 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Client-supervised Federated Learning: Towards One-model-for-all Personalization
Mar 28, 2024
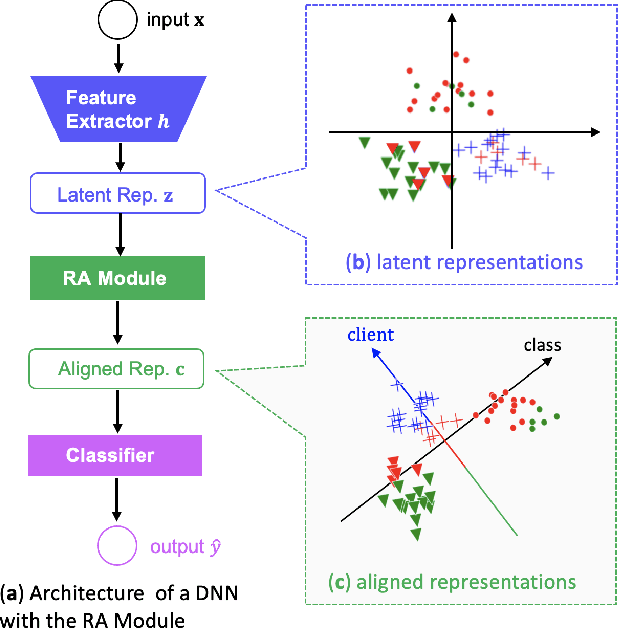
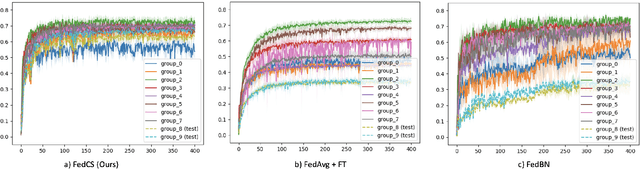
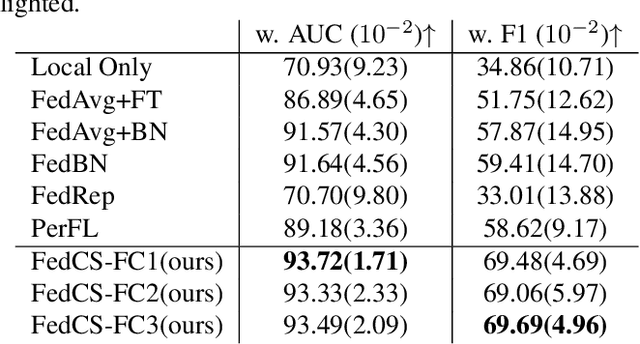
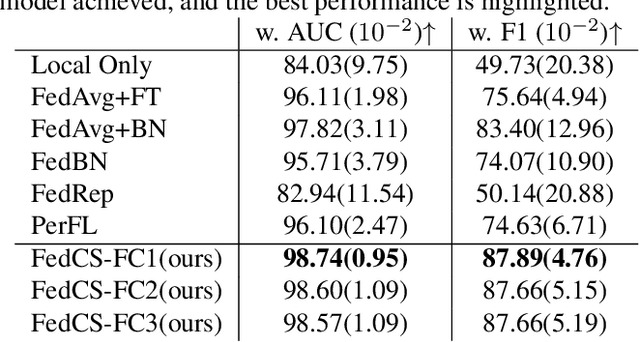
Personalized Federated Learning (PerFL) is a new machine learning paradigm that delivers personalized models for diverse clients under federated learning settings. Most PerFL methods require extra learning processes on a client to adapt a globally shared model to the client-specific personalized model using its own local data. However, the model adaptation process in PerFL is still an open challenge in the stage of model deployment and test time. This work tackles the challenge by proposing a novel federated learning framework to learn only one robust global model to achieve competitive performance to those personalized models on unseen/test clients in the FL system. Specifically, we design a new Client-Supervised Federated Learning (FedCS) to unravel clients' bias on instances' latent representations so that the global model can learn both client-specific and client-agnostic knowledge. Experimental study shows that the FedCS can learn a robust FL global model for the changing data distributions of unseen/test clients. The FedCS's global model can be directly deployed to the test clients while achieving comparable performance to other personalized FL methods that require model adaptation.
