 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAMOTS: A Real-Time System for Aerial Multi-Object Tracking based on Deep Learning and Big Data Technology
Feb 06, 2025



Multi-object tracking (MOT) in UAV-based video is challenging due to variations in viewpoint, low resolution, and the presence of small objects. While other research on MOT dedicated to aerial videos primarily focuses on the academic aspect by developing sophisticated algorithms, there is a lack of attention to the practical aspect of these systems. In this paper, we propose a novel real-time MOT framework that integrates Apache Kafka and Apache Spark for efficient and fault-tolerant video stream processing, along with state-of-the-art deep learning models YOLOv8/YOLOv10 and BYTETRACK/BoTSORT for accurate object detection and tracking. Our work highlights the importance of not only the advanced algorithms but also the integration of these methods with scalable and distributed systems. By leveraging these technologies, our system achieves a HOTA of 48.14 and a MOTA of 43.51 on the Visdrone2019-MOT test set while maintaining a real-time processing speed of 28 FPS on a single GPU. Our work demonstrates the potential of big data technologies and deep learning for addressing the challenges of MOT in UAV applications.
A study of Vietnamese readability assessing through semantic and statistical features
Nov 07, 2024



Determining the difficulty of a text involves assessing various textual features that may impact the reader's text comprehension, yet current research in Vietnamese has only focused on statistical features. This paper introduces a new approach that integrates statistical and semantic approaches to assessing text readability. Our research utilized three distinct datasets: the Vietnamese Text Readability Dataset (ViRead), OneStopEnglish, and RACE, with the latter two translated into Vietnamese. Advanced semantic analysis methods were employed for the semantic aspect using state-of-the-art language models such as PhoBERT, ViDeBERTa, and ViBERT. In addition, statistical methods were incorporated to extract syntactic and lexical features of the text. We conducted experiments using various machine learning models, including Support Vector Machine (SVM), Random Forest, and Extra Trees and evaluated their performance using accuracy and F1 score metrics. Our results indicate that a joint approach that combines semantic and statistical features significantly enhances the accuracy of readability classification compared to using each method in isolation. The current study emphasizes the importance of considering both statistical and semantic aspects for a more accurate assessment of text difficulty in Vietnamese. This contribution to the field provides insights into the adaptability of advanced language models in the context of Vietnamese text readability. It lays the groundwork for future research in this area.
Real-time stress detection on social network posts using big data technology
Nov 07, 2024



In the context of modern life, particularly in Industry 4.0 within the online space, emotions and moods are frequently conveyed through social media posts. The trend of sharing stories, thoughts, and feelings on these platforms generates a vast and promising data source for Big Data. This creates both a challenge and an opportunity for research in applying technology to develop more automated and accurate methods for detecting stress in social media users. In this study, we developed a real-time system for stress detection in online posts, using the "Dreaddit: A Reddit Dataset for Stress Analysis in Social Media," which comprises 187,444 posts across five different Reddit domains. Each domain contains texts with both stressful and non-stressful content, showcasing various expressions of stress. A labeled dataset of 3,553 lines was created for training. Apache Kafka, PySpark, and AirFlow were utilized to build and deploy the model. Logistic Regression yielded the best results for new streaming data, achieving 69,39% for measuring accuracy and 68,97 for measuring F1-scores.
Vietnamese AI Generated Text Detection
May 06, 2024



In recent years, Large Language Models (LLMs) have become integrated into our daily lives, serving as invaluable assistants in completing tasks. Widely embraced by users, the abuse of LLMs is inevitable, particularly in using them to generate text content for various purposes, leading to difficulties in distinguishing between text generated by LLMs and that written by humans. In this study, we present a dataset named ViDetect, comprising 6.800 samples of Vietnamese essay, with 3.400 samples authored by humans and the remainder generated by LLMs, serving the purpose of detecting text generated by AI. We conducted evaluations using state-of-the-art methods, including ViT5, BartPho, PhoBERT, mDeberta V3, and mBERT. These results contribute not only to the growing body of research on detecting text generated by AI but also demonstrate the adaptability and effectiveness of different methods in the Vietnamese language context. This research lays the foundation for future advancements in AI-generated text detection and provides valuable insights for researchers in the field of natural language processing.
Exploiting Hatred by Targets for Hate Speech Detection on Vietnamese Social Media Texts
Apr 30, 2024



