 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Multi-Label Feature Selection Using Adaptive and Transformed Relevance
Sep 26, 2023

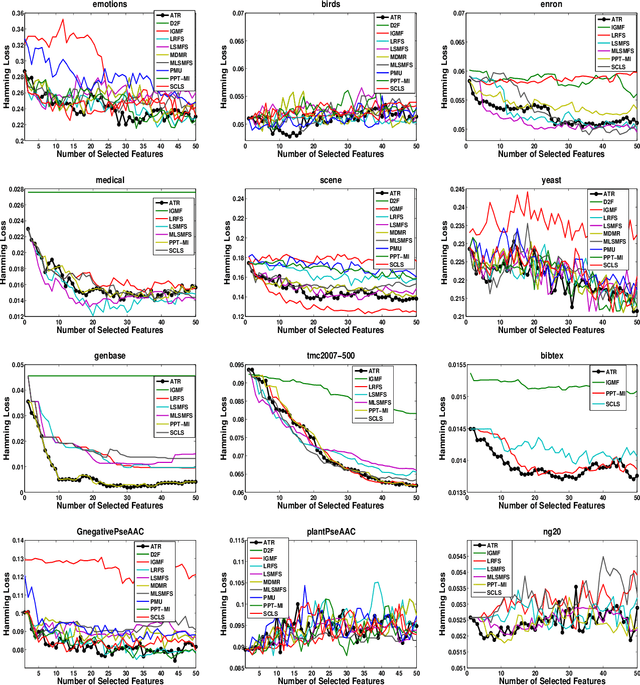
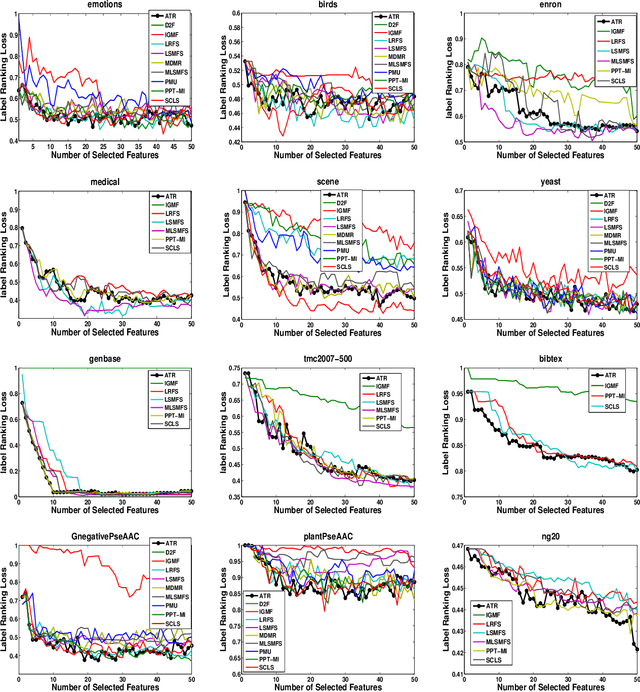
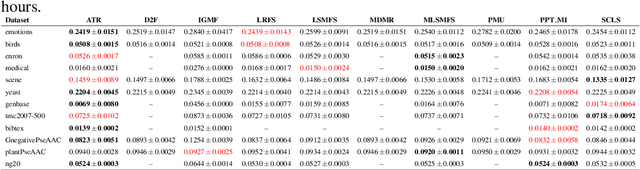
Multi-label learning has emerged as a crucial paradigm in data analysis, addressing scenarios where instances are associated with multiple class labels simultaneously. With the growing prevalence of multi-label data across diverse applications, such as text and image classification, the significance of multi-label feature selection has become increasingly evident. This paper presents a novel information-theoretical filter-based multi-label feature selection, called ATR, with a new heuristic function. Incorporating a combinations of algorithm adaptation and problem transformation approaches, ATR ranks features considering individual labels as well as abstract label space discriminative powers. Our experimental studies encompass twelve benchmarks spanning various domains, demonstrating the superiority of our approach over ten state-of-the-art information-theoretical filter-based multi-label feature selection methods across six evaluation metrics. Furthermore, our experiments affirm the scalability of ATR for benchmarks characterized by extensive feature and label spaces. The codes are available at https://github.com/Sadegh28/ATR
ViCGCN: Graph Convolutional Network with Contextualized Language Models for Social Media Mining in Vietnamese
Sep 06, 2023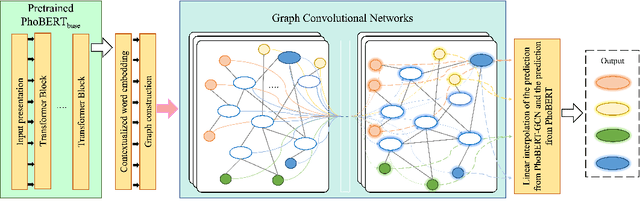
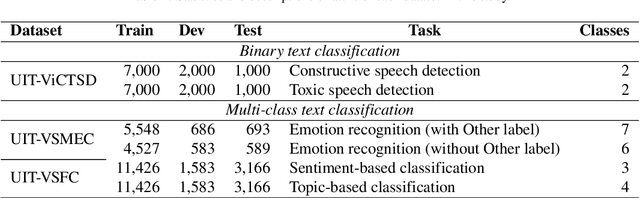
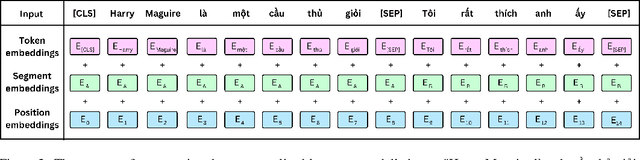
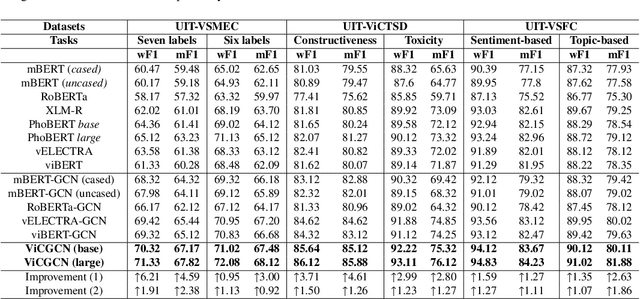
