 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SmoothI: Smooth Rank Indicators for Differentiable IR Metrics
May 03, 2021
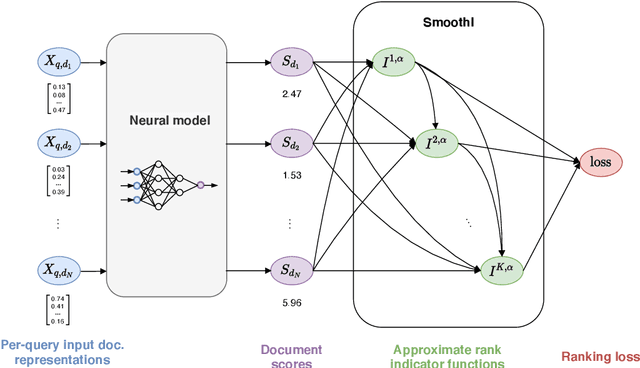
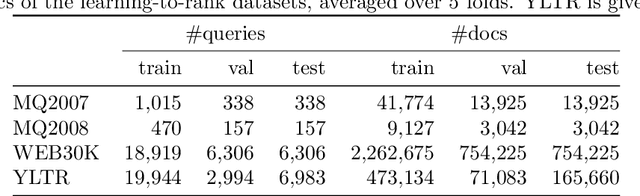
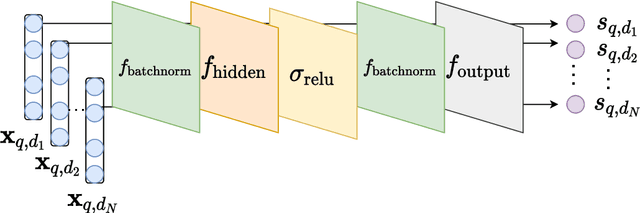
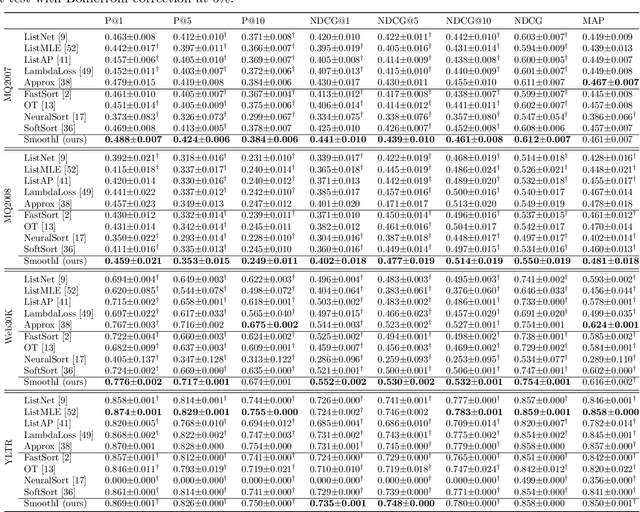
Information retrieval (IR) systems traditionally aim to maximize metrics built on rankings, such as precision or NDCG. However, the non-differentiability of the ranking operation prevents direct optimization of such metrics in state-of-the-art neural IR models, which rely entirely on the ability to compute meaningful gradients. To address this shortcoming, we propose SmoothI, a smooth approximation of rank indicators that serves as a basic building block to devise differentiable approximations of IR metrics. We further provide theoretical guarantees on SmoothI and derived approximations, showing in particular that the approximation errors decrease exponentially with an inverse temperature-like hyperparameter that controls the quality of the approximations. Extensive experiments conducted on four standard learning-to-rank datasets validate the efficacy of the listwise losses based on SmoothI, in comparison to previously proposed ones. Additional experiments with a vanilla BERT ranking model on a text-based IR task also confirm the benefits of our listwise approach.
