 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Implicit Integration of Superpixel Segmentation into Fully Convolutional Networks
Mar 05, 2021
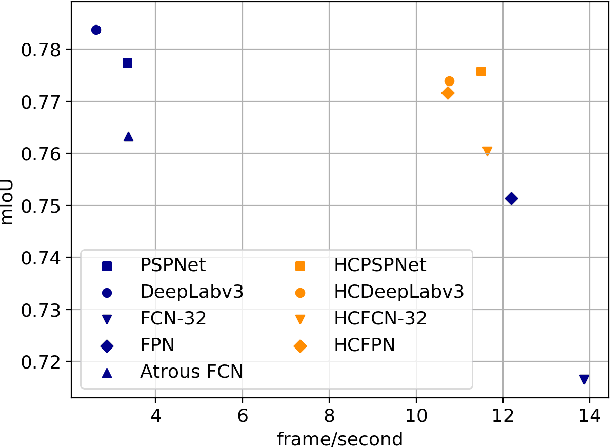
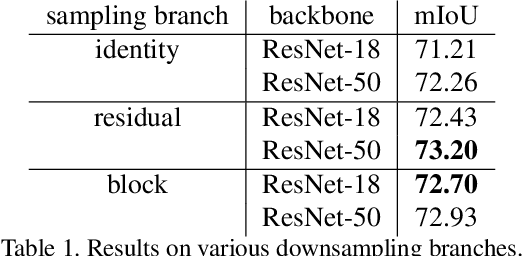

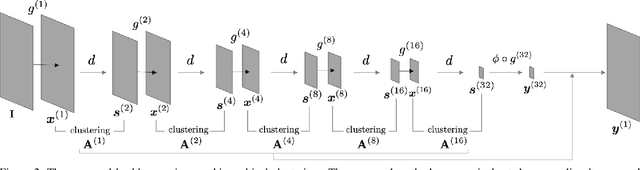
Superpixels are a useful representation to reduce the complexity of image data. However, to combine superpixels with convolutional neural networks (CNNs) in an end-to-end fashion, one requires extra models to generate superpixels and special operations such as graph convolution. In this paper, we propose a way to implicitly integrate a superpixel scheme into CNNs, which makes it easy to use superpixels with CNNs in an end-to-end fashion. Our proposed method hierarchically groups pixels at downsampling layers and generates superpixels. Our method can be plugged into many existing architectures without a change in their feed-forward path because our method does not use superpixels in the feed-forward path but use them to recover the lost resolution instead of bilinear upsampling. As a result, our method preserves detailed information such as object boundaries in the form of superpixels even when the model contains downsampling layers. We evaluate our method on several tasks such as semantic segmentation, superpixel segmentation, and monocular depth estimation, and confirm that it speeds up modern architectures and/or improves their prediction accuracy in these tasks.
FIT: a Fast and Accurate Framework for Solving Medical Inquiring and Diagnosing Tasks
Dec 02, 2020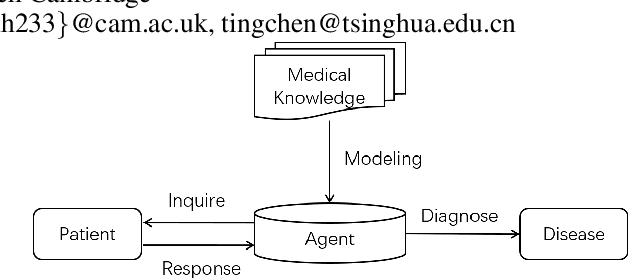


Automatic self-diagnosis provides low-cost and accessible healthcare via an agent that queries the patient and makes predictions about possible diseases. From a machine learning perspective, symptom-based self-diagnosis can be viewed as a sequential feature selection and classification problem. Reinforcement learning methods have shown good performance in this task but often suffer from large search spaces and costly training. To address these problems, we propose a competitive framework, called FIT, which uses an information-theoretic reward to determine what data to collect next. FIT improves over previous information-based approaches by using a multimodal variational autoencoder (MVAE) model and a two-step sampling strategy for disease prediction. Furthermore, we propose novel methods to substantially reduce the computational cost of FIT to a level that is acceptable for practical online self-diagnosis. Our results in two simulated datasets show that FIT can effectively deal with large search space problems, outperforming existing baselines. Moreover, using two medical datasets, we show that FIT is a competitive alternative in real-world settings.