The growth of social networks makes toxic content spread rapidly. Hate speech detection is a task to help decrease the number of harmful comments. With the diversity in the hate speech created by users, it is necessary to interpret the hate speech besides detecting it. Hence, we propose a methodology to construct a system for targeted hate speech detection from online streaming texts from social media. We first introduce the ViTHSD - a targeted hate speech detection dataset for Vietnamese Social Media Texts. The dataset contains 10K comments, each comment is labeled to specific targets with three levels: clean, offensive, and hate. There are 5 targets in the dataset, and each target is labeled with the corresponding level manually by humans with strict annotation guidelines. The inter-annotator agreement obtained from the dataset is 0.45 by Cohen's Kappa index, which is indicated as a moderate level. Then, we construct a baseline for this task by combining the Bi-GRU-LSTM-CNN with the pre-trained language model to leverage the power of text representation of BERTology. Finally, we suggest a methodology to integrate the baseline model for targeted hate speech detection into the online streaming system for practical application in preventing hateful and offensive content on social media.
An Application of Vector Autoregressive Model for Analyzing the Impact of Weather And Nearby Traffic Flow On The Traffic Volume
Nov 12, 2023



This paper aims to predict the traffic flow at one road segment based on nearby traffic volume and weather conditions. Our team also discover the impact of weather conditions and nearby traffic volume on the traffic flow at a target point. The analysis results will help solve the problem of traffic flow prediction and develop an optimal transport network with efficient traffic movement and minimal traffic congestion. Hourly historical weather and traffic flow data are selected to solve this problem. This paper uses model VAR(36) with time trend and constant to train the dataset and forecast. With an RMSE of 565.0768111 on average, the model is considered appropriate although some statistical tests implies that the residuals are unstable and non-normal. Also, this paper points out some variables that are not useful in forecasting, which helps simplify the data-collecting process when building the forecasting system.
ViCGCN: Graph Convolutional Network with Contextualized Language Models for Social Media Mining in Vietnamese
Sep 06, 2023Social media processing is a fundamental task in natural language processing with numerous applications. As Vietnamese social media and information science have grown rapidly, the necessity of information-based mining on Vietnamese social media has become crucial. However, state-of-the-art research faces several significant drawbacks, including imbalanced data and noisy data on social media platforms. Imbalanced and noisy are two essential issues that need to be addressed in Vietnamese social media texts. Graph Convolutional Networks can address the problems of imbalanced and noisy data in text classification on social media by taking advantage of the graph structure of the data. This study presents a novel approach based on contextualized language model (PhoBERT) and graph-based method (Graph Convolutional Networks). In particular, the proposed approach, ViCGCN, jointly trained the power of Contextualized embeddings with the ability of Graph Convolutional Networks, GCN, to capture more syntactic and semantic dependencies to address those drawbacks. Extensive experiments on various Vietnamese benchmark datasets were conducted to verify our approach. The observation shows that applying GCN to BERTology models as the final layer significantly improves performance. Moreover, the experiments demonstrate that ViCGCN outperforms 13 powerful baseline models, including BERTology models, fusion BERTology and GCN models, other baselines, and SOTA on three benchmark social media datasets. Our proposed ViCGCN approach demonstrates a significant improvement of up to 6.21%, 4.61%, and 2.63% over the best Contextualized Language Models, including multilingual and monolingual, on three benchmark datasets, UIT-VSMEC, UIT-ViCTSD, and UIT-VSFC, respectively. Additionally, our integrated model ViCGCN achieves the best performance compared to other BERTology integrated with GCN models.
Multi-stage Information Retrieval for Vietnamese Legal Texts
Sep 29, 2022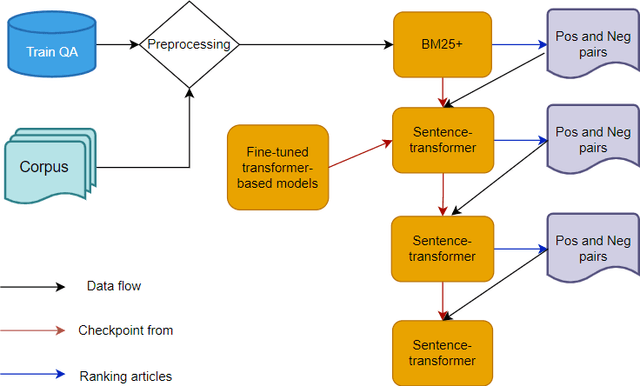