MindReader: Recommendation over Knowledge Graph Entities with Explicit User Ratings
Jun 08, 2021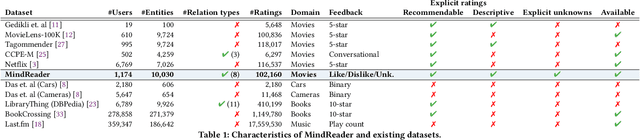
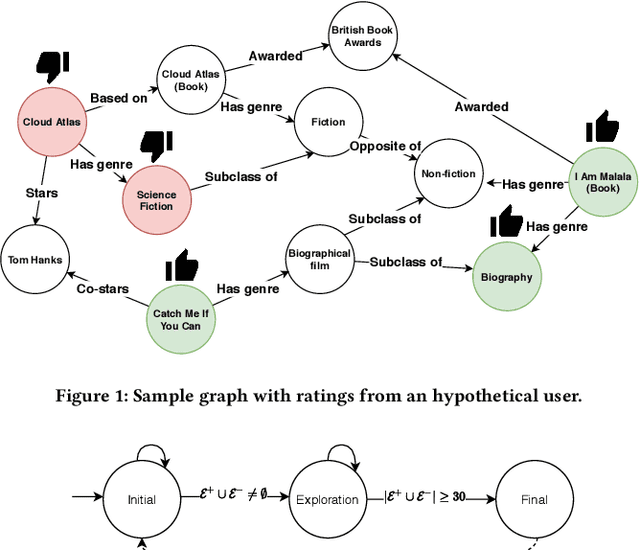
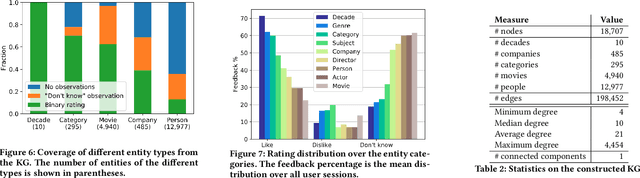
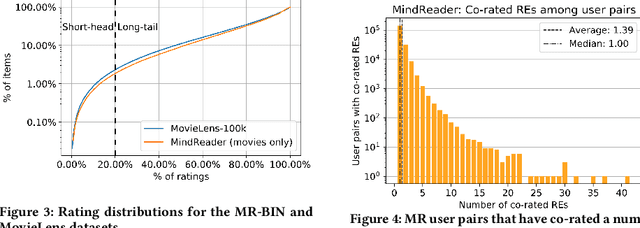
Knowledge Graphs (KGs) have been integrated in several models of recommendation to augment the informational value of an item by means of its related entities in the graph. Yet, existing datasets only provide explicit ratings on items and no information is provided about user opinions of other (non-recommendable) entities. To overcome this limitation, we introduce a new dataset, called the MindReader, providing explicit user ratings both for items and for KG entities. In this first version, the MindReader dataset provides more than 102 thousands explicit ratings collected from 1,174 real users on both items and entities from a KG in the movie domain. This dataset has been collected through an online interview application that we also release open source. As a demonstration of the importance of this new dataset, we present a comparative study of the effect of the inclusion of ratings on non-item KG entities in a variety of state-of-the-art recommendation models. In particular, we show that most models, whether designed specifically for graph data or not, see improvements in recommendation quality when trained on explicit non-item ratings. Moreover, for some models, we show that non-item ratings can effectively replace item ratings without loss of recommendation quality. This finding, thanks also to an observed greater familiarity of users towards common KG entities than towards long-tail items, motivates the use of KG entities for both warm and cold-start recommendations.
Looking for COVID-19 misinformation in multilingual social media texts
May 03, 2021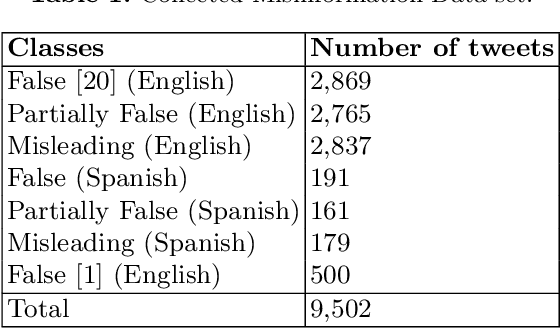
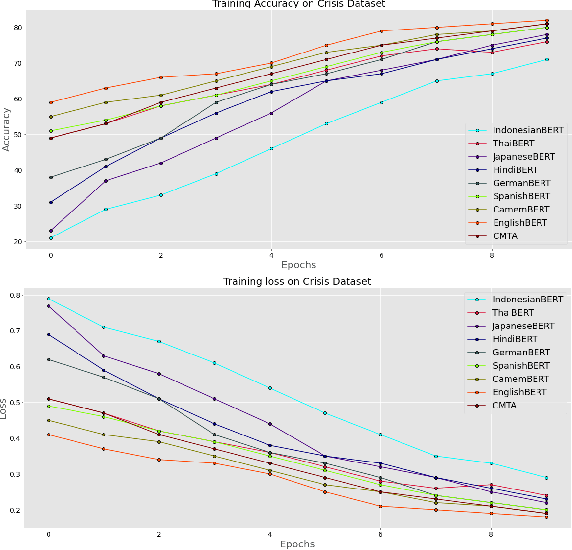
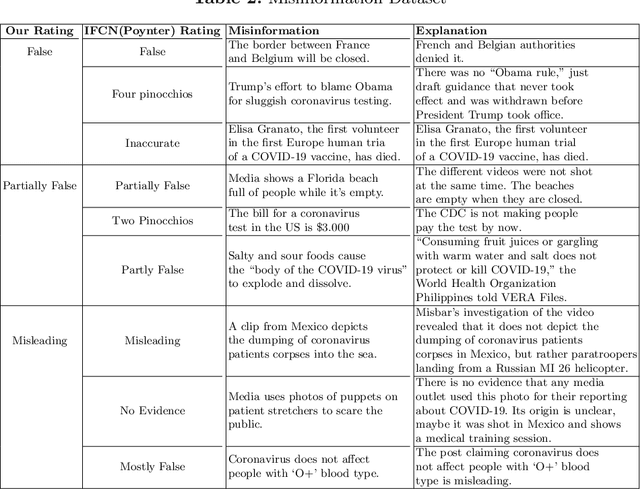
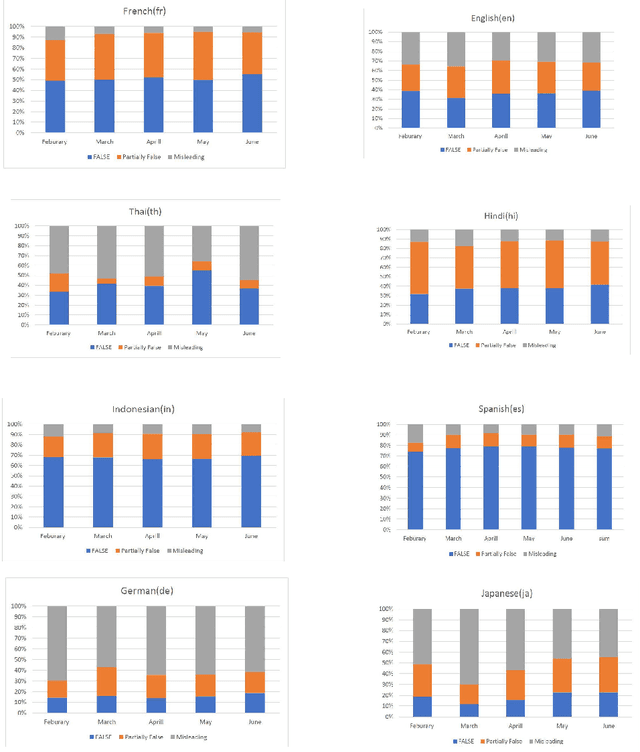