Beyond Talking -- Generating Holistic 3D Human Dyadic Motion for Communication
Mar 28, 2024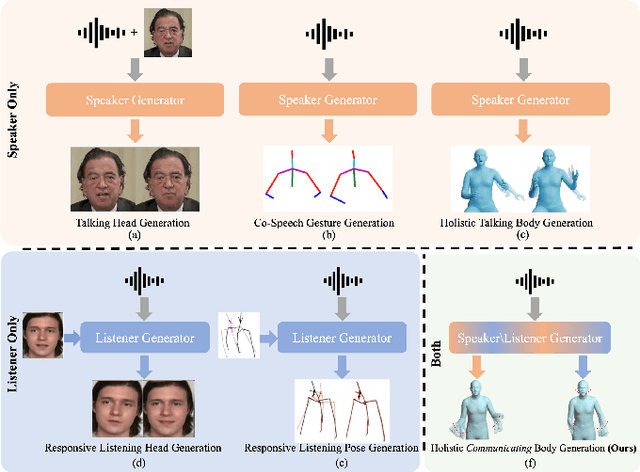

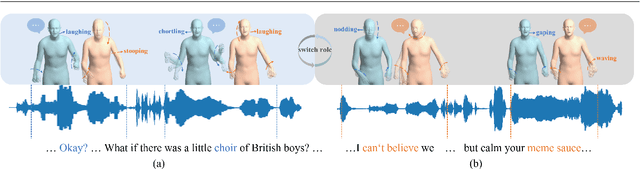
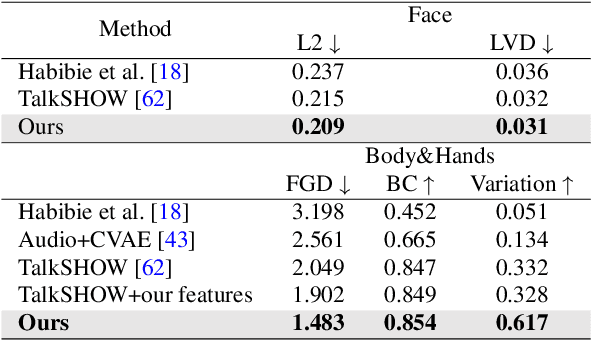
In this paper, we introduce an innovative task focused on human communication, aiming to generate 3D holistic human motions for both speakers and listeners. Central to our approach is the incorporation of factorization to decouple audio features and the combination of textual semantic information, thereby facilitating the creation of more realistic and coordinated movements. We separately train VQ-VAEs with respect to the holistic motions of both speaker and listener. We consider the real-time mutual influence between the speaker and the listener and propose a novel chain-like transformer-based auto-regressive model specifically designed to characterize real-world communication scenarios effectively which can generate the motions of both the speaker and the listener simultaneously. These designs ensure that the results we generate are both coordinated and diverse. Our approach demonstrates state-of-the-art performance on two benchmark datasets. Furthermore, we introduce the HoCo holistic communication dataset, which is a valuable resource for future research. Our HoCo dataset and code will be released for research purposes upon acceptance.
Transparent and Clinically Interpretable AI for Lung Cancer Detection in Chest X-Rays
Mar 28, 2024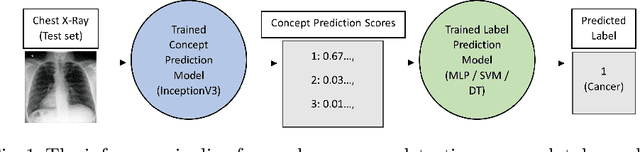
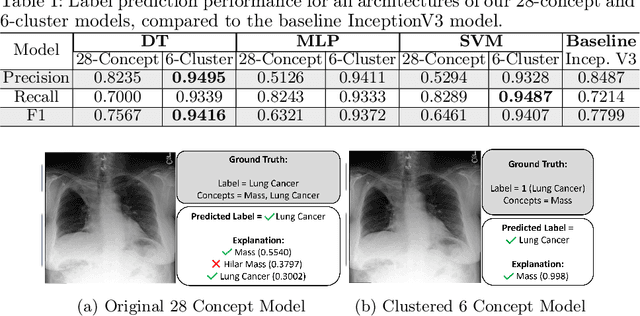
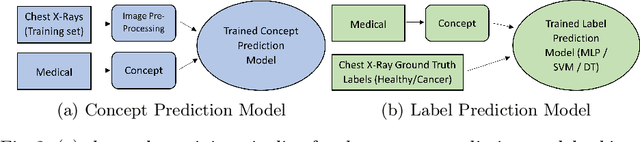

The rapidly advancing field of Explainable Artificial Intelligence (XAI) aims to tackle the issue of trust regarding the use of complex black-box deep learning models in real-world applications. Existing post-hoc XAI techniques have recently been shown to have poor performance on medical data, producing unreliable explanations which are infeasible for clinical use. To address this, we propose an ante-hoc approach based on concept bottleneck models which introduces for the first time clinical concepts into the classification pipeline, allowing the user valuable insight into the decision-making process. On a large public dataset of chest X-rays and associated medical reports, we focus on the binary classification task of lung cancer detection. Our approach yields improved classification performance in lung cancer detection when compared to baseline deep learning models (F1 > 0.9), while also generating clinically relevant and more reliable explanations than existing techniques. We evaluate our approach against post-hoc image XAI techniques LIME and SHAP, as well as CXR-LLaVA, a recent textual XAI tool which operates in the context of question answering on chest X-rays.