Social media processing is a fundamental task in natural language processing with numerous applications. As Vietnamese social media and information science have grown rapidly, the necessity of information-based mining on Vietnamese social media has become crucial. However, state-of-the-art research faces several significant drawbacks, including imbalanced data and noisy data on social media platforms. Imbalanced and noisy are two essential issues that need to be addressed in Vietnamese social media texts. Graph Convolutional Networks can address the problems of imbalanced and noisy data in text classification on social media by taking advantage of the graph structure of the data. This study presents a novel approach based on contextualized language model (PhoBERT) and graph-based method (Graph Convolutional Networks). In particular, the proposed approach, ViCGCN, jointly trained the power of Contextualized embeddings with the ability of Graph Convolutional Networks, GCN, to capture more syntactic and semantic dependencies to address those drawbacks. Extensive experiments on various Vietnamese benchmark datasets were conducted to verify our approach. The observation shows that applying GCN to BERTology models as the final layer significantly improves performance. Moreover, the experiments demonstrate that ViCGCN outperforms 13 powerful baseline models, including BERTology models, fusion BERTology and GCN models, other baselines, and SOTA on three benchmark social media datasets. Our proposed ViCGCN approach demonstrates a significant improvement of up to 6.21%, 4.61%, and 2.63% over the best Contextualized Language Models, including multilingual and monolingual, on three benchmark datasets, UIT-VSMEC, UIT-ViCTSD, and UIT-VSFC, respectively. Additionally, our integrated model ViCGCN achieves the best performance compared to other BERTology integrated with GCN models.
