 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Interpreting Sentiment Composition with Latent Semantic Tree
Aug 31, 2023

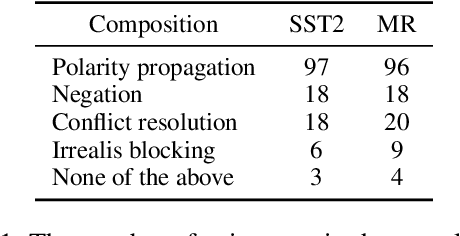
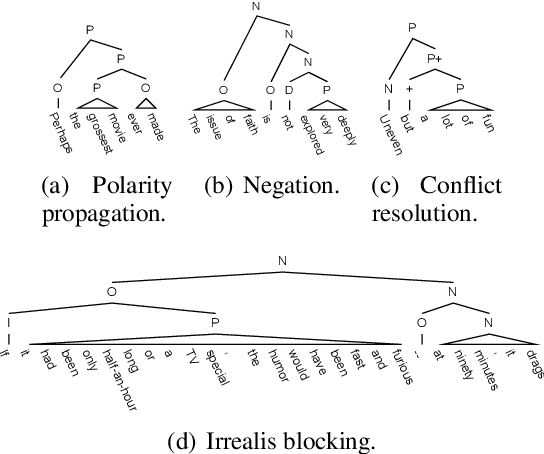
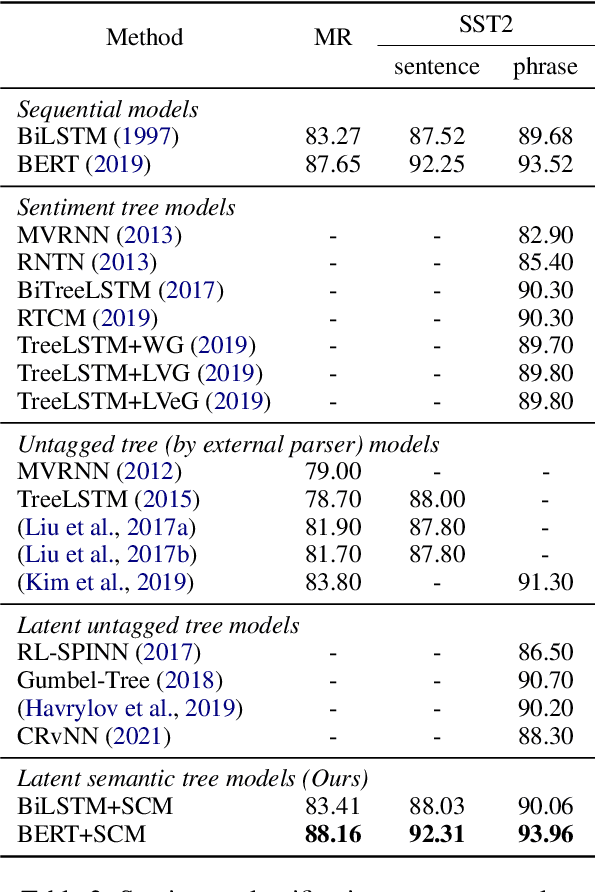
As the key to sentiment analysis, sentiment composition considers the classification of a constituent via classifications of its contained sub-constituents and rules operated on them. Such compositionality has been widely studied previously in the form of hierarchical trees including untagged and sentiment ones, which are intrinsically suboptimal in our view. To address this, we propose semantic tree, a new tree form capable of interpreting the sentiment composition in a principled way. Semantic tree is a derivation of a context-free grammar (CFG) describing the specific composition rules on difference semantic roles, which is designed carefully following previous linguistic conclusions. However, semantic tree is a latent variable since there is no its annotation in regular datasets. Thus, in our method, it is marginalized out via inside algorithm and learned to optimize the classification performance. Quantitative and qualitative results demonstrate that our method not only achieves better or competitive results compared to baselines in the setting of regular and domain adaptation classification, and also generates plausible tree explanations.
