 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Counterfactual Graph Transformer for Traffic Flow Prediction
Aug 01, 2023
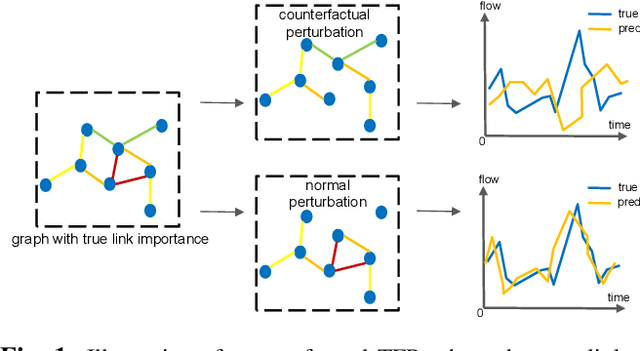
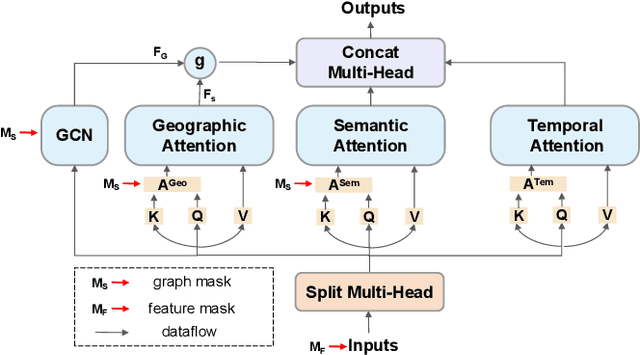
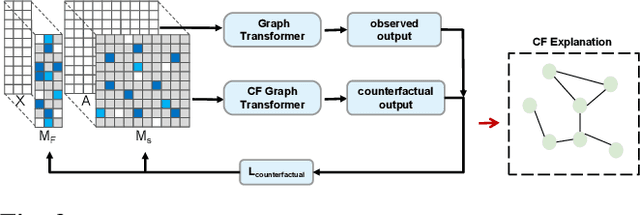
Traffic flow prediction (TFP) is a fundamental problem of the Intelligent Transportation System (ITS), as it models the latent spatial-temporal dependency of traffic flow for potential congestion prediction. Recent graph-based models with multiple kinds of attention mechanisms have achieved promising performance. However, existing methods for traffic flow prediction tend to inherit the bias pattern from the dataset and lack interpretability. To this end, we propose a Counterfactual Graph Transformer (CGT) model with an instance-level explainer (e.g., finding the important subgraphs) specifically designed for TFP. We design a perturbation mask generator over input sensor features at the time dimension and the graph structure on the graph transformer module to obtain spatial and temporal counterfactual explanations. By searching the optimal perturbation masks on the input data feature and graph structures, we can obtain the concise and dominant data or graph edge links for the subsequent TFP task. After re-training the utilized graph transformer model after counterfactual perturbation, we can obtain improved and interpretable traffic flow prediction. Extensive results on three real-world public datasets show that CGT can produce reliable explanations and is promising for traffic flow prediction.
Phase Diverse Phase Retrieval for Microscopy: Comparison of Gaussian and Poisson Approaches
Aug 01, 2023Phase diversity is a widefield aberration correction method that uses multiple images to estimate the phase aberration at the pupil plane of an imaging system by solving an optimization problem. This estimated aberration can then be used to deconvolve the aberrated image or to reacquire it with aberration corrections applied to a deformable mirror. The optimization problem for aberration estimation has been formulated for both Gaussian and Poisson noise models but the Poisson model has never been studied in microscopy nor compared with the Gaussian model. Here, the Gaussian- and Poisson-based estimation algorithms are implemented and compared for widefield microscopy in simulation. The Poisson algorithm is found to match or outperform the Gaussian algorithm in a variety of situations, and converges in a similar or decreased amount of time. The Gaussian algorithm does perform better in low-light regimes when image noise is dominated by additive Gaussian noise. The Poisson algorithm is also found to be more robust to the effects of spatially variant aberration and phase noise. Finally, the relative advantages of re-acquisition with aberration correction and deconvolution with aberrated point spread functions are compared.