Visual analytics of set data for knowledge discovery and member selection support
Apr 04, 2021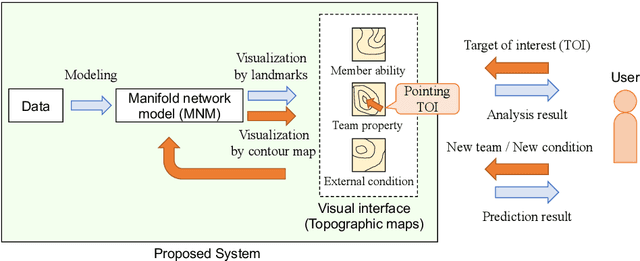
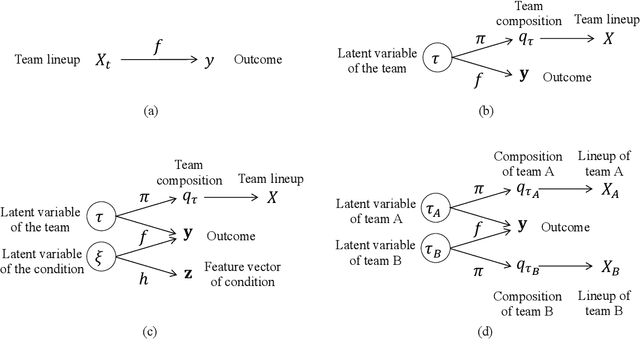
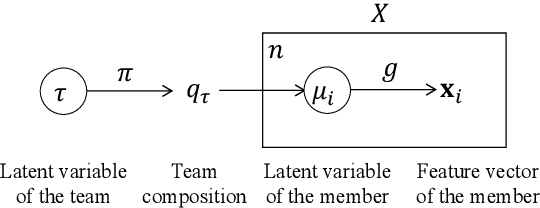
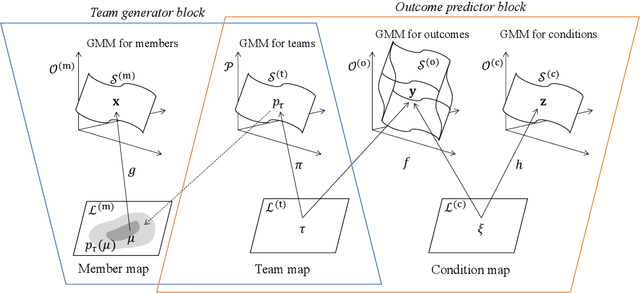
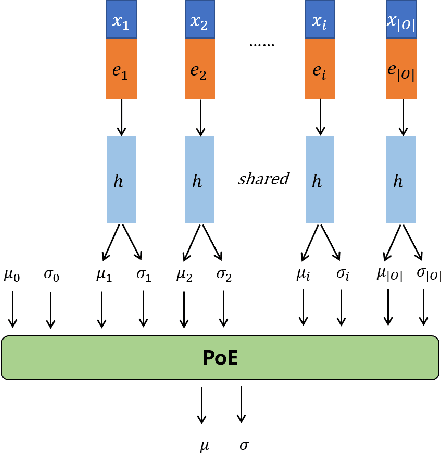
Visual analytics (VA) is a visually assisted exploratory analysis approach in which knowledge discovery is executed interactively between the user and system. The purpose of this study is to develop a method for the VA of set data aimed at supporting knowledge discovery and member selection. A typical target application is a visual support system for team analysis and member selection, by which users can analyze past teams and examine candidate lineups for new teams. Because there are several difficulties, such as the combinatorial explosion problem, developing a VA system of set data is challenging. In this study, we first define the requirements that the target system should satisfy and clarify the accompanying challenges. Then we propose a method for the VA of set data, which satisfies the requirements. The key idea is to model the generation process of sets and their outputs using a manifold network model. The proposed method visualizes the relevant factors as a set of topographic maps on which various information is visualized. Furthermore, using the topographic maps as a bidirectional interface, users can indicate their targets of interest in the system on these maps. We demonstrate the proposed method by applying it to basketball teams, showing how past teams are analyzed and how new lineups are examined. Because the method can be adapted to individual application cases by extending the network structure, it can be a general method by which practical systems can be built.