This paper presents the Multilingual COVID-19 Analysis Method (CMTA) for detecting and observing the spread of misinformation about this disease within texts. CMTA proposes a data science (DS) pipeline that applies machine learning models for processing, classifying (Dense-CNN) and analyzing (MBERT) multilingual (micro)-texts. DS pipeline data preparation tasks extract features from multilingual textual data and categorize it into specific information classes (i.e., 'false', 'partly false', 'misleading'). The CMTA pipeline has been experimented with multilingual micro-texts (tweets), showing misinformation spread across different languages. To assess the performance of CMTA and put it in perspective, we performed a comparative analysis of CMTA with eight monolingual models used for detecting misinformation. The comparison shows that CMTA has surpassed various monolingual models and suggests that it can be used as a general method for detecting misinformation in multilingual micro-texts. CMTA experimental results show misinformation trends about COVID-19 in different languages during the first pandemic months.
Computer Vision and Conflicting Values: Describing People with Automated Alt Text
May 26, 2021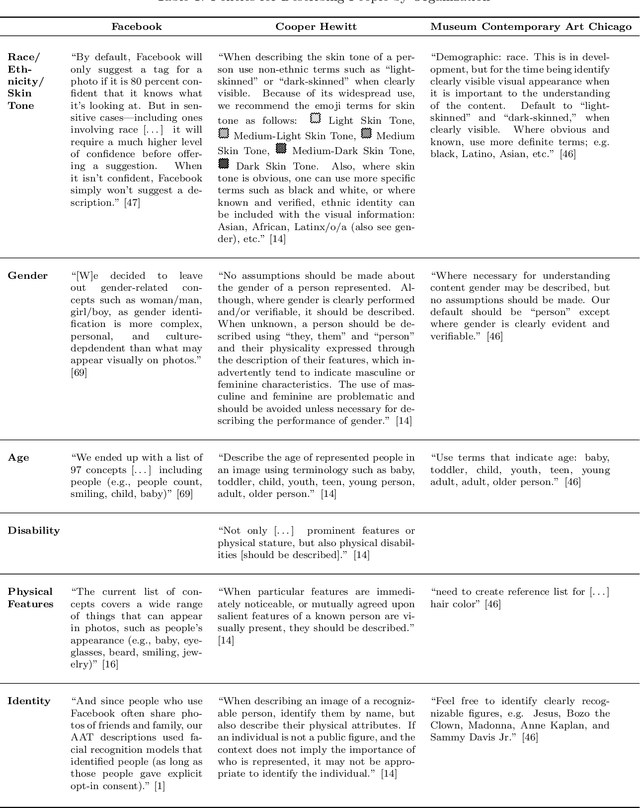
Scholars have recently drawn attention to a range of controversial issues posed by the use of computer vision for automatically generating descriptions of people in images. Despite these concerns, automated image description has become an important tool to ensure equitable access to information for blind and low vision people. In this paper, we investigate the ethical dilemmas faced by companies that have adopted the use of computer vision for producing alt text: textual descriptions of images for blind and low vision people, We use Facebook's automatic alt text tool as our primary case study. First, we analyze the policies that Facebook has adopted with respect to identity categories, such as race, gender, age, etc., and the company's decisions about whether to present these terms in alt text. We then describe an alternative -- and manual -- approach practiced in the museum community, focusing on how museums determine what to include in alt text descriptions of cultural artifacts. We compare these policies, using notable points of contrast to develop an analytic framework that characterizes the particular apprehensions behind these policy choices. We conclude by considering two strategies that seem to sidestep some of these concerns, finding that there are no easy ways to avoid the normative dilemmas posed by the use of computer vision to automate alt text.