Epistemic Planning for Heterogeneous Robotic Systems
Aug 01, 2023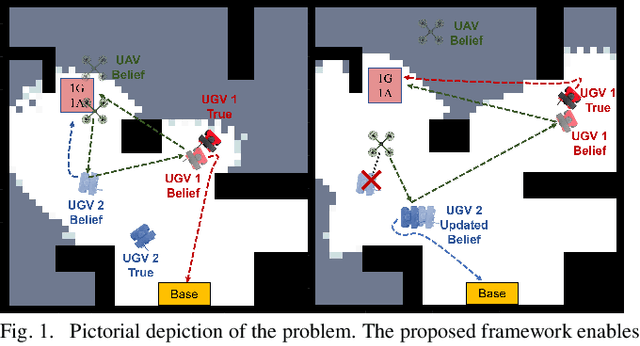
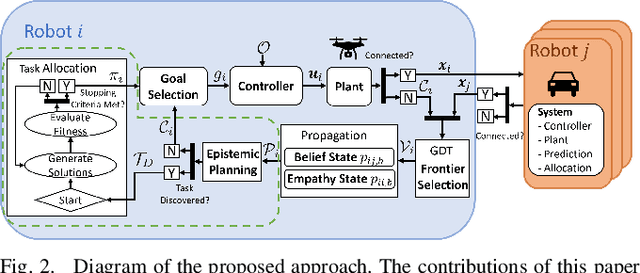
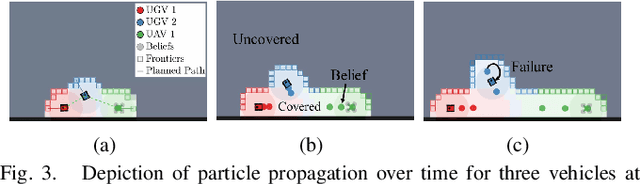
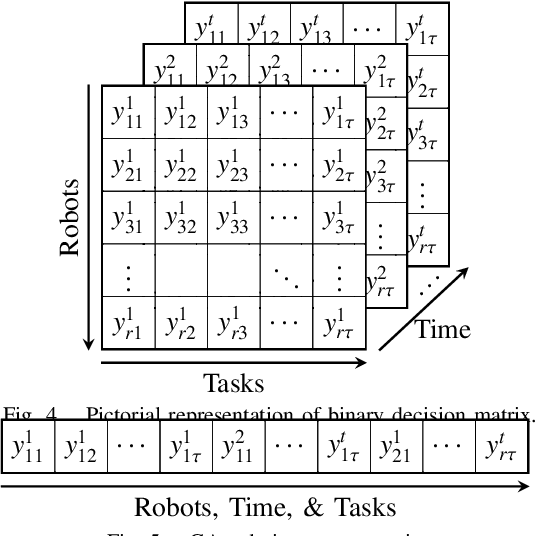
In applications such as search and rescue or disaster relief, heterogeneous multi-robot systems (MRS) can provide significant advantages for complex objectives that require a suite of capabilities. However, within these application spaces, communication is often unreliable, causing inefficiencies or outright failures to arise in most MRS algorithms. Many researchers tackle this problem by requiring all robots to either maintain communication using proximity constraints or assuming that all robots will execute a predetermined plan over long periods of disconnection. The latter method allows for higher levels of efficiency in a MRS, but failures and environmental uncertainties can have cascading effects across the system, especially when a mission objective is complex or time-sensitive. To solve this, we propose an epistemic planning framework that allows robots to reason about the system state, leverage heterogeneous system makeups, and optimize information dissemination to disconnected neighbors. Dynamic epistemic logic formalizes the propagation of belief states, and epistemic task allocation and gossip is accomplished via a mixed integer program using the belief states for utility predictions and planning. The proposed framework is validated using simulations and experiments with heterogeneous vehicles.
