 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MARL for Decentralized Electric Vehicle Charging Coordination with V2V Energy Exchange
Aug 27, 2023
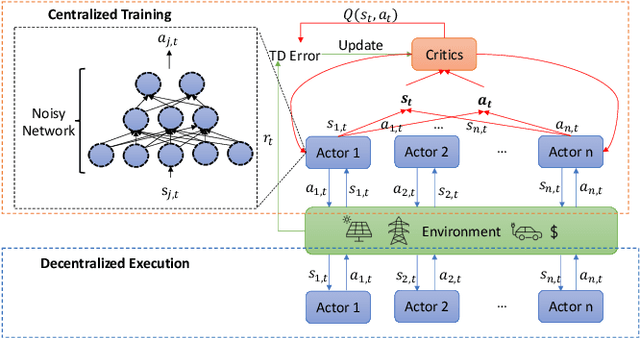
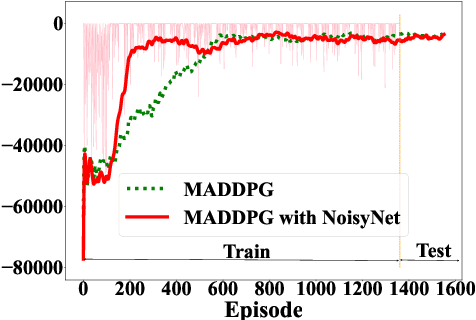
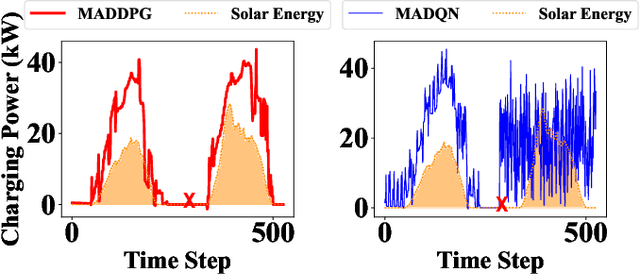
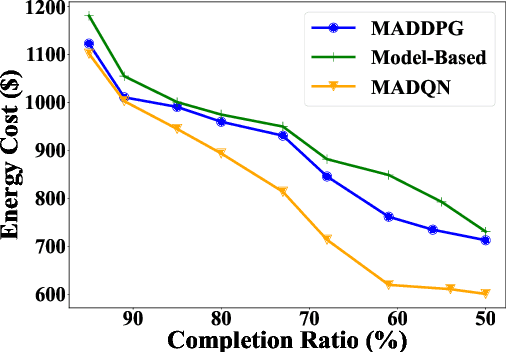
Effective energy management of electric vehicle (EV) charging stations is critical to supporting the transport sector's sustainable energy transition. This paper addresses the EV charging coordination by considering vehicle-to-vehicle (V2V) energy exchange as the flexibility to harness in EV charging stations. Moreover, this paper takes into account EV user experiences, such as charging satisfaction and fairness. We propose a Multi-Agent Reinforcement Learning (MARL) approach to coordinate EV charging with V2V energy exchange while considering uncertainties in the EV arrival time, energy price, and solar energy generation. The exploration capability of MARL is enhanced by introducing parameter noise into MARL's neural network models. Experimental results demonstrate the superior performance and scalability of our proposed method compared to traditional optimization baselines. The decentralized execution of the algorithm enables it to effectively deal with partial system faults in the charging station.