Aggregating Nested Transformers
May 26, 2021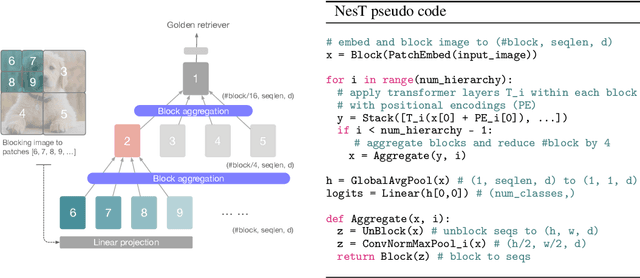
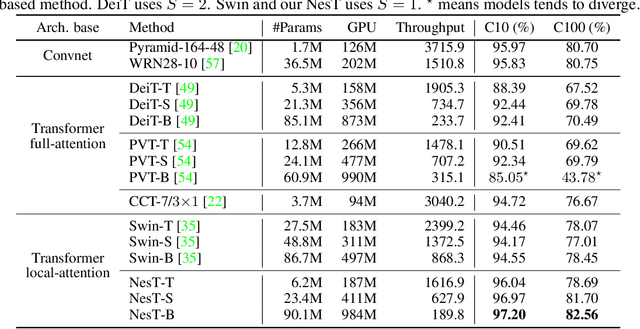
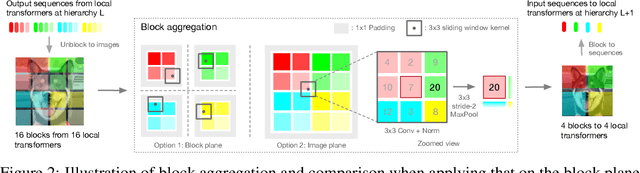
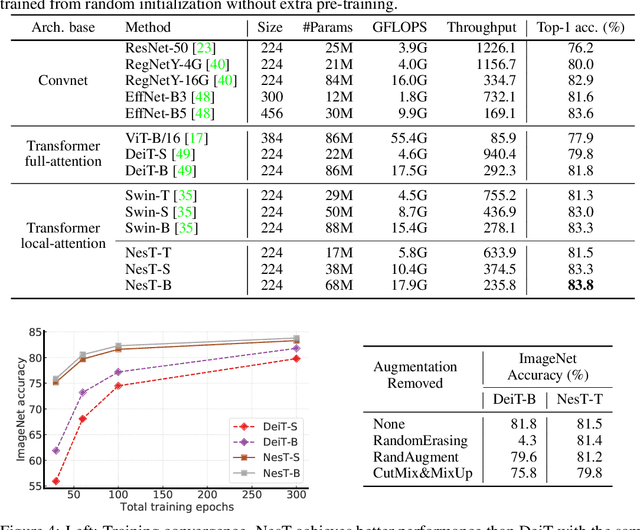
Although hierarchical structures are popular in recent vision transformers, they require sophisticated designs and massive datasets to work well. In this work, we explore the idea of nesting basic local transformers on non-overlapping image blocks and aggregating them in a hierarchical manner. We find that the block aggregation function plays a critical role in enabling cross-block non-local information communication. This observation leads us to design a simplified architecture with minor code changes upon the original vision transformer and obtains improved performance compared to existing methods. Our empirical results show that the proposed method NesT converges faster and requires much less training data to achieve good generalization. For example, a NesT with 68M parameters trained on ImageNet for 100/300 epochs achieves $82.3\%/83.8\%$ accuracy evaluated on $224\times 224$ image size, outperforming previous methods with up to $57\%$ parameter reduction. Training a NesT with 6M parameters from scratch on CIFAR10 achieves $96\%$ accuracy using a single GPU, setting a new state of the art for vision transformers. Beyond image classification, we extend the key idea to image generation and show NesT leads to a strong decoder that is 8$\times$ faster than previous transformer based generators. Furthermore, we also propose a novel method for visually interpreting the learned model.
