 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Illicit Darkweb Classification via Natural-language Processing: Classifying Illicit Content of Webpages based on Textual Information
Dec 08, 2023
This work aims at expanding previous works done in the context of illegal activities classification, performing three different steps. First, we created a heterogeneous dataset of 113995 onion sites and dark marketplaces. Then, we compared pre-trained transferable models, i.e., ULMFit (Universal Language Model Fine-tuning), Bert (Bidirectional Encoder Representations from Transformers), and RoBERTa (Robustly optimized BERT approach) with a traditional text classification approach like LSTM (Long short-term memory) neural networks. Finally, we developed two illegal activities classification approaches, one for illicit content on the Dark Web and one for identifying the specific types of drugs. Results show that Bert obtained the best approach, classifying the dark web's general content and the types of Drugs with 96.08% and 91.98% of accuracy.
Accurate Use of Label Dependency in Multi-Label Text Classification Through the Lens of Causality
Oct 11, 2023Multi-Label Text Classification (MLTC) aims to assign the most relevant labels to each given text. Existing methods demonstrate that label dependency can help to improve the model's performance. However, the introduction of label dependency may cause the model to suffer from unwanted prediction bias. In this study, we attribute the bias to the model's misuse of label dependency, i.e., the model tends to utilize the correlation shortcut in label dependency rather than fusing text information and label dependency for prediction. Motivated by causal inference, we propose a CounterFactual Text Classifier (CFTC) to eliminate the correlation bias, and make causality-based predictions. Specifically, our CFTC first adopts the predict-then-modify backbone to extract precise label information embedded in label dependency, then blocks the correlation shortcut through the counterfactual de-bias technique with the help of the human causal graph. Experimental results on three datasets demonstrate that our CFTC significantly outperforms the baselines and effectively eliminates the correlation bias in datasets.
Text Classification of Cancer Clinical Trial Eligibility Criteria
Sep 14, 2023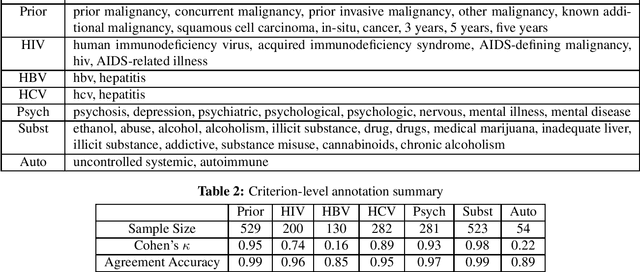

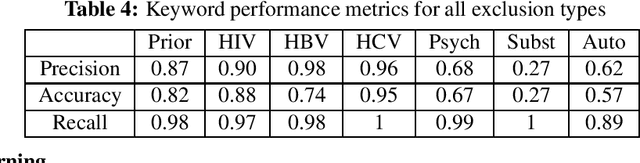
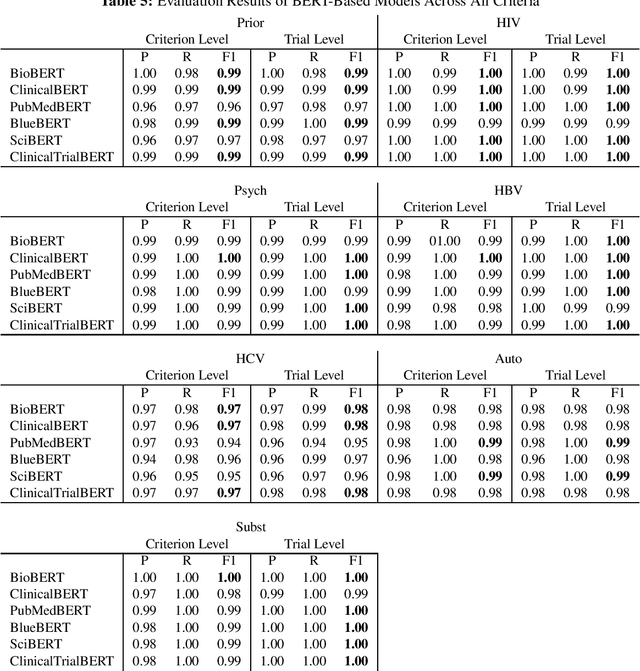
Automatic identification of clinical trials for which a patient is eligible is complicated by the fact that trial eligibility is stated in natural language. A potential solution to this problem is to employ text classification methods for common types of eligibility criteria. In this study, we focus on seven common exclusion criteria in cancer trials: prior malignancy, human immunodeficiency virus, hepatitis B, hepatitis C, psychiatric illness, drug/substance abuse, and autoimmune illness. Our dataset consists of 764 phase III cancer trials with these exclusions annotated at the trial level. We experiment with common transformer models as well as a new pre-trained clinical trial BERT model. Our results demonstrate the feasibility of automatically classifying common exclusion criteria. Additionally, we demonstrate the value of a pre-trained language model specifically for clinical trials, which yields the highest average performance across all criteria.