Improving Multimodal Classification of Social Media Posts by Leveraging Image-Text Auxiliary tasks
Sep 14, 2023
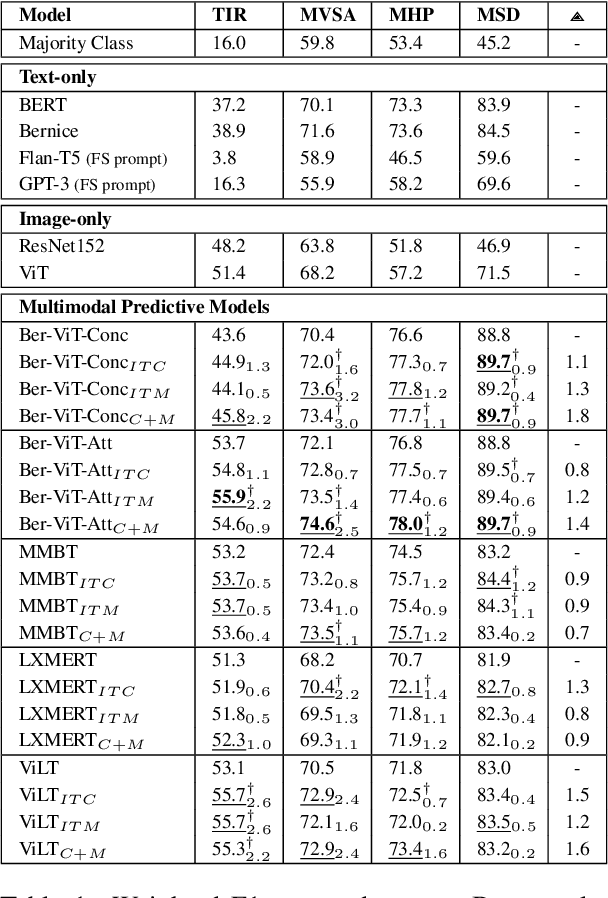
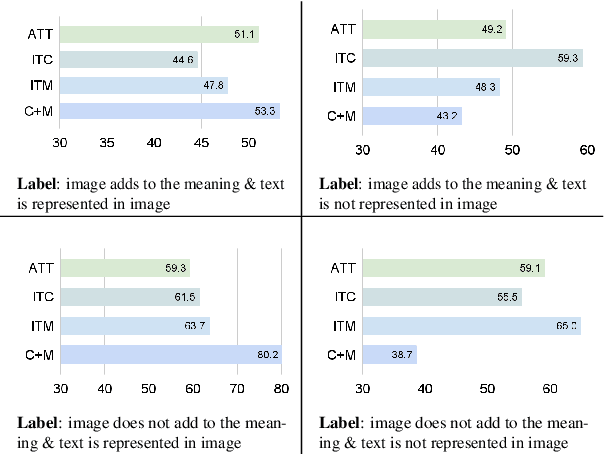

Effectively leveraging multimodal information from social media posts is essential to various downstream tasks such as sentiment analysis, sarcasm detection and hate speech classification. However, combining text and image information is challenging because of the idiosyncratic cross-modal semantics with hidden or complementary information present in matching image-text pairs. In this work, we aim to directly model this by proposing the use of two auxiliary losses jointly with the main task when fine-tuning any pre-trained multimodal model. Image-Text Contrastive (ITC) brings image-text representations of a post closer together and separates them from different posts, capturing underlying dependencies. Image-Text Matching (ITM) facilitates the understanding of semantic correspondence between images and text by penalizing unrelated pairs. We combine these objectives with five multimodal models, demonstrating consistent improvements across four popular social media datasets. Furthermore, through detailed analysis, we shed light on the specific scenarios and cases where each auxiliary task proves to be most effective.
Few-shot Multimodal Sentiment Analysis based on Multimodal Probabilistic Fusion Prompts
Nov 12, 2022
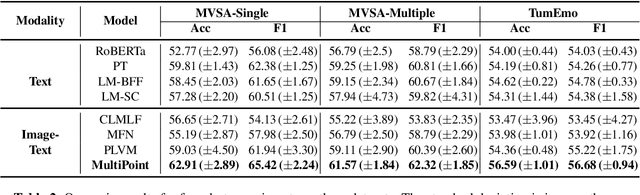
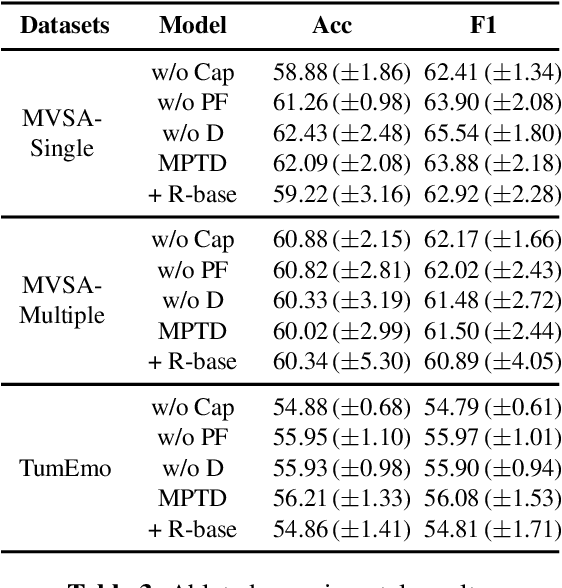
Multimodal sentiment analysis is a trending topic with the explosion of multimodal content on the web. Present studies in multimodal sentiment analysis rely on large-scale supervised data. Collating supervised data is time-consuming and labor-intensive. As such, it is essential to investigate the problem of few-shot multimodal sentiment analysis. Previous works in few-shot models generally use language model prompts, which can improve performance in low-resource settings. However, the textual prompt ignores the information from other modalities. We propose Multimodal Probabilistic Fusion Prompts, which can provide diverse cues for multimodal sentiment detection. We first design a unified multimodal prompt to reduce the discrepancy in different modal prompts. To improve the robustness of our model, we then leverage multiple diverse prompts for each input and propose a probabilistic method to fuse the output predictions. Extensive experiments conducted on three datasets confirm the effectiveness of our approach.
