 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Power of Topic Modeling Techniques in Analyzing Customer Reviews: A Comparative Analysis
Aug 19, 2023The exponential growth of online social network platforms and applications has led to a staggering volume of user-generated textual content, including comments and reviews. Consequently, users often face difficulties in extracting valuable insights or relevant information from such content. To address this challenge, machine learning and natural language processing algorithms have been deployed to analyze the vast amount of textual data available online. In recent years, topic modeling techniques have gained significant popularity in this domain. In this study, we comprehensively examine and compare five frequently used topic modeling methods specifically applied to customer reviews. The methods under investigation are latent semantic analysis (LSA), latent Dirichlet allocation (LDA), non-negative matrix factorization (NMF), pachinko allocation model (PAM), Top2Vec, and BERTopic. By practically demonstrating their benefits in detecting important topics, we aim to highlight their efficacy in real-world scenarios. To evaluate the performance of these topic modeling methods, we carefully select two textual datasets. The evaluation is based on standard statistical evaluation metrics such as topic coherence score. Our findings reveal that BERTopic consistently yield more meaningful extracted topics and achieve favorable results.
Optimizing Multi-Class Text Classification: A Diverse Stacking Ensemble Framework Utilizing Transformers
Aug 19, 2023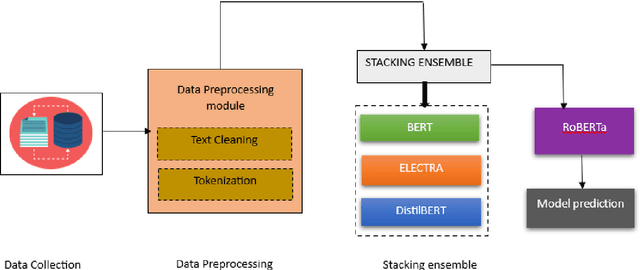
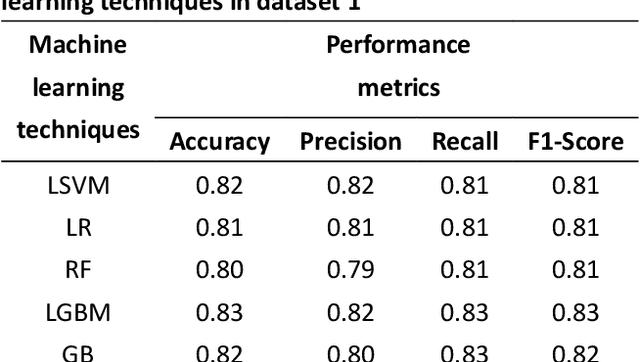
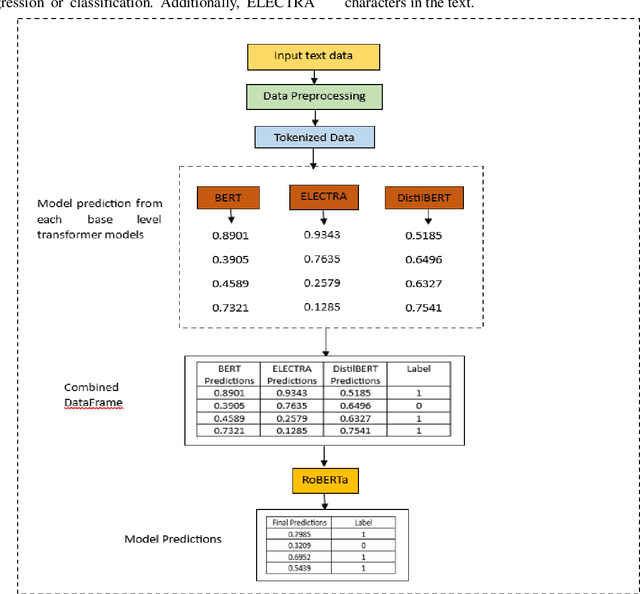
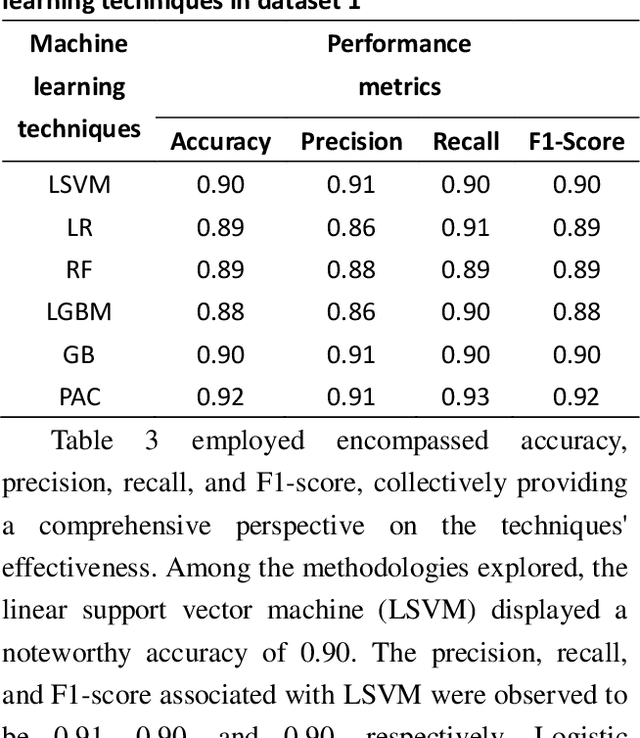
Customer reviews play a crucial role in assessing customer satisfaction, gathering feedback, and driving improvements for businesses. Analyzing these reviews provides valuable insights into customer sentiments, including compliments, comments, and suggestions. Text classification techniques enable businesses to categorize customer reviews into distinct categories, facilitating a better understanding of customer feedback. However, challenges such as overfitting and bias limit the effectiveness of a single classifier in ensuring optimal prediction. This study proposes a novel approach to address these challenges by introducing a stacking ensemble-based multi-text classification method that leverages transformer models. By combining multiple single transformers, including BERT, ELECTRA, and DistilBERT, as base-level classifiers, and a meta-level classifier based on RoBERTa, an optimal predictive model is generated. The proposed stacking ensemble-based multi-text classification method aims to enhance the accuracy and robustness of customer review analysis. Experimental evaluations conducted on a real-world customer review dataset demonstrate the effectiveness and superiority of the proposed approach over traditional single classifier models. The stacking ensemble-based multi-text classification method using transformers proves to be a promising solution for businesses seeking to extract valuable insights from customer reviews and make data-driven decisions to enhance customer satisfaction and drive continuous improvement.
Exploring Machine Learning and Transformer-based Approaches for Deceptive Text Classification: A Comparative Analysis
Aug 11, 2023



Deceptive text classification is a critical task in natural language processing that aims to identify deceptive o fraudulent content. This study presents a comparative analysis of machine learning and transformer-based approaches for deceptive text classification. We investigate the effectiveness of traditional machine learning algorithms and state-of-the-art transformer models, such as BERT, XLNET, DistilBERT, and RoBERTa, in detecting deceptive text. A labeled dataset consisting of deceptive and non-deceptive texts is used for training and evaluation purposes. Through extensive experimentation, we compare the performance metrics, including accuracy, precision, recall, and F1 score, of the different approaches. The results of this study shed light on the strengths and limitations of machine learning and transformer-based methods for deceptive text classification, enabling researchers and practitioners to make informed decisions when dealing with deceptive content.