 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Future of Combating Rumors? Retrieval, Discrimination, and Generation
Mar 29, 2024

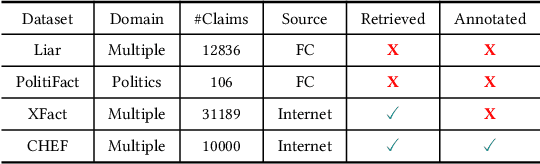
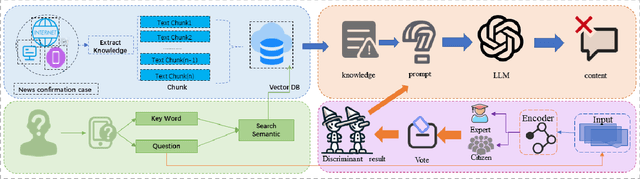
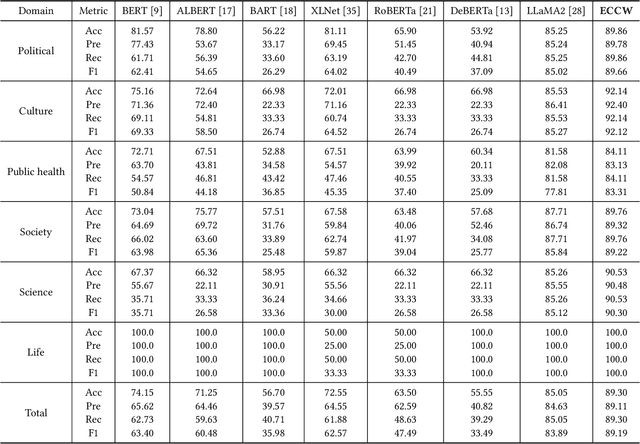
Artificial Intelligence Generated Content (AIGC) technology development has facilitated the creation of rumors with misinformation, impacting societal, economic, and political ecosystems, challenging democracy. Current rumor detection efforts fall short by merely labeling potentially misinformation (classification task), inadequately addressing the issue, and it is unrealistic to have authoritative institutions debunk every piece of information on social media. Our proposed comprehensive debunking process not only detects rumors but also provides explanatory generated content to refute the authenticity of the information. The Expert-Citizen Collective Wisdom (ECCW) module we designed aensures high-precision assessment of the credibility of information and the retrieval module is responsible for retrieving relevant knowledge from a Real-time updated debunking database based on information keywords. By using prompt engineering techniques, we feed results and knowledge into a LLM (Large Language Model), achieving satisfactory discrimination and explanatory effects while eliminating the need for fine-tuning, saving computational costs, and contributing to debunking efforts.
Noise-Aware Training of Layout-Aware Language Models
Mar 30, 2024A visually rich document (VRD) utilizes visual features along with linguistic cues to disseminate information. Training a custom extractor that identifies named entities from a document requires a large number of instances of the target document type annotated at textual and visual modalities. This is an expensive bottleneck in enterprise scenarios, where we want to train custom extractors for thousands of different document types in a scalable way. Pre-training an extractor model on unlabeled instances of the target document type, followed by a fine-tuning step on human-labeled instances does not work in these scenarios, as it surpasses the maximum allowable training time allocated for the extractor. We address this scenario by proposing a Noise-Aware Training method or NAT in this paper. Instead of acquiring expensive human-labeled documents, NAT utilizes weakly labeled documents to train an extractor in a scalable way. To avoid degradation in the model's quality due to noisy, weakly labeled samples, NAT estimates the confidence of each training sample and incorporates it as uncertainty measure during training. We train multiple state-of-the-art extractor models using NAT. Experiments on a number of publicly available and in-house datasets show that NAT-trained models are not only robust in performance -- it outperforms a transfer-learning baseline by up to 6% in terms of macro-F1 score, but it is also more label-efficient -- it reduces the amount of human-effort required to obtain comparable performance by up to 73%.
