 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
kNN-CTC: Enhancing ASR via Retrieval of CTC Pseudo Labels
Dec 21, 2023
The success of retrieval-augmented language models in various natural language processing (NLP) tasks has been constrained in automatic speech recognition (ASR) applications due to challenges in constructing fine-grained audio-text datastores. This paper presents kNN-CTC, a novel approach that overcomes these challenges by leveraging Connectionist Temporal Classification (CTC) pseudo labels to establish frame-level audio-text key-value pairs, circumventing the need for precise ground truth alignments. We further introduce a skip-blank strategy, which strategically ignores CTC blank frames, to reduce datastore size. kNN-CTC incorporates a k-nearest neighbors retrieval mechanism into pre-trained CTC ASR systems, achieving significant improvements in performance. By incorporating a k-nearest neighbors retrieval mechanism into pre-trained CTC ASR systems and leveraging a fine-grained, pruned datastore, kNN-CTC consistently achieves substantial improvements in performance under various experimental settings. Our code is available at https://github.com/NKU-HLT/KNN-CTC.
Learning Mutually Informed Representations for Characters and Subwords
Nov 14, 2023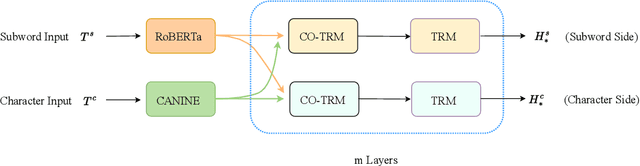
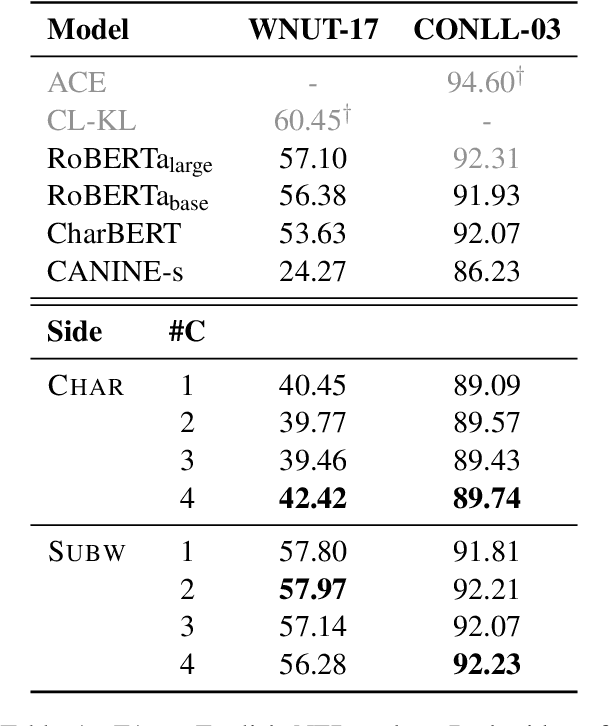
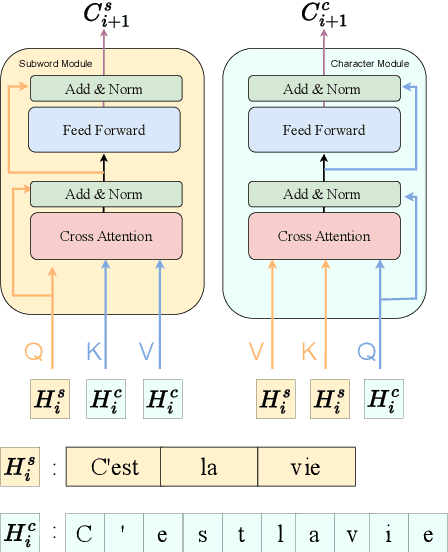
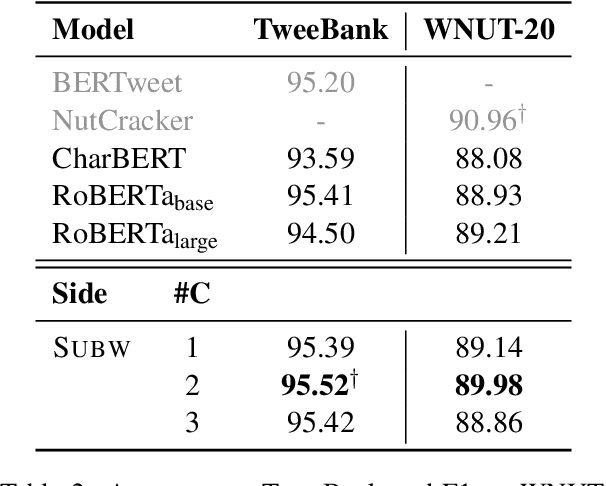
Most pretrained language models rely on subword tokenization, which processes text as a sequence of subword tokens. However, different granularities of text, such as characters, subwords, and words, can contain different kinds of information. Previous studies have shown that incorporating multiple input granularities improves model generalization, yet very few of them outputs useful representations for each granularity. In this paper, we introduce the entanglement model, aiming to combine character and subword language models. Inspired by vision-language models, our model treats characters and subwords as separate modalities, and it generates mutually informed representations for both granularities as output. We evaluate our model on text classification, named entity recognition, and POS-tagging tasks. Notably, the entanglement model outperforms its backbone language models, particularly in the presence of noisy texts and low-resource languages. Furthermore, the entanglement model even outperforms larger pre-trained models on all English sequence labeling tasks and classification tasks. Our anonymized code is available at https://anonymous.4open.science/r/noisy-IE-A673
An energy-based comparative analysis of common approaches to text classification in the Legal domain
Nov 02, 2023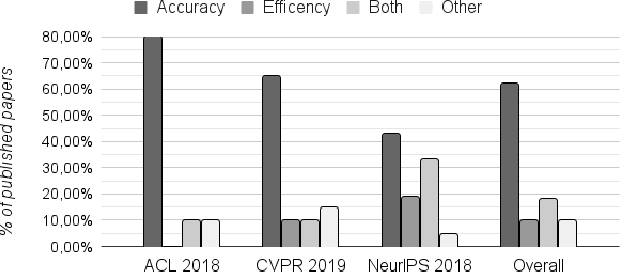