Improving Out-of-Vocabulary Handling in Recommendation Systems
Mar 27, 2024Recommendation systems (RS) are an increasingly relevant area for both academic and industry researchers, given their widespread impact on the daily online experiences of billions of users. One common issue in real RS is the cold-start problem, where users and items may not contain enough information to produce high-quality recommendations. This work focuses on a complementary problem: recommending new users and items unseen (out-of-vocabulary, or OOV) at training time. This setting is known as the inductive setting and is especially problematic for factorization-based models, which rely on encoding only those users/items seen at training time with fixed parameter vectors. Many existing solutions applied in practice are often naive, such as assigning OOV users/items to random buckets. In this work, we tackle this problem and propose approaches that better leverage available user/item features to improve OOV handling at the embedding table level. We discuss general-purpose plug-and-play approaches that are easily applicable to most RS models and improve inductive performance without negatively impacting transductive model performance. We extensively evaluate 9 OOV embedding methods on 5 models across 4 datasets (spanning different domains). One of these datasets is a proprietary production dataset from a prominent RS employed by a large social platform serving hundreds of millions of daily active users. In our experiments, we find that several proposed methods that exploit feature similarity using LSH consistently outperform alternatives on most model-dataset combinations, with the best method showing a mean improvement of 3.74% over the industry standard baseline in inductive performance. We release our code and hope our work helps practitioners make more informed decisions when handling OOV for their RS and further inspires academic research into improving OOV support in RS.
Power-Aware Sparse Reflect Beamforming in Active RIS-aided Interference Channels
Mar 29, 2024Active reconfigurable intelligent surface (RIS) has attracted significant attention in wireless communications, due to its reflecting elements (REs) capable of reflecting incident signals with not only phase shifts but also amplitude amplifications. In this paper, we are interested in active RIS-aided interference channels in which $K$ user pairs share the same time and frequency resources with the aid of active RIS. Thanks to the promising amplitude amplification capability, activating a moderate number of REs, rather than all of them, is sufficient for the active RIS to mitigate cross-channel interferences. Motivated by this, we propose a power-aware sparse reflect beamforming design for the active RIS-aided interference channels, which allows the active RIS to flexibly adjust the number of activated REs for the sake of reducing hardware and power costs. Specifically, we establish the power consumption model in which only those activated REs consume the biasing and operation power that supports the amplitude amplification, yielding an $\ell_0$-norm power consumption function. Based on the proposed model, we investigate a sum-rate maximization problem and an active RIS power minimization problem by carefully designing the sparse reflect beamforming vector. To solve these problems, we first replace the nonconvex $\ell_0$-norm function with an iterative reweighted $\ell_1$-norm function. Then, fractional programming is used to solve the sum-rate maximization, while semidefinite programming together with the difference-of-convex algorithm (DCA) is used to solve the active RIS power minimization. Numerical results show that the proposed sparse designs can notably increase the sum rate of user pairs and decrease the power consumption of active RIS in interference channels.