TG-NAS: Leveraging Zero-Cost Proxies with Transformer and Graph Convolution Networks for Efficient Neural Architecture Search
Mar 30, 2024Neural architecture search (NAS) is an effective method for discovering new convolutional neural network (CNN) architectures. However, existing approaches often require time-consuming training or intensive sampling and evaluations. Zero-shot NAS aims to create training-free proxies for architecture performance prediction. However, existing proxies have suboptimal performance, and are often outperformed by simple metrics such as model parameter counts or the number of floating-point operations. Besides, existing model-based proxies cannot be generalized to new search spaces with unseen new types of operators without golden accuracy truth. A universally optimal proxy remains elusive. We introduce TG-NAS, a novel model-based universal proxy that leverages a transformer-based operator embedding generator and a graph convolution network (GCN) to predict architecture performance. This approach guides neural architecture search across any given search space without the need of retraining. Distinct from other model-based predictor subroutines, TG-NAS itself acts as a zero-cost (ZC) proxy, guiding architecture search with advantages in terms of data independence, cost-effectiveness, and consistency across diverse search spaces. Our experiments showcase its advantages over existing proxies across various NAS benchmarks, suggesting its potential as a foundational element for efficient architecture search. TG-NAS achieves up to 300X improvements in search efficiency compared to previous SOTA ZC proxy methods. Notably, it discovers competitive models with 93.75% CIFAR-10 accuracy on the NAS-Bench-201 space and 74.5% ImageNet top-1 accuracy on the DARTS space.
Targeted aspect-based emotion analysis to detect opportunities and precaution in financial Twitter messages
Mar 30, 2024Microblogging platforms, of which Twitter is a representative example, are valuable information sources for market screening and financial models. In them, users voluntarily provide relevant information, including educated knowledge on investments, reacting to the state of the stock markets in real-time and, often, influencing this state. We are interested in the user forecasts in financial, social media messages expressing opportunities and