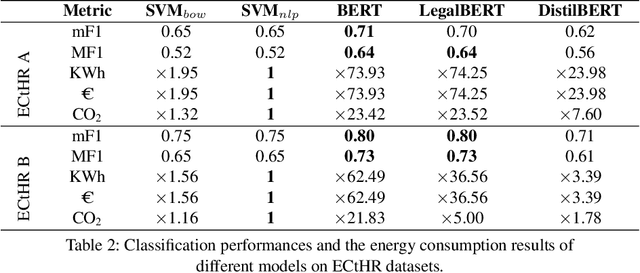

Most Machine Learning research evaluates the best solutions in terms of performance. However, in the race for the best performing model, many important aspects are often overlooked when, on the contrary, they should be carefully considered. In fact, sometimes the gaps in performance between different approaches are neglectable, whereas factors such as production costs, energy consumption, and carbon footprint must take into consideration. Large Language Models (LLMs) are extensively adopted to address NLP problems in academia and industry. In this work, we present a detailed quantitative comparison of LLM and traditional approaches (e.g. SVM) on the LexGLUE benchmark, which takes into account both performance (standard indices) and alternative metrics such as timing, power consumption and cost, in a word: the carbon-footprint. In our analysis, we considered the prototyping phase (model selection by training-validation-test iterations) and in-production phases separately, since they follow different implementation procedures and also require different resources. The results indicate that very often, the simplest algorithms achieve performance very close to that of large LLMs but with very low power consumption and lower resource demands. The results obtained could suggest companies to include additional evaluations in the choice of Machine Learning (ML) solutions.
CartoMark: a benchmark dataset for map pattern recognition and 1 map content retrieval with machine intelligence
Dec 14, 2023Maps are fundamental medium to visualize and represent the real word in a simple and 16 philosophical way. The emergence of the 3rd wave information has made a proportion of maps are available to be generated ubiquitously, which would significantly enrich the dimensions and perspectives to understand the characteristics of the real world. However, a majority of map dataset have never been discovered, acquired and effectively used, and the map data used in many applications might not be completely fitted for the authentic demands of these applications. This challenge is emerged due to the lack of numerous well-labelled benchmark datasets for implementing the deep learning approaches into identifying complicated map content. Thus, we develop a large-scale benchmark dataset that includes well-labelled dataset for map text annotation recognition, map scene classification, map super-resolution reconstruction, and map style transferring. Furthermore, these well-labelled datasets would facilitate the state-of-the-art machine intelligence technologies to conduct map feature detection, map pattern recognition and map content retrieval. We hope our efforts would be useful for AI-enhanced cartographical applications.