Generating Human-Like Movement: A Comparison Between Two Approaches Based on Environmental Features
Dec 11, 2020
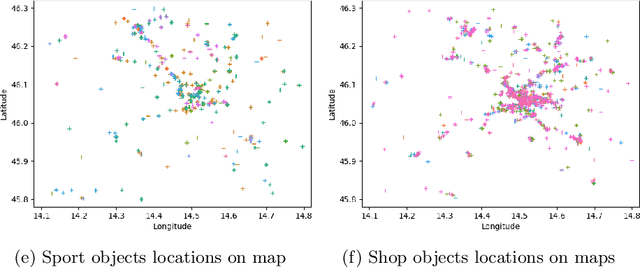

Modelling realistic human behaviours in simulation is an ongoing challenge that resides between several fields like social sciences, philosophy, and artificial intelligence. Human movement is a special type of behaviour driven by intent (e.g. to get groceries) and the surrounding environment (e.g. curiosity to see new interesting places). Services available online and offline do not normally consider the environment when planning a path, which is decisive especially on a leisure trip. Two novel algorithms have been presented to generate human-like trajectories based on environmental features. The Attraction-Based A* algorithm includes in its computation information from the environmental features meanwhile, the Feature-Based A* algorithm also injects information from the real trajectories in its computation. The human-likeness aspect has been tested by a human expert judging the final generated trajectories as realistic. This paper presents a comparison between the two approaches in some key metrics like efficiency, efficacy, and hyper-parameters sensitivity. We show how, despite generating trajectories that are closer to the real one according to our predefined metrics, the Feature-Based A* algorithm fall short in time efficiency compared to the Attraction-Based A* algorithm, hindering the usability of the model in the real world.
Performance Analysis and Optimization of Uplink Cellular Networks with Flexible Frame Structure
Mar 04, 2021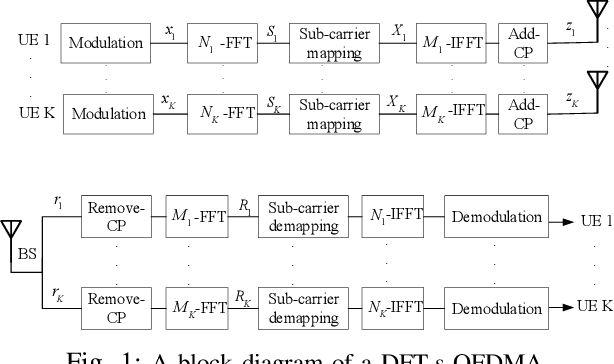
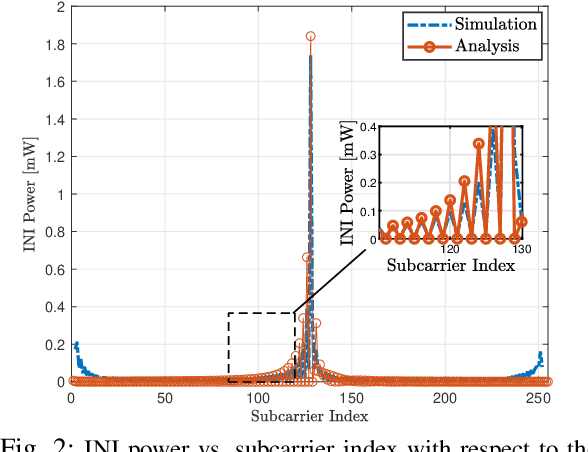
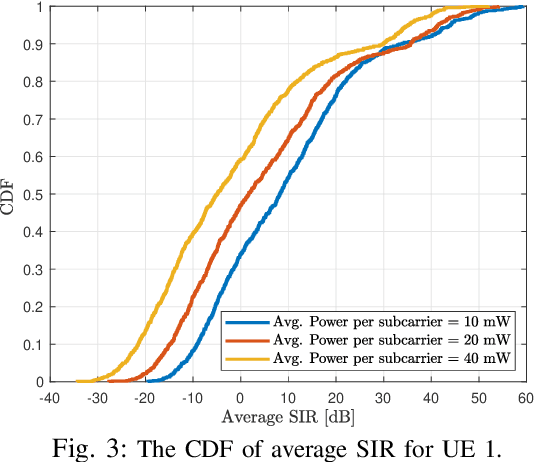
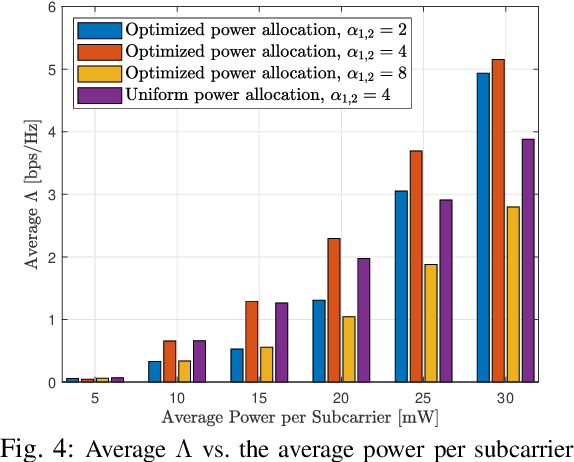
Future wireless cellular networks must support both enhanced mobile broadband (eMBB) and ultra reliable low latency communication (URLLC) to manage heterogeneous data traffic for emerging wireless services. To achieve this goal, a promising technique is to enable flexible frame structure by dynamically changing the