 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Secure Dual-Functional Radar-Communication System via Exploiting Known Interference in the Presence of Clutter
Jun 08, 2021
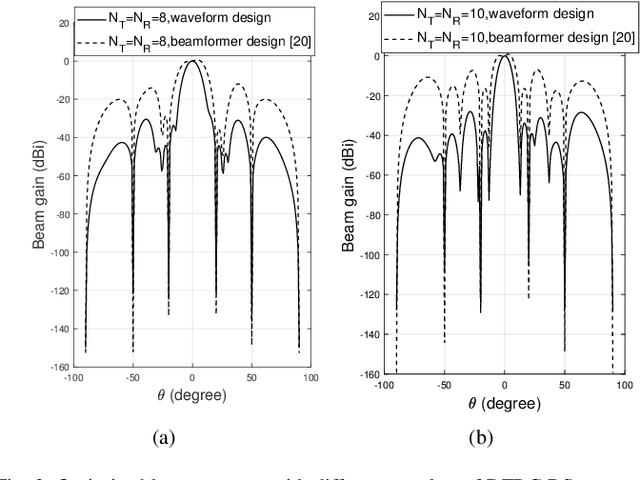
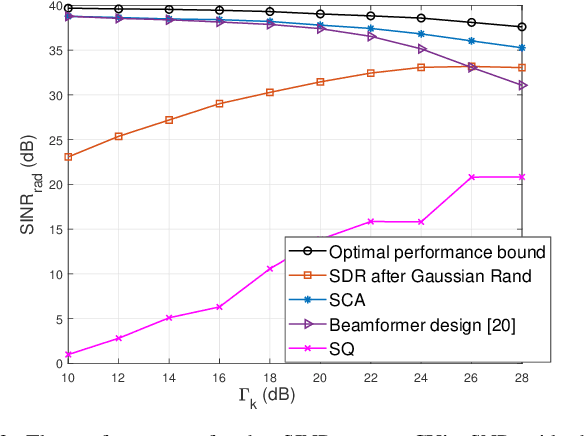
This paper addresses the problem that designing the transmit waveform and receive beamformer aims to maximize the receive radar SINR for secure dual-functional radar-communication (DFRC) systems, where the undesired multi-user interference (MUI) is transformed to useful power. In this system, the DFRC base station (BS) serves communication users (CUs) and detects the target simultaneously, where the radar target is regarded to be malicious since it might eavesdrop the transmitted information from BS to CUs. Inspired by the constructive interference (CI) approach, the phases of received signals at CUs are rotated into the relaxed decision region, and the undesired MUI is designed to contribute in useful power. Then, the convex approximation method (SCA) is adopted to tackle the optimization problem. Finally, numerical results are given to validate the effectiveness of the proposed method, which shows that it is viable to ensure the communication data secure adopting the techniques that we propose.
Iterative DNA Coding Scheme With GC Balance and Run-Length Constraints Using a Greedy Algorithm
Mar 30, 2021
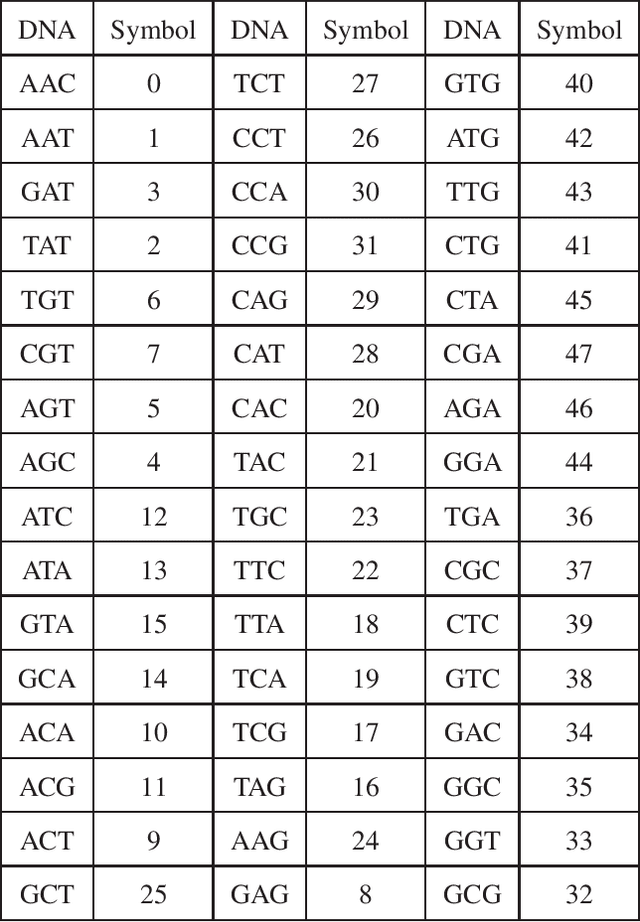
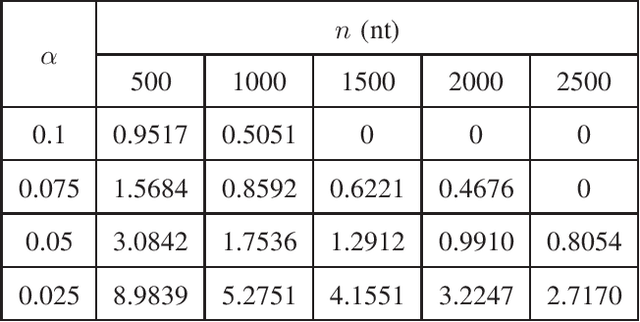
In this paper, we propose a novel iterative encoding algorithm for DNA storage to satisfy both the GC balance and run-length constraints using a greedy algorithm. DNA strands with run-length more than three and the GC balance ratio far from 50\% are known to be prone to errors. The proposed encoding algorithm stores data at high information density with high flexibility of run-length at most $m$ and GC balance between $0.5\pm\alpha$ for arbitrary $m$ and $\alpha$. More importantly, we propose a novel mapping method to reduce the average bit error compared to the randomly generated mapping method, using a greedy algorithm. The proposed algorithm is implemented through iterative encoding, consisting of three main steps: randomization, M-ary mapping, and verification. It has an information density of 1.8616 bits/nt in the case of $m=3$, which approaches the theoretical upper bound of 1.98 bits/nt, while satisfying two constraints. Also, the average bit error caused by the one nt error is 2.3455 bits, which is reduced by $20.5\%$, compared to the randomized mapping.
