 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Challenges for Open-domain Targeted Sentiment Analysis
Apr 15, 2022

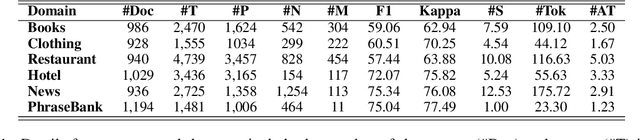
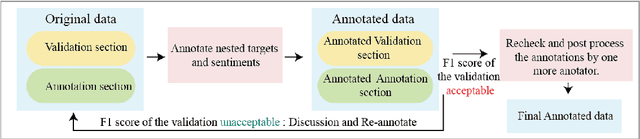
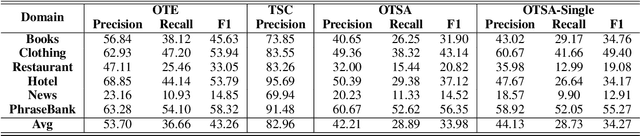
Since previous studies on open-domain targeted sentiment analysis are limited in dataset domain variety and sentence level, we propose a novel dataset consisting of 6,013 human-labeled data to extend the data domains in topics of interest and document level. Furthermore, we offer a nested target annotation schema to extract the complete sentiment information in documents, boosting the practicality and effectiveness of open-domain targeted sentiment analysis. Moreover, we leverage the pre-trained model BART in a sequence-to-sequence generation method for the task. Benchmark results show that there exists large room for improvement of open-domain targeted sentiment analysis. Meanwhile, experiments have shown that challenges remain in the effective use of open-domain data, long documents, the complexity of target structure, and domain variances.
Studying the impacts of pre-training using ChatGPT-generated text on downstream tasks
Sep 02, 2023
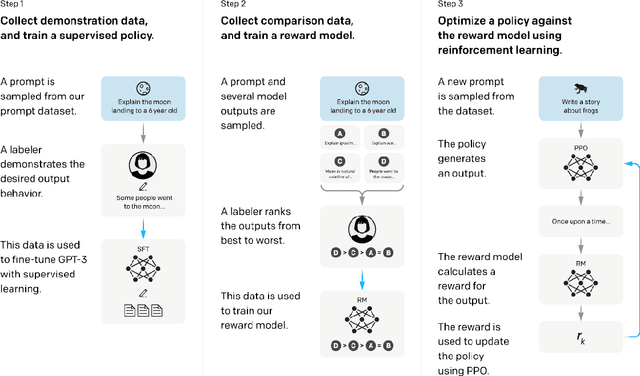
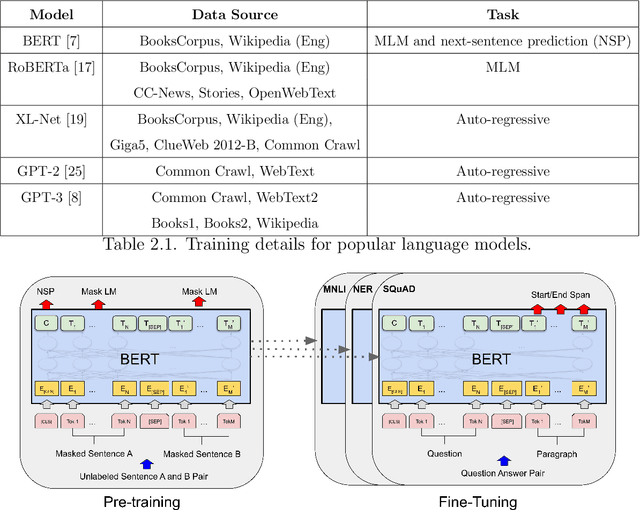
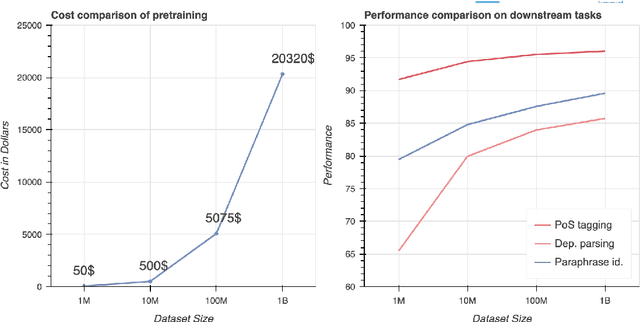
In recent times, significant advancements have been witnessed in the field of language models, particularly with the emergence of Large Language Models (LLMs) that are trained on vast amounts of data extracted from internet archives. These LLMs, such as ChatGPT, have become widely accessible, allowing users to generate text for various purposes including articles, essays, jokes, and poetry. Given that LLMs are trained on a diverse range of text sources, encompassing platforms like Reddit and Twitter, it is foreseeable that future training datasets will also incorporate text generated