 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robustness Verification of Deep Neural Networks using Star-Based Reachability Analysis with Variable-Length Time Series Input
Jul 26, 2023
Data-driven, neural network (NN) based anomaly detection and predictive maintenance are emerging research areas. NN-based analytics of time-series data offer valuable insights into past behaviors and estimates of critical parameters like remaining useful life (RUL) of equipment and state-of-charge (SOC) of batteries. However, input time series data can be exposed to intentional or unintentional noise when passing through sensors, necessitating robust validation and verification of these NNs. This paper presents a case study of the robustness verification approach for time series regression NNs (TSRegNN) using set-based formal methods. It focuses on utilizing variable-length input data to streamline input manipulation and enhance network architecture generalizability. The method is applied to two data sets in the Prognostics and Health Management (PHM) application areas: (1) SOC estimation of a Lithium-ion battery and (2) RUL estimation of a turbine engine. The NNs' robustness is checked using star-based reachability analysis, and several performance measures evaluate the effect of bounded perturbations in the input on network outputs, i.e., future outcomes. Overall, the paper offers a comprehensive case study for validating and verifying NN-based analytics of time-series data in real-world applications, emphasizing the importance of robustness testing for accurate and reliable predictions, especially considering the impact of noise on future outcomes.
Machine Learning for enhancing Wind Field Resolution in Complex Terrain
Sep 18, 2023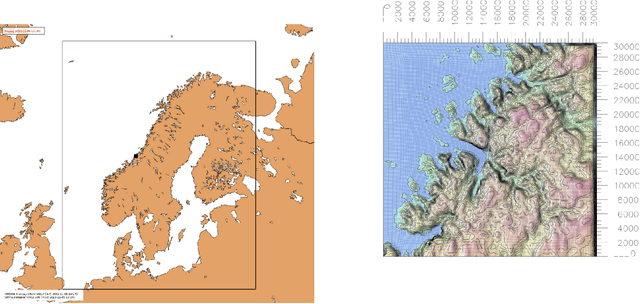


Atmospheric flows are governed by a broad variety of spatio-temporal scales, thus making real-time numerical modeling of such turbulent flows in complex terrain at high resolution computationally intractable. In this study, we demonstrate a neural network approach motivated by Enhanced Super-Resolution Generative Adversarial Networks to upscale low-resolution wind fields to generate high-resolution wind fields in an actual wind farm in Bessaker, Norway. The neural network-based model is shown to successfully reconstruct fully resolved 3D velocity fields from a coarser scale while respecting the local terrain and that it easily outperforms trilinear interpolation. We also demonstrate that by using appropriate cost function based on domain knowledge, we can alleviate the use of adversarial training.
Distilling HuBERT with LSTMs via Decoupled Knowledge Distillation
Sep 18, 2023Much research effort is being applied to the task of compressing the knowledge of self-supervised models, which are powerful, yet large and memory consuming. In this work, we show that the original method of knowledge distillation (and its more recently proposed extension, decoupled knowledge distillation) can be applied to the task of distilling HuBERT. In contrast to methods that focus on distilling internal features, this allows for more freedom in the network architecture of the compressed model. We thus propose to distill HuBERT's Transformer layers into an LSTM-based distilled model that reduces the number of parameters even below DistilHuBERT and at the same time shows improved performance in automatic speech recognition.