A Large Language Model Approach to Educational Survey Feedback Analysis
Sep 29, 2023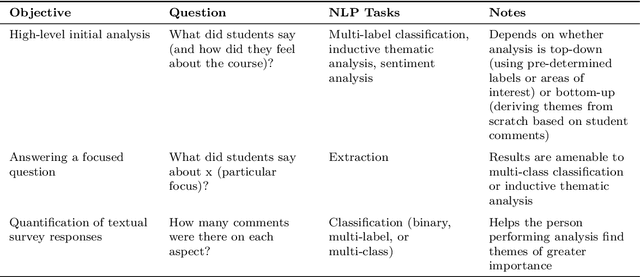
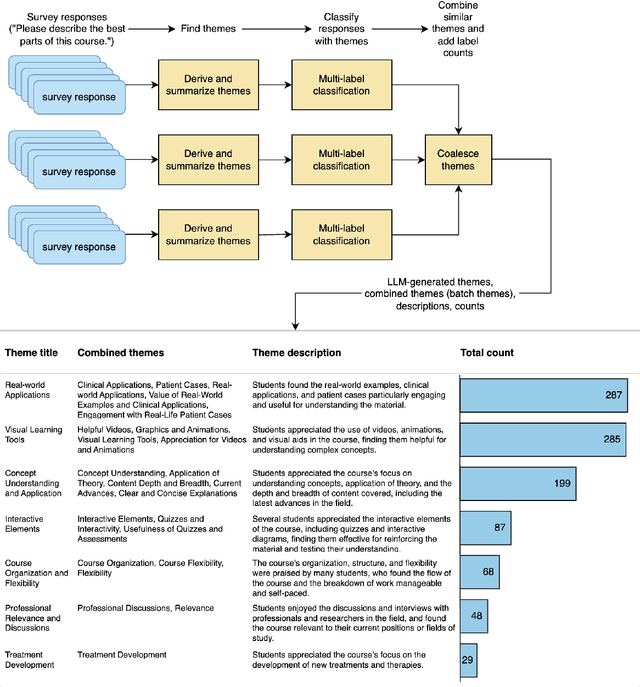
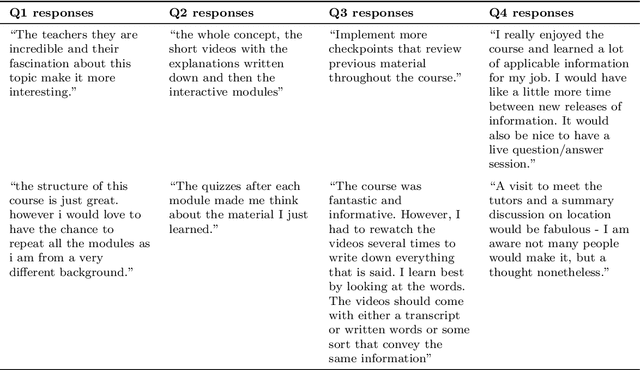
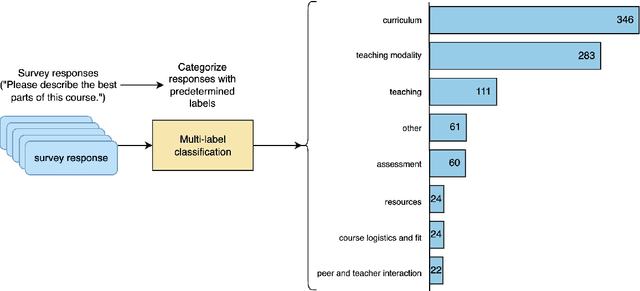
This paper assesses the potential for the large language models (LLMs) GPT-4 and GPT-3.5 to aid in deriving insight from education feedback surveys. Exploration of LLM use cases in education has focused on teaching and learning, with less exploration of capabilities in education feedback analysis. Survey analysis in education involves goals such as finding gaps in curricula or evaluating teachers, often requiring time-consuming manual processing of textual responses. LLMs have the potential to provide a flexible means of achieving these goals without specialized machine learning models or fine-tuning. We demonstrate a versatile approach to such goals by treating them as sequences of natural language processing (NLP) tasks including classification (multi-label, multi-class, and binary), extraction, thematic analysis, and sentiment analysis, each performed by LLM. We apply these workflows to a real-world dataset of 2500 end-of-course survey comments from biomedical science courses, and evaluate a zero-shot approach (i.e., requiring no examples or labeled training data) across all tasks, reflecting education settings, where labeled data is often scarce. By applying effective prompting practices, we achieve human-level performance on multiple tasks with GPT-4, enabling workflows necessary to achieve typical goals. We also show the potential of inspecting LLMs' chain-of-thought (CoT) reasoning for providing insight that may foster confidence in practice. Moreover, this study features development of a versatile set of classification categories, suitable for various course types (online, hybrid, or in-person) and amenable to customization. Our results suggest that LLMs can be used to derive a range of insights from survey text.
