 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Research on self-cross transformer model of point cloud change detecter
Sep 14, 2023
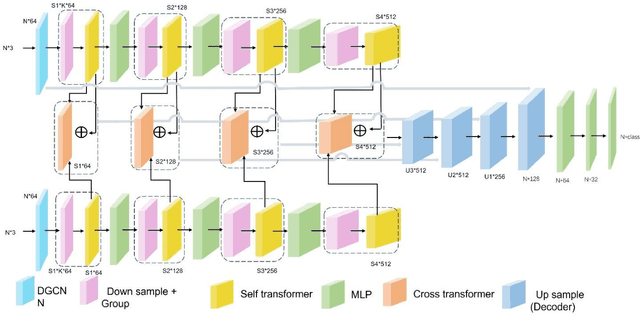

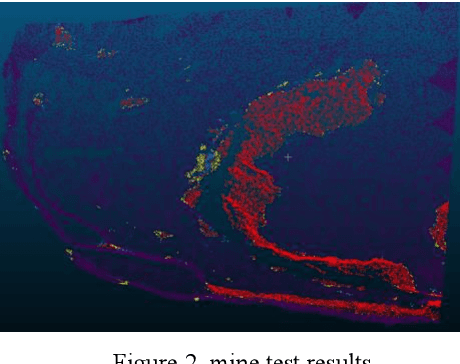
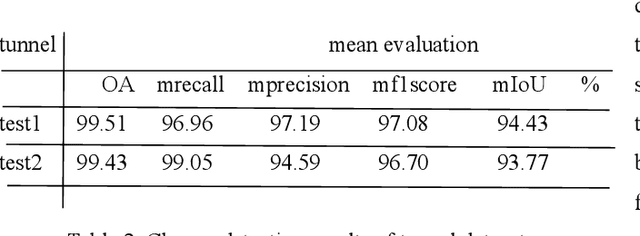
With the vigorous development of the urban construction industry, engineering deformation or changes often occur during the construction process. To combat this phenomenon, it is necessary to detect changes in order to detect construction loopholes in time, ensure the integrity of the project and reduce labor costs. Or the inconvenience and injuriousness of the road. In the study of change detection in 3D point clouds, researchers have published various research methods on 3D point clouds. Directly based on but mostly based ontraditional threshold distance methods (C2C, M3C2, M3C2-EP), and some are to convert 3D point clouds into DSM, which loses a lot of original information. Although deep learning is used in remote sensing methods, in terms of change detection of 3D point clouds, it is more converted into two-dimensional patches, and neural networks are rarely applied directly. We prefer that the network is given at the level of pixels or points. Variety. Therefore, in this article, our network builds a network for 3D point cloud change detection, and proposes a new module Cross transformer suitable for change detection. Simultaneously simulate tunneling data for change detection, and do test experiments with our network.
RecycleNet: Latent Feature Recycling Leads to Iterative Decision Refinement
Sep 14, 2023Despite the remarkable success of deep learning systems over the last decade, a key difference still remains between neural network and human decision-making: As humans, we cannot only form a decision on the spot, but also ponder, revisiting an initial guess from different angles, distilling relevant information, arriving at a better decision. Here, we propose RecycleNet, a latent feature recycling method, instilling the pondering capability for neural networks to refine initial decisions over a number of recycling steps, where outputs are fed back into earlier network layers in an iterative fashion. This approach makes minimal assumptions about the neural network architecture and thus can be implemented in a wide variety of contexts. Using medical image segmentation as the evaluation environment, we show that latent feature recycling enables the network to iteratively refine initial predictions even beyond the iterations seen during training, converging towards an improved decision. We evaluate this across a variety of segmentation benchmarks and show consistent improvements even compared with top-performing segmentation methods. This allows trading increased computation time for improved performance, which can be beneficial, especially for safety-critical applications.