Quantum Wasserstein GANs for State Preparation at Unseen Points of a Phase Diagram
Sep 18, 2023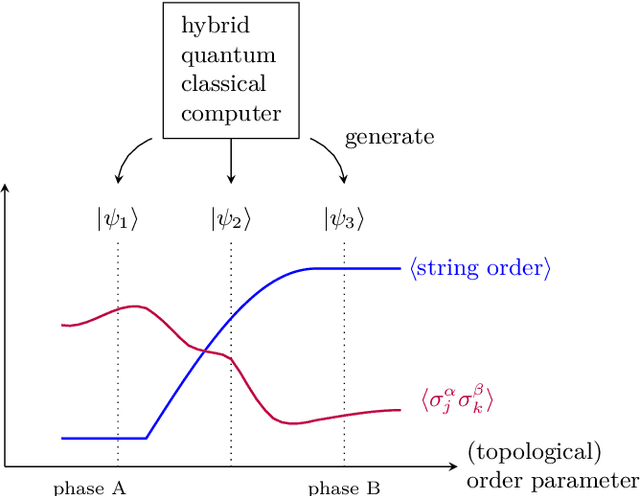
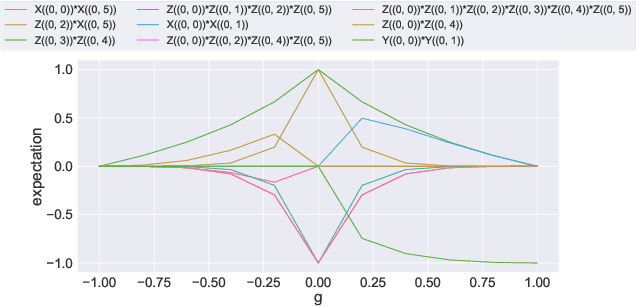
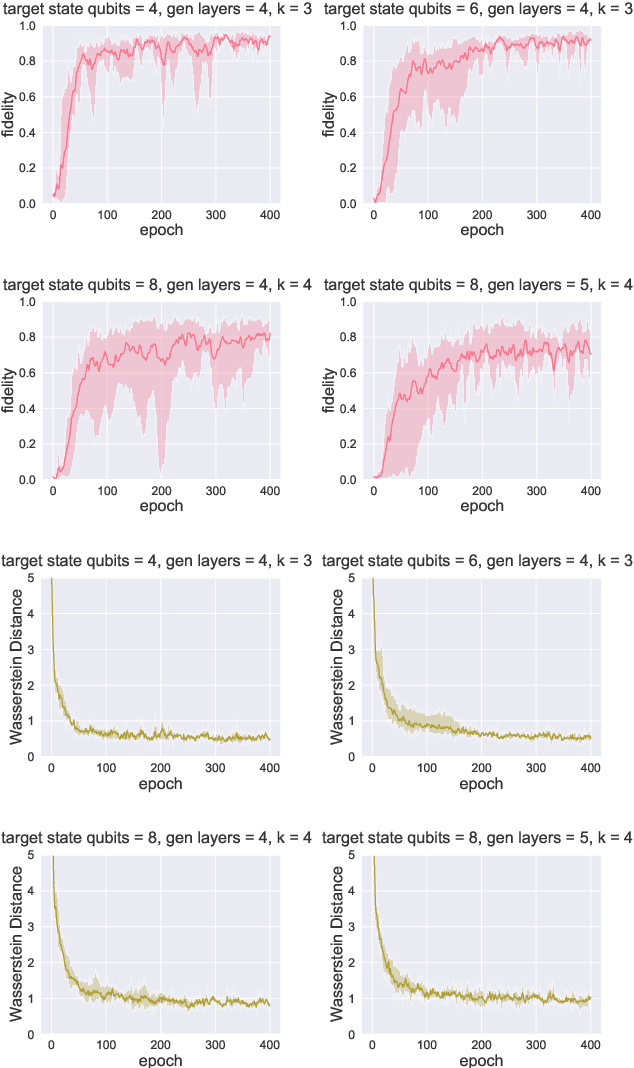
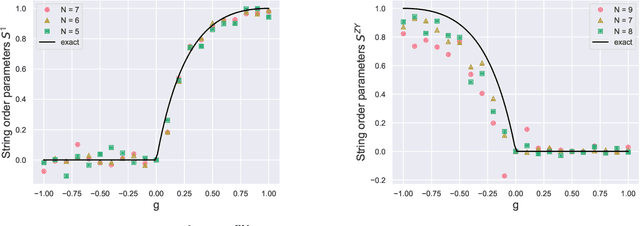
Generative models and in particular Generative Adversarial Networks (GANs) have become very popular and powerful data generation tool. In recent years, major progress has been made in extending this concept into the quantum realm. However, most of the current methods focus on generating classes of states that were supplied in the input set and seen at the training time. In this work, we propose a new hybrid classical-quantum method based on quantum Wasserstein GANs that overcomes this limitation. It allows to learn the function governing the measurement expectations of the supplied states and generate new states, that were not a part of the input set, but which expectations follow the same underlying function.