precautions about assets. We propose a novel Targeted Aspect-Based Emotion Analysis (TABEA) system that can individually discern the financial emotions (positive and negative forecasts) on the different stock market assets in the same tweet (instead of making an overall guess about that whole tweet). It is based on Natural Language Processing (NLP) techniques and Machine Learning streaming algorithms. The system comprises a constituency parsing module for parsing the tweets and splitting them into simpler declarative clauses; an offline data processing module to engineer textual, numerical and categorical features and analyse and select them based on their relevance; and a stream classification module to continuously process tweets on-the-fly. Experimental results on a labelled data set endorse our solution. It achieves over 90% precision for the target emotions, financial opportunity, and precaution on Twitter. To the best of our knowledge, no prior work in the literature has addressed this problem despite its practical interest in decision-making, and we are not aware of any previous NLP nor online Machine Learning approaches to TABEA.
Unsupervised Threat Hunting using Continuous Bag-of-Terms-and-Time (CBoTT)
Mar 15, 2024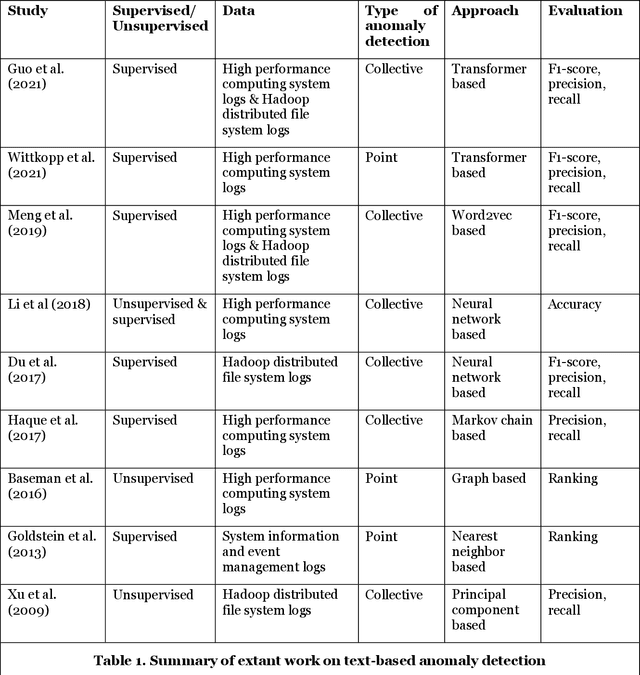
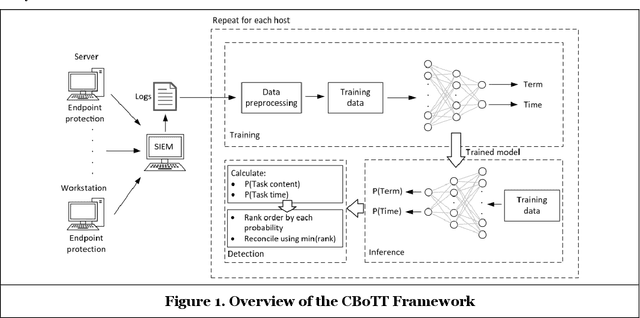
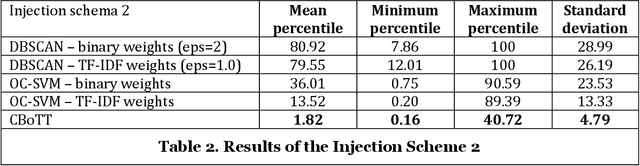
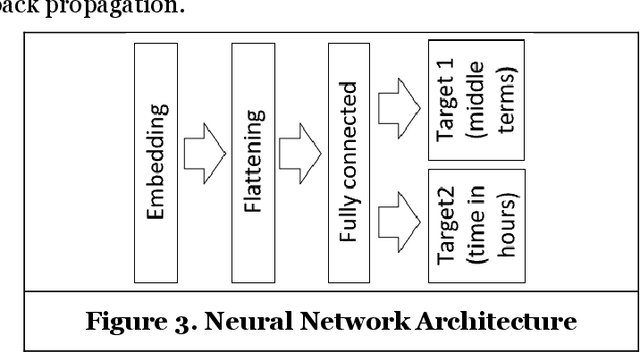
Threat hunting is sifting through system logs to detect malicious activities that might have bypassed existing security measures. It can be performed in several ways, one of which is based on detecting anomalies. We propose an unsupervised framework, called continuous bag-of-terms-and-time (CBoTT), and publish its application programming interface (API) to help researchers and cybersecurity analysts perform anomaly-based threat hunting among SIEM logs geared toward process auditing on endpoint devices. Analyses show that our framework consistently outperforms benchmark approaches. When logs are sorted by likelihood of being an anomaly (from most likely to least), our approach identifies anomalies at higher percentiles (between 1.82-6.46) while benchmark approaches identify the same anomalies at lower percentiles (between 3.25-80.92). This framework can be used by other researchers to conduct benchmark analyses and cybersecurity analysts to find anomalies in SIEM logs.