An Explicit Method for Fast Monocular Depth Recovery in Corridor Environments
Sep 14, 2023Monocular cameras are extensively employed in indoor robotics, but their performance is limited in visual odometry, depth estimation, and related applications due to the absence of scale information.Depth estimation refers to the process of estimating a dense depth map from the corresponding input image, existing researchers mostly address this issue through deep learning-based approaches, yet their inference speed is slow, leading to poor real-time capabilities. To tackle this challenge, we propose an explicit method for rapid monocular depth recovery specifically designed for corridor environments, leveraging the principles of nonlinear optimization. We adopt the virtual camera assumption to make full use of the prior geometric features of the scene. The depth estimation problem is transformed into an optimization problem by minimizing the geometric residual. Furthermore, a novel depth plane construction technique is introduced to categorize spatial points based on their possible depths, facilitating swift depth estimation in enclosed structural scenarios, such as corridors. We also propose a new corridor dataset, named Corr\_EH\_z, which contains images as captured by the UGV camera of a variety of corridors. An exhaustive set of experiments in different corridors reveal the efficacy of the proposed algorithm.
Rail Crack Propagation Forecasting Using Multi-horizons RNNs
Sep 04, 2023The prediction of rail crack length propagation plays a crucial role in the maintenance and safety assessment of materials and structures. Traditional methods rely on physical models and empirical equations such as Paris law, which often have limitations in capturing the complex nature of crack growth. In recent years, machine learning techniques, particularly Recurrent Neural Networks (RNNs), have emerged as promising methods for time series forecasting. They allow to model time series data, and to incorporate exogenous variables into the model. The proposed approach involves collecting real data on the French rail network that includes historical crack length measurements, along with relevant exogenous factors that may influence crack growth. First, a pre-processing phase was performed to prepare a consistent data set for learning. Then, a suitable Bayesian multi-horizons recurrent architecture was designed to model the crack propagation phenomenon. Obtained results show that the Multi-horizons model outperforms state-of-the-art models such as LSTM and GRU.
Tightening Classification Boundaries in Open Set Domain Adaptation through Unknown Exploitation
Sep 16, 2023Convolutional Neural Networks (CNNs) have brought revolutionary advances to many research areas due to their capacity of learning from raw data. However, when those methods are applied to non-controllable environments, many different factors can degrade the model's expected performance, such as unlabeled datasets with different levels of domain shift and category shift. Particularly, when both issues occur at the same time, we tackle this challenging setup as Open Set Domain Adaptation (OSDA) problem. In general, existing OSDA approaches focus their efforts only on aligning known classes or, if they already extract possible negative instances, use them as a new category learned with supervision during the course of training. We propose a novel way to improve OSDA approaches by extracting a high-confidence set of unknown instances and using it as a hard constraint to tighten the classification boundaries of OSDA methods. Especially, we adopt a new loss constraint evaluated in three different means, (1) directly with the pristine negative instances; (2) with randomly transformed negatives using data augmentation techniques; and (3) with synthetically generated negatives containing adversarial features. We assessed all approaches in an extensive set of experiments based on OVANet, where we could observe consistent improvements for two public benchmarks, the Office-31 and Office-Home datasets, yielding absolute gains of up to 1.3% for both Accuracy and H-Score on Office-31 and 5.8% for Accuracy and 4.7% for H-Score on Office-Home.