Colour Passing Revisited: Lifted Model Construction with Commutative Factors
Sep 20, 2023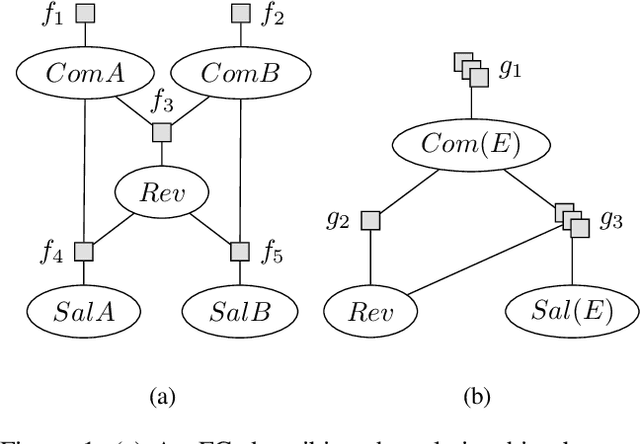
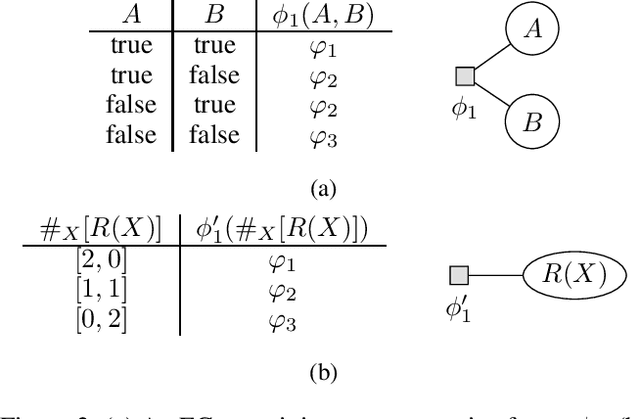
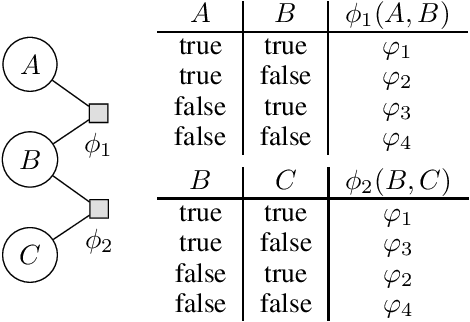
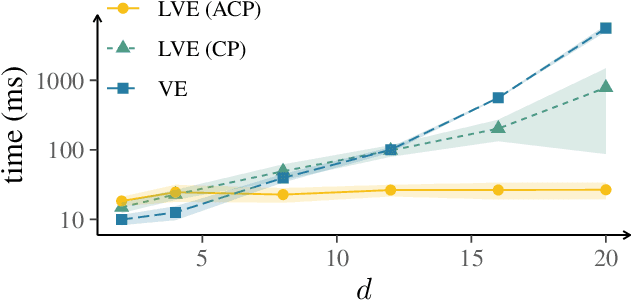
Lifted probabilistic inference exploits symmetries in a probabilistic model to allow for tractable probabilistic inference with respect to domain sizes. To apply lifted inference, a lifted representation has to be obtained, and to do so, the so-called colour passing algorithm is the state of the art. The colour passing algorithm, however, is bound to a specific inference algorithm and we found that it ignores commutativity of factors while constructing a lifted representation. We contribute a modified version of the colour passing algorithm that uses logical variables to construct a lifted representation independent of a specific inference algorithm while at the same time exploiting commutativity of factors during an offline-step. Our proposed algorithm efficiently detects more symmetries than the state of the art and thereby drastically increases compression, yielding significantly faster online query times for probabilistic inference when the resulting model is applied.