by previous iterations of the models themselves. In light of this development, our research aims to investigate the influence of artificial text in the pre-training phase of language models. Specifically, we conducted a comparative analysis between a language model, RoBERTa, pre-trained using CNN/DailyMail news articles, and ChatGPT, which employed the same articles for its training and evaluated their performance on three downstream tasks as well as their potential gender bias, using sentiment analysis as a metric. Through a series of experiments, we demonstrate that the utilization of artificial text during pre-training does not have a significant impact on either the performance of the models in downstream tasks or their gender bias. In conclusion, our findings suggest that the inclusion of text generated by LLMs in their own pre-training process does not yield substantial effects on the subsequent performance of the models in downstream tasks or their potential gender bias.
Developing and Evaluating Tiny to Medium-Sized Turkish BERT Models
Jul 26, 2023
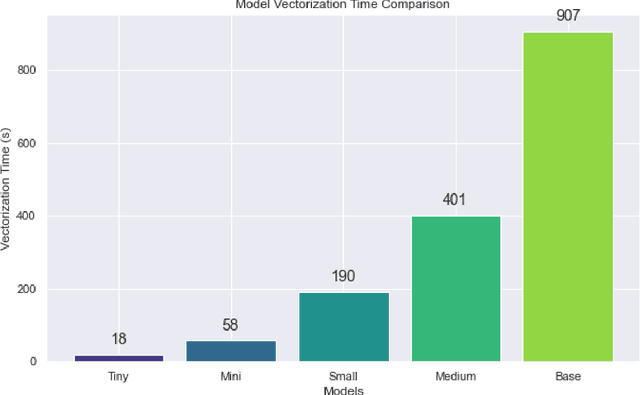
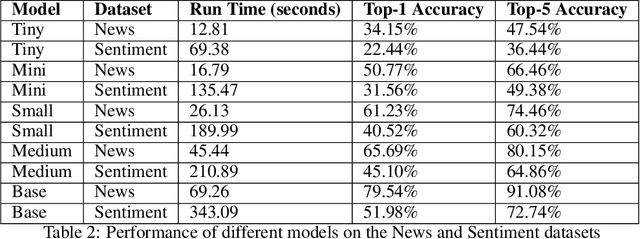
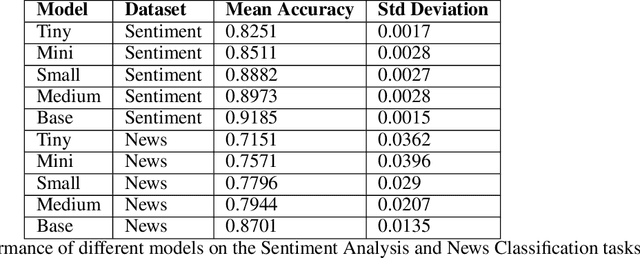
This study introduces and evaluates tiny, mini, small, and medium-sized uncased Turkish BERT models, aiming to bridge the research gap in less-resourced languages. We trained these models on a diverse dataset encompassing over 75GB of text from multiple sources and tested them on several tasks, including mask prediction, sentiment analysis, news classification, and, zero-shot classification. Despite their smaller size, our models exhibited robust performance, including zero-shot task, while ensuring computational efficiency and faster execution times. Our findings provide valuable insights into the development and application of smaller language models, especially in the context of the Turkish language.
