 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Gradient-enhanced multifidelity neural networks for high-dimensional function approximation
Mar 23, 2021
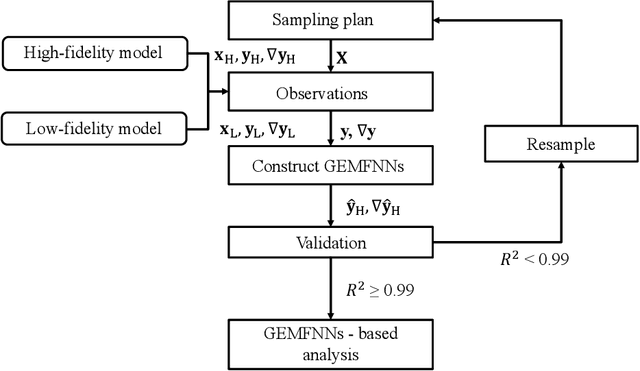
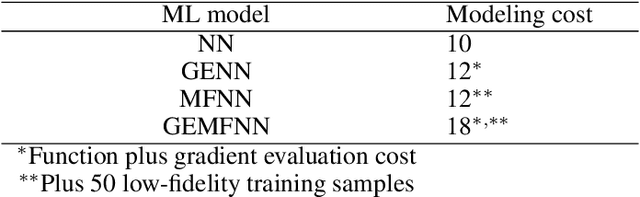
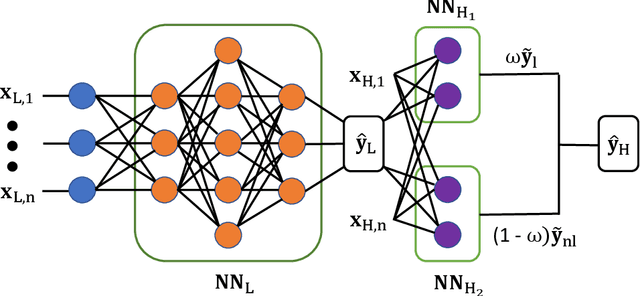

In this work, a novel multifidelity machine learning (ML) model, the gradient-enhanced multifidelity neural networks (GEMFNNs), is proposed. This model is a multifidelity version of gradient-enhanced neural networks (GENNs) as it uses both function and gradient information available at multiple levels of fidelity to make function approximations. Its construction is similar to multifidelity neural networks (MFNNs). This model is tested on three analytical function, a one, two, and a 20 variable function. It is also compared to neural networks (NNs), GENNs, and MFNNs, and the number of samples required to reach a global accuracy of 0.99 coefficient of determination (R^2) is measured. GEMFNNs required 18, 120, and 600 high-fidelity samples for the one, two, and 20 dimensional cases, respectively, to meet the target accuracy. NNs performed best on the one variable case, requiring only ten samples, while GENNs worked best on the two variable case, requiring 120 samples. GEMFNNs worked best for the 20 variable case, while requiring nearly eight times fewer samples than its nearest competitor, GENNs. For this case, NNs and MFNNs did not reach the target global accuracy even after using 10,000 high-fidelity samples. This work demonstrates the benefits of using gradient as well as multifidelity information in NNs for high-dimensional problems.