A Physics-embedded Deep Learning Framework for Cloth Simulation
Mar 27, 2024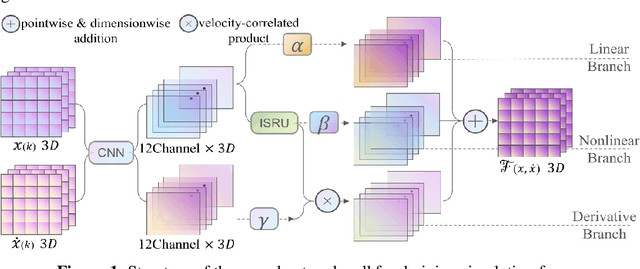

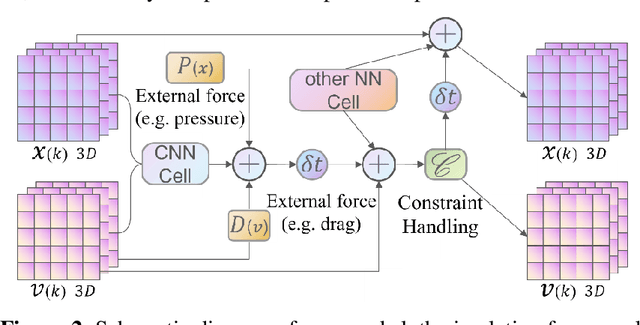

Delicate cloth simulations have long been desired in computer graphics. Various methods were proposed to improve engaged force interactions, collision handling, and numerical integrations. Deep learning has the potential to achieve fast and real-time simulation, but common neural network structures often demand many parameters to capture cloth dynamics. This paper proposes a physics-embedded learning framework that directly encodes physical features of cloth simulation. The convolutional neural network is used to represent spatial correlations of the mass-spring system, after which three branches are designed to learn linear, nonlinear, and time derivate features of cloth physics. The framework can also integrate with other external forces and collision handling through either traditional simulators or sub neural networks. The model is tested across different cloth animation cases, without training with new data. Agreement with baselines and predictive realism successfully validate its generalization ability. Inference efficiency of the proposed model also defeats traditional physics simulation. This framework is also designed to easily integrate with other visual refinement techniques like wrinkle carving, which leaves significant chances to incorporate prevailing macing learning techniques in 3D cloth amination.
Implementation of the Principal Component Analysis onto High-Performance Computer Facilities for Hyperspectral Dimensionality Reduction: Results and Comparisons
Mar 27, 2024Dimensionality reduction represents a critical preprocessing step in order to increase the efficiency and the performance of many hyperspectral imaging algorithms. However, dimensionality reduction algorithms, such as the Principal Component Analysis (PCA), suffer from their computationally demanding nature, becoming advisable for their implementation onto high-performance computer architectures for applications under strict latency constraints. This work presents the implementation of the PCA algorithm onto two different high-performance devices, namely, an NVIDIA Graphics Processing Unit (GPU) and a Kalray manycore, uncovering a highly valuable set of tips and tricks in order to take full advantage of the inherent parallelism of these high-performance computing platforms, and hence, reducing the time that is required to process a given hyperspectral image. Moreover, the achieved results obtained with different hyperspectral images have been compared with the ones that were obtained with a field programmable gate array (FPGA)-based implementation of the PCA algorithm that has been recently published, providing, for the first time in the literature, a comprehensive analysis in order to highlight the pros and cons of each option.
A Moreau Envelope Approach for LQR Meta-Policy Estimation
Mar 26, 2024We study the problem of policy estimation for the Linear Quadratic Regulator (LQR) in discrete-time linear time-invariant uncertain dynamical systems. We propose a Moreau Envelope-based surrogate LQR cost, built from a finite set of realizations of the uncertain system, to define a meta-policy efficiently adjustable to new realizations. Moreover, we design an algorithm to find an approximate first-order stationary point of the meta-LQR cost function. Numerical results show that the proposed approach outperforms naive averaging of controllers on new realizations of the linear system. We also provide empirical evidence that our method has better sample complexity than Model-Agnostic Meta-Learning (MAML) approaches.