Colloquial Persian POS (CPPOS) Corpus: A Novel Corpus for Colloquial Persian Part of Speech Tagging
Oct 01, 2023Introduction: Part-of-Speech (POS) Tagging, the process of classifying words into their respective parts of speech (e.g., verb or noun), is essential in various natural language processing applications. POS tagging is a crucial preprocessing task for applications like machine translation, question answering, sentiment analysis, etc. However, existing corpora for POS tagging in Persian mainly consist of formal texts, such as daily news and newspapers. As a result, smart POS tools, machine learning models, and deep learning models trained on these corpora may not perform optimally for processing colloquial text in social network analysis. Method: This paper introduces a novel corpus, "Colloquial Persian POS" (CPPOS), specifically designed to support colloquial Persian text. The corpus includes formal and informal text collected from various domains such as political, social, and commercial on Telegram, Twitter, and Instagram more than 520K labeled tokens. After collecting posts from these social platforms for one year, special preprocessing steps were conducted, including normalization, sentence tokenizing, and word tokenizing for social text. The tokens and sentences were then manually annotated and verified by a team of linguistic experts. This study also defines a POS tagging guideline for annotating the data and conducting the annotation process. Results: To evaluate the quality of CPPOS, various deep learning models, such as the RNN family, were trained using the constructed corpus. A comparison with another well-known Persian POS corpus named "Bijankhan" and the Persian Hazm POS tool trained on Bijankhan revealed that our model trained on CPPOS outperforms them. With the new corpus and the BiLSTM deep neural model, we achieved a 14% improvement over the previous dataset.
Comparative Analysis of Libraries for the Sentimental Analysis
Jul 26, 2023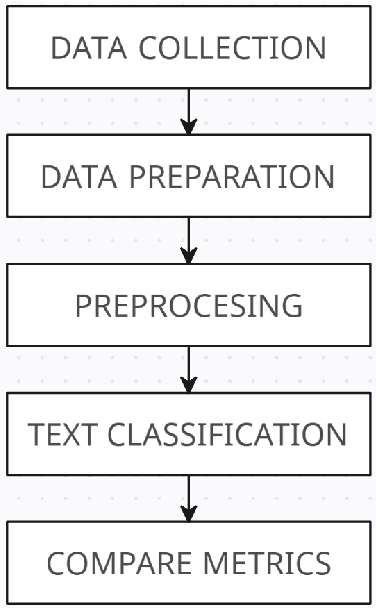
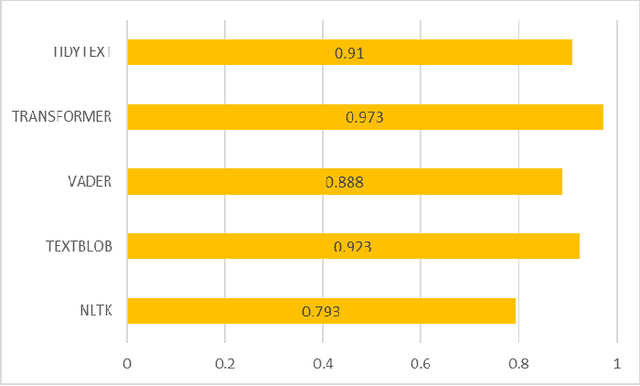
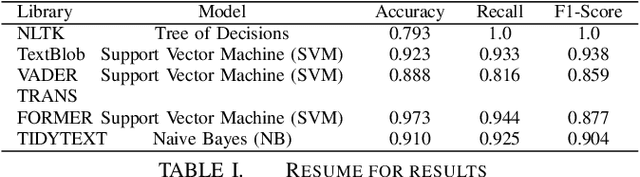
This study is main goal is to provide a comparative comparison of libraries using machine learning methods. Experts in natural language processing (NLP) are becoming more and more interested in sentiment analysis (SA) of text changes. The objective of employing NLP text analysis techniques is to recognize and categorize feelings related to twitter users utterances. In this examination, issues with SA and the libraries utilized are also looked at. provides a number of cooperative methods to classify emotional polarity. The Naive Bayes Classifier, Decision Tree Classifier, Maxent Classifier, Sklearn Classifier, Sklearn Classifier MultinomialNB, and other conjoint learning algorithms, according to recent research, are very effective. In the project will use Five Python and R libraries NLTK, TextBlob, Vader, Transformers (GPT and BERT pretrained), and Tidytext will be used in the study to apply sentiment analysis techniques. Four machine learning models Tree of Decisions (DT), Support Vector Machine (SVM), Naive Bayes (NB), and K-Nearest Neighbor (KNN) will also be used. To evaluate how well libraries for SA operate in the social network environment, comparative study was also carried out. The measures to assess the best algorithms in this experiment, which used a single data set for each method, were precision, recall, and F1 score. We conclude that the BERT transformer method with an Accuracy: 0.973 is recommended for sentiment analysis.
