging. In this regard, we propose deep Lagrange dual with equality embedding (DeepLDE), a framework that learns to find an optimal solution without using labels. To ensure feasible solutions, we embed equality constraints into the NNs and train the NNs using the primal-dual method to impose inequality constraints. Furthermore, we prove the convergence of DeepLDE and show that the primal-dual learning method alone cannot ensure equality constraints without the help of equality embedding. Simulation results on convex, non-convex, and AC optimal power flow (AC-OPF) problems show that the proposed DeepLDE achieves the smallest optimality gap among all the NN-based approaches while always ensuring feasible solutions. Furthermore, the computation time of the proposed method is about 5 to 250 times faster than DC3 and the conventional solvers in solving constrained convex, non-convex optimization, and/or AC-OPF.
Binary domain generalization for sparsifying binary neural networks
Jun 23, 2023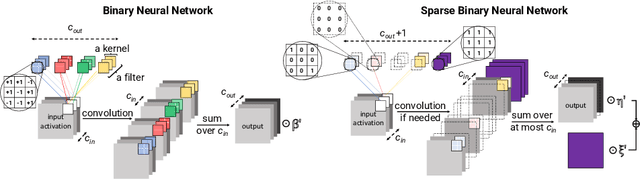

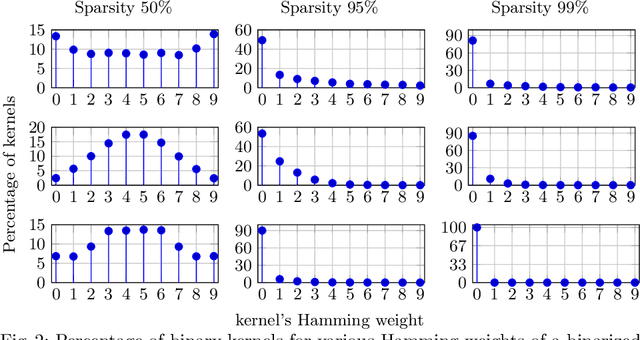
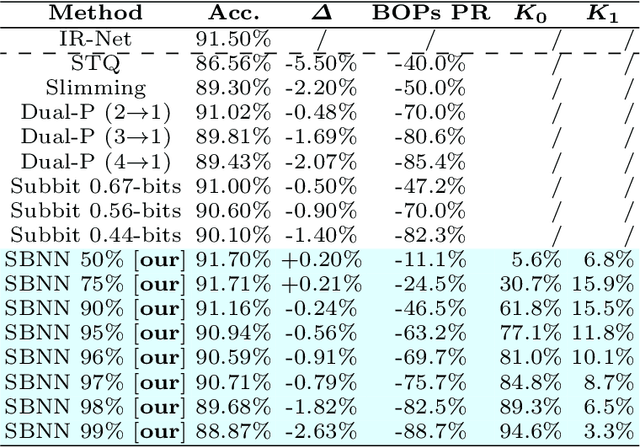
Binary neural networks (BNNs) are an attractive solution for developing and deploying deep neural network (DNN)-based applications in resource constrained devices. Despite their success, BNNs still suffer from a fixed and limited compression factor that may be explained by the fact that existing pruning methods for full-precision DNNs cannot be directly applied to BNNs. In fact, weight pruning of BNNs leads to performance degradation, which suggests that the standard binarization domain of BNNs is not well adapted for the task. This work proposes a novel more general binary domain that extends the standard binary one that is more robust to pruning techniques, thus guaranteeing improved compression and avoiding severe performance losses. We demonstrate a closed-form solution for quantizing the weights of a full-precision network into the proposed binary domain. Finally, we show the flexibility of our method, which can be combined with other pruning strategies. Experiments over CIFAR-10 and CIFAR-100 demonstrate that the novel approach is able to generate efficient sparse networks with reduced memory usage and run-time latency, while maintaining performance.