 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTangram: Unlocking Non-Uniform KV Cache for Efficient Multi-turn LLM Serving
Jun 04, 2026Multi-turn Large Language Model (LLM) serving is critical for consistent user experiences, yet the linear growth of the Key-Value (KV) cache imposes significant pressure on GPU memory and bandwidth. Non-uniform KV compression effectively preserves more information by considering the individual importance of each KV cache. However, such KV cache heterogeneity introduces various systemic challenges - including memory fragmentation, scheduling complexities, and diminished kernel utilization - which collectively lead to significant inefficiencies in existing LLM serving systems. To overcome these challenges, we present Tangram, a novel serving system designed to make Non-uniform KV caches practical. Tangram addresses systemic inefficiencies through three core techniques: (1) Deterministic Budget Allocation assigns a static memory footprint to each head based on its intrinsic pattern, entirely eliminating dynamic scheduling overhead and prefill stalls; (2) Head Group Page clusters attention heads with similar retention demands and manages them with independent, vectorized page tables, thereby maximizing physical memory reclamation; and (3) Ahead-of-Time (AOT) Load Balancing leverages static budget profiles to ensure uniform GPU utilization without runtime overhead. Experimental results show that Tangram improves throughput by up to 2.6x compared to existing baselines, while fully preserving model accuracy. Our implementation is publicly available at https://github.com/aiha-lab/TANGRAM.
LUMINA: A Grid Foundation Model for Benchmarking AC Optimal Power Flow Surrogate Learning
May 04, 2026AC optimal power flow (ACOPF) is foundational yet computationally expensive in power grid operations, driving learning-based surrogates for large-scale grid analysis. These surrogates, however, often fail to generalize across network topologies, a critical gap for deployment on grids not seen during training and for routine operational what-if studies. We introduce LUMINA-Bench, a comprehensive benchmark suite for ACOPF surrogate learning covering multi-topology pretraining, transfer, and adaptation. The benchmark evaluates homogeneous and heterogeneous architectures under single- and multi-topology learning settings using unified metrics that capture both predictive accuracy and physics-informed constraint violations. We additionally compare constraint-aware training objectives, including MSE, augmented Lagrangian, and violation-based Lagrangian losses, to characterize accuracy-robustness trade-offs across settings. Data processing, training, and evaluation frameworks are open-sourced as the LUMINA suite to support reproducibility and accelerate future research on feasibility-aware OPF surrogates.
LUMINA: Foundation Models for Topology Transferable ACOPF
Mar 04, 2026Foundation models in general promise to accelerate scientific computation by learning reusable representations across problem instances, yet constrained scientific systems, where predictions must satisfy physical laws and safety limits, pose unique challenges that stress conventional training paradigms. We derive design principles for constrained scientific foundation models through systematic investigation of AC optimal power flow (ACOPF), a representative optimization problem in power grid operations where power balance equations and operational constraints are non-negotiable. Through controlled experiments spanning architectures, training objectives, and system diversity, we extract three empirically grounded principles governing scientific foundation model design. These principles characterize three design trade-offs: learning physics-invariant representations while respecting system-specific constraints, optimizing accuracy while ensuring constraint satisfaction, and ensuring reliability in high-impact operating regimes. We present the LUMINA framework, including data processing and training pipelines to support reproducible research on physics-informed, feasibility-aware foundation models across scientific applications.
Self-supervised Equality Embedded Deep Lagrange Dual for Approximate Constrained Optimization
Jul 02, 2023Conventional solvers are often computationally expensive for constrained optimization, particularly in large-scale and time-critical problems. While this leads to a growing interest in using neural networks (NNs) as fast optimal solution approximators, incorporating the constraints with NNs is challenging. In this regard, we propose deep Lagrange dual with equality embedding (DeepLDE), a framework that learns to find an optimal solution without using labels. To ensure feasible solutions, we embed equality constraints into the NNs and train the NNs using the primal-dual method to impose inequality constraints. Furthermore, we prove the convergence of DeepLDE and show that the primal-dual learning method alone cannot ensure equality constraints without the help of equality embedding. Simulation results on convex, non-convex, and AC optimal power flow (AC-OPF) problems show that the proposed DeepLDE achieves the smallest optimality gap among all the NN-based approaches while always ensuring feasible solutions. Furthermore, the computation time of the proposed method is about 5 to 250 times faster than DC3 and the conventional solvers in solving constrained convex, non-convex optimization, and/or AC-OPF.
Markov Chain Score Ascent: A Unifying Framework of Variational Inference with Markovian Gradients
Jun 13, 2022
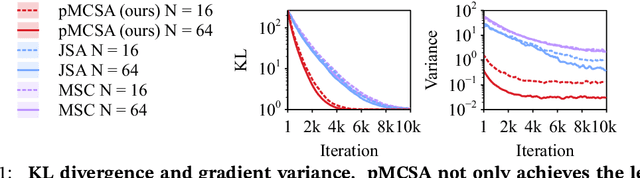
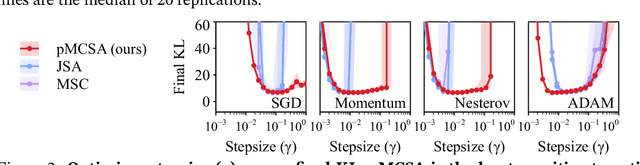
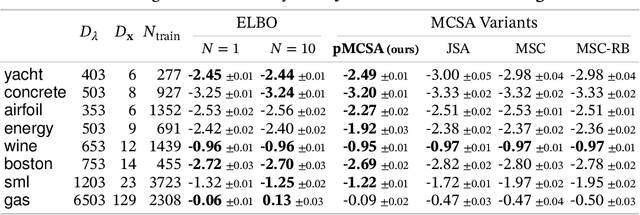
Minimizing the inclusive Kullback-Leibler (KL) divergence with stochastic gradient descent (SGD) is challenging since its gradient is defined as an integral over the posterior. Recently, multiple methods have been proposed to run SGD with biased gradient estimates obtained from a Markov chain. This paper provides the first non-asymptotic convergence analysis of these methods by establishing their mixing rate and gradient variance. To do this, we demonstrate that these methods-which we collectively refer to as Markov chain score ascent (MCSA) methods-can be cast as special cases of the Markov chain gradient descent framework. Furthermore, by leveraging this new understanding, we develop a novel MCSA scheme, parallel MCSA (pMCSA), that achieves a tighter bound on the gradient variance. We demonstrate that this improved theoretical result translates to superior empirical performance.