Space-time Mixing Attention for Video Transformer
Jun 10, 2021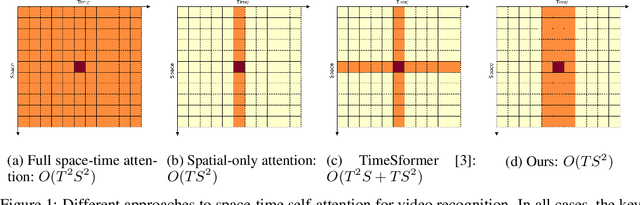
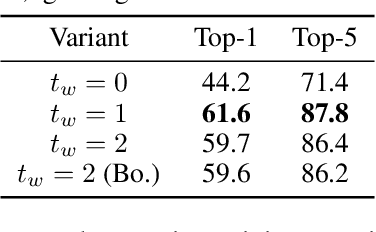
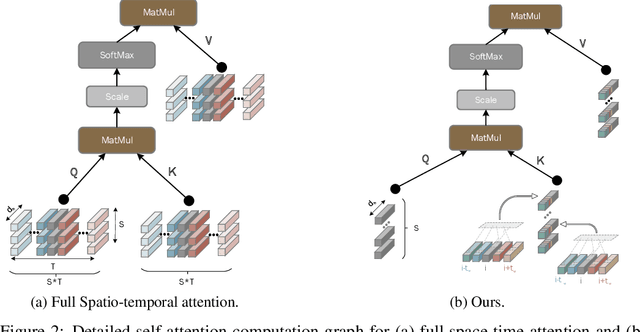
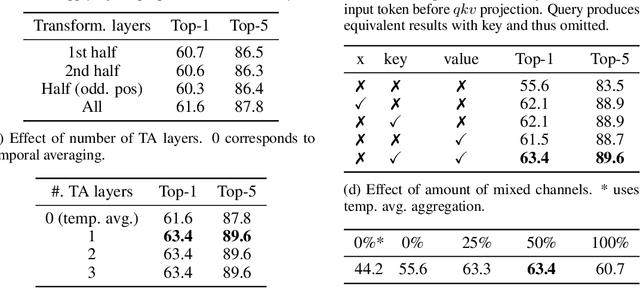
This paper is on video recognition using Transformers. Very recent attempts in this area have demonstrated promising results in terms of recognition accuracy, yet they have been also shown to induce, in many cases, significant computational overheads due to the additional modelling of the temporal information. In this work, we propose a Video Transformer model the complexity of which scales linearly with the number of frames in the video sequence and hence induces \textit{no overhead} compared to an image-based Transformer model. To achieve this, our model makes two approximations to the full space-time attention used in Video Transformers: (a) It restricts time attention to a local temporal window and capitalizes on the Transformer's depth to obtain full temporal coverage of the video sequence. (b) It uses efficient space-time mixing to attend \textit{jointly} spatial and temporal locations without inducing any additional cost on top of a spatial-only attention model. We also show how to integrate 2 very lightweight mechanisms for global temporal-only attention which provide additional accuracy improvements at minimal computational cost. We demonstrate that our model produces very high recognition accuracy on the most popular video recognition datasets while at the same time being significantly more efficient than other Video Transformer models. Code will be made available.
Embedded Deep Regularized Block HSIC Thermomics for Early Diagnosis of Breast Cancer
Jun 03, 2021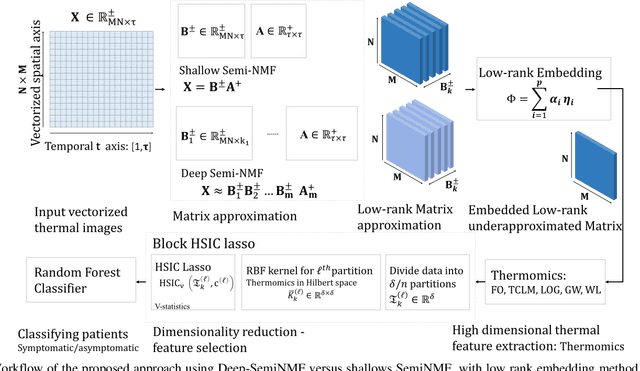


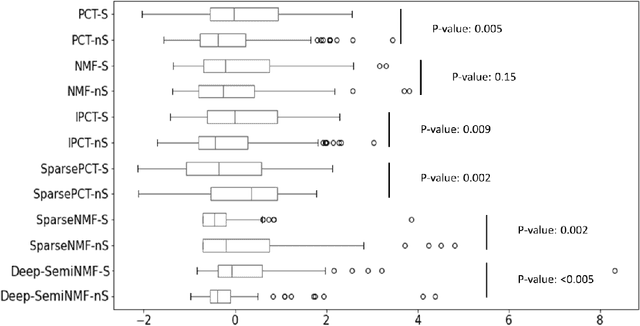
Thermography has been used extensively as a complementary diagnostic tool in breast cancer detection. Among thermographic methods matrix factorization (MF) techniques show an unequivocal capability to detect thermal patterns corresponding to vasodilation in cancer cases. One of the biggest challenges in such techniques is selecting the best representation of the thermal basis. In this study, an embedding method is proposed to address this problem and Deep-semi-nonnegative matrix factorization (Deep-SemiNMF) for thermography is introduced, then tested for 208 breast cancer screening cases. First, we apply Deep-SemiNMF to infrared images to extract low-rank thermal representations for each case. Then, we embed low-rank bases to obtain one basis for each patient. After that, we extract 300 thermal imaging features, called thermomics, to decode imaging information for the automatic diagnostic model. We reduced the dimensionality of thermomics by spanning them onto Hilbert space using RBF kernel and select the three most efficient features using the block Hilbert Schmidt Independence Criterion Lasso (block HSIC Lasso). The preserved thermal heterogeneity successfully classified asymptomatic versus symptomatic patients applying a random forest model (cross-validated accuracy of 71.36% (69.42%-73.3%)).