Imbalanced Multi-label Classification for Business-related Text with Moderately Large Label Spaces
Jun 12, 2023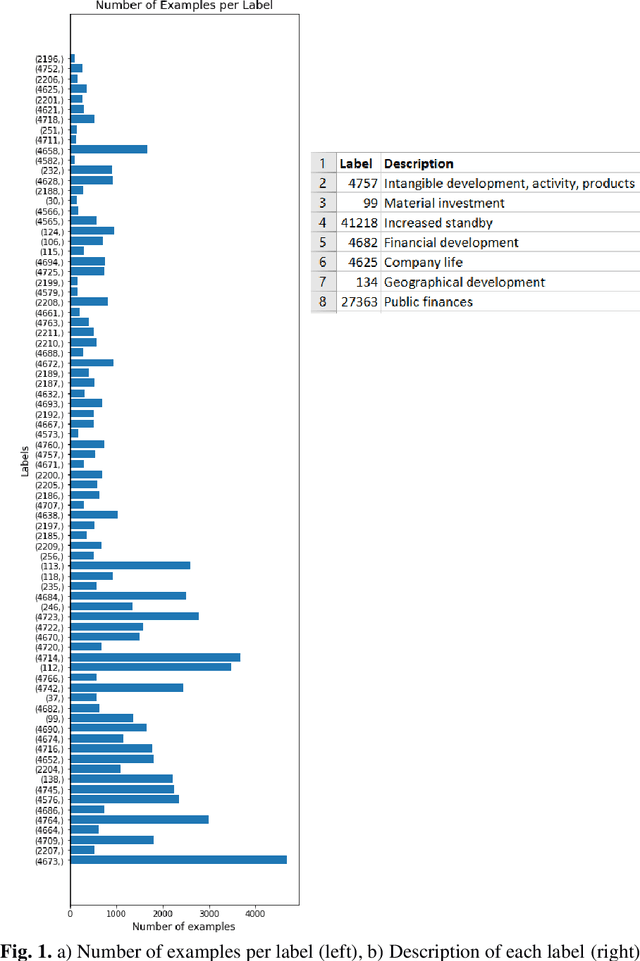
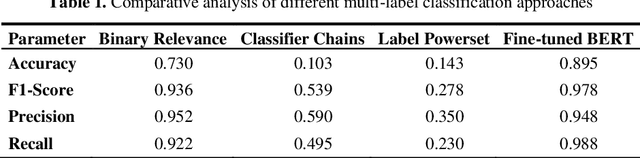
In this study, we compared the performance of four different methods for multi label text classification using a specific imbalanced business dataset. The four methods we evaluated were fine tuned BERT, Binary Relevance, Classifier Chains, and Label Powerset. The results show that fine tuned BERT outperforms the other three methods by a significant margin, achieving high values of accuracy, F1 Score, Precision, and Recall. Binary Relevance also performs well on this dataset, while Classifier Chains and Label Powerset demonstrate relatively poor performance. These findings highlight the effectiveness of fine tuned BERT for multi label text classification tasks, and suggest that it may be a useful tool for businesses seeking to analyze complex and multifaceted texts.
Evaluating Unsupervised Text Classification: Zero-shot and Similarity-based Approaches
Nov 29, 2022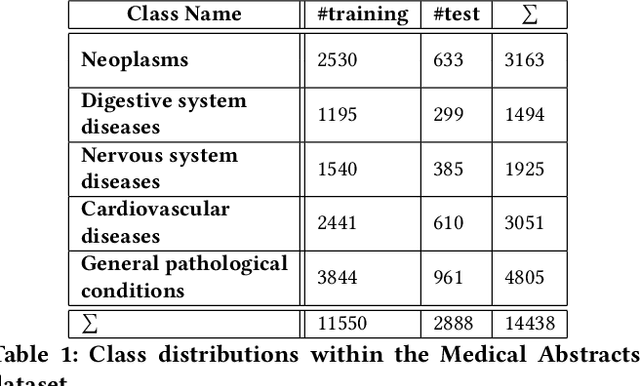
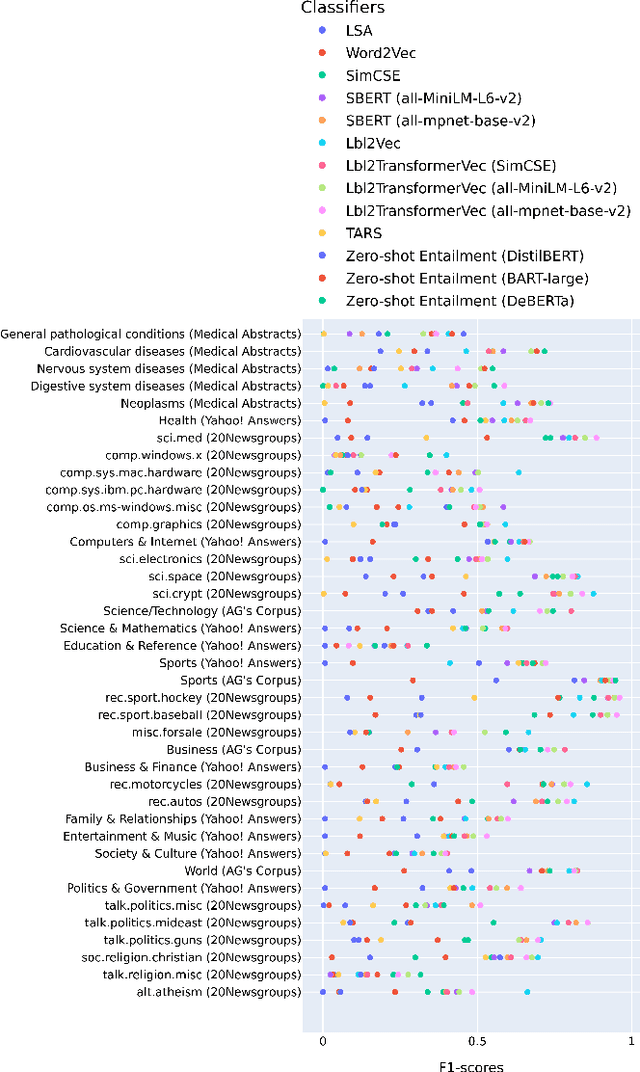
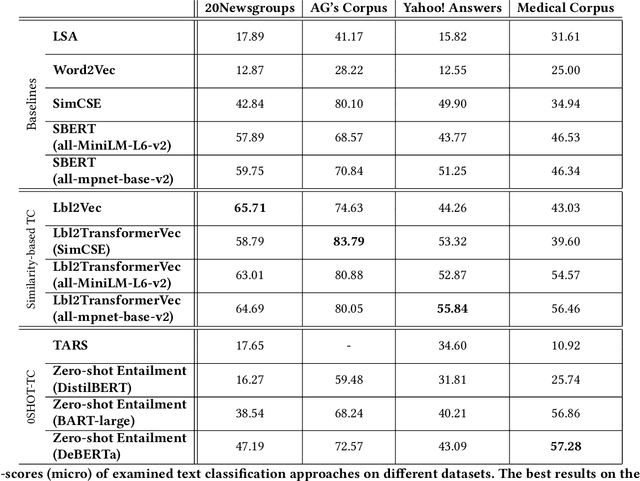
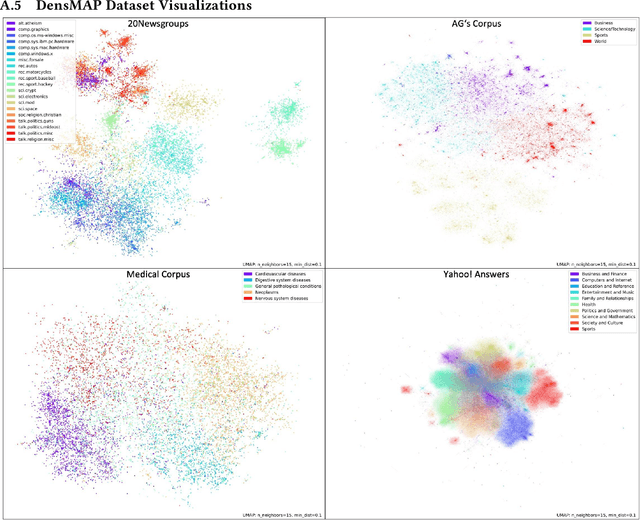
Text classification of unseen classes is a challenging Natural Language Processing task and is mainly attempted using two different types of approaches. Similarity-based approaches attempt to classify instances based on similarities between text document representations and class description representations. Zero-shot text classification approaches aim to generalize knowledge gained from a training task by assigning appropriate labels of unknown classes to text documents. Although existing studies have already investigated individual approaches to these categories, the experiments in literature do not provide a consistent comparison. This paper addresses this gap by conducting a systematic evaluation of different similarity-based and zero-shot approaches for text classification of unseen classes. Different state-of-the-art approaches are benchmarked on four text classification datasets, including a new dataset from the medical domain. Additionally, novel SimCSE and SBERT-based baselines are proposed, as other baselines used in existing work yield weak classification results and are easily outperformed. Finally, the novel similarity-based Lbl2TransformerVec approach is presented, which outperforms previous state-of-the-art approaches in unsupervised text classification. Our experiments show that similarity-based approaches significantly outperform zero-shot approaches in most cases. Additionally, using SimCSE or SBERT embeddings instead of simpler text representations increases similarity-based classification results even further.