BERT-Based Combination of Convolutional and Recurrent Neural Network for Indonesian Sentiment Analysis
Nov 10, 2022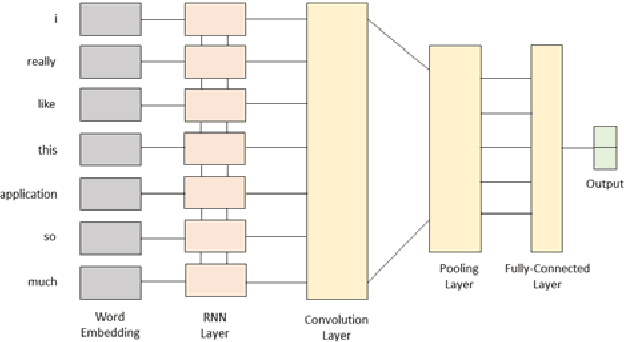

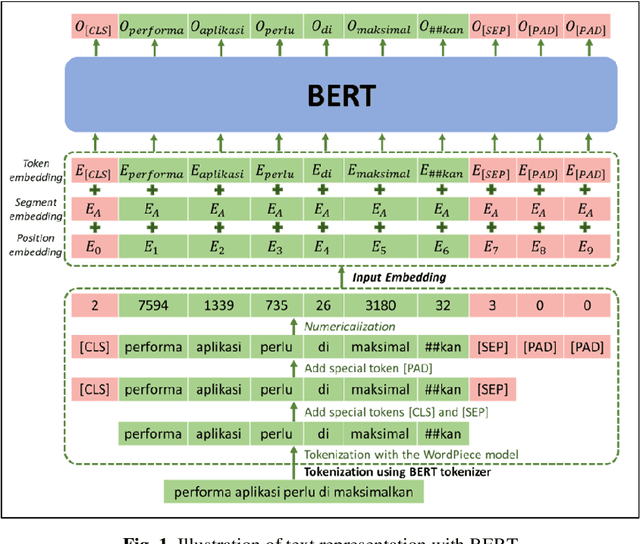
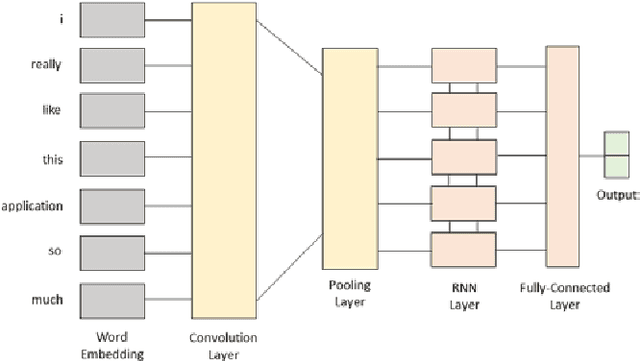
Sentiment analysis is the computational study of opinions and emotions ex-pressed in text. Deep learning is a model that is currently producing state-of-the-art in various application domains, including sentiment analysis. Many researchers are using a hybrid approach that combines different deep learning models and has been shown to improve model performance. In sentiment analysis, input in text data is first converted into a numerical representation. The standard method used to obtain a text representation is the fine-tuned embedding method. However, this method does not pay attention to each word's context in the sentence. Therefore, the Bidirectional Encoder Representation from Transformer (BERT) model is used to obtain text representations based on the context and position of words in sentences. This research extends the previous hybrid deep learning using BERT representation for Indonesian sentiment analysis. Our simulation shows that the BERT representation improves the accuracies of all hybrid architectures. The BERT-based LSTM-CNN also reaches slightly better accuracies than other BERT-based hybrid architectures.
