 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Limits of Graph Samplers for Training Inductive Recommender Systems: Extended results
May 20, 2025



Inductive Recommender Systems are capable of recommending for new users and with new items thus avoiding the need to retrain after new data reaches the system. However, these methods are still trained on all the data available, requiring multiple days to train a single model, without counting hyperparameter tuning. In this work we focus on graph-based recommender systems, i.e., systems that model the data as a heterogeneous network. In other applications, graph sampling allows to study a subgraph and generalize the findings to the original graph. Thus, we investigate the applicability of sampling techniques for this task. We test on three real world datasets, with three state-of-the-art inductive methods, and using six different sampling methods. We find that its possible to maintain performance using only 50% of the training data with up to 86% percent decrease in training time; however, using less training data leads to far worse performance. Further, we find that when it comes to data for recommendations, graph sampling should also account for the temporal dimension. Therefore, we find that if higher data reduction is needed, new graph based sampling techniques should be studied and new inductive methods should be designed.
Large Language Models and Knowledge Graphs: Opportunities and Challenges
Aug 11, 2023Large Language Models (LLMs) have taken Knowledge Representation -- and the world -- by storm. This inflection point marks a shift from explicit knowledge representation to a renewed focus on the hybrid representation of both explicit knowledge and parametric knowledge. In this position paper, we will discuss some of the common debate points within the community on LLMs (parametric knowledge) and Knowledge Graphs (explicit knowledge) and speculate on opportunities and visions that the renewed focus brings, as well as related research topics and challenges.
Simple and Powerful Architecture for Inductive Recommendation Using Knowledge Graph Convolutions
Sep 13, 2022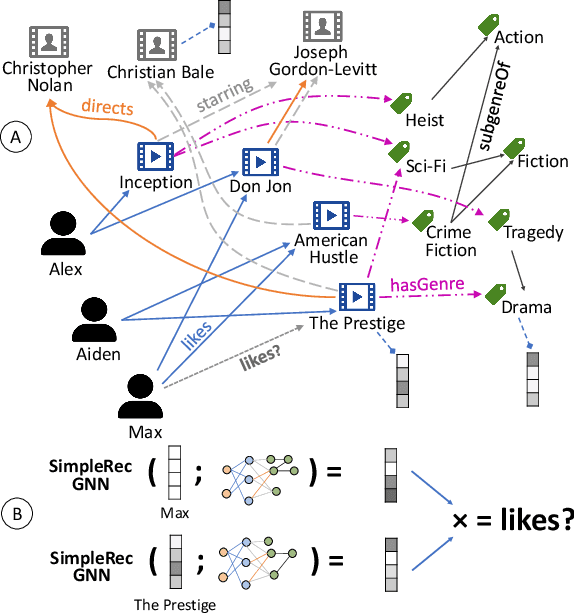
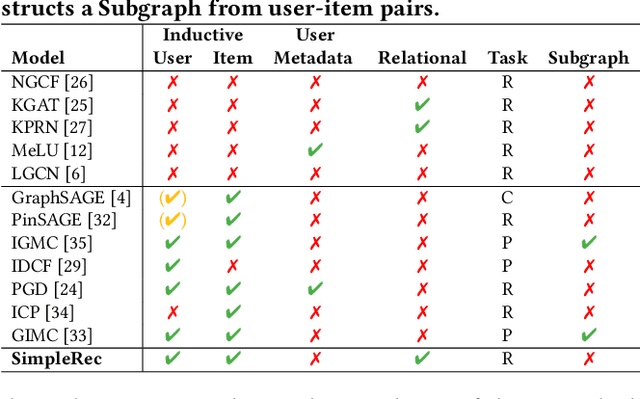
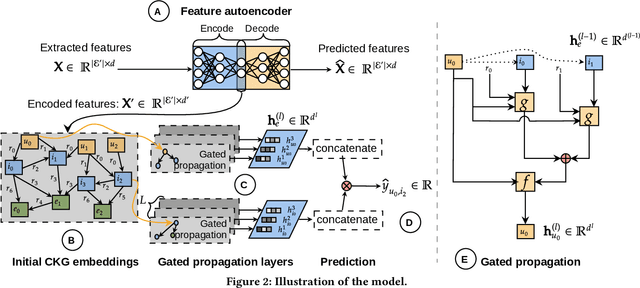
Using graph models with relational information in recommender systems has shown promising results. Yet, most methods are transductive, i.e., they are based on dimensionality reduction architectures. Hence, they require heavy retraining every time new items or users are added. Conversely, inductive methods promise to solve these issues. Nonetheless, all inductive methods rely only on interactions, making recommendations for users with few interactions sub-optimal and even impossible for new items. Therefore, we focus on inductive methods able to also exploit knowledge graphs (KGs). In this work, we propose SimpleRec, a strong baseline that uses a graph neural network and a KG to provide better recommendations than related inductive methods for new users and items. We show that it is unnecessary to create complex model architectures for user representations, but it is enough to allow users to be represented by the few ratings they provide and the indirect connections among them without any user metadata. As a result, we re-evaluate state-of-the-art methods, identify better evaluation protocols, highlight unwarranted conclusions from previous proposals, and showcase a novel, stronger baseline for this task.