Sample Size in Natural Language Processing within Healthcare Research
Sep 05, 2023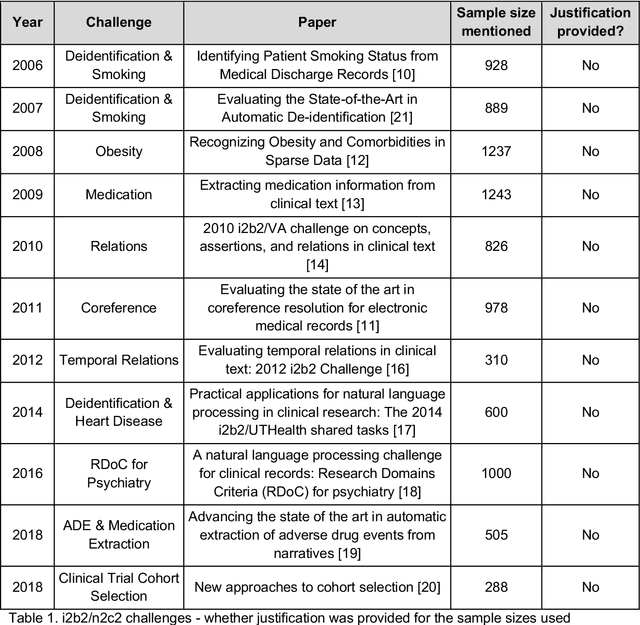
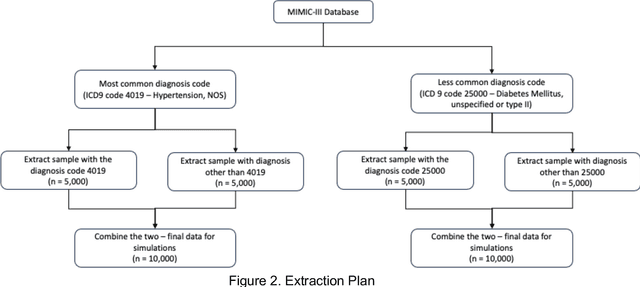
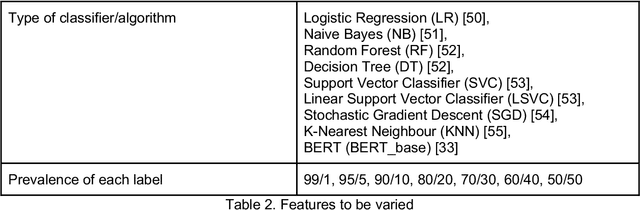
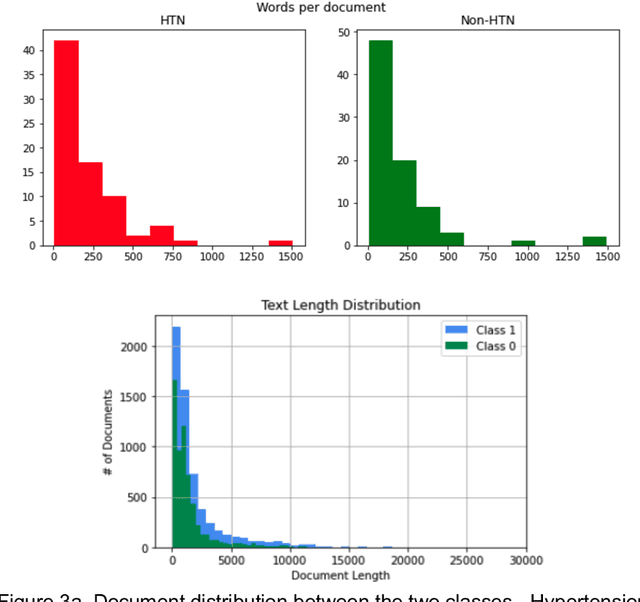
Sample size calculation is an essential step in most data-based disciplines. Large enough samples ensure representativeness of the population and determine the precision of estimates. This is true for most quantitative studies, including those that employ machine learning methods, such as natural language processing, where free-text is used to generate predictions and classify instances of text. Within the healthcare domain, the lack of sufficient corpora of previously collected data can be a limiting factor when determining sample sizes for new studies. This paper tries to address the issue by making recommendations on sample sizes for text classification tasks in the healthcare domain. Models trained on the MIMIC-III database of critical care records from Beth Israel Deaconess Medical Center were used to classify documents as having or not having Unspecified Essential Hypertension, the most common diagnosis code in the database. Simulations were performed using various classifiers on different sample sizes and class proportions. This was repeated for a comparatively less common diagnosis code within the database of diabetes mellitus without mention of complication. Smaller sample sizes resulted in better results when using a K-nearest neighbours classifier, whereas larger sample sizes provided better results with support vector machines and BERT models. Overall, a sample size larger than 1000 was sufficient to provide decent performance metrics. The simulations conducted within this study provide guidelines that can be used as recommendations for selecting appropriate sample sizes and class proportions, and for predicting expected performance, when building classifiers for textual healthcare data. The methodology used here can be modified for sample size estimates calculations with other datasets.
