 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Use of a Large Language Model-Powered Guide to Make Virtual Reality Accessible for Blind and Low Vision People
Mar 10, 2026As social virtual reality (VR) grows more popular, addressing accessibility for blind and low vision (BLV) users is increasingly critical. Researchers have proposed an AI "sighted guide" to help users navigate VR and answer their questions, but it has not been studied with users. To address this gap, we developed a large language model (LLM)-powered guide and studied its use with 16 BLV participants in virtual environments with confederates posing as other users. We found that when alone, participants treated the guide as a tool, but treated it companionably around others, giving it nicknames, rationalizing its mistakes with its appearance, and encouraging confederate-guide interaction. Our work furthers understanding of guides as a versatile method for VR accessibility and presents design recommendations for future guides.
How Multimodal Large Language Models Support Access to Visual Information: A Diary Study With Blind and Low Vision People
Feb 13, 2026Multimodal large language models (MLLMs) are changing how Blind and Low Vision (BLV) people access visual information in their daily lives. Unlike traditional visual interpretation tools that provide access through captions and OCR (text recognition through camera input), MLLM-enabled applications support access through conversational assistance, where users can ask questions to obtain goal-relevant details. However, evidence about their performance in the real-world and their implications for BLV people's everyday life remain limited. To address this, we conducted a two-week diary study, where we captured 20 BLV participants' use of an MLLM-enabled visual interpretation application. Although participants rated the visual interpretations of the application as "somewhat trustworthy" (mean=3.76 out of 5, max=very trustworthy) and "somewhat satisfying" (mean=4.13 out of 5, max=very satisfying), the AI often produced incorrect answers (22.2%) or abstained (10.8%) from responding to follow-up requests. Our work demonstrates that MLLMs can improve the accuracy of descriptive visual interpretations, but that supporting everyday use also depends on the "visual assistant" skill -- a set of behaviors for providing goal-directed, reliable assistance. We conclude by proposing the "visual assistant" skill and practical guidelines to help future MLLM-enabled visual interpretation applications better support BLV people's access to visual information.
Towards Understanding the Use of MLLM-Enabled Applications for Visual Interpretation by Blind and Low Vision People
Mar 07, 2025



Blind and Low Vision (BLV) people have adopted AI-powered visual interpretation applications to address their daily needs. While these applications have been helpful, prior work has found that users remain unsatisfied by their frequent errors. Recently, multimodal large language models (MLLMs) have been integrated into visual interpretation applications, and they show promise for more descriptive visual interpretations. However, it is still unknown how this advancement has changed people's use of these applications. To address this gap, we conducted a two-week diary study in which 20 BLV people used an MLLM-enabled visual interpretation application we developed, and we collected 553 entries. In this paper, we report a preliminary analysis of 60 diary entries from 6 participants. We found that participants considered the application's visual interpretations trustworthy (mean 3.75 out of 5) and satisfying (mean 4.15 out of 5). Moreover, participants trusted our application in high-stakes scenarios, such as receiving medical dosage advice. We discuss our plan to complete our analysis to inform the design of future MLLM-enabled visual interpretation systems.
Investigating Use Cases of AI-Powered Scene Description Applications for Blind and Low Vision People
Mar 22, 2024



"Scene description" applications that describe visual content in a photo are useful daily tools for blind and low vision (BLV) people. Researchers have studied their use, but they have only explored those that leverage remote sighted assistants; little is known about applications that use AI to generate their descriptions. Thus, to investigate their use cases, we conducted a two-week diary study where 16 BLV participants used an AI-powered scene description application we designed. Through their diary entries and follow-up interviews, users shared their information goals and assessments of the visual descriptions they received. We analyzed the entries and found frequent use cases, such as identifying visual features of known objects, and surprising ones, such as avoiding contact with dangerous objects. We also found users scored the descriptions relatively low on average, 2.76 out of 5 (SD=1.49) for satisfaction and 2.43 out of 4 (SD=1.16) for trust, showing that descriptions still need significant improvements to deliver satisfying and trustworthy experiences. We discuss future opportunities for AI as it becomes a more powerful accessibility tool for BLV users.
Computer Vision and Conflicting Values: Describing People with Automated Alt Text
May 26, 2021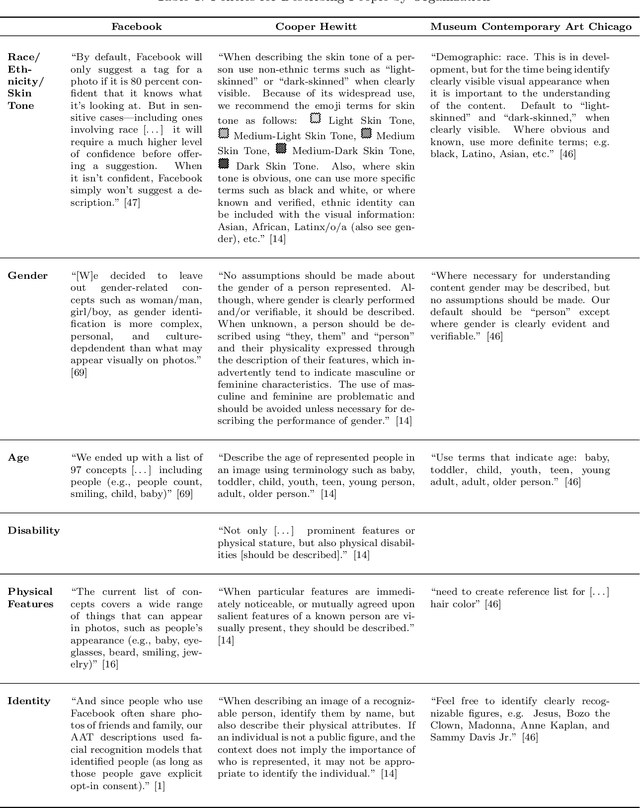
Scholars have recently drawn attention to a range of controversial issues posed by the use of computer vision for automatically generating descriptions of people in images. Despite these concerns, automated image description has become an important tool to ensure equitable access to information for blind and low vision people. In this paper, we investigate the ethical dilemmas faced by companies that have adopted the use of computer vision for producing alt text: textual descriptions of images for blind and low vision people, We use Facebook's automatic alt text tool as our primary case study. First, we analyze the policies that Facebook has adopted with respect to identity categories, such as race, gender, age, etc., and the company's decisions about whether to present these terms in alt text. We then describe an alternative -- and manual -- approach practiced in the museum community, focusing on how museums determine what to include in alt text descriptions of cultural artifacts. We compare these policies, using notable points of contrast to develop an analytic framework that characterizes the particular apprehensions behind these policy choices. We conclude by considering two strategies that seem to sidestep some of these concerns, finding that there are no easy ways to avoid the normative dilemmas posed by the use of computer vision to automate alt text.