Ad-Rec: Advanced Feature Interactions to Address Covariate-Shifts in Recommendation Networks
Aug 28, 2023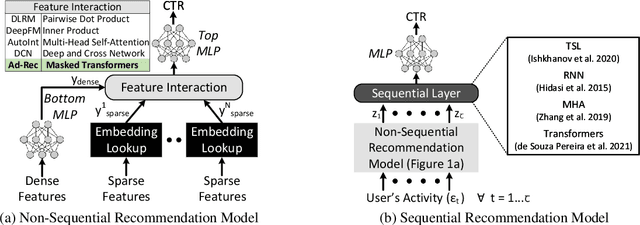
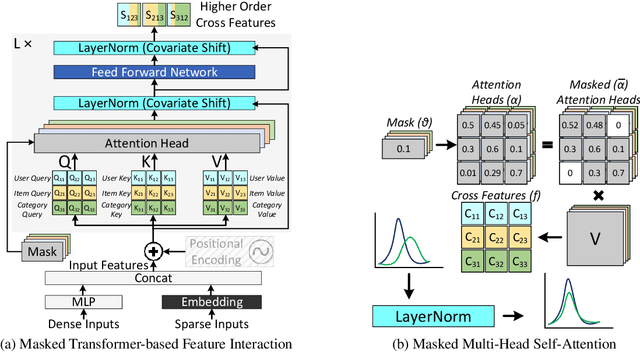

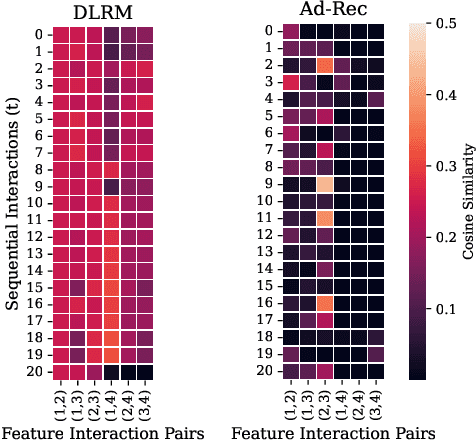
Recommendation models are vital in delivering personalized user experiences by leveraging the correlation between multiple input features. However, deep learning-based recommendation models often face challenges due to evolving user behaviour and item features, leading to covariate shifts. Effective cross-feature learning is crucial to handle data distribution drift and adapting to changing user behaviour. Traditional feature interaction techniques have limitations in achieving optimal performance in this context. This work introduces Ad-Rec, an advanced network that leverages feature interaction techniques to address covariate shifts. This helps eliminate irrelevant interactions in recommendation tasks. Ad-Rec leverages masked transformers to enable the learning of higher-order cross-features while mitigating the impact of data distribution drift. Our approach improves model quality, accelerates convergence, and reduces training time, as measured by the Area Under Curve (AUC) metric. We demonstrate the scalability of Ad-Rec and its ability to achieve superior model quality through comprehensive ablation studies.
Causality-Based Feature Importance Quantifying Methods:PN-FI, PS-FI and PNS-FI
Aug 28, 2023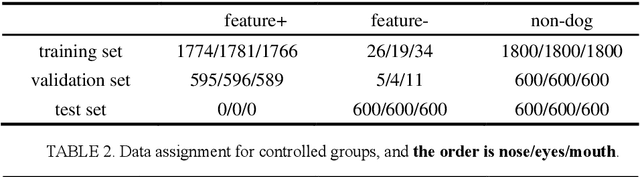
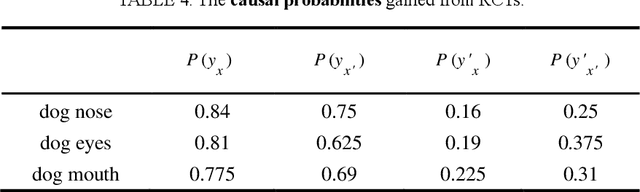
In current ML field models are getting larger and more complex, data we use are also getting larger in quantity and higher in dimension, so in order to train better models, save training time and computational resources, a good Feature Selection (FS) method in preprocessing stage is necessary. Feature importance (FI) is of great importance since it is the basis of feature selection. This paper creatively introduces the calculation of PNS(the probability of Necessity and Sufficiency) in Causality into quantifying feature importance and creates new FI measuring methods: PN-FI, which means how much importance a feature has in image recognition tasks, PS_FI that means how much importance a feature has in image generating tasks, and PNS_FI which measures both. The main body of this paper is three RCTs, with whose results we show how PS_FI, PN_FI and PNS_FI of three features: dog nose, dog eyes and dog mouth are calculated. The FI values are intervals with tight upper and lower bounds.
