 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDB3D-L: Depth-aware BEV Feature Transformation for Accurate 3D Lane Detection
May 19, 2025



3D Lane detection plays an important role in autonomous driving. Recent advances primarily build Birds-Eye-View (BEV) feature from front-view (FV) images to perceive 3D information of Lane more effectively. However, constructing accurate BEV information from FV image is limited due to the lacking of depth information, causing previous works often rely heavily on the assumption of a flat ground plane. Leveraging monocular depth estimation to assist in constructing BEV features is less constrained, but existing methods struggle to effectively integrate the two tasks. To address the above issue, in this paper, an accurate 3D lane detection method based on depth-aware BEV feature transtormation is proposed. In detail, an effective feature extraction module is designed, in which a Depth Net is integrated to obtain the vital depth information for 3D perception, thereby simplifying the complexity of view transformation. Subquently a feature reduce module is proposed to reduce height dimension of FV features and depth features, thereby enables effective fusion of crucial FV features and depth features. Then a fusion module is designed to build BEV feature from prime FV feature and depth information. The proposed method performs comparably with state-of-the-art methods on both synthetic Apollo, realistic OpenLane datasets.
An Explicit Method for Fast Monocular Depth Recovery in Corridor Environments
Sep 14, 2023



Monocular cameras are extensively employed in indoor robotics, but their performance is limited in visual odometry, depth estimation, and related applications due to the absence of scale information.Depth estimation refers to the process of estimating a dense depth map from the corresponding input image, existing researchers mostly address this issue through deep learning-based approaches, yet their inference speed is slow, leading to poor real-time capabilities. To tackle this challenge, we propose an explicit method for rapid monocular depth recovery specifically designed for corridor environments, leveraging the principles of nonlinear optimization. We adopt the virtual camera assumption to make full use of the prior geometric features of the scene. The depth estimation problem is transformed into an optimization problem by minimizing the geometric residual. Furthermore, a novel depth plane construction technique is introduced to categorize spatial points based on their possible depths, facilitating swift depth estimation in enclosed structural scenarios, such as corridors. We also propose a new corridor dataset, named Corr\_EH\_z, which contains images as captured by the UGV camera of a variety of corridors. An exhaustive set of experiments in different corridors reveal the efficacy of the proposed algorithm.
Towards A Deep Insight into Landmark-based Visual Place Recognition: Methodology and Practice
Aug 22, 2018

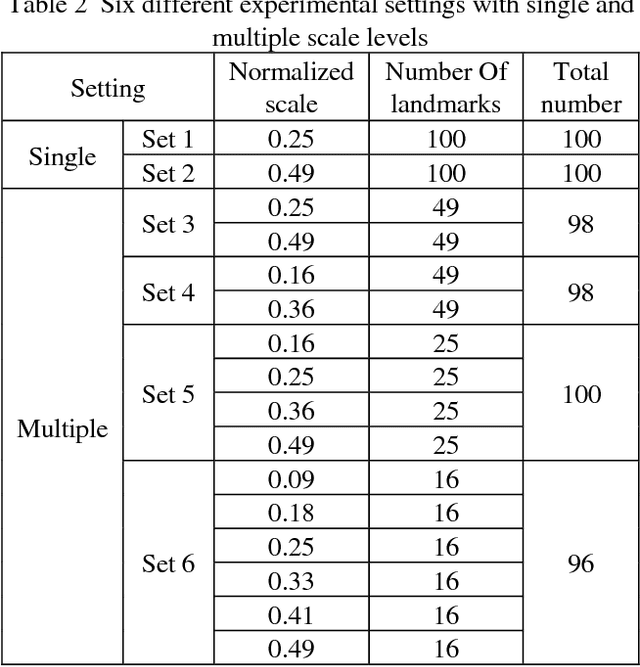
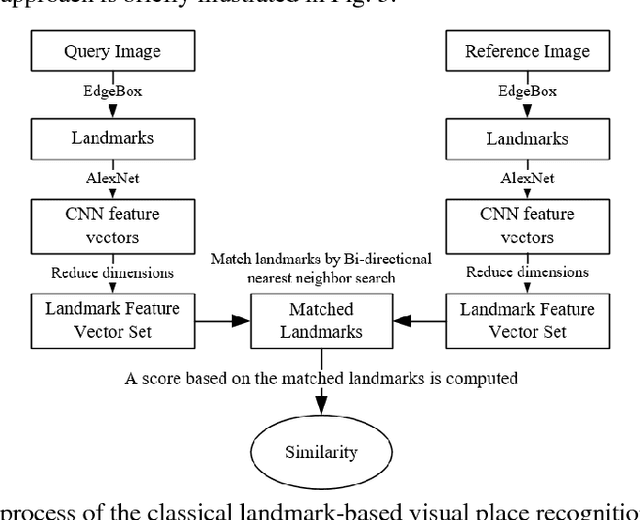
In this paper, we address the problem of landmark-based visual place recognition. In the state-of-the-art method, accurate object proposal algorithms are first leveraged for generating a set of local regions containing particular landmarks with high confidence. Then, these candidate regions are represented by deep features and pairwise matching is performed in an exhaustive manner for the similarity measure. Despite its success, conventional object proposal methods usually produce massive landmark-dependent image patches exhibiting significant distribution variance in scale and overlap. As a result, the inconsistency in landmark distributions tends to produce biased similarity between pairwise images yielding the suboptimal performance. In order to gain an insight into the landmark-based place recognition scheme, we conduct a comprehensive study in which the influence of landmark scales and the proportion of overlap on the recognition performance is explored. More specifically, we thoroughly study the exhaustive search based landmark matching mechanism, and thus derive three-fold important observations in terms of the beneficial effect of specific landmark generation strategies. Inspired by the above observations, a simple yet effective dense sampling based scheme is presented for accurate place recognition in this paper. Different from the conventional object proposal strategy, we generate local landmarks of multiple scales with uniform distribution from entire image by dense sampling, and subsequently perform multi-scale fusion on the densely sampled landmarks for similarity measure. The experimental results on three challenging datasets demonstrate that the recognition performance can be significantly improved by our efficient method in which the landmarks are appropriately produced for accurate pairwise matching.