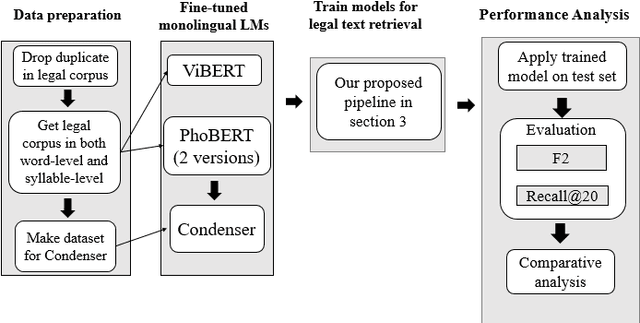
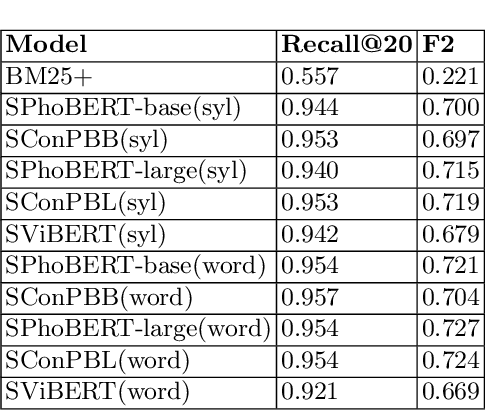
This study deals with the problem of information retrieval (IR) for Vietnamese legal texts. Despite being well researched in many languages, information retrieval has still not received much attention from the Vietnamese research community. This is especially true for the case of legal documents, which are hard to process. This study proposes a new approach for information retrieval for Vietnamese legal documents using sentence-transformer. Besides, various experiments are conducted to make comparisons between different transformer models, ranking scores, syllable-level, and word-level training. The experiment results show that the proposed model outperforms models used in current research on information retrieval for Vietnamese documents.
Vietnamese Hate and Offensive Detection using PhoBERT-CNN and Social Media Streaming Data
Jun 01, 2022

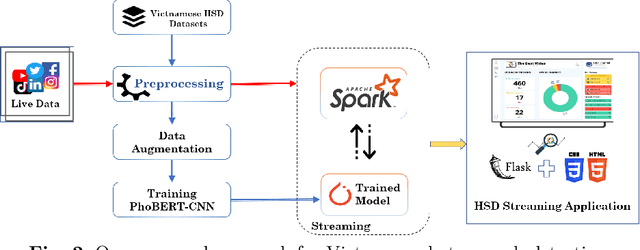

Society needs to develop a system to detect hate and offense to build a healthy and safe environment. However, current research in this field still faces four major shortcomings, including deficient pre-processing techniques, indifference to data imbalance issues, modest performance models, and lacking practical applications. This paper focused on developing an intelligent system capable of addressing these shortcomings. Firstly, we proposed an efficient pre-processing technique to clean comments collected from Vietnamese social media. Secondly, a novel hate speech detection (HSD) model, which is the combination of a pre-trained PhoBERT model and a Text-CNN model, was proposed for solving tasks in Vietnamese. Thirdly, EDA techniques are applied to deal with imbalanced data to improve the performance of classification models. Besides, various experiments were conducted as baselines to compare and investigate the proposed model's performance against state-of-the-art methods. The experiment results show that the proposed PhoBERT-CNN model outperforms SOTA methods and achieves an F1-score of 67,46% and 98,45% on two benchmark datasets, ViHSD and HSD-VLSP, respectively. Finally, we also built a streaming HSD application to demonstrate the practicality of our proposed system.