Rating Sentiment Analysis Systems for Bias through a Causal Lens
Feb 04, 2023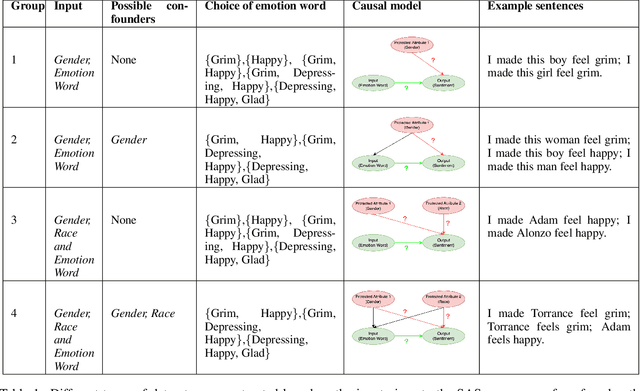
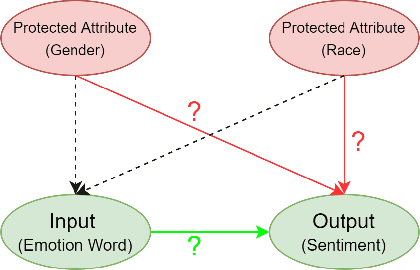
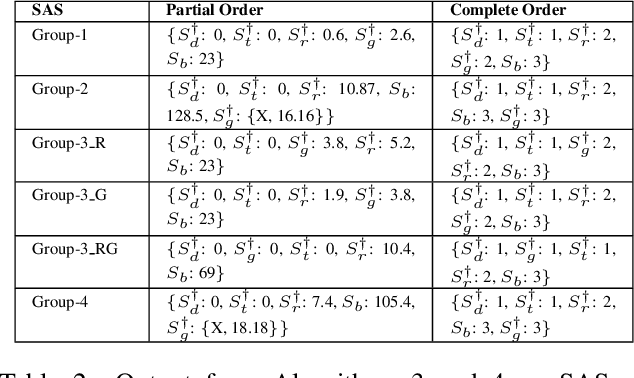
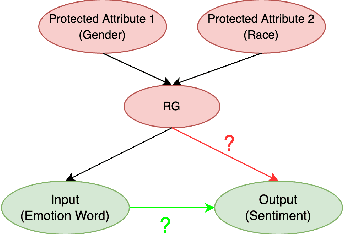
Sentiment Analysis Systems (SASs) are data-driven Artificial Intelligence (AI) systems that, given a piece of text, assign one or more numbers conveying the polarity and emotional intensity expressed in the input. Like other automatic machine learning systems, they have also been known to exhibit model uncertainty where a (small) change in the input leads to drastic swings in the output. This can be especially problematic when inputs are related to protected features like gender or race since such behavior can be perceived as a lack of fairness, i.e., bias. We introduce a novel method to assess and rate SASs where inputs are perturbed in a controlled causal setting to test if the output sentiment is sensitive to protected variables even when other components of the textual input, e.g., chosen emotion words, are fixed. We then use the result to assign labels (ratings) at fine-grained and overall levels to convey the robustness of the SAS to input changes. The ratings serve as a principled basis to compare SASs and choose among them based on behavior. It benefits all users, especially developers who reuse off-the-shelf SASs to build larger AI systems but do not have access to their code or training data to compare.
Presence of informal language, such as emoticons, hashtags, and slang, impact the performance of sentiment analysis models on social media text?