Global Hierarchical Neural Networks using Hierarchical Softmax
Aug 02, 2023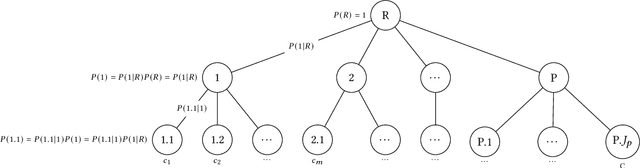
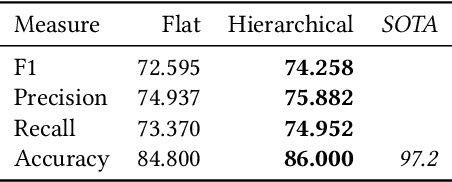
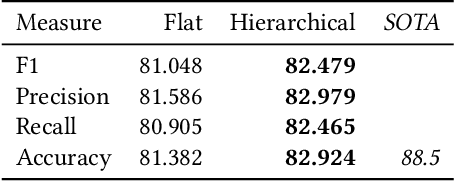
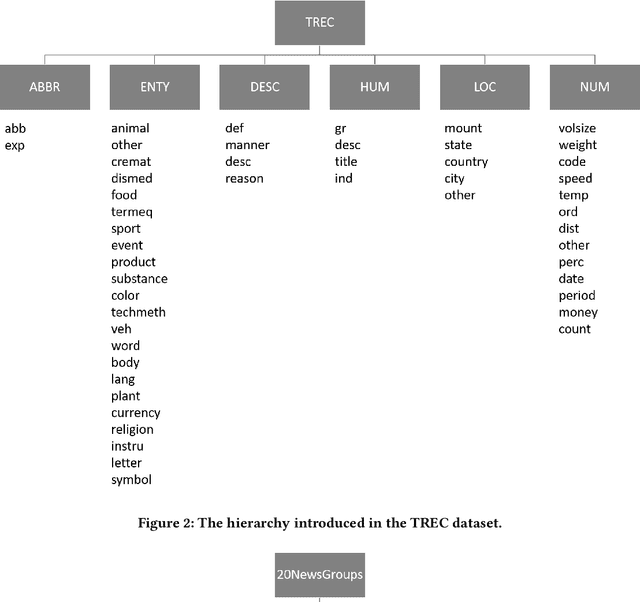
This paper presents a framework in which hierarchical softmax is used to create a global hierarchical classifier. The approach is applicable for any classification task where there is a natural hierarchy among classes. We show empirical results on four text classification datasets. In all datasets the hierarchical softmax improved on the regular softmax used in a flat classifier in terms of macro-F1 and macro-recall. In three out of four datasets hierarchical softmax achieved a higher micro-accuracy and macro-precision.
Towards Semi-Structured Automatic ICD Coding via Tree-based Contrastive Learning
Oct 14, 2023
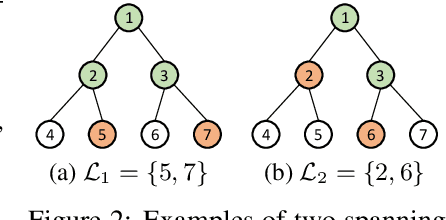
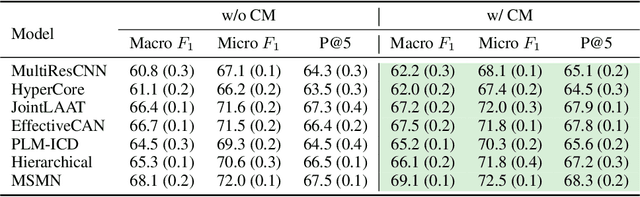
Automatic coding of International Classification of Diseases (ICD) is a multi-label text categorization task that involves extracting disease or procedure codes from clinical notes. Despite the application of state-of-the-art natural language processing (NLP) techniques, there are still challenges including limited availability of data due to privacy constraints and the high variability of clinical notes caused by different writing habits of medical professionals and various pathological features of patients. In this work, we investigate the semi-structured nature of clinical notes and propose an automatic algorithm to segment them into sections. To address the variability issues in existing ICD coding models with limited data, we introduce a contrastive pre-training approach on sections using a soft multi-label similarity metric based on tree edit distance. Additionally, we design a masked section training strategy to enable ICD coding models to locate sections related to ICD codes. Extensive experimental results demonstrate that our proposed training strategies effectively enhance the performance of existing ICD coding methods.