Biomedical Entity Linking with Triple-aware Pre-Training
Aug 28, 2023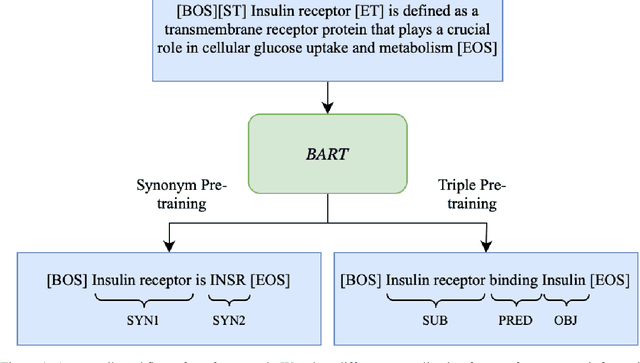
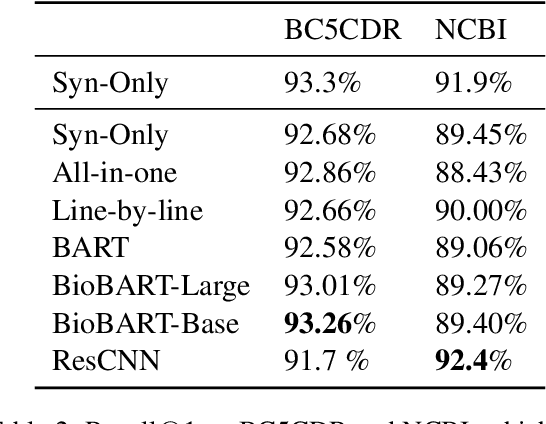
Linking biomedical entities is an essential aspect in biomedical natural language processing tasks, such as text mining and question answering. However, a difficulty of linking the biomedical entities using current large language models (LLM) trained on a general corpus is that biomedical entities are scarcely distributed in texts and therefore have been rarely seen during training by the LLM. At the same time, those LLMs are not aware of high level semantic connection between different biomedical entities, which are useful in identifying similar concepts in different textual contexts. To cope with aforementioned problems, some recent works focused on injecting knowledge graph information into LLMs. However, former methods either ignore the relational knowledge of the entities or lead to catastrophic forgetting. Therefore, we propose a novel framework to pre-train the powerful generative LLM by a corpus synthesized from a KG. In the evaluations we are unable to confirm the benefit of including synonym, description or relational information.
Breaking Boundaries: Distributed Domain Decomposition with Scalable Physics-Informed Neural PDE Solvers
Aug 28, 2023Mosaic Flow is a novel domain decomposition method designed to scale physics-informed neural PDE solvers to large domains. Its unique approach leverages pre-trained networks on small domains to solve partial differential equations on large domains purely through inference, resulting in high reusability. This paper presents an end-to-end parallelization of Mosaic Flow, combining data parallel training and domain parallelism for inference on large-scale problems. By optimizing the network architecture and data parallel training, we significantly reduce the training time for learning the Laplacian operator to minutes on 32 GPUs. Moreover, our distributed domain decomposition algorithm enables scalable inferences for solving the Laplace equation on domains 4096 times larger than the training domain, demonstrating strong scaling while maintaining accuracy on 32 GPUs. The reusability of Mosaic Flow, combined with the improved performance achieved through the distributed-memory algorithms, makes it a promising tool for modeling complex physical phenomena and accelerating scientific discovery.