Hybrid-SORT: Weak Cues Matter for Online Multi-Object Tracking
Aug 01, 2023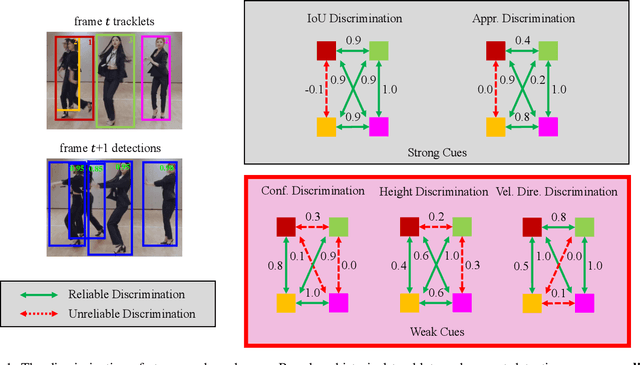
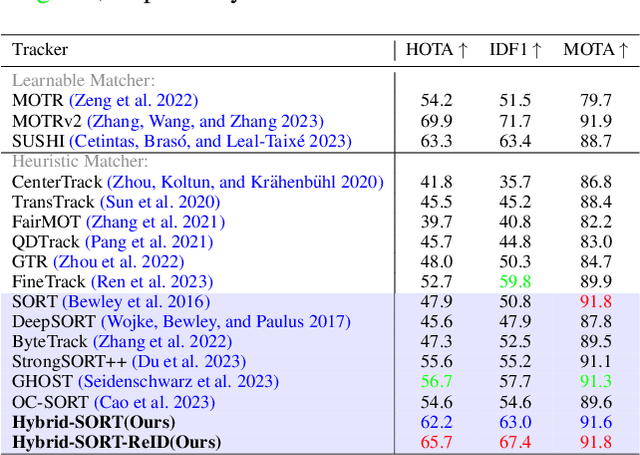
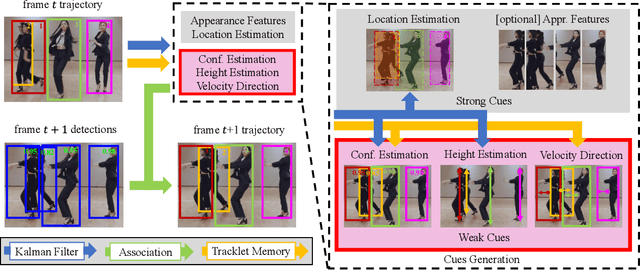
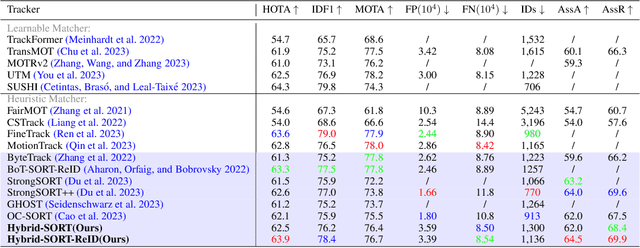
Multi-Object Tracking (MOT) aims to detect and associate all desired objects across frames. Most methods accomplish the task by explicitly or implicitly leveraging strong cues (i.e., spatial and appearance information), which exhibit powerful instance-level discrimination. However, when object occlusion and clustering occur, both spatial and appearance information will become ambiguous simultaneously due to the high overlap between objects. In this paper, we demonstrate that this long-standing challenge in MOT can be efficiently and effectively resolved by incorporating weak cues to compensate for strong cues. Along with velocity direction, we introduce the confidence state and height state as potential weak cues. With superior performance, our method still maintains Simple, Online and Real-Time (SORT) characteristics. Furthermore, our method shows strong generalization for diverse trackers and scenarios in a plug-and-play and training-free manner. Significant and consistent improvements are observed when applying our method to 5 different representative trackers. Further, by leveraging both strong and weak cues, our method Hybrid-SORT achieves superior performance on diverse benchmarks, including MOT17, MOT20, and especially DanceTrack where interaction and occlusion are frequent and severe. The code and models are available at https://github.com/ymzis69/HybirdSORT.
AOSoar: Autonomous Orographic Soaring of a Micro Air Vehicle
Aug 01, 2023
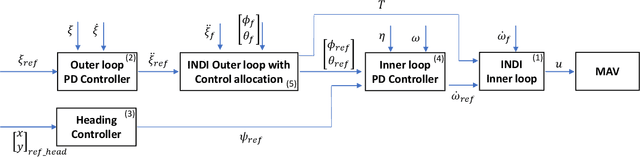


Utilizing wind hovering techniques of soaring birds can save energy expenditure and improve the flight endurance of micro air vehicles (MAVs). Here, we present a novel method for fully autonomous orographic soaring without a priori knowledge of the wind field. Specifically, we devise an Incremental Nonlinear Dynamic Inversion (INDI) controller with control allocation, adapting it for autonomous soaring. This allows for both soaring and the use of the throttle if necessary, without changing any gain or parameter during the flight. Furthermore, we propose a simulated-annealing-based optimization method to search for soaring positions. This enables for the first time an MAV to autonomously find a feasible soaring position while minimizing throttle usage and other control efforts. Autonomous orographic soaring was performed in the wind tunnel. The wind speed and incline of a ramp were changed during the soaring flight. The MAV was able to perform autonomous orographic soaring for flight times of up to 30 minutes. The mean throttle usage was only 0.25% for the entire soaring flight, whereas normal powered flight requires 38%. Also, it was shown that the MAV can find a new soaring spot when the wind field changes during the flight.