LIME: Weakly-Supervised Text Classification Without Seeds
Oct 13, 2022
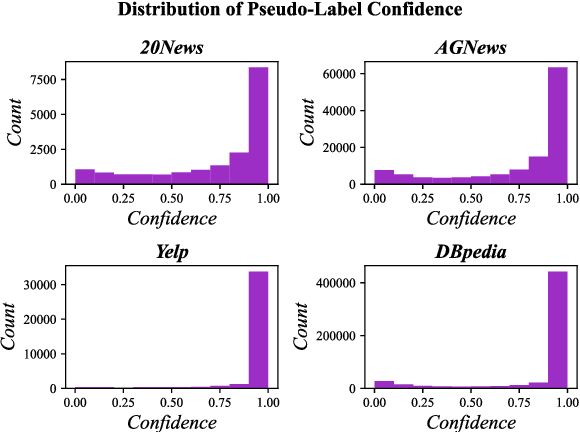
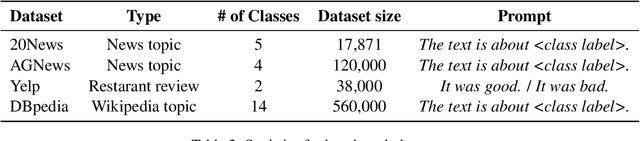
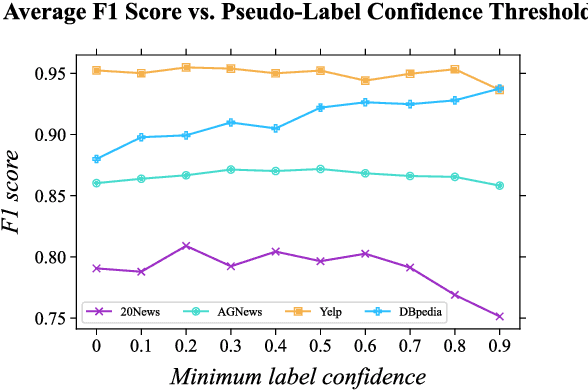
In weakly-supervised text classification, only label names act as sources of supervision. Predominant approaches to weakly-supervised text classification utilize a two-phase framework, where test samples are first assigned pseudo-labels and are then used to train a neural text classifier. In most previous work, the pseudo-labeling step is dependent on obtaining seed words that best capture the relevance of each class label. We present LIME, a framework for weakly-supervised text classification that entirely replaces the brittle seed-word generation process with entailment-based pseudo-classification. We find that combining weakly-supervised classification and textual entailment mitigates shortcomings of both, resulting in a more streamlined and effective classification pipeline. With just an off-the-shelf textual entailment model, LIME outperforms recent baselines in weakly-supervised text classification and achieves state-of-the-art in 4 benchmarks. We open source our code at https://github.com/seongminp/LIME.
Efficient Post-training Quantization with FP8 Formats
Sep 26, 2023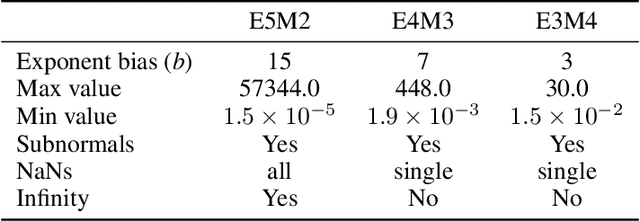
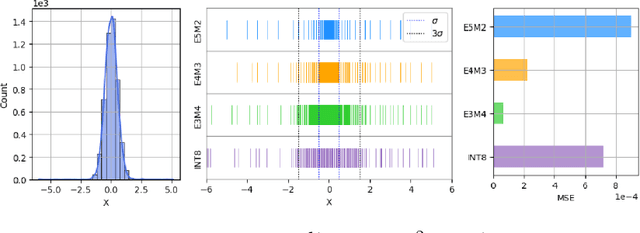
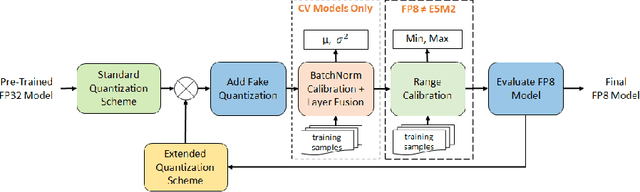
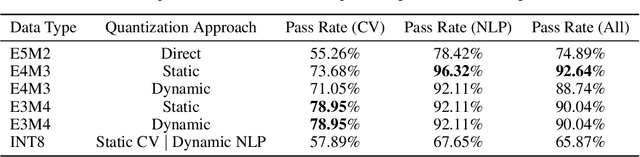
Recent advances in deep learning methods such as LLMs and Diffusion models have created a need for improved quantization methods that can meet the computational demands of these modern architectures while maintaining accuracy. Towards this goal, we study the advantages of FP8 data formats for post-training quantization across 75 unique network architectures covering a wide range of tasks, including machine translation, language modeling, text generation, image classification, generation, and segmentation. We examine three different FP8 representations (E5M2, E4M3, and E3M4) to study the effects of varying degrees of trade-off between dynamic range and precision on model accuracy. Based on our extensive study, we developed a quantization workflow that generalizes across different network architectures. Our empirical results show that FP8 formats outperform INT8 in multiple aspects, including workload coverage (92.64% vs. 65.87%), model accuracy and suitability for a broader range of operations. Furthermore, our findings suggest that E4M3 is better suited for NLP models, whereas E3M4 performs marginally better than E4M3 on computer vision tasks. The code is publicly available on Intel Neural Compressor: https://github.com/intel/neural-compressor.