data frame's numerology according to the channel information as well as traffic quality of service requirements. However, due to nonorthogonal subcarriers, this technique can result in an interference, known as inter numerology interference (INI), thus, degrading the network performance. In this work, a novel framework is proposed to analyze the INI in the uplink cellular communications. In particular, a closed form expression is derived for the INI power in the uplink with a flexible frame structure, and a new resource allocation problem is formulated to maximize the network spectral efficiency (SE) by jointly optimizing the power allocation and numerology selection in a multi user uplink scenario. The simulation results validate the derived theoretical INI analyses and provide guidelines for power allocation and numerology selection.
Learnable Sampling 3D Convolution for Video Enhancement and Action Recognition
Nov 22, 2020


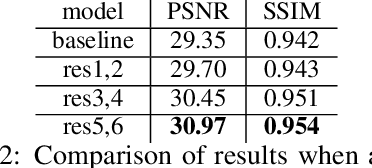
A key challenge in video enhancement and action recognition is to fuse useful information from neighboring frames. Recent works suggest establishing accurate correspondences between neighboring frames before fusing temporal information. However, the generated results heavily depend on the quality of correspondence estimation. In this paper, we propose a more robust solution: \emph{sampling and fusing multi-level features} across neighborhood frames to generate the results. Based on this idea, we introduce a new module to improve the capability of 3D convolution, namely, learnable sampling 3D convolution (\emph{LS3D-Conv}). We add learnable 2D offsets to 3D convolution which aims to sample locations on spatial feature maps across frames. The offsets can be learned for specific tasks. The \emph{LS3D-Conv} can flexibly replace 3D convolution layers in existing 3D networks and get new architectures, which learns the sampling at multiple feature levels. The experiments on video interpolation, video super-resolution, video denoising, and action recognition demonstrate the effectiveness of our approach.