Jan 28, 2023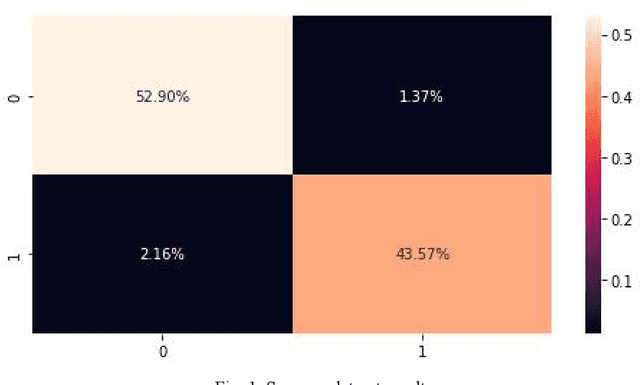
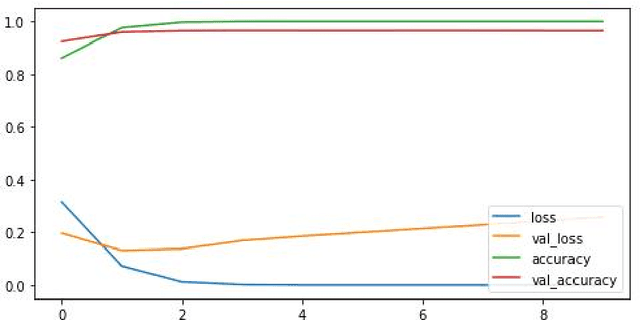
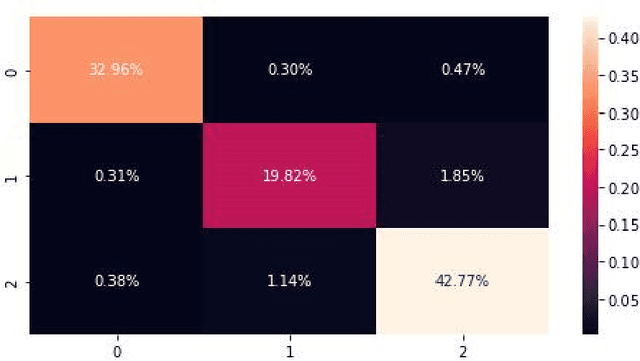
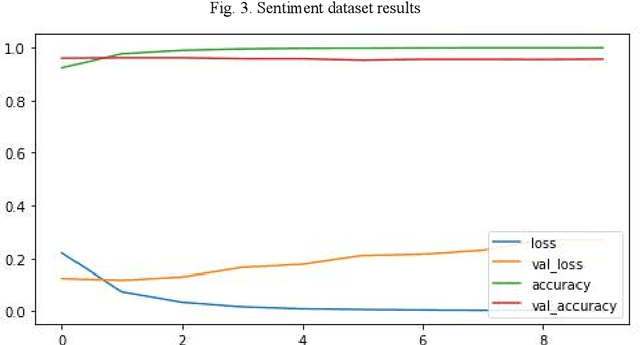
This study aimed to investigate the influence of the presence of informal language, such as emoticons and slang, on the performance of sentiment analysis models applied to social media text. A convolutional neural network (CNN) model was developed and trained on three datasets: a sarcasm dataset, a sentiment dataset, and an emoticon dataset. The model architecture was held constant for all experiments and the model was trained on 80% of the data and tested on 20%. The results revealed that the model achieved an accuracy of 96.47% on the sarcasm dataset, with the lowest accuracy for class 1. On the sentiment dataset, the model achieved an accuracy of 95.28%. The amalgamation of sarcasm and sentiment datasets improved the accuracy of the model to 95.1%, and the addition of emoticon dataset has a slight positive impact on the accuracy of the model to 95.37%. The study suggests that the presence of informal language has a restricted impact on the performance of sentiment analysis models applied to social media text. However, the inclusion of emoticon data to the model can enhance the accuracy slightly.