Redundancy Transmission in UAV-Aided LoRa Networks Featuring Wake-Up Radios
Mar 26, 2024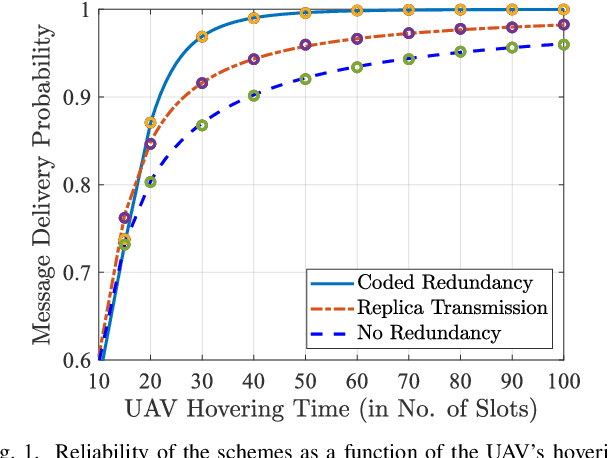
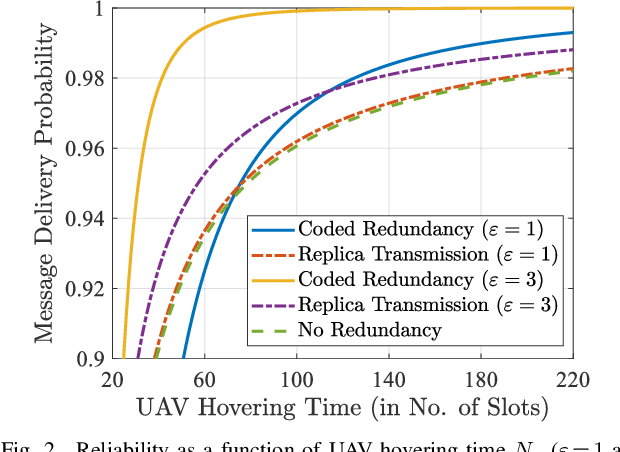
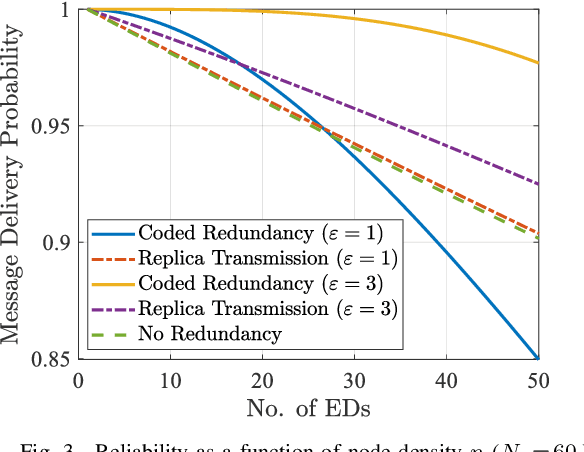

We consider a LoRa sensor network featuring a UAV-mounted gateway for collecting sensor data (messages). Wake-up radios (WuR) are employed to inform the sensors of the UAV's arrival. Building on an existing random access scheme for such setups, we propose and evaluate two redundancy transmission protocols for enhancing the reliability of the data transfer. One protocol employs fountain-coded transmissions, whereas the other performs message replication. Our results illustrate how redundancy transmission can be beneficial under the time constraints imposed by the UAV's limited hovering duration, and how node density, hovering time, and sensor energy budget impact the performance of the schemes.
Prediction of Vessel Arrival Time to Pilotage Area Using Multi-Data Fusion and Deep Learning
Mar 15, 2024This paper investigates the prediction of vessels' arrival time to the pilotage area using multi-data fusion and deep learning approaches. Firstly, the vessel arrival contour is extracted based on Multivariate Kernel Density Estimation (MKDE) and clustering. Secondly, multiple data sources, including Automatic Identification System (AIS), pilotage booking information, and meteorological data, are fused before latent feature extraction. Thirdly, a Temporal Convolutional Network (TCN) framework that incorporates a residual mechanism is constructed to learn the hidden arrival patterns of the vessels. Extensive tests on two real-world data sets from Singapore have been conducted and the following promising results have been obtained: 1) fusion of pilotage booking information and meteorological data improves the prediction accuracy, with pilotage booking information having a more significant impact; 2) using discrete embedding for the meteorological data performs better than using continuous embedding; 3) the TCN outperforms the state-of-the-art baseline methods in regression tasks, exhibiting Mean Absolute Error (MAE) ranging from 4.58 min to 4.86 min; and 4) approximately 89.41% to 90.61% of the absolute prediction residuals fall within a time frame of 10 min.