Weakly Supervised Text Classification on Free Text Comments in Patient-Reported Outcome Measures
Aug 11, 2023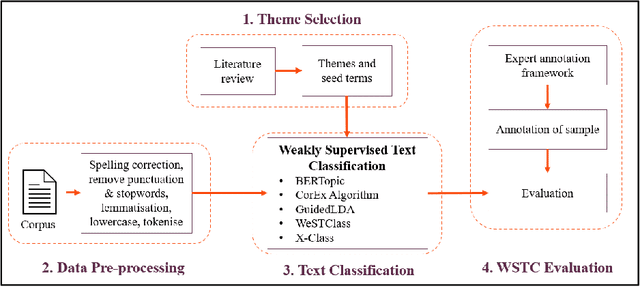

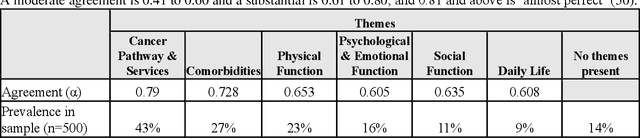
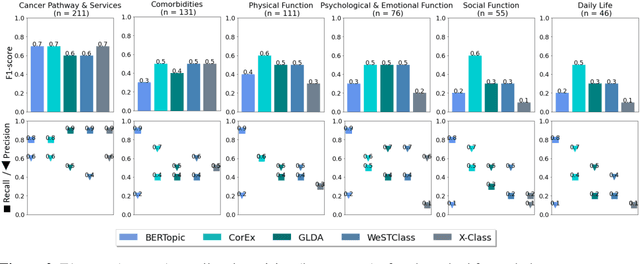
Free text comments (FTC) in patient-reported outcome measures (PROMs) data are typically analysed using manual methods, such as content analysis, which is labour-intensive and time-consuming. Machine learning analysis methods are largely unsupervised, necessitating post-analysis interpretation. Weakly supervised text classification (WSTC) can be a valuable method of analysis to classify domain-specific text data in which there is limited labelled data. In this paper, we apply five WSTC techniques to FTC in PROMs data to identify health-related quality of life (HRQoL) themes reported by colorectal cancer patients. The WSTC methods label all the themes mentioned in the FTC. The results showed moderate performance on the PROMs data, mainly due to the precision of the models, and variation between themes. Evaluation of the classification performance illustrated the potential and limitations of keyword based WSTC to label PROMs FTC when labelled data is limited.
Meta-Tsallis-Entropy Minimization: A New Self-Training Approach for Domain Adaptation on Text Classification
Aug 04, 2023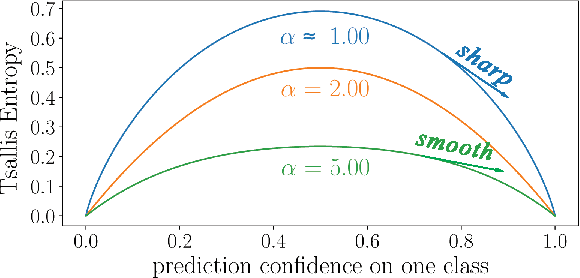
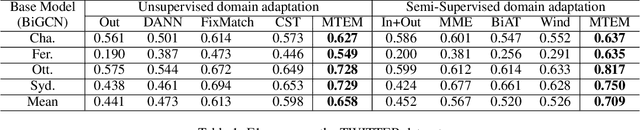
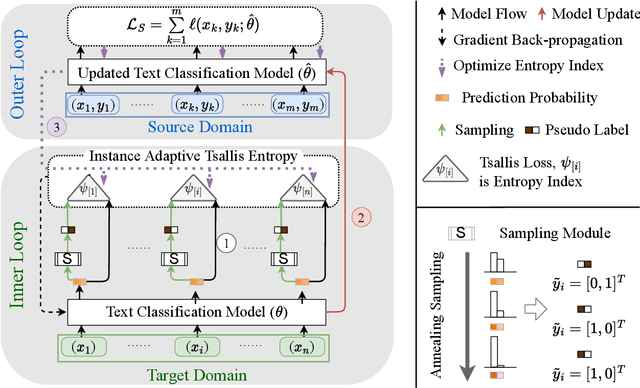
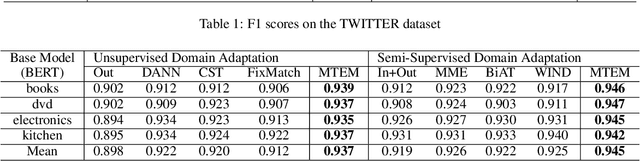
Text classification is a fundamental task for natural language processing, and adapting text classification models across domains has broad applications. Self-training generates pseudo-examples from the model's predictions and iteratively trains on the pseudo-examples, i.e., minimizes the loss on the source domain and the Gibbs entropy on the target domain. However, Gibbs entropy is sensitive to prediction errors, and thus, self-training tends to fail when the domain shift is large. In this paper, we propose Meta-Tsallis Entropy minimization (MTEM), which applies a meta-learning algorithm to optimize the instance adaptive Tsallis entropy on the target domain. To reduce the computation cost of MTEM, we propose an approximation technique to approximate the Second-order derivation involved in the meta-learning. To efficiently generate pseudo labels, we propose an annealing sampling mechanism for exploring the model's prediction probability. Theoretically, we prove the convergence of the meta-learning algorithm in MTEM and analyze the effectiveness of MTEM in achieving domain adaptation. Experimentally, MTEM improves the adaptation performance of BERT with an average of 4 percent on the benchmark dataset.