CliniDigest: A Case Study in Large Language Model Based Large-Scale Summarization of Clinical Trial Descriptions
Jul 31, 2023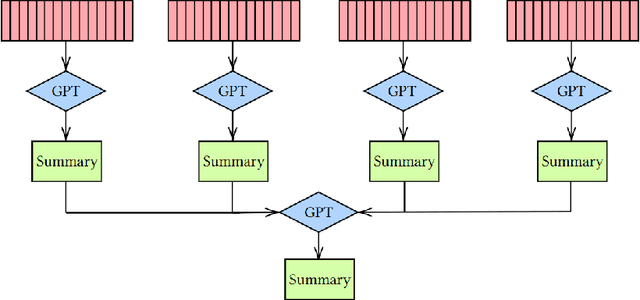

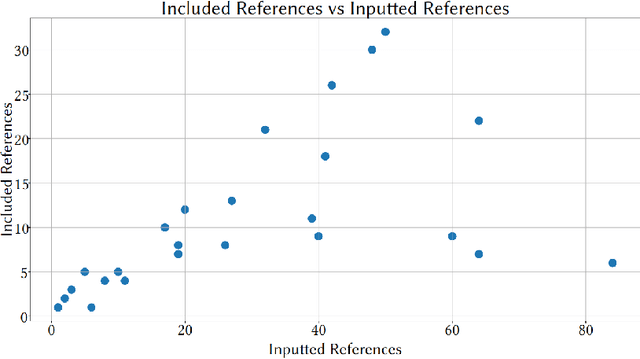
A clinical trial is a study that evaluates new biomedical interventions. To design new trials, researchers draw inspiration from those current and completed. In 2022, there were on average more than 100 clinical trials submitted to ClinicalTrials.gov every day, with each trial having a mean of approximately 1500 words [1]. This makes it nearly impossible to keep up to date. To mitigate this issue, we have created a batch clinical trial summarizer called CliniDigest using GPT-3.5. CliniDigest is, to our knowledge, the first tool able to provide real-time, truthful, and comprehensive summaries of clinical trials. CliniDigest can reduce up to 85 clinical trial descriptions (approximately 10,500 words) into a concise 200-word summary with references and limited hallucinations. We have tested CliniDigest on its ability to summarize 457 trials divided across 27 medical subdomains. For each field, CliniDigest generates summaries of $\mu=153,\ \sigma=69 $ words, each of which utilizes $\mu=54\%,\ \sigma=30\% $ of the sources. A more comprehensive evaluation is planned and outlined in this paper.
An Efficient Shapley Value Computation for the Naive Bayes Classifier
Jul 31, 2023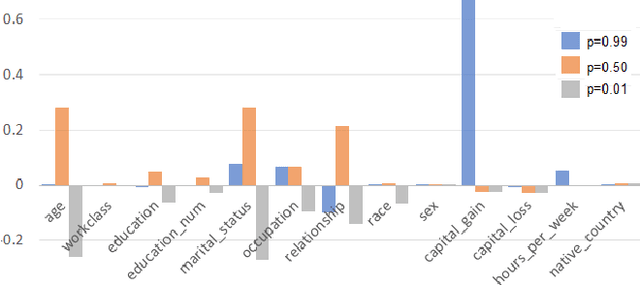
Variable selection or importance measurement of input variables to a machine learning model has become the focus of much research. It is no longer enough to have a good model, one also must explain its decisions. This is why there are so many intelligibility algorithms available today. Among them, Shapley value estimation algorithms are intelligibility methods based on cooperative game theory. In the case of the naive Bayes classifier, and to our knowledge, there is no ``analytical" formulation of Shapley values. This article proposes an exact analytic expression of Shapley values in the special case of the naive Bayes Classifier. We analytically compare this Shapley proposal, to another frequently used indicator, the Weight of Evidence (WoE) and provide an empirical comparison of our proposal with (i) the WoE and (ii) KernelShap results on real world datasets, discussing similar and dissimilar results. The results show that our Shapley proposal for the naive Bayes classifier provides informative results with low algorithmic complexity so that it can be used on very large datasets with extremely low computation time.