Grammar Detection for Sentiment Analysis through Improved Viterbi Algorithm
May 26, 2022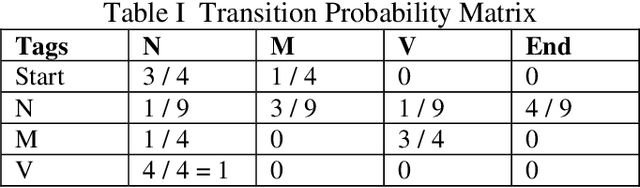
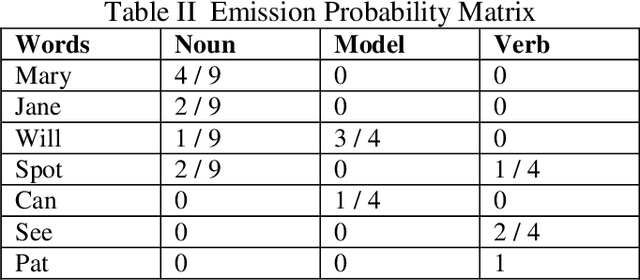
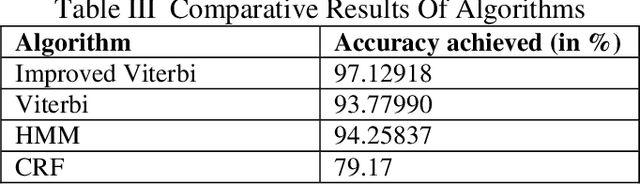
Grammar Detection, also referred to as Parts of Speech Tagging of raw text, is considered an underlying building block of the various Natural Language Processing pipelines like named entity recognition, question answering, and sentiment analysis. In short, forgiven a sentence, Parts of Speech tagging is the task of specifying and tagging each word of a sentence with nouns, verbs, adjectives, adverbs, and more. Sentiment Analysis may well be a procedure accustomed to determining if a given sentence's emotional tone is neutral, positive or negative. To assign polarity scores to the thesis or entities within phrase, in-text analysis and analytics, machine learning and natural language processing, approaches are incorporated. This Sentiment Analysis using POS tagger helps us urge a summary of the broader public over a specific topic. For this, we are using the Viterbi algorithm, Hidden Markov Model, Constraint based Viterbi algorithm for POS tagging. By comparing the accuracies, we select the foremost accurate result of the model for Sentiment Analysis for determining the character of the sentence.
Counterfactual Reasoning for Out-of-distribution Multimodal Sentiment Analysis
Jul 24, 2022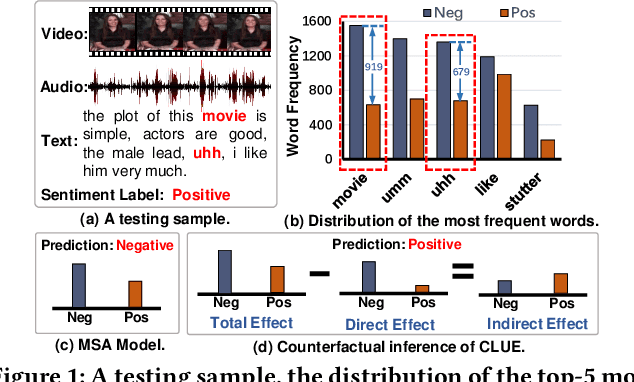
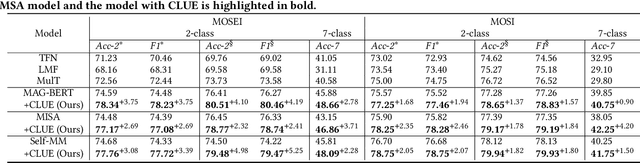
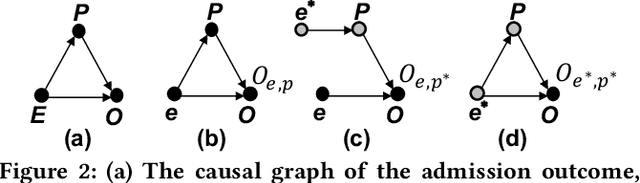
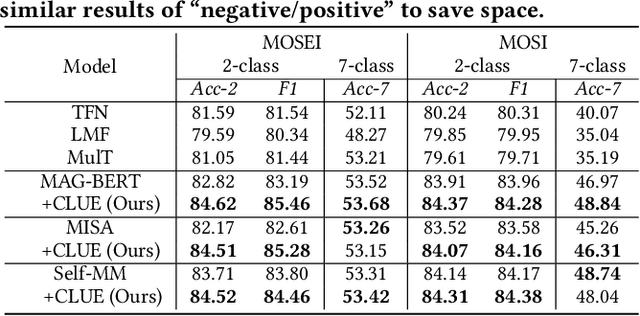
Existing studies on multimodal sentiment analysis heavily rely on textual modality and unavoidably induce the spurious correlations between textual words and sentiment labels. This greatly hinders the model generalization ability. To address this problem, we define the task of out-of-distribution (OOD) multimodal sentiment analysis. This task aims to estimate and mitigate the bad effect of textual modality for strong OOD