* Authors version. arXiv admin note: text overlap with arXiv:2010.06784
Feature Reuse and Fusion for Real-time Semantic segmentation
May 27, 2021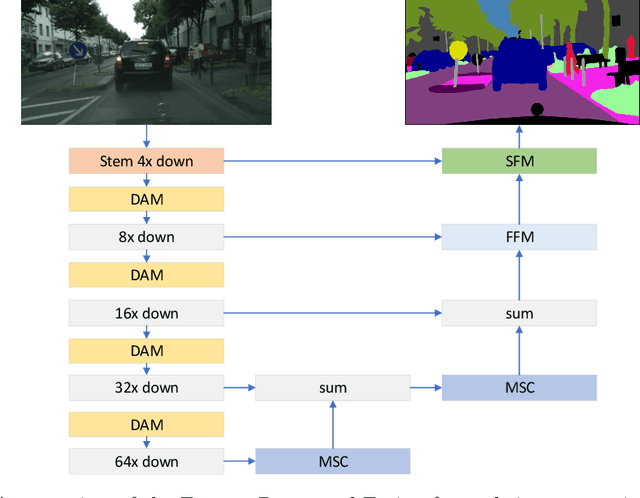
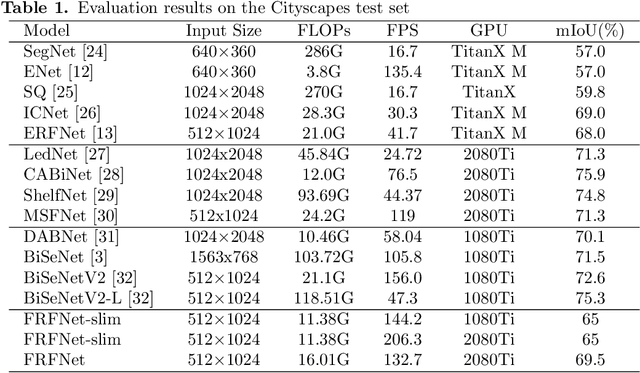
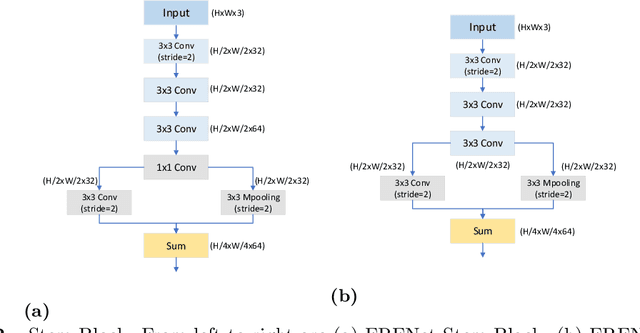

For real-time semantic segmentation, how to increase the speed while maintaining high resolution is a problem that has been discussed and solved. Backbone design and fusion design have always been two essential parts of real-time semantic segmentation. We hope to design a light-weight network based on previous design experience and reach the level of state-of-the-art real-time semantic segmentation without any pre-training. To achieve this goal, a encoder-decoder architectures are proposed to solve this problem by applying a decoder network onto a backbone model designed for real-time segmentation tasks and designed three different ways to fuse semantics and detailed information in the aggregation phase. We have conducted extensive experiments on two semantic segmentation benchmarks. Experiments on the Cityscapes and CamVid datasets show that the proposed FRFNet strikes a balance between speed calculation and accuracy. It achieves 76.4\% Mean Intersection over Union (mIoU\%) on the Cityscapes test dataset with the speed of 161 FPS on a single RTX 2080Ti card. The Code is available at https://github.com/favoMJ/FRFNet.