Trajectory Tracking Control of Skid-Steering Mobile Robots with Slip and Skid Compensation using Sliding-Mode Control and Deep Learning
Sep 16, 2023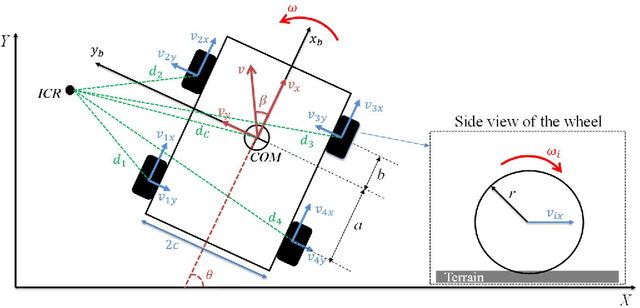
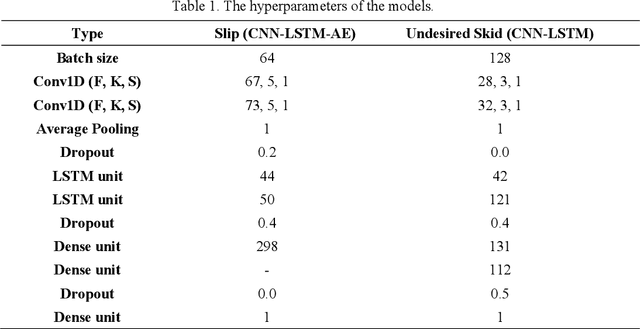
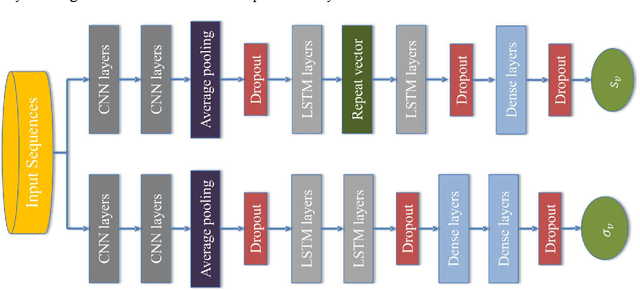
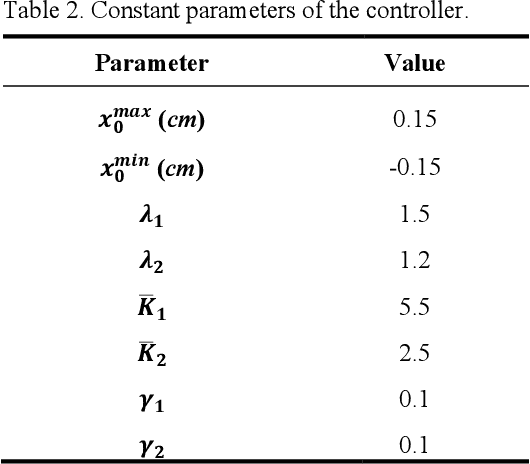
Slip and skid compensation is crucial for mobile robots' navigation in outdoor environments and uneven terrains. In addition to the general slipping and skidding hazards for mobile robots in outdoor environments, slip and skid cause uncertainty for the trajectory tracking system and put the validity of stability analysis at risk. Despite research in this field, having a real-world feasible online slip and skid compensation is still challenging due to the complexity of wheel-terrain interaction in outdoor environments. This paper presents a novel trajectory tracking technique with real-world feasible online slip and skid compensation at the vehicle-level for skid-steering mobile robots in outdoor environments. The sliding mode control technique is utilized to design a robust trajectory tracking system to be able to consider the parameter uncertainty of this type of robot. Two previously developed deep learning models [1], [2] are integrated into the control feedback loop to estimate the robot's slipping and undesired skidding and feed the compensator in a real-time manner. The main advantages of the proposed technique are (1) considering two slip-related parameters rather than the conventional three slip parameters at the wheel-level, and (2) having an online real-world feasible slip and skid compensator to be able to reduce the tracking errors in unforeseen environments. The experimental results show that the proposed controller with the slip and skid compensator improves the performance of the trajectory tracking system by more than 27%.
BodySLAM++: Fast and Tightly-Coupled Visual-Inertial Camera and Human Motion Tracking
Sep 03, 2023Robust, fast, and accurate human state - 6D pose and posture - estimation remains a challenging problem. For real-world applications, the ability to estimate the human state in real-time is highly desirable. In this paper, we present BodySLAM++, a fast, efficient, and accurate human and camera state estimation framework relying on visual-inertial data. BodySLAM++ extends an existing visual-inertial state estimation framework, OKVIS2, to solve the dual task of estimating camera and human states simultaneously. Our system improves the accuracy of both human and camera state estimation with respect to baseline methods by 26% and 12%, respectively, and achieves real-time performance at 15+ frames per second on an Intel i7-model CPU. Experiments were conducted on a custom dataset containing both ground truth human and camera poses collected with an indoor motion tracking system.