LP-MusicCaps: LLM-Based Pseudo Music Captioning
Jul 31, 2023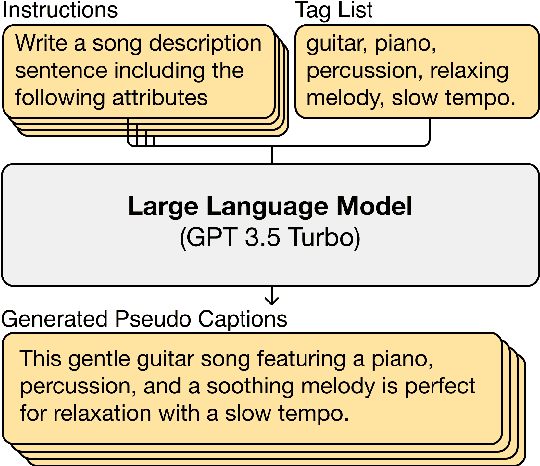

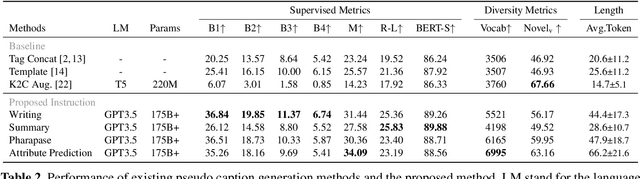
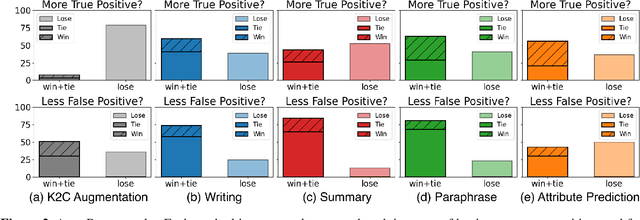
Automatic music captioning, which generates natural language descriptions for given music tracks, holds significant potential for enhancing the understanding and organization of large volumes of musical data. Despite its importance, researchers face challenges due to the costly and time-consuming collection process of existing music-language datasets, which are limited in size. To address this data scarcity issue, we propose the use of large language models (LLMs) to artificially generate the description sentences from large-scale tag datasets. This results in approximately 2.2M captions paired with 0.5M audio clips. We term it Large Language Model based Pseudo music caption dataset, shortly, LP-MusicCaps. We conduct a systemic evaluation of the large-scale music captioning dataset with various quantitative evaluation metrics used in the field of natural language processing as well as human evaluation. In addition, we trained a transformer-based music captioning model with the dataset and evaluated it under zero-shot and transfer-learning settings. The results demonstrate that our proposed approach outperforms the supervised baseline model.
SpatialNet: Extensively Learning Spatial Information for Multichannel Joint Speech Separation, Denoising and Dereverberation
Jul 31, 2023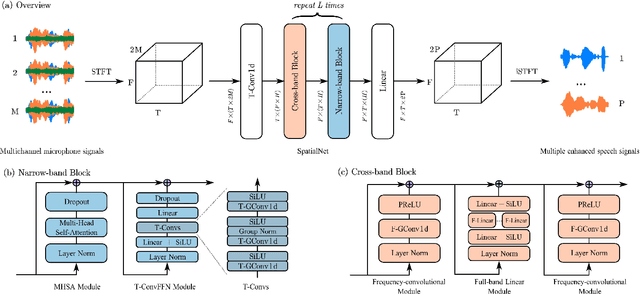

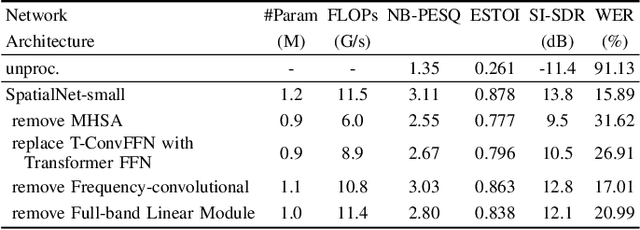
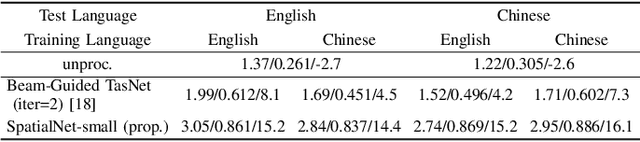
This work proposes a neural network to extensively exploit spatial information for multichannel joint speech separation, denoising and dereverberation, named SpatialNet.In the short-time Fourier transform (STFT) domain, the proposed network performs end-to-end speech enhancement. It is mainly composed of interleaved narrow-band and cross-band blocks to respectively exploit narrow-band and cross-band spatial information. The narrow-band blocks process frequencies independently, and use self-attention mechanism and temporal convolutional layers to respectively perform spatial-feature-based speaker clustering and temporal smoothing/filtering. The cross-band blocks processes frames independently, and use full-band linear layer and frequency convolutional layers to respectively learn the correlation between all frequencies and adjacent frequencies. Experiments are conducted on various simulated and real datasets, and the results show that 1) the proposed network achieves the state-of-the-art performance on almost all tasks; 2) the proposed network suffers little from the spectral generalization problem; and 3) the proposed network is indeed performing speaker clustering (demonstrated by attention maps).