MindReader: Recommendation over Knowledge Graph Entities with Explicit User Ratings
Jun 08, 2021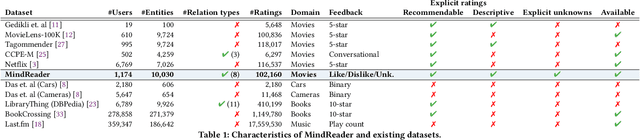
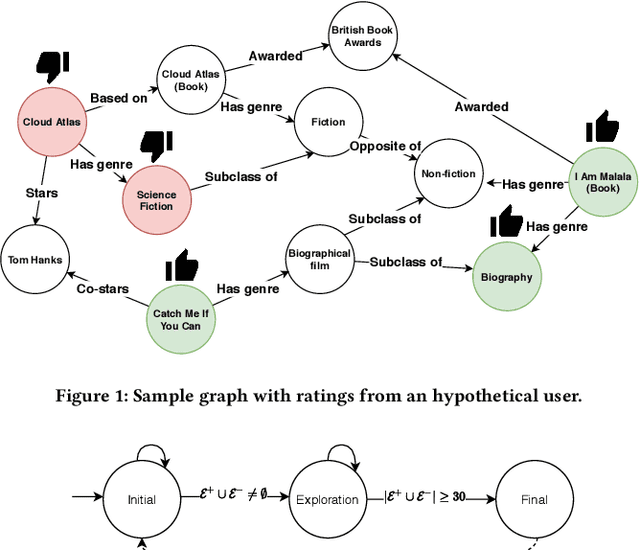
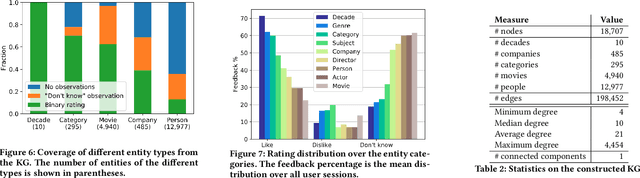
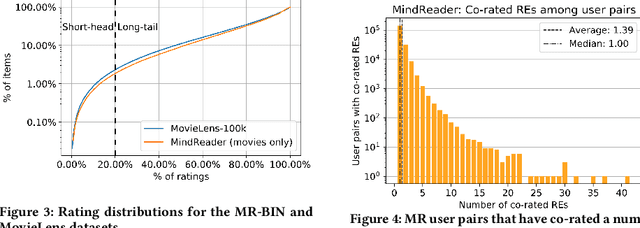
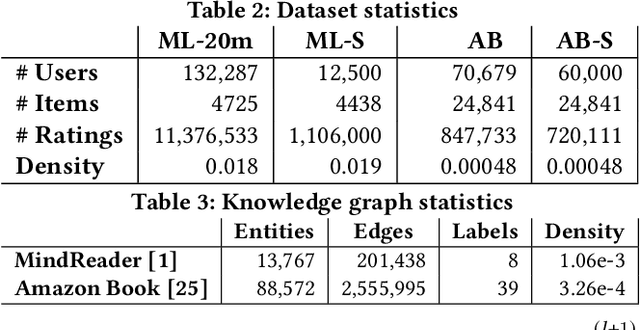
Knowledge Graphs (KGs) have been integrated in several models of recommendation to augment the informational value of an item by means of its related entities in the graph. Yet, existing datasets only provide explicit ratings on items and no information is provided about user opinions of other (non-recommendable) entities. To overcome this limitation, we introduce a new dataset, called the MindReader, providing explicit user ratings both for items and for KG entities. In this first version, the MindReader dataset provides more than 102 thousands explicit ratings collected from 1,174 real users on both items and entities from a KG in the movie domain. This dataset has been collected through an online interview application that we also release open source. As a demonstration of the importance of this new dataset, we present a comparative study of the effect of the inclusion of ratings on non-item KG entities in a variety of state-of-the-art recommendation models. In particular, we show that most models, whether designed specifically for graph data or not, see improvements in recommendation quality when trained on explicit non-item ratings. Moreover, for some models, we show that non-item ratings can effectively replace item ratings without loss of recommendation quality. This finding, thanks also to an observed greater familiarity of users towards common KG entities than towards long-tail items, motivates the use of KG entities for both warm and cold-start recommendations.