Mitigating False-Negative Contexts in Multi-document QuestionAnswering with Retrieval Marginalization
Mar 22, 2021


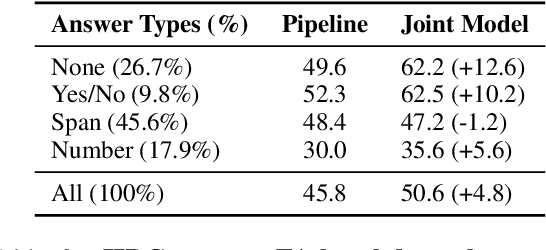
Question Answering (QA) tasks requiring information from multiple documents often rely on a retrieval model to identify relevant information from which the reasoning model can derive an answer. The retrieval model is typically trained to maximize the likelihood of the labeled supporting evidence. However, when retrieving from large text corpora such as Wikipedia, the correct answer can often be obtained from multiple evidence candidates, not all of them labeled as positive, thus rendering the training signal weak and noisy. The problem is exacerbated when the questions are unanswerable or the answers are boolean, since the models cannot rely on lexical overlap to map answers to supporting evidences. We develop a new parameterization of set-valued retrieval that properly handles unanswerable queries, and we show that marginalizing over this set during training allows a model to mitigate false negatives in annotated supporting evidences. We test our method with two multi-document QA datasets, IIRC and HotpotQA. On IIRC, we show that joint modeling with marginalization on alternative contexts improves model performance by 5.5 F1 points and achieves a new state-of-the-art performance of 50.6 F1. We also show that marginalization results in 0.9 to 1.6 QA F1 improvement on HotpotQA in various settings.
Acoustic Scene Classification Using Multichannel Observation with Partially Missing Channels
May 05, 2021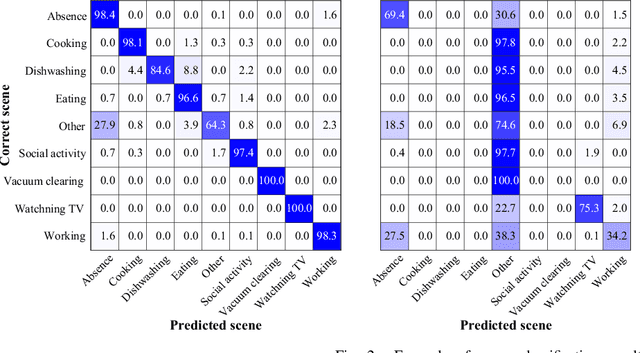
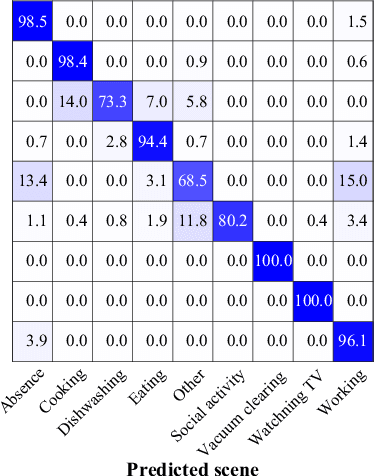
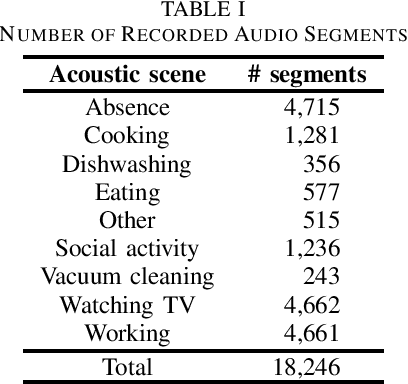

Sounds recorded with smartphones or IoT devices often have partially unreliable observations caused by clipping, wind noise, and completely missing parts due to microphone failure and packet loss in data transmission over the network. In this paper, we investigate the impact of the partially missing channels on the performance of acoustic scene classification using multichannel audio recordings, especially for a distributed microphone array. Missing observations cause not only losses of time-frequency and spatial information on sound sources but also a mismatch between a trained model and evaluation data. We thus investigate how a missing channel affects the performance of acoustic scene classification in detail. We also propose simple data augmentation methods for scene classification using multichannel observations with partially missing channels and evaluate the scene classification performance using the data augmentation methods.