A Natural Gas Consumption Forecasting System for Continual Learning Scenarios based on Hoeffding Trees with Change Point Detection Mechanism
Sep 07, 2023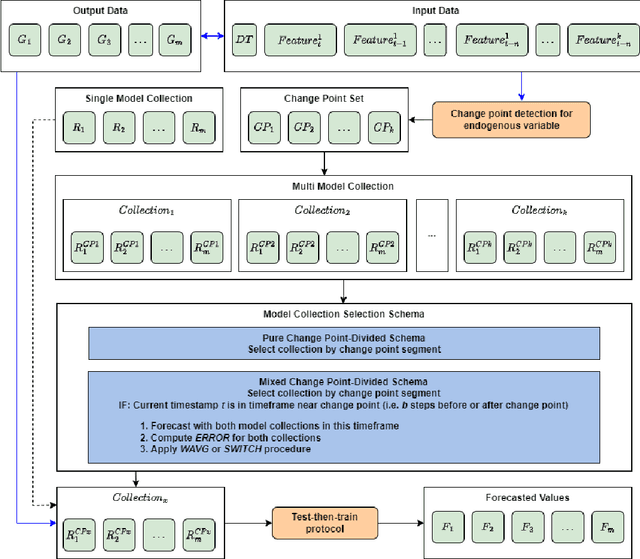
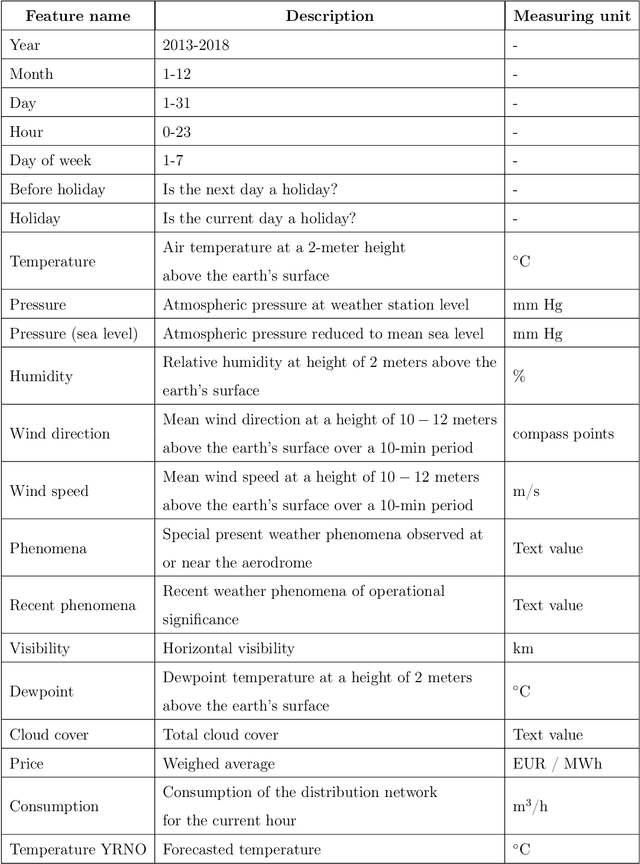
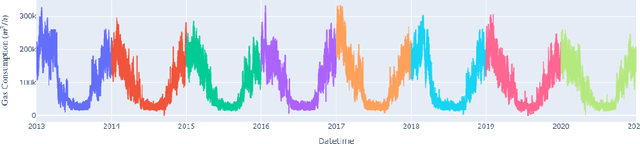
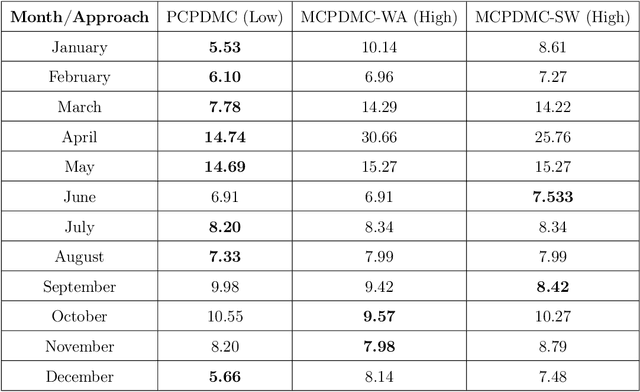
Forecasting natural gas consumption, considering seasonality and trends, is crucial in planning its supply and consumption and optimizing the cost of obtaining it, mainly by industrial entities. However, in times of threats to its supply, it is also a critical element that guarantees the supply of this raw material to meet individual consumers' needs, ensuring society's energy security. This article introduces a novel multistep ahead forecasting of natural gas consumption with change point detection integration for model collection selection with continual learning capabilities using data stream processing. The performance of the forecasting models based on the proposed approach is evaluated in a complex real-world use case of natural gas consumption forecasting. We employed Hoeffding tree predictors as forecasting models and the Pruned Exact Linear Time (PELT) algorithm for the change point detection procedure. The change point detection integration enables selecting a different model collection for successive time frames. Thus, three model collection selection procedures (with and without an error feedback loop) are defined and evaluated for forecasting scenarios with various densities of detected change points. These models were compared with change point agnostic baseline approaches. Our