Feature Extraction Using Deep Generative Models for Bangla Text Classification on a New Comprehensive Dataset
Aug 21, 2023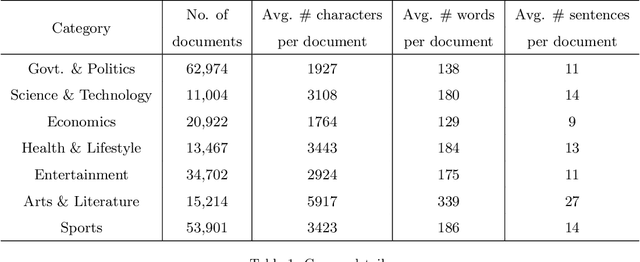
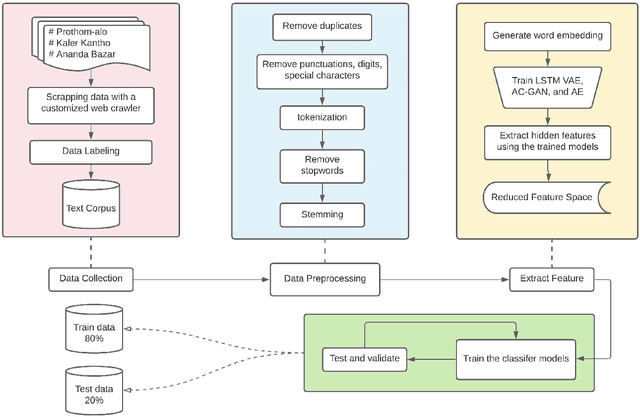
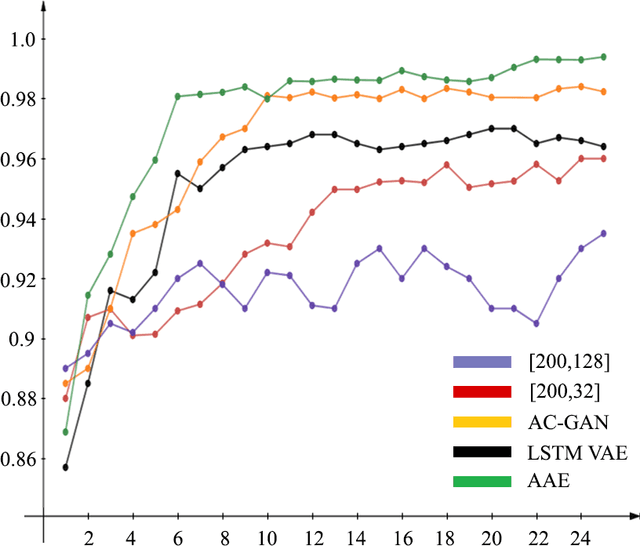
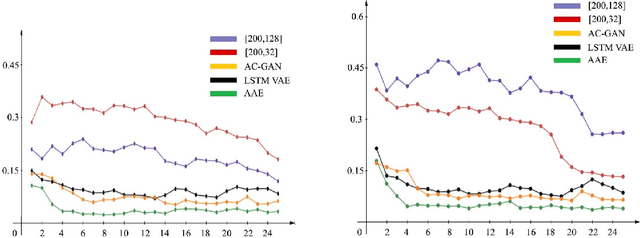
The selection of features for text classification is a fundamental task in text mining and information retrieval. Despite being the sixth most widely spoken language in the world, Bangla has received little attention due to the scarcity of text datasets. In this research, we collected, annotated, and prepared a comprehensive dataset of 212,184 Bangla documents in seven different categories and made it publicly accessible. We implemented three deep learning generative models: LSTM variational autoencoder (LSTM VAE), auxiliary classifier generative adversarial network (AC-GAN), and adversarial autoencoder (AAE) to extract text features, although their applications are initially found in the field of computer vision. We utilized our dataset to train these three models and used the feature space obtained in the document classification task. We evaluated the performance of the classifiers and found that the adversarial autoencoder model produced the best feature space.
Context Unlocks Emotions: Text-based Emotion Classification Dataset Auditing with Large Language Models
Nov 06, 2023The lack of contextual information in text data can make the annotation process of text-based emotion classification datasets challenging. As a result, such datasets often contain labels that fail to consider all the relevant emotions in the vocabulary. This misalignment between text inputs and labels can degrade the performance of machine learning models trained on top of them. As re-annotating entire datasets is a costly and time-consuming task that cannot be done at scale, we propose to use the expressive capabilities of large language models to synthesize additional context for input text to increase its alignment with the annotated emotional labels. In this work, we propose a formal definition of textual context to motivate a prompting strategy to enhance such contextual information. We provide both human and empirical evaluation to demonstrate the efficacy of the enhanced context. Our method improves alignment between inputs and their human-annotated labels from both an empirical and human-evaluated standpoint.
Performance Trade-offs of Watermarking Large Language Models