A Neural TTS System with Parallel Prosody Transfer from Unseen Speakers
Sep 20, 2023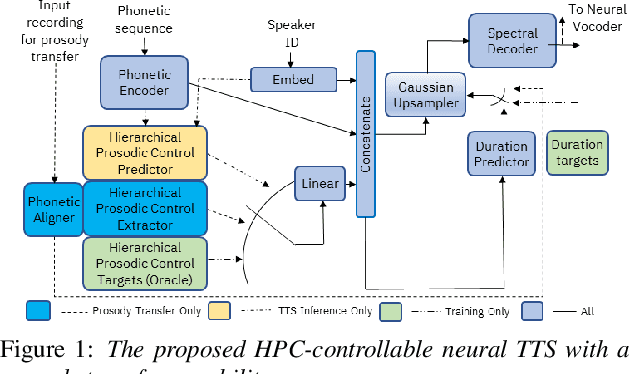
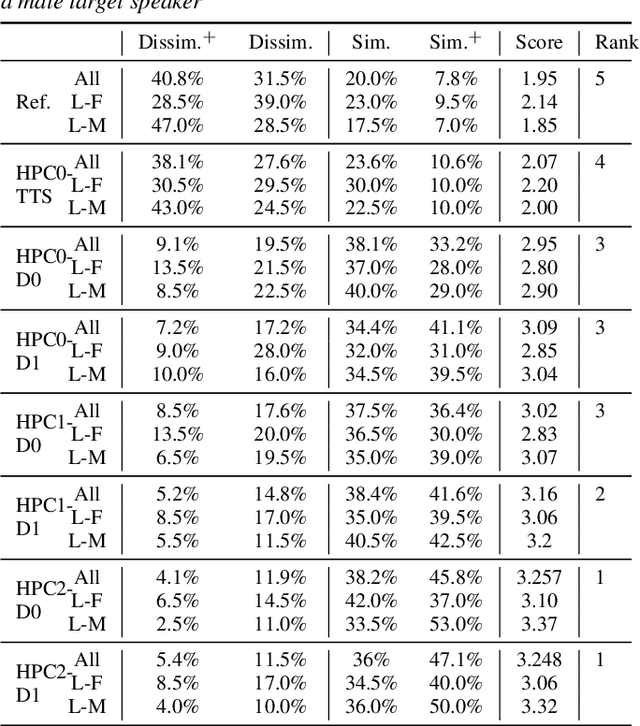
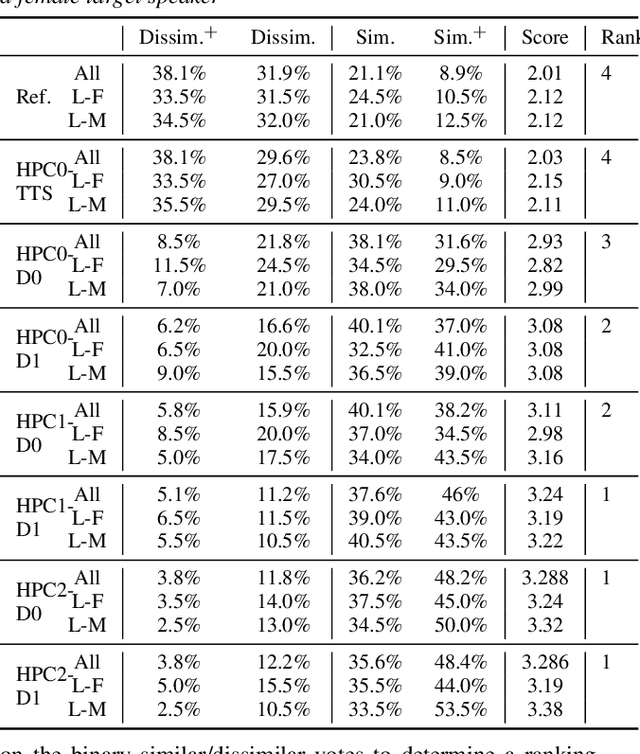
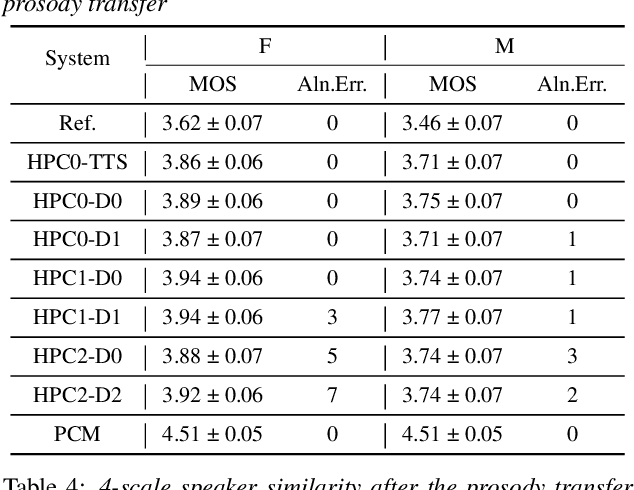
Modern neural TTS systems are capable of generating natural and expressive speech when provided with sufficient amounts of training data. Such systems can be equipped with prosody-control functionality, allowing for more direct shaping of the speech output at inference time. In some TTS applications, it may be desirable to have an option that guides the TTS system with an ad-hoc speech recording exemplar to impose an implicit fine-grained, user-preferred prosodic realization for certain input prompts. In this work we present a first-of-its-kind neural TTS system equipped with such functionality to transfer the prosody from a parallel text recording from an unseen speaker. We demonstrate that the proposed system can precisely transfer the speech prosody from novel speakers to various trained TTS voices with no quality degradation, while preserving the target TTS speakers' identity, as evaluated by a set of subjective listening experiments.