The Programming of Deep Learning Accelerators as a Constraint Satisfaction Problem
Apr 10, 2021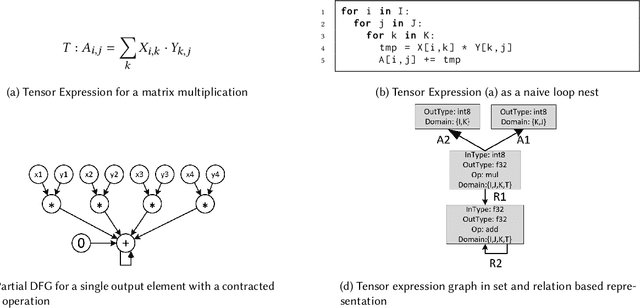
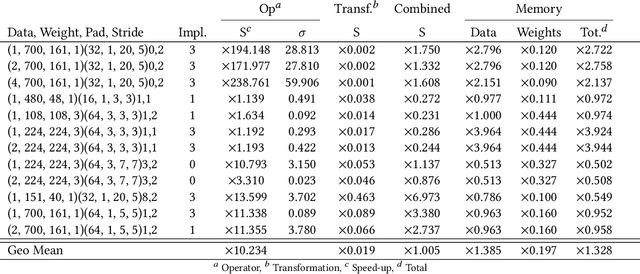

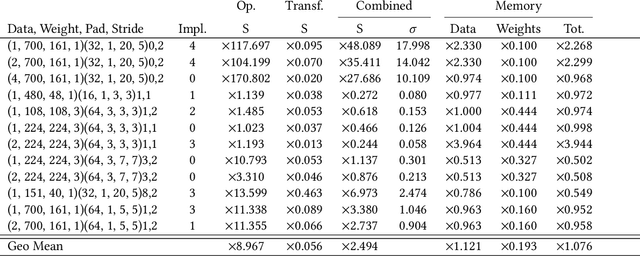
The success of Deep Artificial Neural Networks (DNNs) in many domains created a rich body of research concerned with hardware accelerators for compute-intensive DNN operators. However, implementing such operators efficiently with complex instructions such as matrix multiply is a task not yet automated gracefully. Solving this task often requires complex program and memory layout transformations. First solutions to this problem have been proposed, such as TVM or ISAMIR, which work on a loop-level representation of operators and rewrite the program before an instruction embedding into the operator is performed. This top-down approach creates a tension between exploration range and search space complexity. In this work, we propose a new approach to this problem. We have created a bottom-up method that allows the direct generation of implementations based on an accelerator's instruction set. By formulating the embedding as a constraint satisfaction problem over the scalar dataflow, every possible embedding solution is contained in the search space. By adding additional constraints, a solver can produce the subset of preferable solutions. %From the information in a computed embedding, an implementation can be generated. A detailed evaluation using the VTA hardware accelerator with the Baidu DeepBench inference benchmark suite shows that our approach can automatically generate code competitive to reference implementations, and furthermore that memory layout flexibilty can be beneficial for overall performance. While the reference implementation achieves very low hardware utilization due to its fixed embedding strategy, we achieve a geomean speedup of up to x2.49, while individual operators can improve as much as x238.