Verifying the Selected Completely at Random Assumption in Positive-Unlabeled Learning
Mar 29, 2024The goal of positive-unlabeled (PU) learning is to train a binary classifier on the basis of training data containing positive and unlabeled instances, where unlabeled observations can belong either to the positive class or to the negative class. Modeling PU data requires certain assumptions on the labeling mechanism that describes which positive observations are assigned a label. The simplest assumption, considered in early works, is SCAR (Selected Completely at Random Assumption), according to which the propensity score function, defined as the probability of assigning a label to a positive observation, is constant. On the other hand, a much more realistic assumption is SAR (Selected at Random), which states that the propensity function solely depends on the observed feature vector. SCAR-based algorithms are much simpler and computationally much faster compared to SAR-based algorithms, which usually require challenging estimation of the propensity score. In this work, we propose a relatively simple and computationally fast test that can be used to determine whether the observed data meet the SCAR assumption. Our test is based on generating artificial labels conforming to the SCAR case, which in turn allows to mimic the distribution of the test statistic under the null hypothesis of SCAR. We justify our method theoretically. In experiments, we demonstrate that the test successfully detects various deviations from SCAR scenario and at the same time it is possible to effectively control the type I error. The proposed test can be recommended as a pre-processing step to decide which final PU algorithm to choose in cases when nature of labeling mechanism is not known.
Accurate Block Quantization in LLMs with Outliers
Mar 29, 2024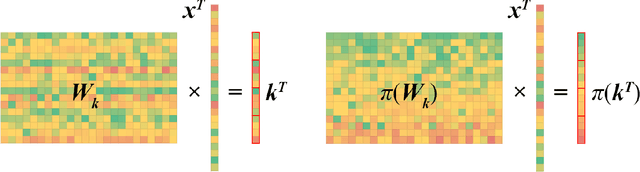
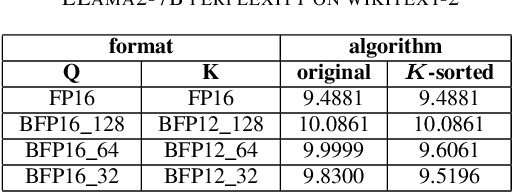
The demand for inference on extremely large scale LLMs has seen enormous growth in the recent months. It made evident the colossal shortage of dedicated hardware capable of efficient and fast processing of the involved compute and memory movement. The problem is aggravated by the exploding raise in the lengths of the sequences being processed, since those require efficient on-chip storage of the KV-cache of size proportional to the sequence length. To make the required compute feasible and fit the involved data into available memory, numerous quantization techniques have been proposed that allow accurate quantization for both weights and activations. One of the main recent breakthroughs in this direction was introduction of the family of Block Floating Point (BFP) formats characterized by a block of mantissas with a shared scale factor. These enable memory- power-, and compute- efficient hardware support of the tensor operations and provide extremely good quantization accuracy. The main issues preventing widespread application of block formats is caused by the presence of outliers in weights and activations since those affect the accuracy of the other values in the same block. In this paper, we focus on the most critical problem of limited KV-cache storage. We propose a novel approach enabling usage of low precision BFP formats without compromising the resulting model accuracy. We exploit the common channel-wise patterns exhibited by the outliers to rearrange them in such a way, that their quantization quality is significantly improved. The methodology yields 2x savings in the memory footprint without significant degradation of the model's accuracy. Importantly, the rearrangement of channels happens at the compile time and thus has no impact on the inference latency.