* Presented at Interspeech 2023
A Variational Auto-Encoder Enabled Multi-Band Channel Prediction Scheme for Indoor Localization
Sep 19, 2023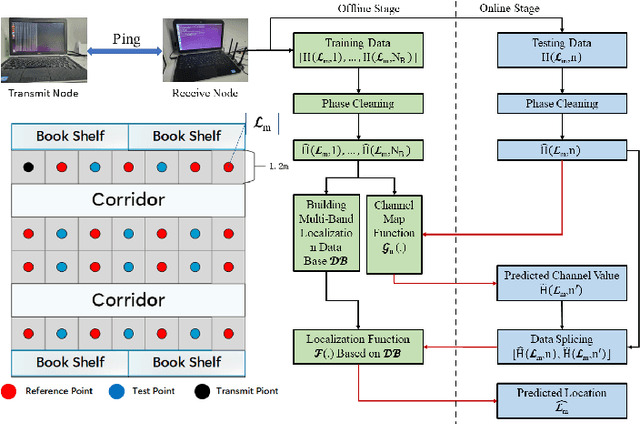
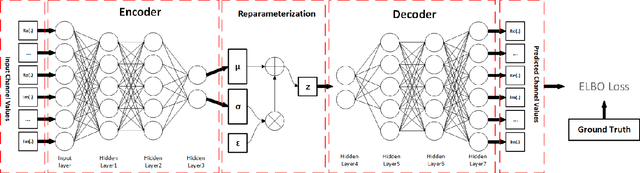
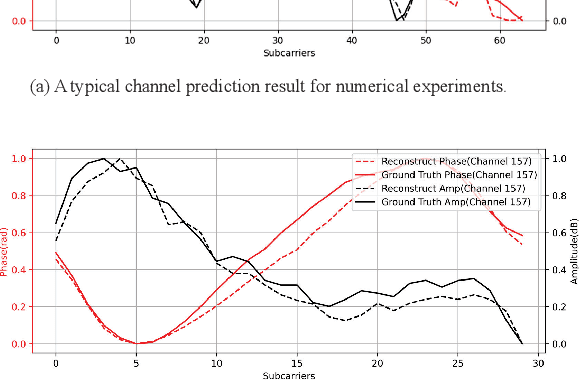
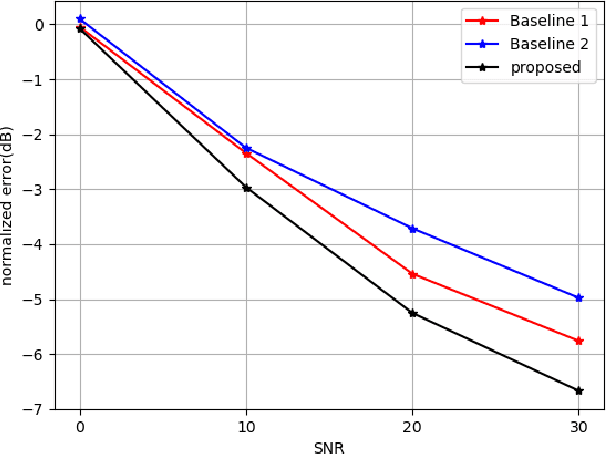
Indoor localization is getting increasing demands for various cutting-edged technologies, like Virtual/Augmented reality and smart home. Traditional model-based localization suffers from significant computational overhead, so fingerprint localization is getting increasing attention, which needs lower computation cost after the fingerprint database is built. However, the accuracy of indoor localization is limited by the complicated indoor environment which brings the multipath signal refraction. In this paper, we provided a scheme to improve the accuracy of indoor fingerprint localization from the frequency domain by predicting the channel state information (CSI) values from another transmitting channel and spliced the multi-band information together to get more precise localization results. We tested our proposed scheme on COST 2100 simulation data and real time orthogonal frequency division multiplexing (OFDM) WiFi data collected from an office scenario.