Quantum Next Generation Reservoir Computing: An Efficient Quantum Algorithm for Forecasting Quantum Dynamics
Aug 28, 2023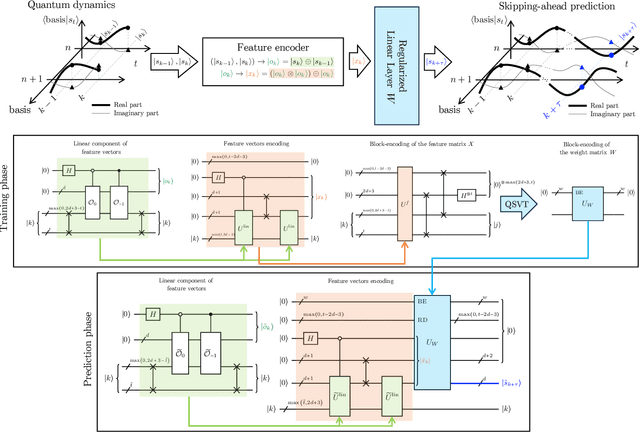
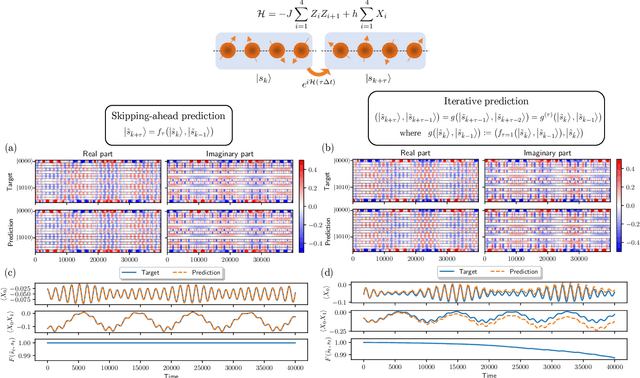
Next Generation Reservoir Computing (NG-RC) is a modern class of model-free machine learning that enables an accurate forecasting of time series data generated by dynamical systems. We demonstrate that NG-RC can accurately predict full many-body quantum dynamics, instead of merely concentrating on the dynamics of observables, which is the conventional application of reservoir computing. In addition, we apply a technique which we refer to as skipping ahead to predict far future states accurately without the need to extract information about the intermediate states. However, adopting a classical NG-RC for many-body quantum dynamics prediction is computationally prohibitive due to the large Hilbert space of sample input data. In this work, we propose an end-to-end quantum algorithm for many-body quantum dynamics forecasting with a quantum computational speedup via the block-encoding technique. This proposal presents an efficient model-free quantum scheme to forecast quantum dynamics coherently, bypassing inductive biases incurred in a model-based approach.
Federated Linear Bandit Learning via Over-the-Air Computation
Aug 28, 2023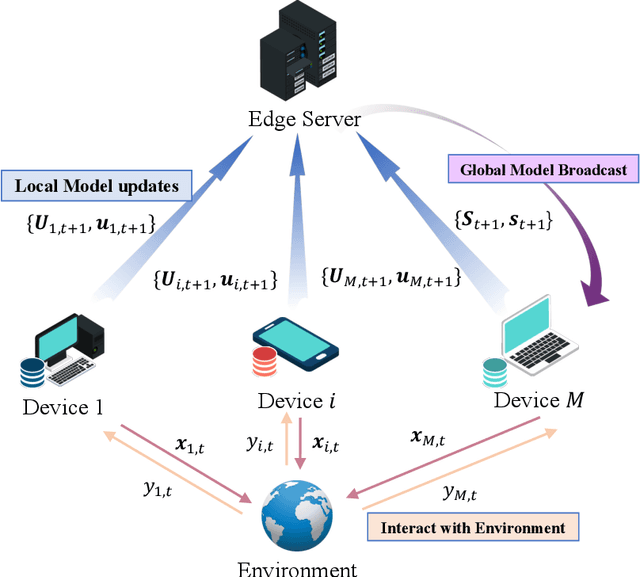
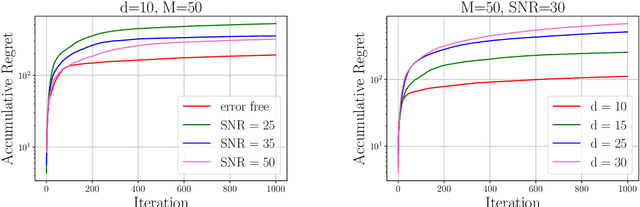
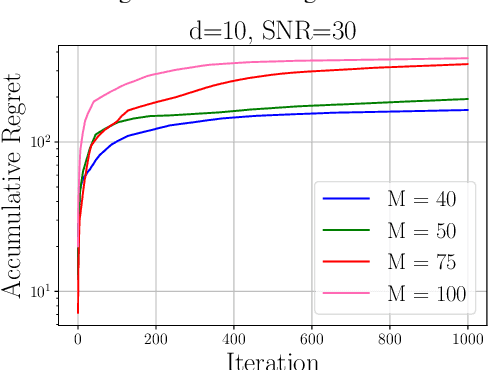
In this paper, we investigate federated contextual linear bandit learning within a wireless system that comprises a server and multiple devices. Each device interacts with the environment, selects an action based on the received reward, and sends model updates to the server. The primary objective is to minimize cumulative regret across all devices within a finite time horizon. To reduce the communication overhead, devices communicate with the server via over-the-air computation (AirComp) over noisy fading channels, where the channel noise may distort the signals. In this context, we propose a customized federated linear bandits scheme, where each device transmits an analog signal, and the server receives a superposition of these signals distorted by channel noise. A rigorous mathematical analysis is conducted to determine the regret bound of the proposed scheme. Both theoretical analysis and numerical experiments demonstrate the competitive performance of our proposed scheme in terms of regret bounds in various settings.