Supervised Time Series Classification for Anomaly Detection in Subsea Engineering
Mar 12, 2024
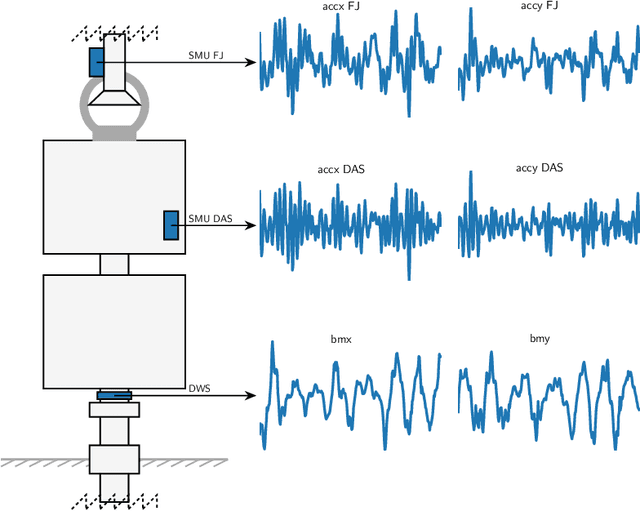
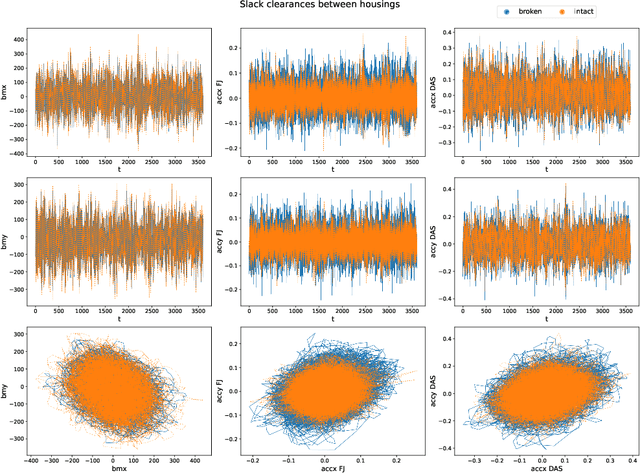
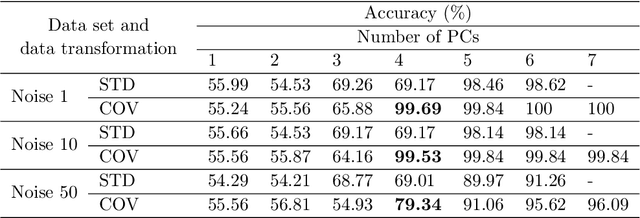
Time series classification is of significant importance in monitoring structural systems. In this work, we investigate the use of supervised machine learning classification algorithms on simulated data based on a physical system with two states: Intact and Broken. We provide a comprehensive discussion of the preprocessing of temporal data, using measures of statistical dispersion and dimension reduction techniques. We present an intuitive baseline method and discuss its efficiency. We conclude with a comparison of the various methods based on different performance metrics, showing the advantage of using machine learning techniques as a tool in decision making.
FastPerson: Enhancing Video Learning through Effective Video Summarization that Preserves Linguistic and Visual Contexts
Mar 26, 2024Quickly understanding lengthy lecture videos is essential for learners with limited time and interest in various topics to improve their learning efficiency. To this end, video summarization has been actively researched to enable users to view only important scenes from a video. However, these studies focus on either the visual or audio information of a video and extract important segments in the video. Therefore, there is a risk of missing important information when both the teacher's speech and visual information on the blackboard or slides are important, such as in a lecture video. To tackle this issue, we propose FastPerson, a video summarization approach that considers both the visual and auditory information in lecture videos. FastPerson creates summary videos by utilizing audio transcriptions along with on-screen images and text, minimizing the risk of overlooking crucial information for learners. Further, it provides a feature that allows learners to switch between the summary and original videos for each chapter of the video, enabling them to adjust the pace of learning based on their interests and level of understanding. We conducted an evaluation with 40 participants to assess the effectiveness of our method and confirmed that it reduced viewing time by 53\% at the same level of comprehension as that when using traditional video playback methods.
Project MOSLA: Recording Every Moment of Second Language Acquisition
Mar 26, 2024Second language acquisition (SLA) is a complex and dynamic process. Many SLA studies that have attempted to record and analyze this process have typically focused on a single modality (e.g., textual output of learners), covered only a short period of time, and/or lacked control (e.g., failed to capture every aspect of the learning process). In Project MOSLA (Moments of Second Language Acquisition), we have created a longitudinal, multimodal, multilingual, and controlled dataset by inviting participants to learn one of three target languages (Arabic, Spanish, and Chinese) from scratch over a span of two years, exclusively through online instruction, and recording every lesson using Zoom. The dataset is semi-automatically annotated with speaker/language IDs and transcripts by both human annotators and fine-tuned state-of-the-art speech models. Our experiments reveal linguistic insights into learners' proficiency development over time, as well as the potential for automatically detecting the areas of focus on the screen purely from the unannotated multimodal data. Our dataset is freely available for research purposes and can serve as a valuable resource for a wide range of applications, including but not limited to SLA, proficiency assessment, language and speech processing, pedagogy, and multimodal learning analytics.