A Generalized A* Algorithm for Finding Globally Optimal Paths in Weighted Colored Graphs
Dec 24, 2020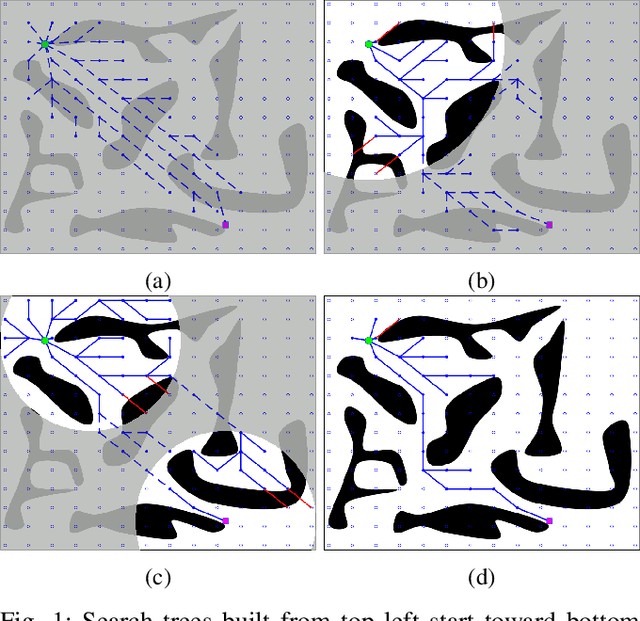
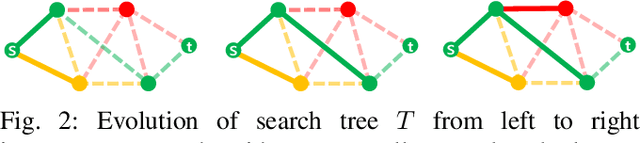
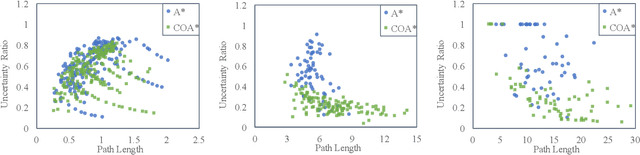
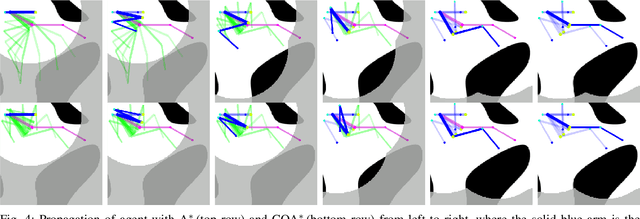
Both geometric and semantic information of the search space is imperative for a good plan. We encode those properties in a weighted colored graph (geometric information in terms of edge weight and semantic information in terms of edge and vertex color), and propose a generalized A* to find the shortest path among the set of paths with minimal inclusion of low-ranked color edges. We prove the completeness and optimality of this Class-Ordered A* (COA*) algorithm with respect to the hereto defined notion of optimality. The utility of COA* is numerically validated in a ternary graph with feasible, infeasible, and unknown vertices and edges for the cases of a 2D mobile robot, a 3D robotic arm, and a 5D robotic arm with limited sensing capabilities. We compare the results of COA* to that of the regular A* algorithm, the latter of which finds the shortest path regardless of uncertainty, and we show that the COA* dominates the A* solution in terms of finding less uncertain paths.
Geo-Spatiotemporal Features and Shape-Based Prior Knowledge for Fine-grained Imbalanced Data Classification
Mar 21, 2021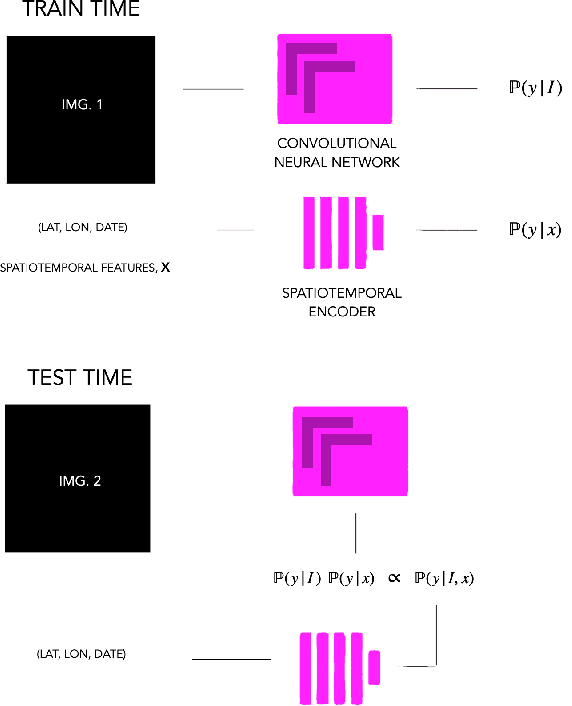
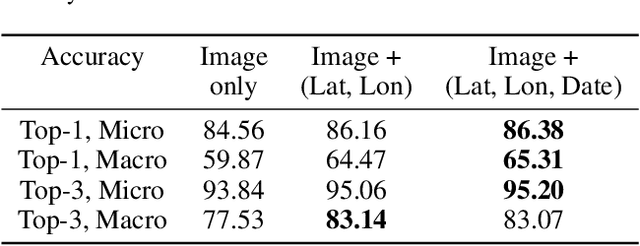

Fine-grained classification aims at distinguishing between items with similar global perception and patterns, but that differ by minute details. Our primary challenges come from both small inter-class variations and large intra-class variations. In this article, we propose to combine several innovations to improve fine-grained classification within the use-case of wildlife, which is of practical interest for experts. We utilize geo-spatiotemporal data to enrich the picture information and further improve the performance. We also investigate state-of-the-art methods for handling the imbalanced data issue.