SSD-2: Scaling and Inference-time Fusion of Diffusion Language Models
May 24, 2023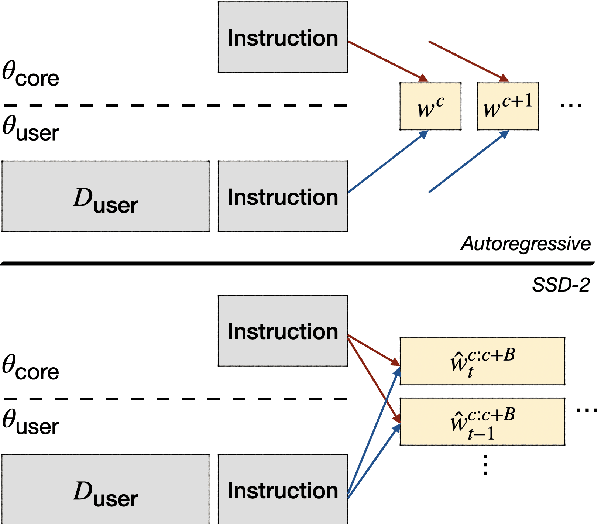

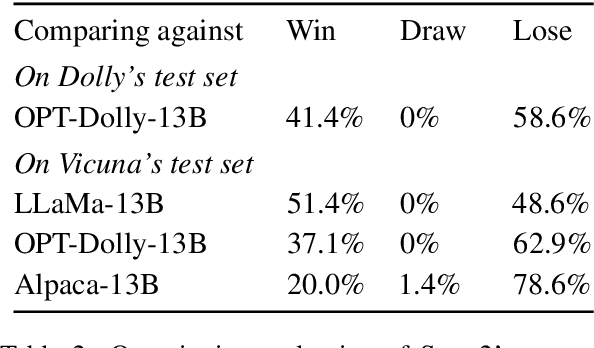
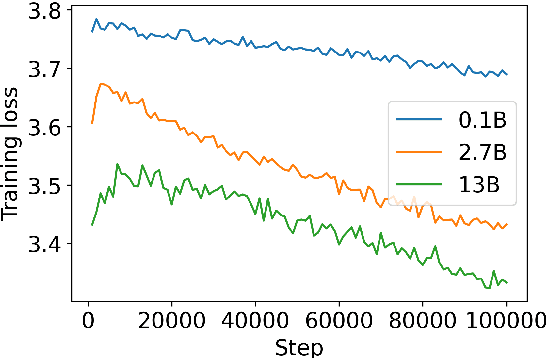
Diffusion-based language models (LMs) have been shown to be competent generative models that are easy to control at inference and are a promising alternative to autoregressive LMs. While autoregressive LMs have benefited immensely from scaling and instruction-based learning, existing studies on diffusion LMs have been conducted on a relatively smaller scale. Starting with a recently proposed diffusion model SSD-LM, in this work we explore methods to scale it from 0.4B to 13B parameters, proposing several techniques to improve its training and inference efficiency. We call the new model SSD-2. We further show that this model can be easily finetuned to follow instructions. Finally, leveraging diffusion models' capability at inference-time control, we show that SSD-2 facilitates novel ensembles with 100x smaller models that can be customized and deployed by individual users. We find that compared to autoregressive models, the collaboration between diffusion models is more effective, leading to higher-quality and more relevant model responses due to their ability to incorporate bi-directional contexts.