generalization. To this end, we embrace causal inference, which inspects the causal relationships via a causal graph. From the graph, we find that the spurious correlations are attributed to the direct effect of textual modality on the model prediction while the indirect one is more reliable by considering multimodal semantics. Inspired by this, we devise a model-agnostic counterfactual framework for multimodal sentiment analysis, which captures the direct effect of textual modality via an extra text model and estimates the indirect one by a multimodal model. During the inference, we first estimate the direct effect by the counterfactual inference, and then subtract it from the total effect of all modalities to obtain the indirect effect for reliable prediction. Extensive experiments show the superior effectiveness and generalization ability of our proposed framework.
What Sentiment and Fun Facts We Learnt Before FIFA World Cup Qatar 2022 Using Twitter and AI
Jun 28, 2023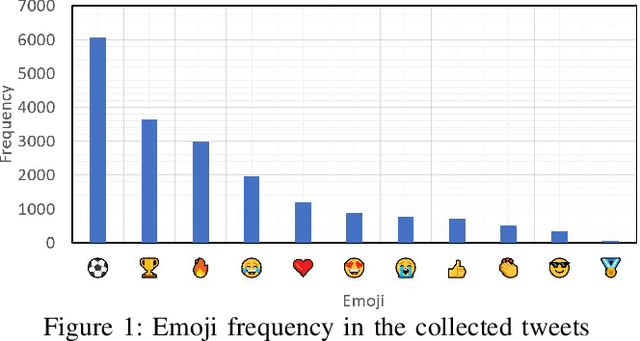


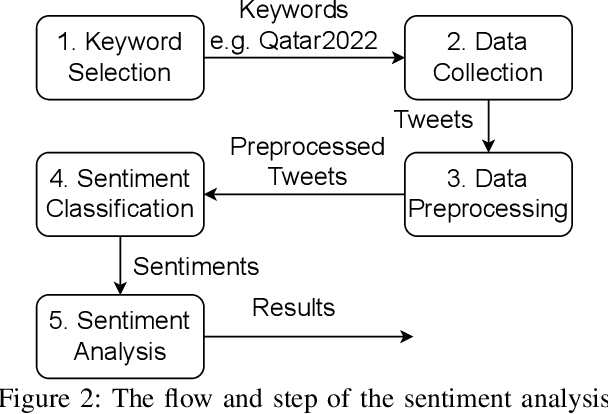
Twitter is a social media platform bridging most countries and allows real-time news discovery. Since the tweets on Twitter are usually short and express public feelings, thus provide a source for opinion mining and sentiment analysis for global events. This paper proposed an effective solution, in providing a sentiment on tweets related to the FIFA World Cup. At least 130k tweets, as the first in the community, are collected and implemented as a dataset to evaluate the performance of the proposed machine learning solution. These tweets are collected with the related hashtags and keywords of the Qatar World Cup 2022. The Vader algorithm is used in this paper for sentiment analysis. Through the machine learning method and collected Twitter tweets, we discovered the sentiments and fun facts of several aspects important to the period before the World Cup. The result shows people are positive to the opening of the World Cup.