VideoAdviser: Video Knowledge Distillation for Multimodal Transfer Learning
Sep 27, 2023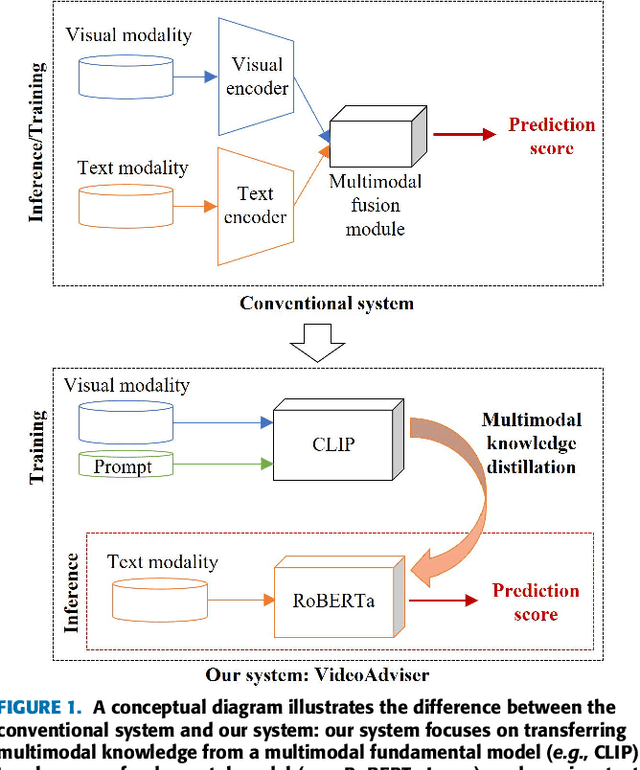
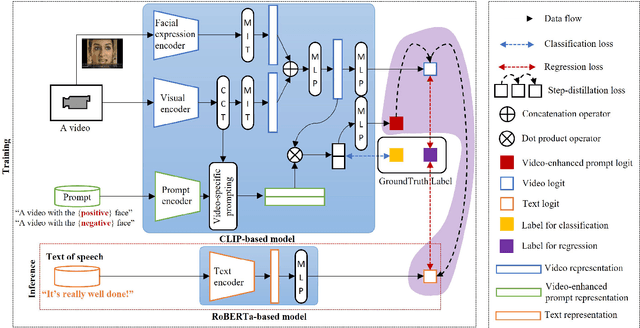
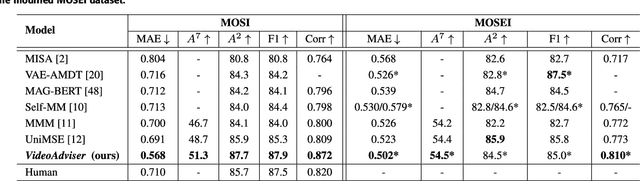
Multimodal transfer learning aims to transform pretrained representations of diverse modalities into a common domain space for effective multimodal fusion. However, conventional systems are typically built on the assumption that all modalities exist, and the lack of modalities always leads to poor inference performance. Furthermore, extracting pretrained embeddings for all modalities is computationally inefficient for inference. In this work, to achieve high efficiency-performance multimodal transfer learning, we propose VideoAdviser, a video knowledge distillation method to transfer multimodal knowledge of video-enhanced prompts from a multimodal fundamental model (teacher) to a specific modal fundamental model (student). With an intuition that the best learning performance comes with professional advisers and smart students, we use a CLIP-based teacher model to provide expressive multimodal knowledge supervision signals to a RoBERTa-based student model via optimizing a step-distillation objective loss -- first step: the teacher distills multimodal knowledge of video-enhanced prompts from classification logits to a regression logit -- second step: the multimodal knowledge is distilled from the regression logit of the teacher to the student. We evaluate our method in two challenging multimodal tasks: video-level sentiment analysis (MOSI and MOSEI datasets) and audio-visual retrieval (VEGAS dataset). The student (requiring only the text modality as input) achieves an MAE score improvement of up to 12.3% for MOSI and MOSEI. Our method further enhances the state-of-the-art method by 3.4% mAP score for VEGAS without additional computations for inference. These results suggest the strengths of our method for achieving high efficiency-performance multimodal transfer learning.