Ahead of the Text: Leveraging Entity Preposition for Financial Relation Extraction
Aug 08, 2023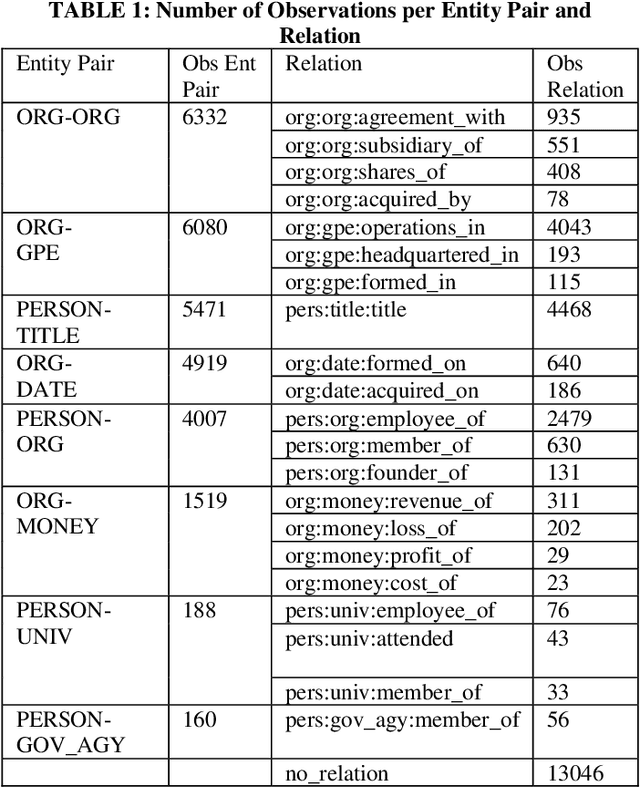
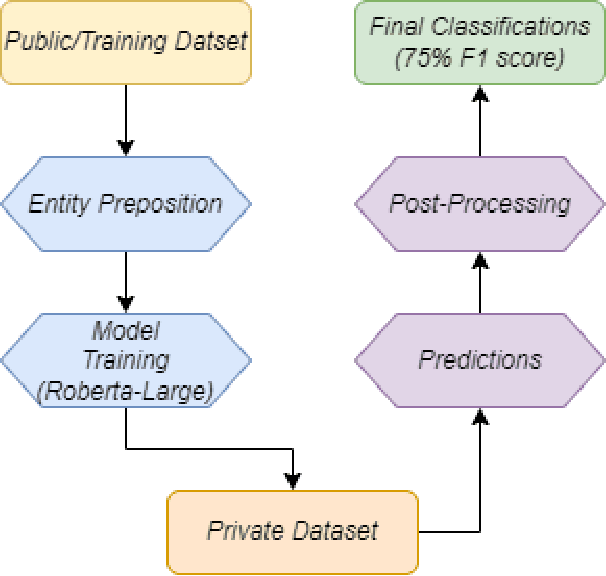
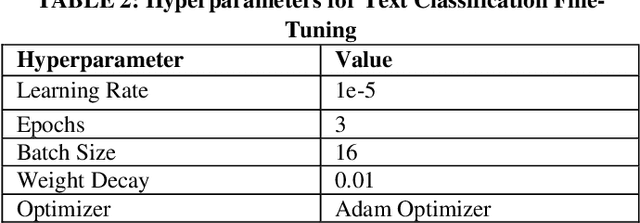

In the context of the ACM KDF-SIGIR 2023 competition, we undertook an entity relation task on a dataset of financial entity relations called REFind. Our top-performing solution involved a multi-step approach. Initially, we inserted the provided entities at their corresponding locations within the text. Subsequently, we fine-tuned the transformer-based language model roberta-large for text classification by utilizing a labeled training set to predict the entity relations. Lastly, we implemented a post-processing phase to identify and handle improbable predictions generated by the model. As a result of our methodology, we achieved the 1st place ranking on the competition's public leaderboard.