Efficient and Explainable Graph Neural Architecture Search via Monte-Carlo Tree Search
Sep 01, 2023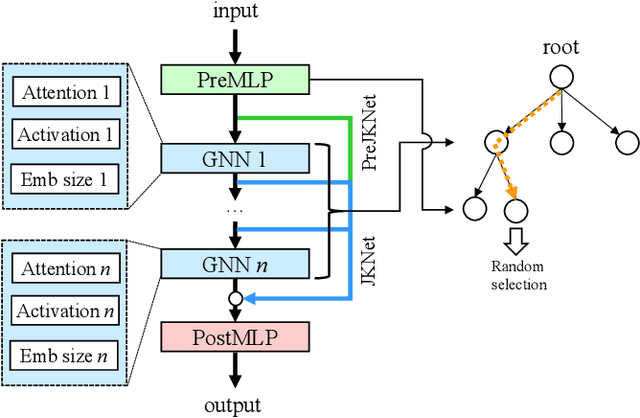
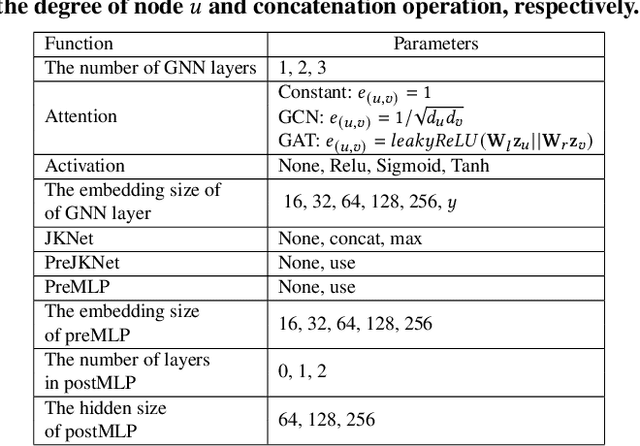
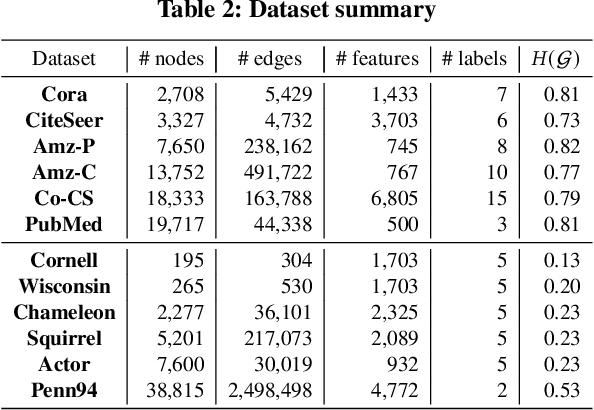
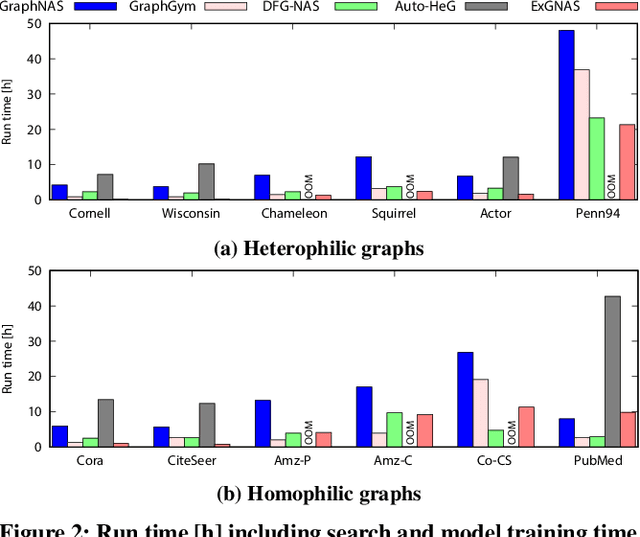
Graph neural networks (GNNs) are powerful tools for performing data science tasks in various domains. Although we use GNNs in wide application scenarios, it is a laborious task for researchers and practitioners to design/select optimal GNN architectures in diverse graphs. To save human efforts and computational costs, graph neural architecture search (Graph NAS) has been used to search for a sub-optimal GNN architecture that combines existing components. However, there are no existing Graph NAS methods that satisfy explainability, efficiency, and adaptability to various graphs. Therefore, we propose an efficient and explainable Graph NAS method, called ExGNAS, which consists of (i) a simple search space that can adapt to various graphs and (ii) a search algorithm that makes the decision process explainable. The search space includes only fundamental functions that can handle homophilic and heterophilic graphs. The search algorithm efficiently searches for the best GNN architecture via Monte-Carlo tree search without neural models. The combination of our search space and algorithm achieves finding accurate GNN models and the important functions within the search space. We comprehensively evaluate our method compared with twelve hand-crafted GNN architectures and three Graph NAS methods in four graphs. Our experimental results show that ExGNAS increases AUC up to 3.6 and reduces run time up to 78\% compared with the state-of-the-art Graph NAS methods. Furthermore, we show ExGNAS is effective in analyzing the difference between GNN architectures in homophilic and heterophilic graphs.
ALJP: An Arabic Legal Judgment Prediction in Personal Status Cases Using Machine Learning Models
Sep 01, 2023Legal Judgment Prediction (LJP) aims to predict judgment outcomes based on case description. Several researchers have developed techniques to assist potential clients by predicting the outcome in the legal profession. However, none of the proposed techniques were implemented in Arabic, and only a few attempts were implemented in English, Chinese, and Hindi. In this paper, we develop a system that utilizes deep learning (DL) and natural language processing (NLP) techniques to predict the judgment outcome from Arabic case scripts, especially in cases of custody and annulment of marriage. This system will assist judges and attorneys in improving