* Accepted by IEEE Access
Has Sentiment Returned to the Pre-pandemic Level? A Sentiment Analysis Using U.S. College Subreddit Data from 2019 to 2022
Sep 16, 2023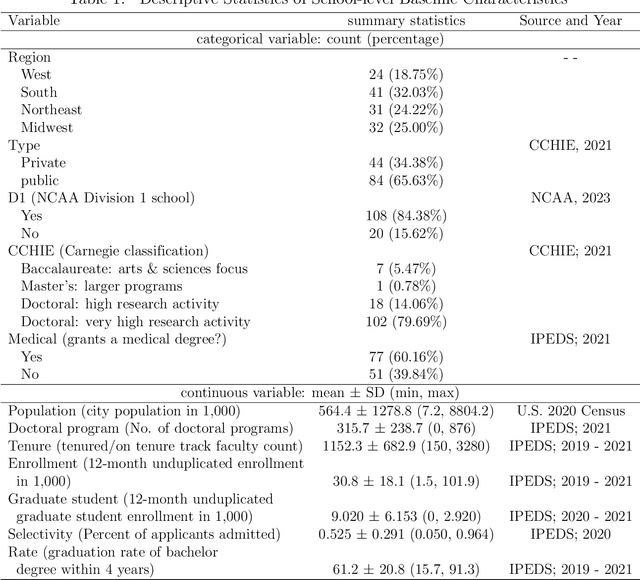
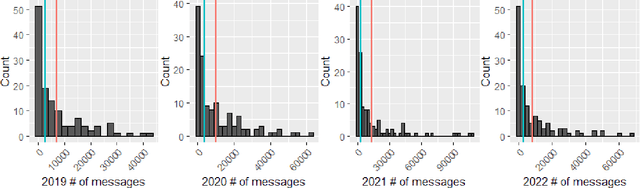
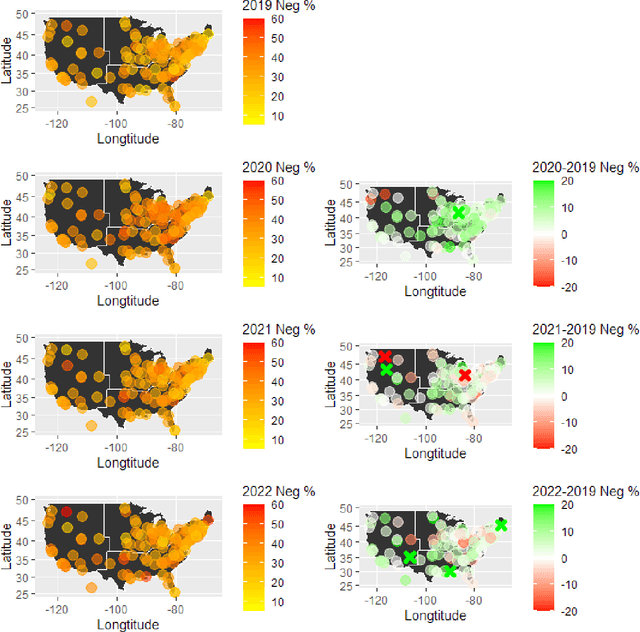
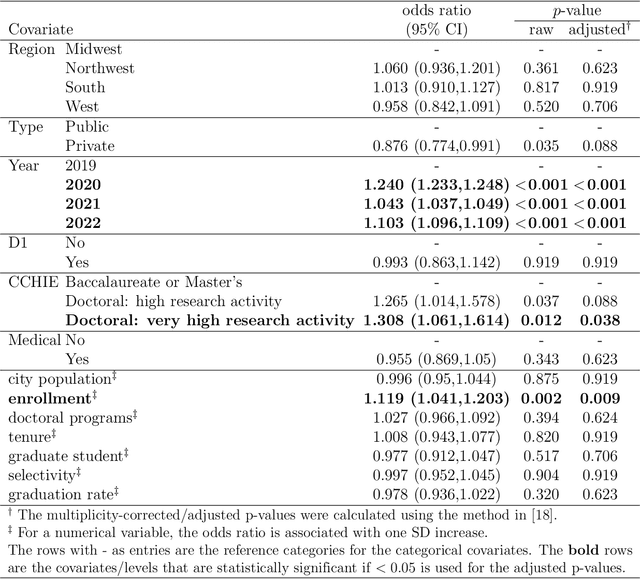
As impact of COVID-19 pandemic winds down, both individuals and society gradually return to pre-pandemic activities. This study aims to explore how people's emotions have changed from the pre-pandemic during the pandemic to post-emergency period and whether it has returned to pre-pandemic level. We collected Reddit data in 2019 (pre-pandemic), 2020 (peak pandemic), 2021, and 2022 (late stages of pandemic, transitioning period to post-emergency period) from subreddits in 128 universities/colleges in the U.S., and a set of school-level characteristics. We predicted two sets of sentiments from a pre-trained Robustly Optimized BERT pre-training approach (RoBERTa) and graph attention network (GAT) that leverages both rich semantic and relational information among posted messages and then applied a logistic stacking method to obtain the final sentiment classification. After obtaining sentiment label for each message, we used a generalized linear mixed-effects model to estimate temporal trend in sentiment from 2019 to 2022 and how school-level factors may affect sentiment. Compared to the year 2019, the odds of negative sentiment in years 2020, 2021, and 2022 are 24%, 4.3%, and 10.3% higher, respectively, which are all statistically significant(adjusted $p$<0.05). Our study findings suggest a partial recovery in the sentiment composition in the post-pandemic-emergency era. The results align with common expectations and provide a detailed quantification of how sentiments have evolved from 2019 to 2022.