ICL Markup: Structuring In-Context Learning using Soft-Token Tags
Dec 12, 2023Large pretrained language models (LLMs) can be rapidly adapted to a wide variety of tasks via a text-to-text approach, where the instruction and input are fed to the model in natural language. Combined with in-context learning (ICL), this paradigm is impressively flexible and powerful. However, it also burdens users with an overwhelming number of choices, many of them arbitrary. Inspired by markup languages like HTML, we contribute a method of using soft-token tags to compose prompt templates. This approach reduces arbitrary decisions and streamlines the application of ICL. Our method is a form of meta-learning for ICL; it learns these tags in advance during a parameter-efficient fine-tuning ``warm-up'' process. The tags can subsequently be used in templates for ICL on new, unseen tasks without any additional fine-tuning. Our experiments with this approach yield promising initial results, improving LLM performance on important enterprise applications such as few-shot and open-world intent detection, as well as text classification in news and legal domains.
A Review of Hybrid and Ensemble in Deep Learning for Natural Language Processing
Dec 09, 2023This review presents a comprehensive exploration of hybrid and ensemble deep learning models within Natural Language Processing (NLP), shedding light on their transformative potential across diverse tasks such as Sentiment Analysis, Named Entity Recognition, Machine Translation, Question Answering, Text Classification, Generation, Speech Recognition, Summarization, and Language Modeling. The paper systematically introduces each task, delineates key architectures from Recurrent Neural Networks (RNNs) to Transformer-based models like BERT, and evaluates their performance, challenges, and computational demands. The adaptability of ensemble techniques is emphasized, highlighting their capacity to enhance various NLP applications. Challenges in implementation, including computational overhead, overfitting, and model interpretation complexities, are addressed alongside the trade-off between interpretability and performance. Serving as a concise yet invaluable guide, this review synthesizes insights into tasks, architectures, and challenges, offering a holistic perspective for researchers and practitioners aiming to advance language-driven applications through ensemble deep learning in NLP.
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Jan 04, 2024The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this "bag-level" image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We plan to release the benchmark, consisting of 7 datasets, which will contribute to future research in zero-shot recognition.
Beyond Gradient and Priors in Privacy Attacks: Leveraging Pooler Layer Inputs of Language Models in Federated Learning
Dec 10, 2023Federated learning (FL) emphasizes decentralized training by storing data locally and sending only model updates, underlining user privacy. Recently, a line of works on privacy attacks impairs user privacy by extracting sensitive training text from language models in the context of FL. Yet, these attack techniques face distinct hurdles: some work chiefly with limited batch sizes (e.g., batch size of 1), and others are easily detectable. This paper introduces an innovative approach that is challenging to detect, significantly enhancing the recovery rate of text in various batch-size settings. Building on fundamental gradient matching and domain prior knowledge, we enhance the attack by recovering the input of the Pooler layer of language models, which enables us to provide additional supervised signals at the feature level. Unlike gradient data, these signals do not average across sentences and tokens, thereby offering more nuanced and effective insights. We benchmark our method using text classification tasks on datasets such as CoLA, SST-2, and Rotten Tomatoes. Across different batch sizes and models, our approach consistently outperforms previous state-of-the-art results.
