 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Overlapping Microservices from Monolithic Code via Deep Semantic Embeddings and Graph Neural Network-Based Soft Clustering
Aug 10, 2025Modern software systems are increasingly shifting from monolithic architectures to microservices to enhance scalability, maintainability, and deployment flexibility. Existing microservice extraction methods typically rely on hard clustering, assigning each software component to a single microservice. This approach often increases inter-service coupling and reduces intra-service cohesion. We propose Mo2oM (Monolithic to Overlapping Microservices), a framework that formulates microservice extraction as a soft clustering problem, allowing components to belong probabilistically to multiple microservices. This approach is inspired by expert-driven decompositions, where practitioners intentionally replicate certain software components across services to reduce communication overhead. Mo2oM combines deep semantic embeddings with structural dependencies extracted from methodcall graphs to capture both functional and architectural relationships. A graph neural network-based soft clustering algorithm then generates the final set of microservices. We evaluate Mo2oM on four open-source monolithic benchmarks and compare it against eight state-of-the-art baselines. Our results demonstrate that Mo2oM achieves improvements of up to 40.97% in structural modularity (balancing cohesion and coupling), 58% in inter-service call percentage (communication overhead), 26.16% in interface number (modularity and decoupling), and 38.96% in non-extreme distribution (service size balance) across all benchmarks.
Online Continual Learning: A Systematic Literature Review of Approaches, Challenges, and Benchmarks
Jan 09, 2025



Online Continual Learning (OCL) is a critical area in machine learning, focusing on enabling models to adapt to evolving data streams in real-time while addressing challenges such as catastrophic forgetting and the stability-plasticity trade-off. This study conducts the first comprehensive Systematic Literature Review (SLR) on OCL, analyzing 81 approaches, extracting over 1,000 features (specific tasks addressed by these approaches), and identifying more than 500 components (sub-models within approaches, including algorithms and tools). We also review 83 datasets spanning applications like image classification, object detection, and multimodal vision-language tasks. Our findings highlight key challenges, including reducing computational overhead, developing domain-agnostic solutions, and improving scalability in resource-constrained environments. Furthermore, we identify promising directions for future research, such as leveraging self-supervised learning for multimodal and sequential data, designing adaptive memory mechanisms that integrate sparse retrieval and generative replay, and creating efficient frameworks for real-world applications with noisy or evolving task boundaries. By providing a rigorous and structured synthesis of the current state of OCL, this review offers a valuable resource for advancing this field and addressing its critical challenges and opportunities. The complete SLR methodology steps and extracted data are publicly available through the provided link: https://github.com/kiyan-rezaee/ Systematic-Literature-Review-on-Online-Continual-Learning
Multi-Label Feature Selection Using Adaptive and Transformed Relevance
Sep 26, 2023



Multi-label learning has emerged as a crucial paradigm in data analysis, addressing scenarios where instances are associated with multiple class labels simultaneously. With the growing prevalence of multi-label data across diverse applications, such as text and image classification, the significance of multi-label feature selection has become increasingly evident. This paper presents a novel information-theoretical filter-based multi-label feature selection, called ATR, with a new heuristic function. Incorporating a combinations of algorithm adaptation and problem transformation approaches, ATR ranks features considering individual labels as well as abstract label space discriminative powers. Our experimental studies encompass twelve benchmarks spanning various domains, demonstrating the superiority of our approach over ten state-of-the-art information-theoretical filter-based multi-label feature selection methods across six evaluation metrics. Furthermore, our experiments affirm the scalability of ATR for benchmarks characterized by extensive feature and label spaces. The codes are available at https://github.com/Sadegh28/ATR
Understanding User Intent Modeling for Conversational Recommender Systems: A Systematic Literature Review
Aug 05, 2023Context: User intent modeling is a crucial process in Natural Language Processing that aims to identify the underlying purpose behind a user's request, enabling personalized responses. With a vast array of approaches introduced in the literature (over 13,000 papers in the last decade), understanding the related concepts and commonly used models in AI-based systems is essential. Method: We conducted a systematic literature review to gather data on models typically employed in designing conversational recommender systems. From the collected data, we developed a decision model to assist researchers in selecting the most suitable models for their systems. Additionally, we performed two case studies to evaluate the effectiveness of our proposed decision model. Results: Our study analyzed 59 distinct models and identified 74 commonly used features. We provided insights into potential model combinations, trends in model selection, quality concerns, evaluation measures, and frequently used datasets for training and evaluating these models. Contribution: Our study contributes practical insights and a comprehensive understanding of user intent modeling, empowering the development of more effective and personalized conversational recommender systems. With the Conversational Recommender System, researchers can perform a more systematic and efficient assessment of fitting intent modeling frameworks.
Supervised Infinite Feature Selection
Aug 21, 2017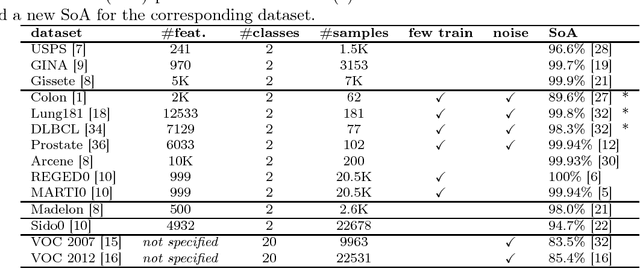
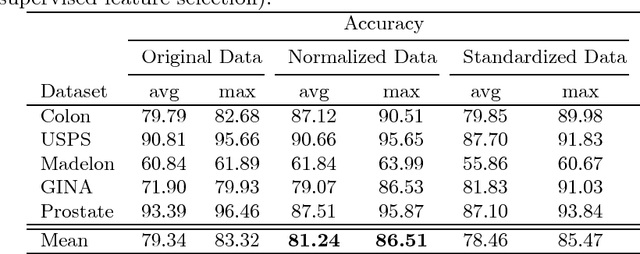
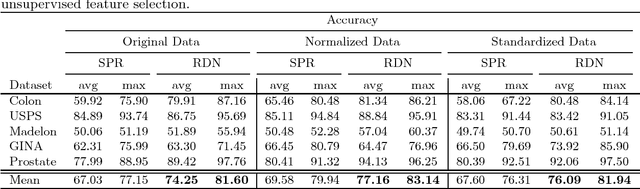
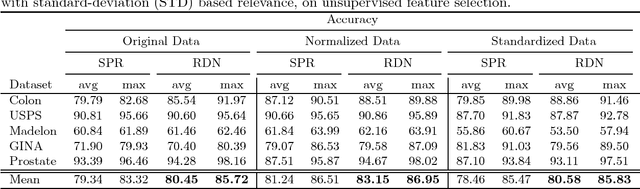
In this paper, we present a new feature selection method that is suitable for both unsupervised and supervised problems. We build upon the recently proposed Infinite Feature Selection (IFS) method where feature subsets of all sizes (including infinity) are considered. We extend IFS in two ways. First, we propose a supervised version of it. Second, we propose new ways of forming the feature adjacency matrix that perform better for unsupervised problems. We extensively evaluate our methods on many benchmark datasets, including large image-classification datasets (PASCAL VOC), and show that our methods outperform both the IFS and the widely used "minimum-redundancy maximum-relevancy (mRMR)" feature selection algorithm.