Impact of Sentiment Analysis in Fake Review Detection
Dec 18, 2022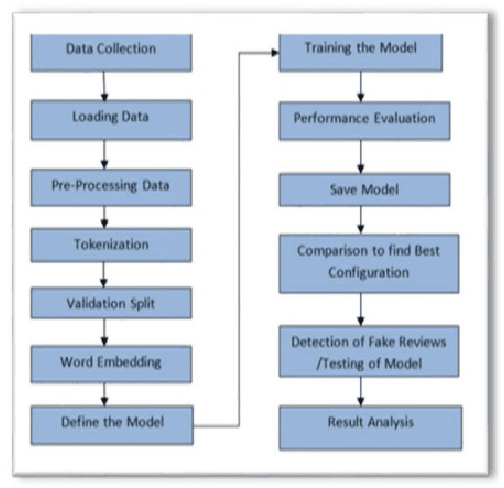
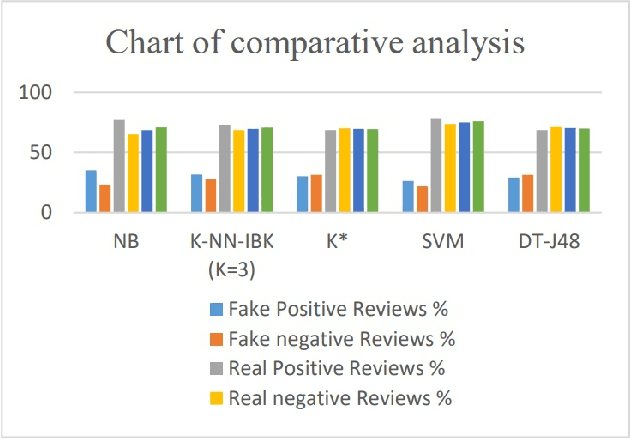
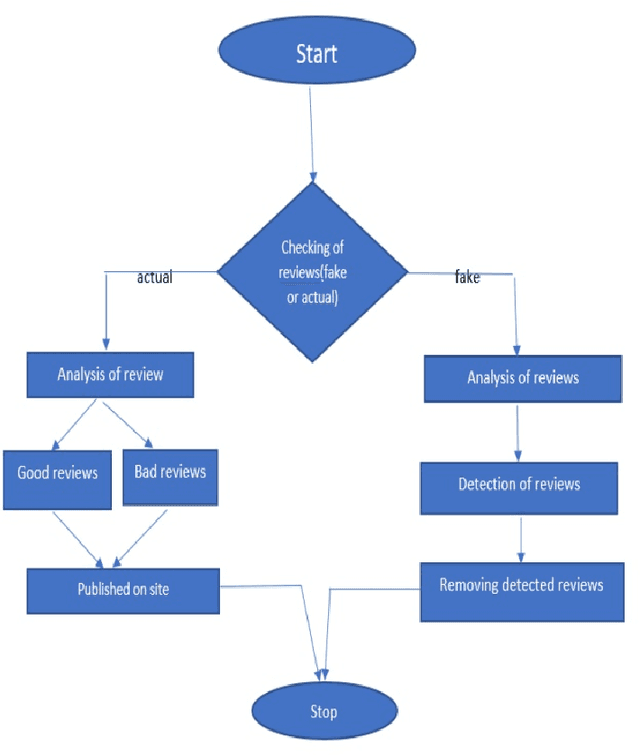

Fake review identification is an important topic and has gained the interest of experts all around the world. Identifying fake reviews is challenging for researchers, and there are several primary challenges to fake review detection. We propose developing an initial research paper for investigating fake reviews by using sentiment analysis. Ten research papers are identified that show fake reviews, and they discuss currently available solutions for predicting or detecting fake reviews. They also show the distribution of fake and truthful reviews through the analysis of sentiment. We summarize and compare previous studies related to fake reviews. We highlight the most significant challenges in the sentiment evaluation process and demonstrate that there is a significant impact on sentiment scores used to identify fake feedback.