experiments show that fewer change points result in a lower forecasting error regardless of the model collection selection procedure employed. Also, simpler model collection selection procedures omitting forecasting error feedback leads to more robust forecasting models suitable for continual learning tasks.
TransNet: A Transfer Learning-Based Network for Human Action Recognition
Sep 13, 2023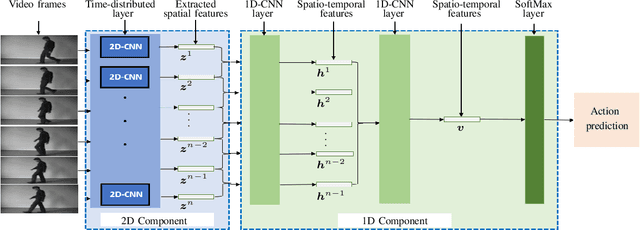
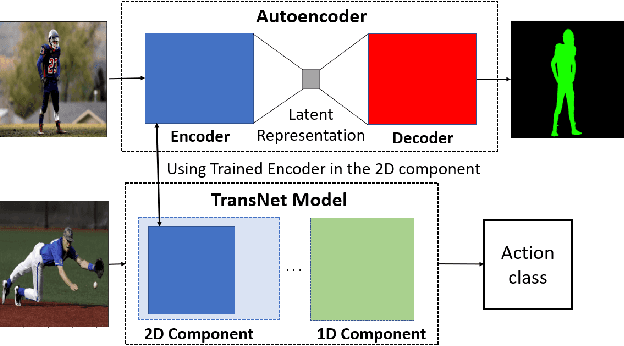

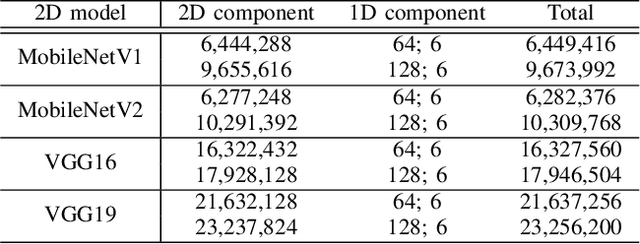
Human action recognition (HAR) is a high-level and significant research area in computer vision due to its ubiquitous applications. The main limitations of the current HAR models are their complex structures and lengthy training time. In this paper, we propose a simple yet versatile and effective end-to-end deep learning architecture, coined as TransNet, for HAR. TransNet decomposes the complex 3D-CNNs into 2D- and 1D-CNNs, where the 2D- and 1D-CNN components extract spatial features and temporal patterns in videos, respectively. Benefiting from its concise architecture, TransNet is ideally compatible with any pretrained state-of-the-art 2D-CNN models in other fields, being transferred to serve the HAR task. In other words, it naturally leverages the power and success of transfer learning for HAR, bringing huge advantages in terms of efficiency and effectiveness. Extensive experimental results and the comparison with the state-of-the-art models demonstrate the superior performance of the proposed TransNet in HAR in terms of flexibility, model complexity, training speed and classification accuracy.