Matrix Completion with Noise via Leveraged Sampling
Nov 11, 2020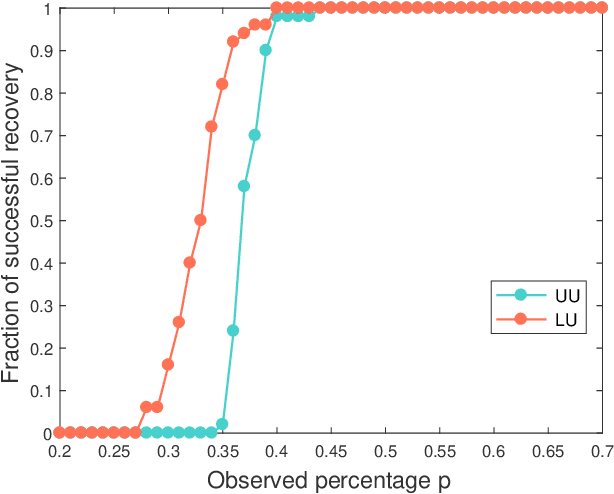
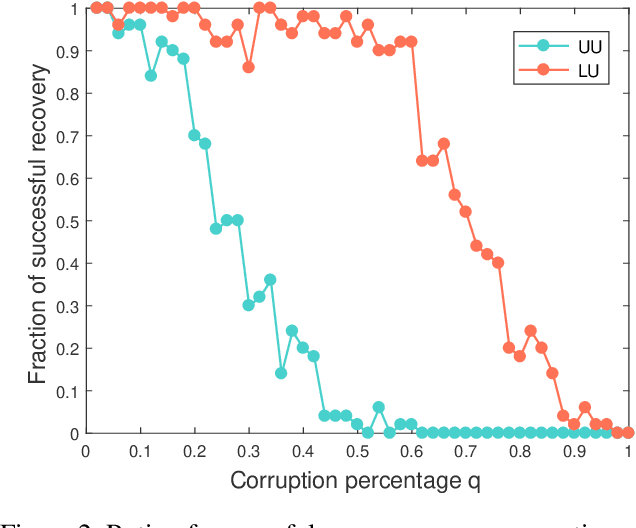
Many matrix completion methods assume that the data follows the uniform distribution. To address the limitation of this assumption, Chen et al. \cite{Chen20152999} propose to recover the matrix where the data follows the specific biased distribution. Unfortunately, in most real-world applications, the recovery of a data matrix appears to be incomplete, and perhaps even corrupted information. This paper considers the recovery of a low-rank matrix, where some observed entries are sampled in a \emph{biased distribution} suitably dependent on \emph{leverage scores} of a matrix, and some observed entries are uniformly corrupted. Our theoretical findings show that we can provably recover an unknown $n\times n$ matrix of rank $r$ from just about $O(nr\log^2 n)$ entries even when the few observed entries are corrupted with a small amount of noisy information. Empirical studies verify our theoretical results.
Maximum sampled conditional likelihood for informative subsampling
Nov 11, 2020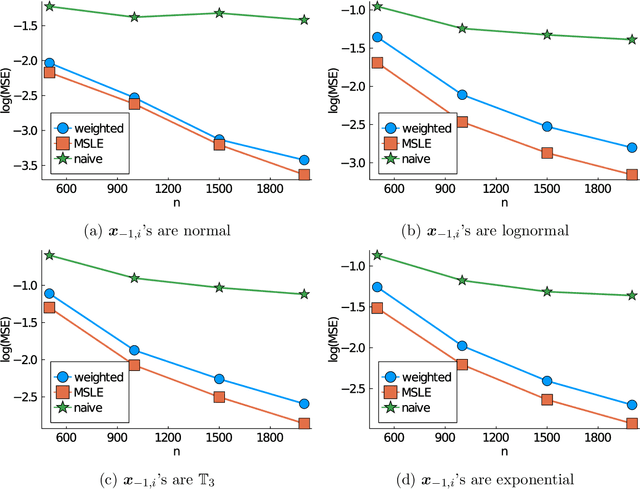
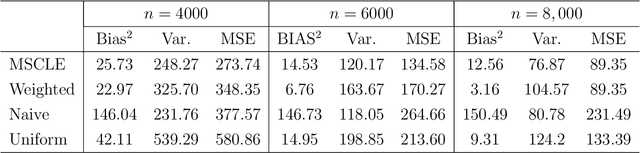
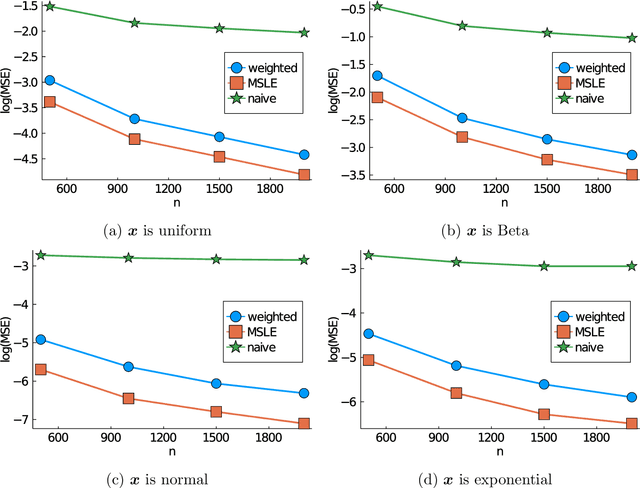
Subsampling is a computationally effective approach to extract information from massive data sets when computing resources are limited. After a subsample is taken from the full data, most available methods use an inverse probability weighted objective function to estimate the model parameters. This type of weighted estimator does not fully utilize information in the selected subsample. In this paper, we propose to use the maximum sampled conditional likelihood estimator (MSCLE) based on the sampled data. We