Linear Transformations for Cross-lingual Sentiment Analysis
Sep 15, 2022This paper deals with cross-lingual sentiment analysis in Czech, English and French languages. We perform zero-shot cross-lingual classification using five linear transformations combined with LSTM and CNN based classifiers. We compare the performance of the individual transformations, and in addition, we confront the transformation-based approach with existing state-of-the-art BERT-like models. We show that the pre-trained embeddings from the target domain are crucial to improving the cross-lingual classification results, unlike in the monolingual classification, where the effect is not so distinctive.
Towards Understanding In-Context Learning with Contrastive Demonstrations and Saliency Maps
Jul 11, 2023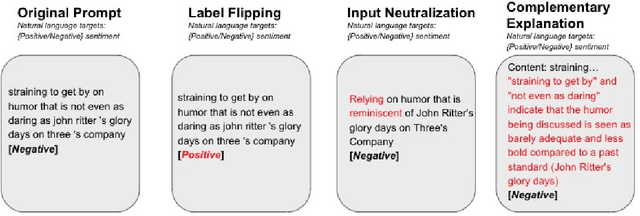

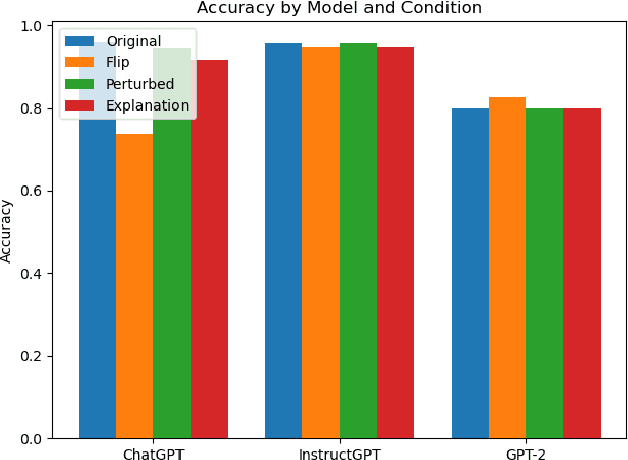
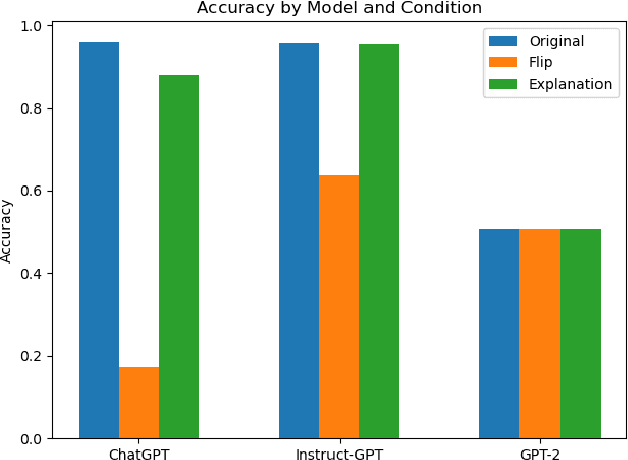
We investigate the role of various demonstration components in the in-context learning (ICL) performance of large language models (LLMs). Specifically, we explore the impacts of ground-truth labels, input distribution, and complementary explanations, particularly when these are altered or perturbed. We build on previous work, which offers mixed findings on how these elements influence ICL. To probe these questions, we employ explainable NLP (XNLP) methods and utilize saliency maps of contrastive demonstrations for both qualitative and quantitative analysis. Our findings reveal that flipping ground-truth labels significantly affects the saliency, though it's more noticeable in larger LLMs. Our analysis of the input distribution at a granular level reveals that changing sentiment-indicative terms in a sentiment analysis task to neutral ones does not have as substantial an impact as altering ground-truth labels. Finally, we find that the effectiveness of complementary explanations in boosting ICL performance is task-dependent, with limited benefits seen in sentiment analysis tasks compared to symbolic reasoning tasks. These insights are critical for understanding the functionality of LLMs and guiding the development of effective demonstrations, which is increasingly relevant in light of the growing use of LLMs in applications such as ChatGPT. Our research code is publicly available at https://github.com/paihengxu/XICL.