* Copyright by the authors. All rights reserved to authors only. Correspondence to: ckantor (at) stanford [dot] edu
Metric Embedding Sub-discrimination Study
Feb 05, 2021
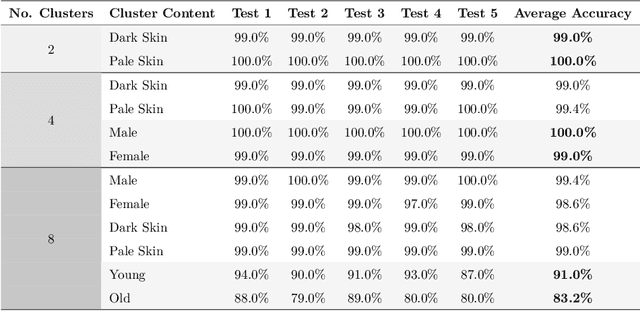
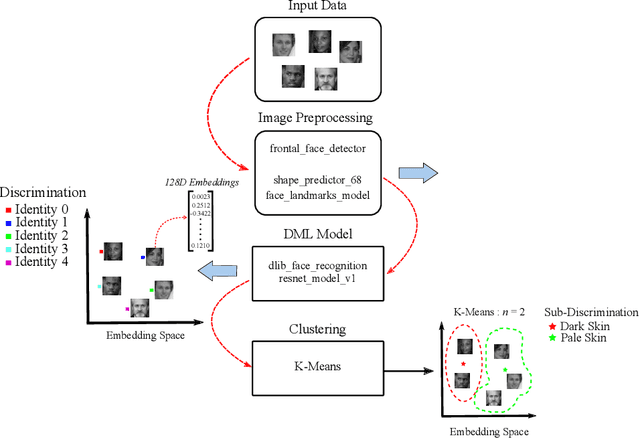
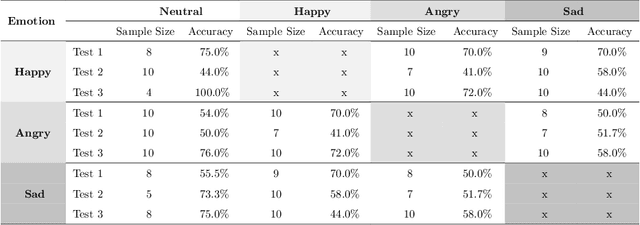
Deep metric learning is a technique used in a variety of discriminative tasks to achieve zero-shot, one-shot or few-shot learning. When applied, the system learns an embedding space where a non-parametric approach, such as \gls{knn}, can be used to discriminate features during test time. This work focuses on investigating to what extent feature information contained within this embedding space can be used to carry out sub-discrimination in the feature space. The study shows that within a discrimination embedding, the information on the salient attributes needed to solve the problem of sub-discrimination is saved within the embedding and that this inherent information can be used to carry out sub-discriminative tasks. To demonstrate this, an embedding designed initially to discriminate faces is used to differentiate several attributes such as gender, age and skin tone, without any additional training. The study is split into two study cases: intra class discrimination where all the embeddings took into consideration are from the same identity; and extra class discrimination where the embeddings represent different identities. After the study, it is shown that it is possible to infer common attributes to different identities. The system can also perform extra class sub-discrimination with a high accuracy rate, notably 99.3\%, 99.3\% and 94.1\% for gender, skin tone, and age, respectively. Intra class tests show more mixed results with more nuanced attributes like emotions not being reliably classified, while more distinct attributes such as thick-framed glasses and beards, achieving 97.2\% and 95.8\% accuracy, respectively.