established the asymptotic normality of the MSCLE and prove that its asymptotic variance covariance matrix is the smallest among a class of asymptotically unbiased estimators, including the inverse probability weighted estimator. We further discuss the asymptotic results with the L-optimal subsampling probabilities and illustrate the estimation procedure with generalized linear models. Numerical experiments are provided to evaluate the practical performance of the proposed method.
Phenotyping Clusters of Patient Trajectories suffering from Chronic Complex Disease
Nov 17, 2020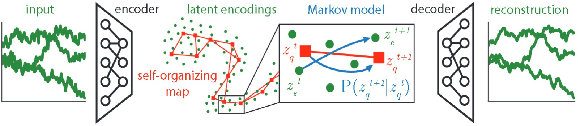
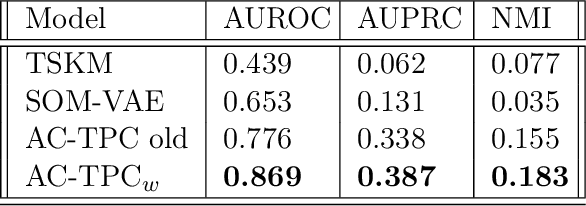
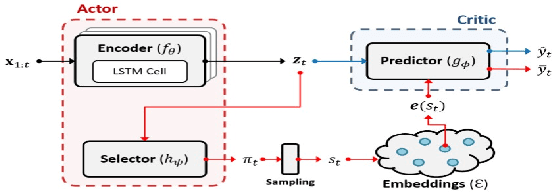
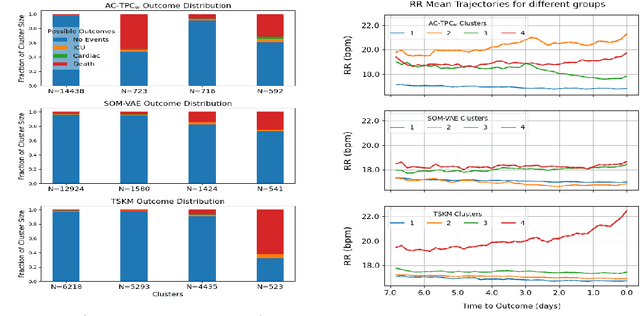
Recent years have seen an increased focus into the tasks of predicting hospital inpatient risk of deterioration and trajectory evolution due to the availability of electronic patient data. A common approach to these problems involves clustering patients time-series information such as vital sign observations) to determine dissimilar subgroups of the patient population. Most clustering methods assume time-invariance of vital-signs and are unable to provide interpretability in clusters that is clinically relevant, for instance, event or outcome information. In this work, we evaluate three different clustering models on a large hospital dataset of vital-sign observations from patients suffering from Chronic Obstructive Pulmonary Disease. We further propose novel modifications to deal with unevenly sampled time-series data and unbalanced class distribution to improve phenotype separation. Lastly, we discuss further avenues of investigation for models to learn patient subgroups with distinct behaviour and phenotype.