Optimizing Multi-Class Text Classification: A Diverse Stacking Ensemble Framework Utilizing Transformers
Aug 19, 2023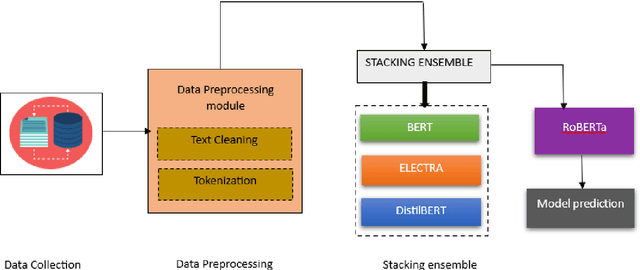
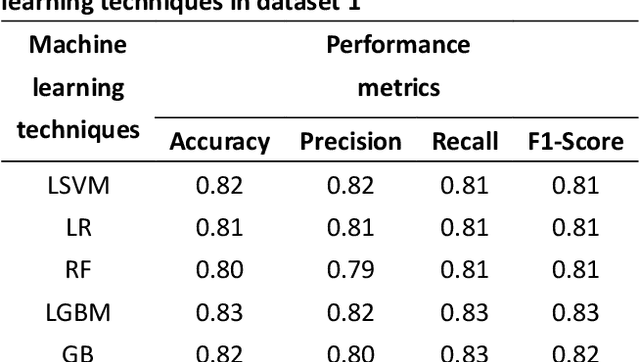
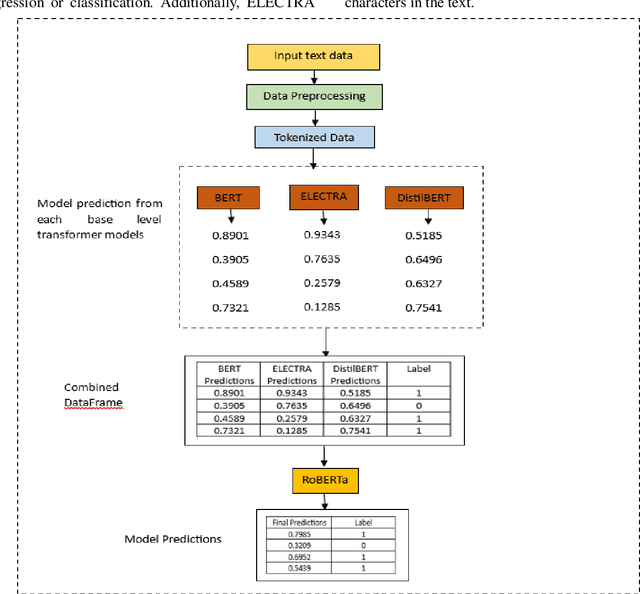
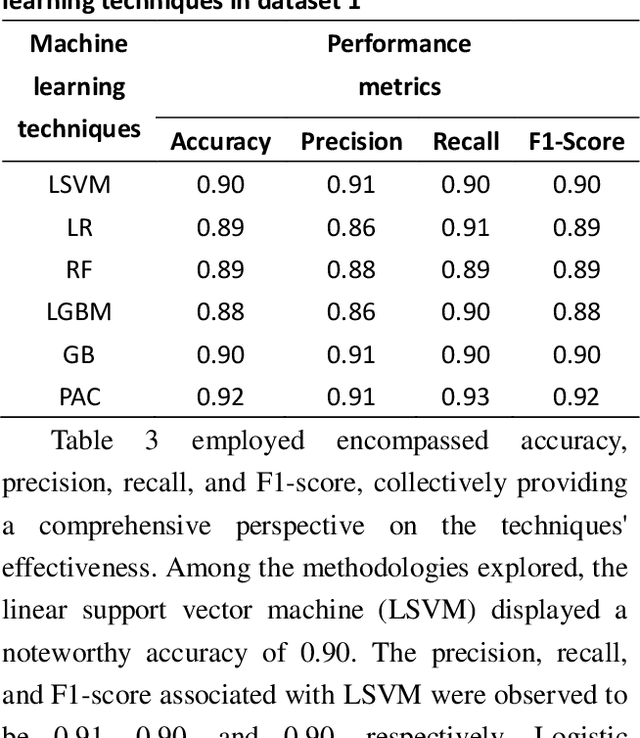
Customer reviews play a crucial role in assessing customer satisfaction, gathering feedback, and driving improvements for businesses. Analyzing these reviews provides valuable insights into customer sentiments, including compliments, comments, and suggestions. Text classification techniques enable businesses to categorize customer reviews into distinct categories, facilitating a better understanding of customer feedback. However, challenges such as overfitting and bias limit the effectiveness of a single classifier in ensuring optimal prediction. This study proposes a novel approach to address these challenges by introducing a stacking ensemble-based multi-text classification method that leverages transformer models. By combining multiple single transformers, including BERT, ELECTRA, and DistilBERT, as base-level classifiers, and a meta-level classifier based on RoBERTa, an optimal predictive model is generated. The proposed stacking ensemble-based multi-text classification method aims to enhance the accuracy and robustness of customer review analysis. Experimental evaluations conducted on a real-world customer review dataset demonstrate the effectiveness and superiority of the proposed approach over traditional single classifier models. The stacking ensemble-based multi-text classification method using transformers proves to be a promising solution for businesses seeking to extract valuable insights from customer reviews and make data-driven decisions to enhance customer satisfaction and drive continuous improvement.