Event-Driven Imaging in Turbid Media: A Confluence of Optoelectronics and Neuromorphic Computation
Sep 13, 2023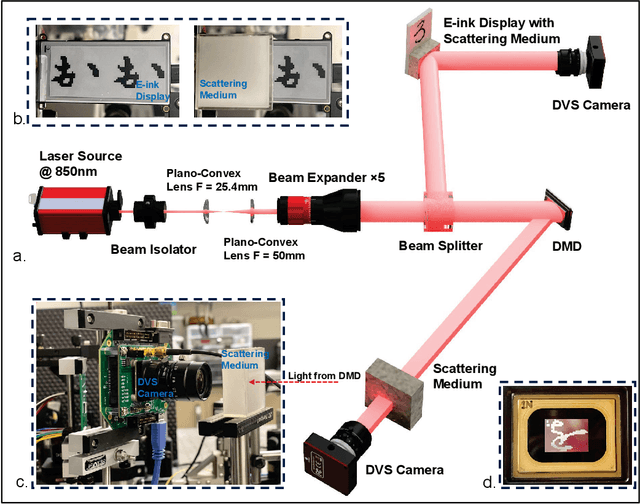
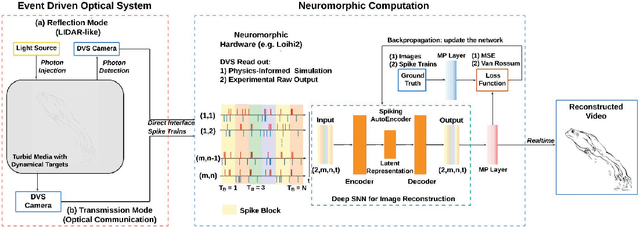
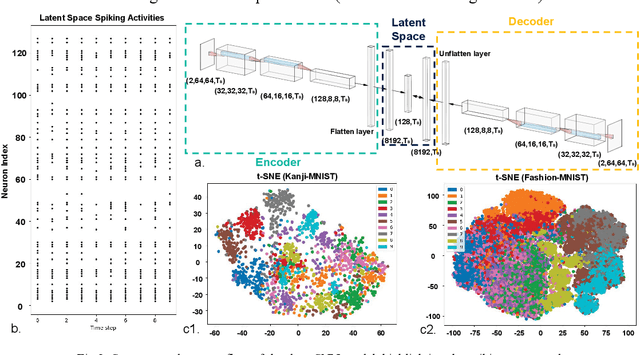

In this paper a new optical-computational method is introduced to unveil images of targets whose visibility is severely obscured by light scattering in dense, turbid media. The targets of interest are taken to be dynamic in that their optical properties are time-varying whether stationary in space or moving. The scheme, to our knowledge the first of its kind, is human vision inspired whereby diffuse photons collected from the turbid medium are first transformed to spike trains by a dynamic vision sensor as in the retina, and image reconstruction is then performed by a neuromorphic computing approach mimicking the brain. We combine benchtop experimental data in both reflection (backscattering) and transmission geometries with support from physics-based simulations to develop a neuromorphic computational model and then apply this for image reconstruction of different MNIST characters and image sets by a dedicated deep spiking neural network algorithm. Image reconstruction is achieved under conditions of turbidity where an original image is unintelligible to the human eye or a digital video camera, yet clearly and quantifiable identifiable when using the new neuromorphic computational approach.