The Earth Mover's Pinball Loss: Quantiles for Histogram-Valued Regression
Jun 03, 2021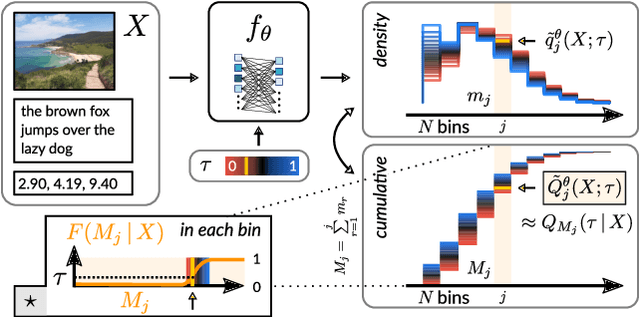
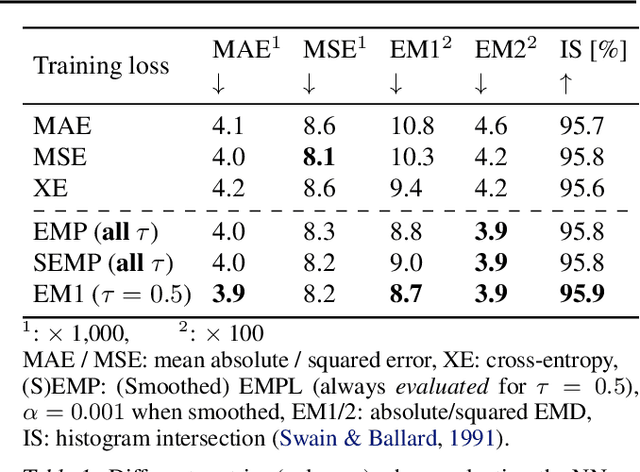
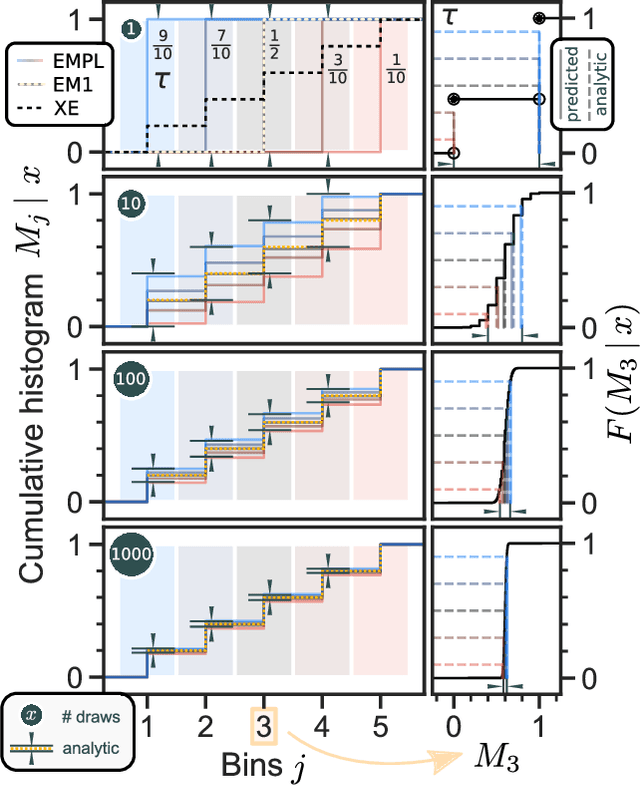
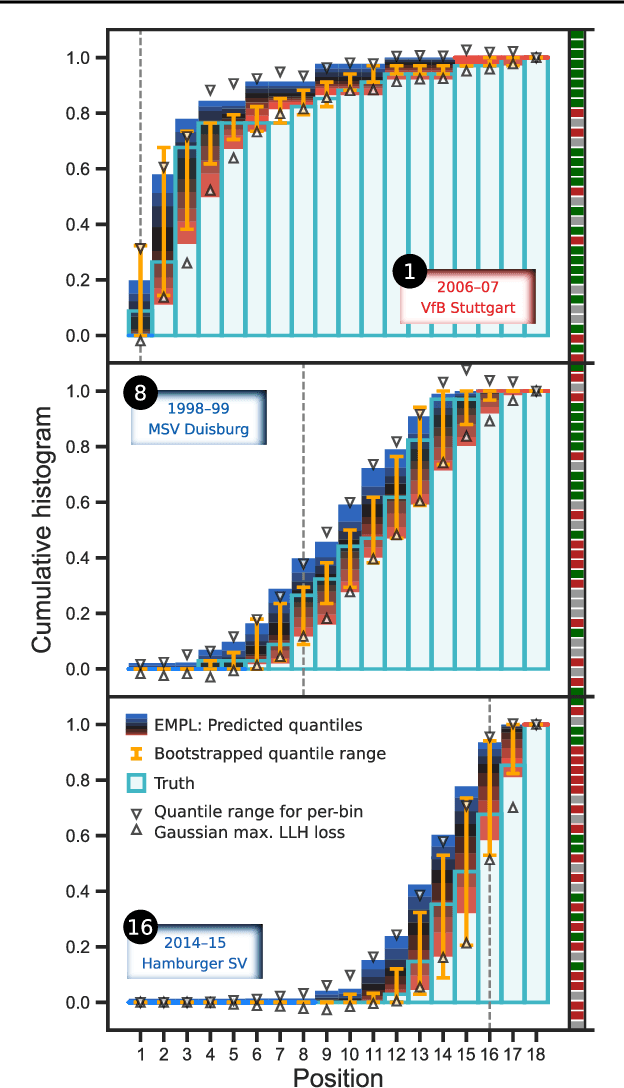
Although ubiquitous in the sciences, histogram data have not received much attention by the Deep Learning community. Whilst regression and classification tasks for scalar and vector data are routinely solved by neural networks, a principled approach for estimating histogram labels as a function of an input vector or image is lacking in the literature. We present a dedicated method for Deep Learning-based histogram regression, which incorporates cross-bin information and yields distributions over possible histograms, expressed by $\tau$-quantiles of the cumulative histogram in each bin. The crux of our approach is a new loss function obtained by applying the pinball loss to the cumulative histogram, which for 1D histograms reduces to the Earth Mover's distance (EMD) in the special case of the median ($\tau = 0.5$), and generalizes it to arbitrary quantiles. We validate our method with an illustrative toy example, a football-related task, and an astrophysical computer vision problem. We show that with our loss function, the accuracy of the predicted median histograms is very similar to the standard EMD case (and higher than for per-bin loss functions such as cross-entropy), while the predictions become much more informative at almost no additional computational cost.