Nov 16, 2023Amidst growing concerns of large language models (LLMs) being misused for generating misinformation or completing homework assignments, watermarking has emerged as an effective solution for distinguishing human-written and LLM-generated text. A prominent watermarking strategy is to embed a signal into generated text by upsampling a (pseudorandomly-chosen) subset of tokens at every generation step. Although this signal is imperceptible to a human reader, it is detectable through statistical testing. However, implanting such signals alters the model's output distribution and can have unintended effects when watermarked LLMs are used for downstream applications. In this work, we evaluate the performance of watermarked LLMs on a diverse suite of tasks, including text classification, textual entailment, reasoning, question answering, translation, summarization, and language modeling. We find that watermarking has negligible impact on the performance of tasks posed as k-class classification problems in the average case. However, the accuracy can plummet to that of a random classifier for some scenarios (that occur with non-negligible probability). Tasks that are cast as multiple-choice questions and short-form generation are surprisingly unaffected by watermarking. For long-form generation tasks, including summarization and translation, we see a drop of 15-20% in the performance due to watermarking. Our findings highlight the trade-offs that users should be cognizant of when using watermarked models, and point to cases where future research could improve existing trade-offs.
Text generation for dataset augmentation in security classification tasks
Oct 22, 2023Security classifiers, designed to detect malicious content in computer systems and communications, can underperform when provided with insufficient training data. In the security domain, it is often easy to find samples of the negative (benign) class, and challenging to find enough samples of the positive (malicious) class to train an effective classifier. This study evaluates the application of natural language text generators to fill this data gap in multiple security-related text classification tasks. We describe a variety of previously-unexamined language-model fine-tuning approaches for this purpose and consider in particular the impact of disproportionate class-imbalances in the training set. Across our evaluation using three state-of-the-art classifiers designed for offensive language detection, review fraud detection, and SMS spam detection, we find that models trained with GPT-3 data augmentation strategies outperform both models trained without augmentation and models trained using basic data augmentation strategies already in common usage. In particular, we find substantial benefits for GPT-3 data augmentation strategies in situations with severe limitations on known positive-class samples.