Dynamic Probabilistic Pruning: A general framework for hardware-constrained pruning at different granularities
May 26, 2021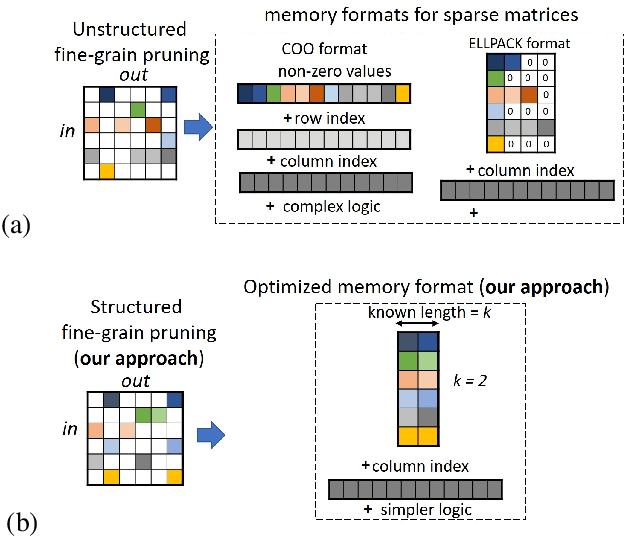
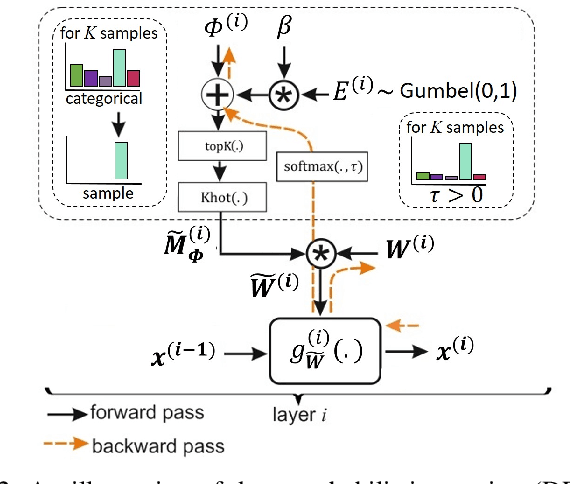
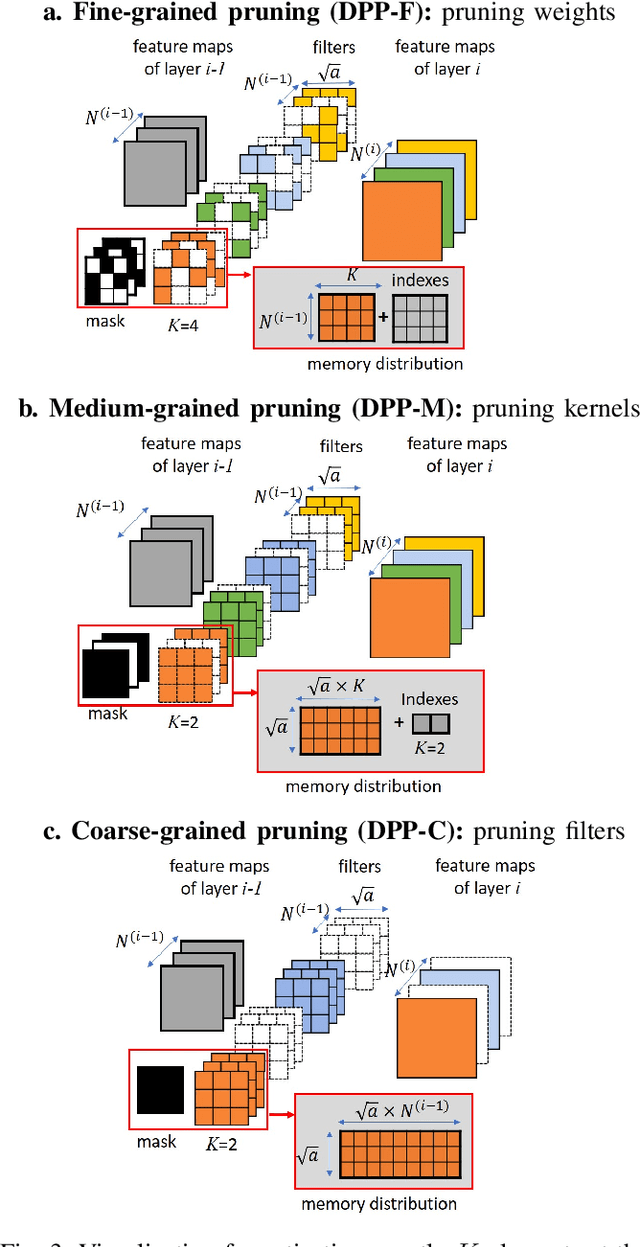
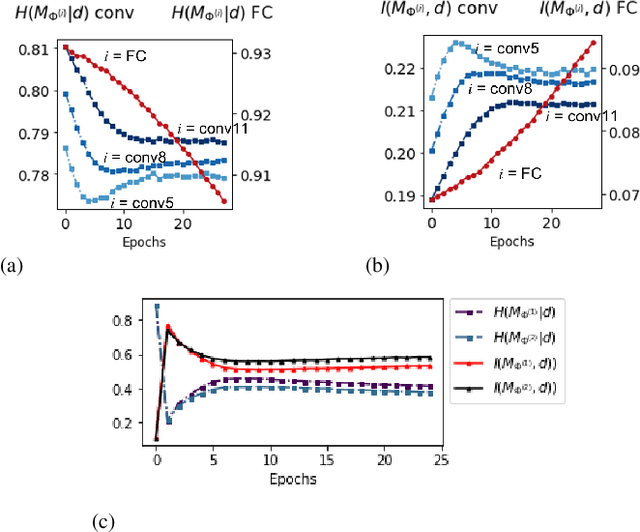
Unstructured neural network pruning algorithms have achieved impressive compression rates. However, the resulting - typically irregular - sparse matrices hamper efficient hardware implementations, leading to additional memory usage and complex control logic that diminishes the benefits of unstructured pruning. This has spurred structured coarse-grained pruning solutions that prune entire filters or even layers, enabling efficient implementation at the expense of reduced flexibility. Here we propose a flexible new pruning mechanism that facilitates pruning at different granularities (weights, kernels, filters/feature maps), while retaining efficient memory organization (e.g. pruning exactly k-out-of-n weights for every output neuron, or pruning exactly k-out-of-n kernels for every feature map). We refer to this algorithm as Dynamic Probabilistic Pruning (DPP). DPP leverages the Gumbel-softmax relaxation for differentiable k-out-of-n sampling, facilitating end-to-end optimization. We show that DPP achieves competitive compression rates and classification accuracy when pruning common deep learning models trained on different benchmark datasets for image classification. Relevantly, the non-magnitude-based nature of DPP allows for joint optimization of pruning and weight quantization in order to even further compress the network, which we show as well. Finally, we propose novel information theoretic metrics that show the confidence and pruning diversity of pruning masks within a layer.