A concise method for feature selection via normalized frequencies
Jun 10, 2021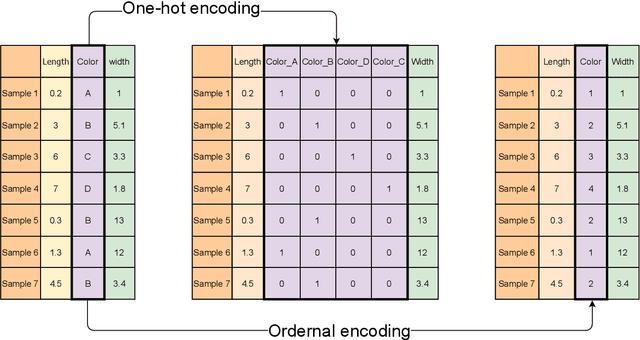

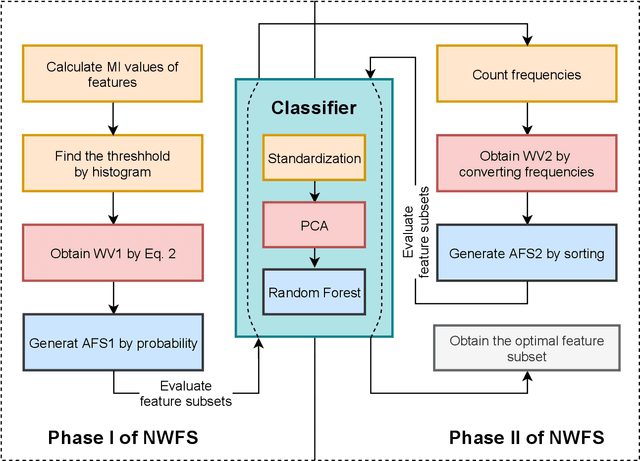

Feature selection is an important part of building a machine learning model. By eliminating redundant or misleading features from data, the machine learning model can achieve better performance while reducing the demand on com-puting resources. Metaheuristic algorithms are mostly used to implement feature selection such as swarm intelligence algorithms and evolutionary algorithms. However, they suffer from the disadvantage of relative complexity and slowness. In this paper, a concise method is proposed for universal feature selection. The proposed method uses a fusion of the filter method and the wrapper method, rather than a combination of them. In the method, one-hoting encoding is used to preprocess the dataset, and random forest is utilized as the classifier. The proposed method uses normalized frequencies to assign a value to each feature, which will be used to find the optimal feature subset. Furthermore, we propose a novel approach to exploit the outputs of mutual information, which allows for a better starting point for the experiments. Two real-world dataset in the field of intrusion detection were used to evaluate the proposed method. The evaluation results show that the proposed method outperformed several state-of-the-art related works in terms of accuracy, precision, recall, F-score and AUC.