their work and time efficiency while reducing sentencing disparity. In addition, it will help litigants, lawyers, and law students analyze the probable outcomes of any given case before trial. We use a different machine and deep learning models such as Support Vector Machine (SVM), Logistic regression (LR), Long Short Term Memory (LSTM), and Bidirectional Long Short-Term Memory (BiLSTM) using representation techniques such as TF-IDF and word2vec on the developed dataset. Experimental results demonstrate that compared with the five baseline methods, the SVM model with word2vec and LR with TF-IDF achieve the highest accuracy of 88% and 78% in predicting the judgment on custody cases and annulment of marriage, respectively. Furthermore, the LR and SVM with word2vec and BiLSTM model with TF-IDF achieved the highest accuracy of 88% and 69% in predicting the probability of outcomes on custody cases and annulment of marriage, respectively.
Consistency of Lloyd's Algorithm Under Perturbations
Sep 01, 2023In the context of unsupervised learning, Lloyd's algorithm is one of the most widely used clustering algorithms. It has inspired a plethora of work investigating the correctness of the algorithm under various settings with ground truth clusters. In particular, in 2016, Lu and Zhou have shown that the mis-clustering rate of Lloyd's algorithm on $n$ independent samples from a sub-Gaussian mixture is exponentially bounded after $O(\log(n))$ iterations, assuming proper initialization of the algorithm. However, in many applications, the true samples are unobserved and need to be learned from the data via pre-processing pipelines such as spectral methods on appropriate data matrices. We show that the mis-clustering rate of Lloyd's algorithm on perturbed samples from a sub-Gaussian mixture is also exponentially bounded after $O(\log(n))$ iterations under the assumptions of proper initialization and that the perturbation is small relative to the sub-Gaussian noise. In canonical settings with ground truth clusters, we derive bounds for algorithms such as $k$-means$++$ to find good initializations and thus leading to the correctness of clustering via the main result. We show the implications of the results for pipelines measuring the statistical significance of derived clusters from data such as SigClust. We use these general results to derive implications in providing theoretical guarantees on the misclustering rate for Lloyd's algorithm in a host of applications, including high-dimensional time series, multi-dimensional scaling, and community detection for sparse networks via spectral clustering.