Using four different online media sources to forecast the crude oil price
May 19, 2021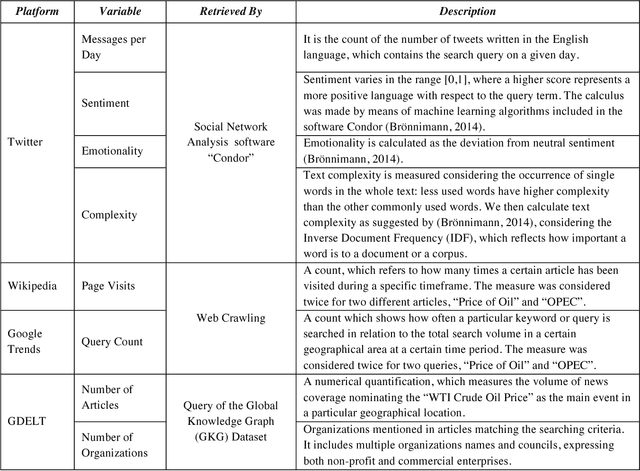

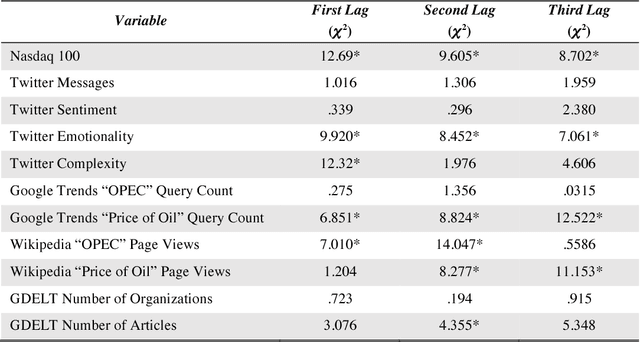
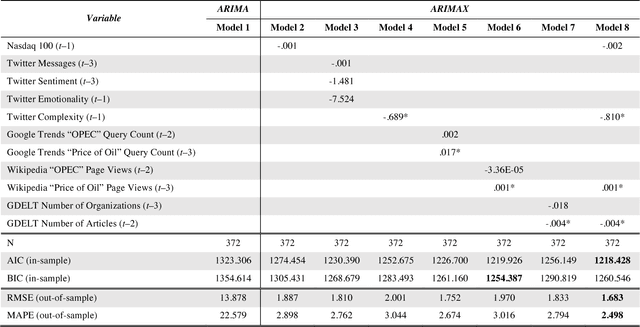
This study looks for signals of economic awareness on online social media and tests their significance in economic predictions. The study analyses, over a period of two years, the relationship between the West Texas Intermediate daily crude oil price and multiple predictors extracted from Twitter, Google Trends, Wikipedia, and the Global Data on Events, Language, and Tone database (GDELT). Semantic analysis is applied to study the sentiment, emotionality and complexity of the language used. Autoregressive Integrated Moving Average with Explanatory Variable (ARIMAX) models are used to make predictions and to confirm the value of the study variables. Results show that the combined analysis of the four media platforms carries valuable information in making financial forecasting. Twitter language complexity, GDELT number of articles and Wikipedia page reads have the highest predictive power. This study also allows a comparison of the different fore-sighting abilities of each platform, in terms of how many days ahead a platform can predict a price movement before it happens. In comparison with previous work, more media sources and more dimensions of the interaction and of the language used are combined in a joint analysis.