Enabling Full Mutualism for Symbiotic Radio with Massive Backscatter Devices
Jun 10, 2021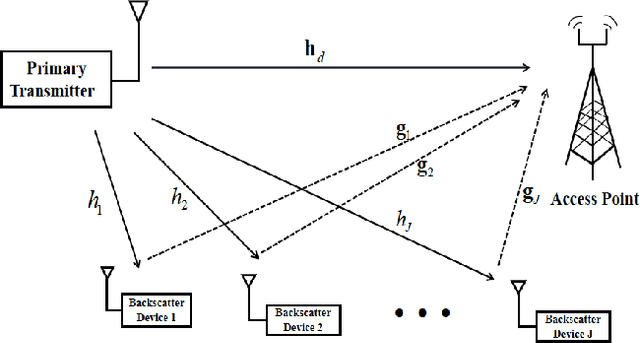
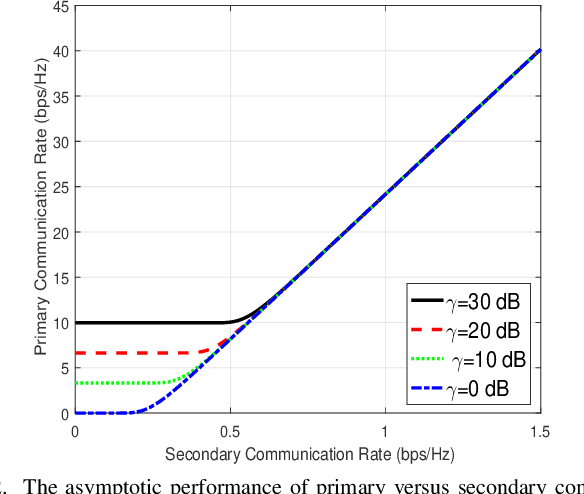
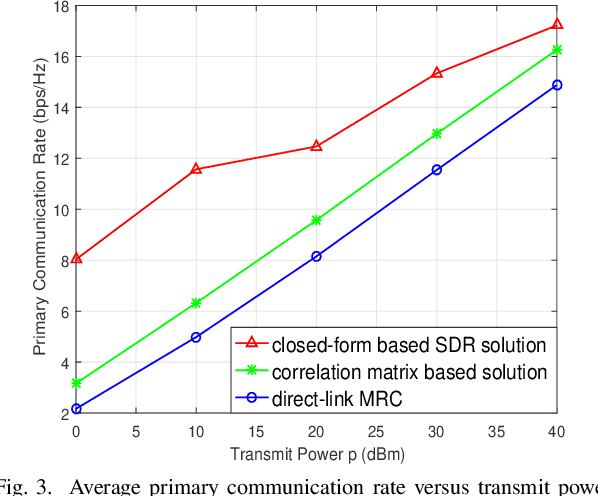
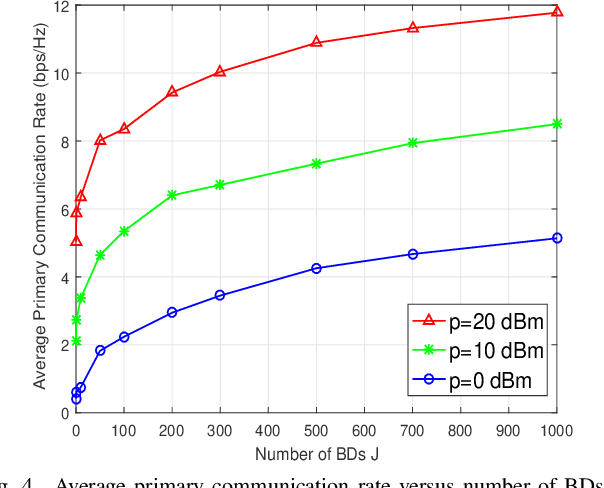
Symbiotic radio is a promising technology to achieve spectrum- and energy-efficient wireless communications, where the secondary backscatter device (BD) leverages not only the spectrum but also the power of the primary signals for its own information transmission. In return, the primary communication link can be enhanced by the additional multipaths created by the BD. This is known as the mutualism relationship of symbiotic radio. However, as the backscattering link is much weaker than the direct link due to double attenuations, the improvement of the primary link brought by one single BD is extremely limited. To address this issue and enable full mutualism of symbiotic radio, in this paper, we study symbiotic radio with massive number of BDs. For symbiotic radio multiple access channel (MAC) with successive interference cancellation (SIC), we first derive the achievable rate of both the primary and secondary communications, based on which a receive beamforming optimization problem is formulated and solved. Furthermore, considering the asymptotic regime of massive number of BDs, closed-form expressions are derived for the primary and the secondary communication rates, both of which are shown to be increasing functions of the number of BDs. This thus demonstrates that the mutualism relationship of symbiotic radio can be fully exploited with massive BD access.