Oracle Complexity Reduction for Model-free LQR: A Stochastic Variance-Reduced Policy Gradient Approach
Sep 19, 2023We investigate the problem of learning an $\epsilon$-approximate solution for the discrete-time Linear Quadratic Regulator (LQR) problem via a Stochastic Variance-Reduced Policy Gradient (SVRPG) approach. Whilst policy gradient methods have proven to converge linearly to the optimal solution of the model-free LQR problem, the substantial requirement for two-point cost queries in gradient estimations may be intractable, particularly in applications where obtaining cost function evaluations at two distinct control input configurations is exceptionally costly. To this end, we propose an oracle-efficient approach. Our method combines both one-point and two-point estimations in a dual-loop variance-reduced algorithm. It achieves an approximate optimal solution with only $O\left(\log\left(1/\epsilon\right)^{\beta}\right)$ two-point cost information for $\beta \in (0,1)$.
Accelerating Diffusion-Based Text-to-Audio Generation with Consistency Distillation
Sep 19, 2023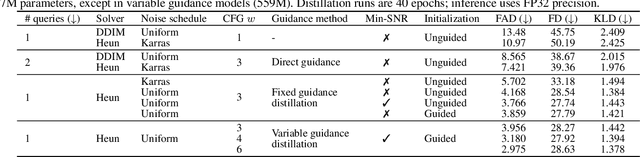
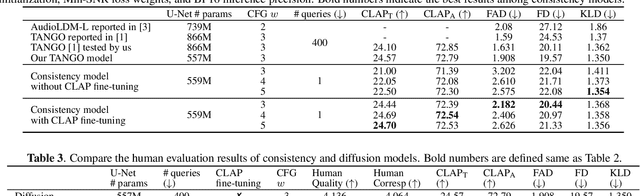
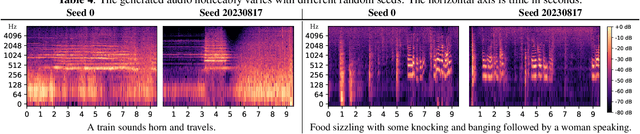
Diffusion models power a vast majority of text-to-audio (TTA) generation methods. Unfortunately, these models suffer from slow inference speed due to iterative queries to the underlying denoising network, thus unsuitable for scenarios with inference time or computational constraints. This work modifies the recently proposed consistency distillation framework to train TTA models that require only a single neural network query. In addition to incorporating classifier-free guidance into the distillation process, we leverage the availability of generated audio during distillation training to fine-tune the consistency TTA model with novel loss functions in the audio space, such as the CLAP score. Our objective and subjective evaluation results on the AudioCaps dataset show that consistency models retain diffusion models' high generation quality and diversity while reducing the number of queries by a factor of 400.
Parameter-Varying Koopman Operator for Nonlinear System Modeling and Control
Sep 19, 2023This paper proposes a novel approach for modeling and controlling nonlinear systems with varying parameters. The approach introduces the use of a parameter-varying Koopman operator (PVKO) in a lifted space, which provides an efficient way to understand system behavior and design control algorithms that account for underlying dynamics and changing parameters. The PVKO builds on a conventional Koopman model by incorporating local time-invariant linear systems through interpolation within the lifted space. This paper outlines a procedure for identifying the PVKO and designing a model predictive control using the identified PVKO model. Simulation results demonstrate that the proposed approach improves model accuracy and enables predictions based on future parameter information. The feasibility and stability of the proposed control approach are analyzed, and their effectiveness is demonstrated through simulation.