Boosting Prompt-Based Self-Training With Mapping-Free Automatic Verbalizer for Multi-Class Classification
Dec 08, 2023Recently, prompt-based fine-tuning has garnered considerable interest as a core technique for few-shot text classification task. This approach reformulates the fine-tuning objective to align with the Masked Language Modeling (MLM) objective. Leveraging unlabeled data, prompt-based self-training has shown greater effectiveness in binary and three-class classification. However, prompt-based self-training for multi-class classification has not been adequately investigated, despite its significant applicability to real-world scenarios. Moreover, extending current methods to multi-class classification suffers from the verbalizer that extracts the predicted value of manually pre-defined single label word for each class from MLM predictions. Consequently, we introduce a novel, efficient verbalizer structure, named Mapping-free Automatic Verbalizer (MAV). Comprising two fully connected layers, MAV serves as a trainable verbalizer that automatically extracts the requisite word features for classification by capitalizing on all available information from MLM predictions. Experimental results on five multi-class classification datasets indicate MAV's superior self-training efficacy.
Exploring Small Language Models with Prompt-Learning Paradigm for Efficient Domain-Specific Text Classification
Sep 26, 2023
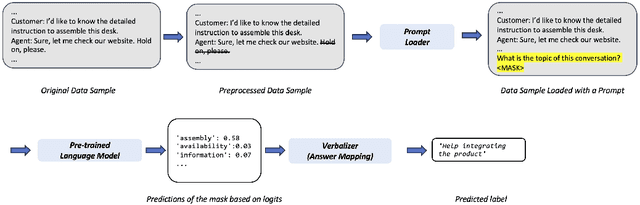

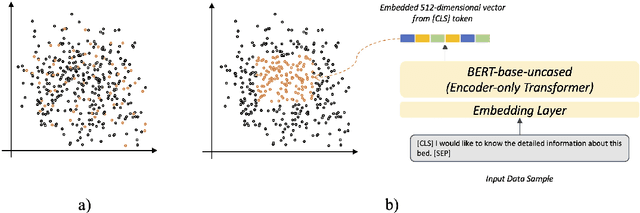
Domain-specific text classification faces the challenge of scarce labeled data due to the high cost of manual labeling. Prompt-learning, known for its efficiency in few-shot scenarios, is proposed as an alternative to traditional fine-tuning methods. And besides, although large language models (LLMs) have gained prominence, small language models (SLMs, with under 1B parameters) offer significant customizability, adaptability, and cost-effectiveness for domain-specific tasks, given industry constraints. In this study, we investigate the potential of SLMs combined with prompt-learning paradigm for domain-specific text classification, specifically within customer-agent interactions in retail. Our evaluations show that, in few-shot settings when prompt-based model fine-tuning is possible, T5-base, a typical SLM with 220M parameters, achieve approximately 75% accuracy with limited labeled data (up to 15% of full data), which shows great potentials of SLMs with prompt-learning. Based on this, We further validate the effectiveness of active few-shot sampling and the ensemble strategy in the prompt-learning pipeline that contribute to a remarkable performance gain. Besides, in zero-shot settings with a fixed model, we underscore a pivotal observation that, although the GPT-3.5-turbo equipped with around 154B parameters garners an accuracy of 55.16%, the power of well designed prompts becomes evident when the FLAN-T5-large, a model with a mere 0.5% of GPT-3.5-turbo's parameters, achieves an accuracy exceeding 31% with the optimized prompt, a leap from its sub-18% performance with an unoptimized one. Our findings underscore the promise of prompt-learning in classification tasks with SLMs, emphasizing the benefits of active few-shot sampling, and ensemble strategies in few-shot settings, and the importance of prompt engineering in zero-shot settings.