Fusion-DHL: WiFi, IMU, and Floorplan Fusion for Dense History of Locations in Indoor Environments
May 18, 2021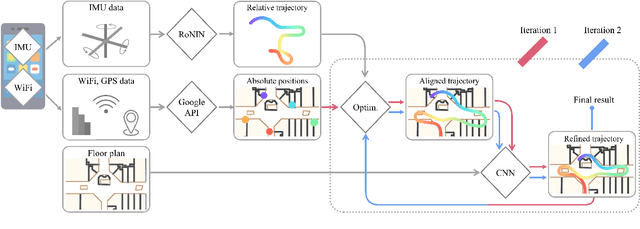
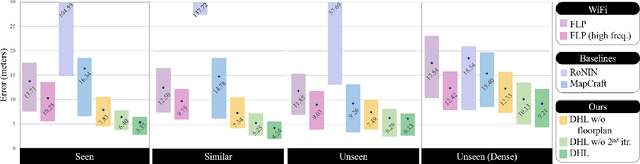
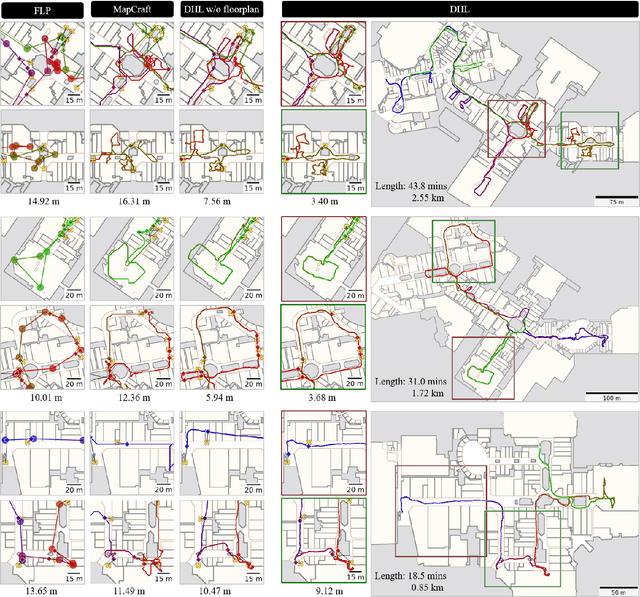
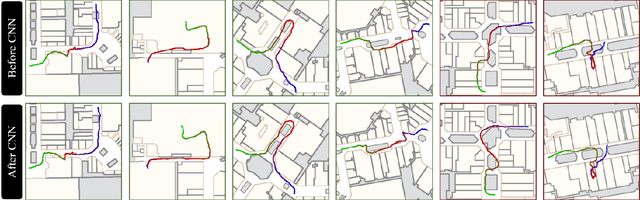
The paper proposes a multi-modal sensor fusion algorithm that fuses WiFi, IMU, and floorplan information to infer an accurate and dense location history in indoor environments. The algorithm uses 1) an inertial navigation algorithm to estimate a relative motion trajectory from IMU sensor data; 2) a WiFi-based localization API in industry to obtain positional constraints and geo-localize the trajectory; and 3) a convolutional neural network to refine the location history to be consistent with the floorplan. We have developed a data acquisition app to build a new dataset with WiFi, IMU, and floorplan data with ground-truth positions at 4 university buildings and 3 shopping malls. Our qualitative and quantitative evaluations demonstrate that the proposed system is able to produce twice as accurate and a few orders of magnitude denser location history than the current standard, while requiring minimal additional energy consumption. We will publicly share our code, data and models.
* To be published in ICRA 2021. Code and data: https://github.com/Sachini/Fusion-DHL