Knowledge-Base Enriched Word Embeddings for Biomedical Domain
Feb 20, 2021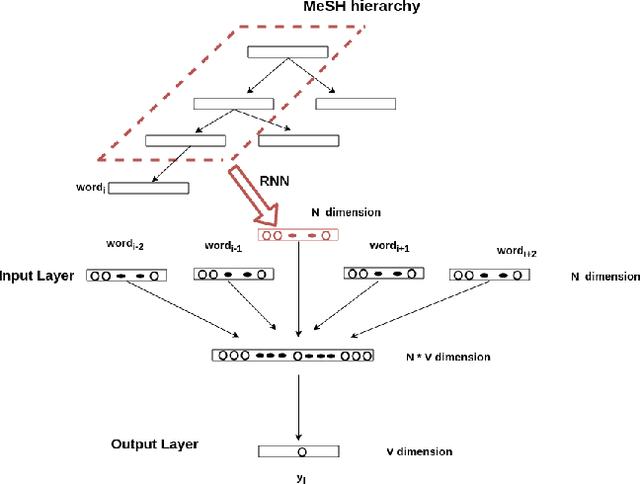


Word embeddings have been shown adept at capturing the semantic and syntactic regularities of the natural language text, as a result of which these representations have found their utility in a wide variety of downstream content analysis tasks. Commonly, these word embedding techniques derive the distributed representation of words based on the local context information. However, such approaches ignore the rich amount of explicit information present in knowledge-bases. This is problematic, as it might lead to poor representation for words with insufficient local context such as domain specific words. Furthermore, the problem becomes pronounced in domain such as bio-medicine where the presence of these domain specific words are relatively high. Towards this end, in this project, we propose a new word embedding based model for biomedical domain that jointly leverages the information from available corpora and domain knowledge in order to generate knowledge-base powered embeddings. Unlike existing approaches, the proposed methodology is simple but adept at capturing the precise knowledge available in domain resources in an accurate way. Experimental results on biomedical concept similarity and relatedness task validates the effectiveness of the proposed approach.
Finding Significant Features for Few-Shot Learning using Dimensionality Reduction
Jul 06, 2021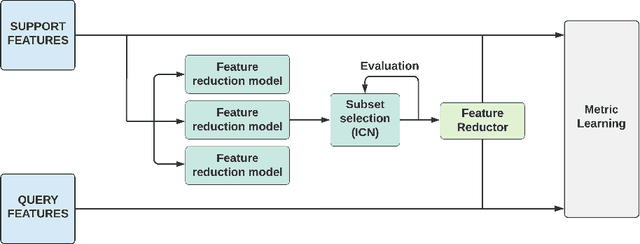
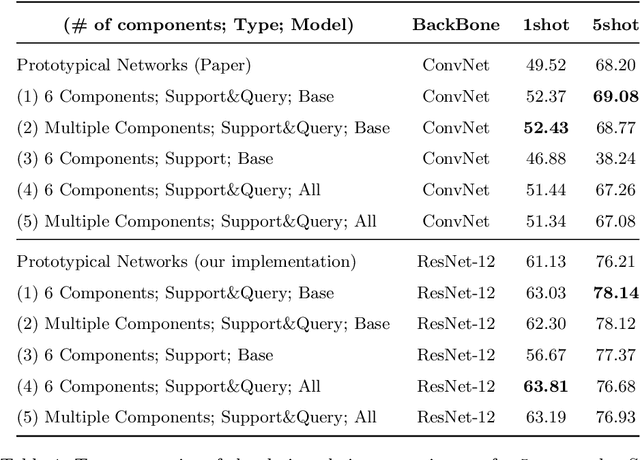
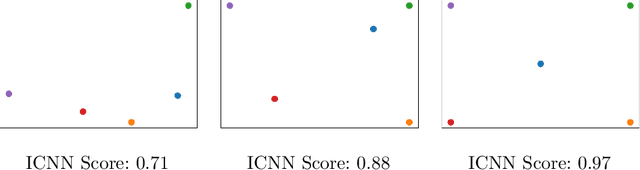
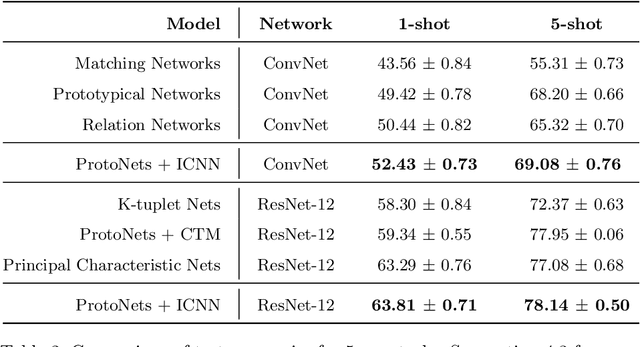
Few-shot learning is a relatively new technique that specializes in problems where we have little amounts of data. The goal of these methods is to classify categories that have not been seen before with just a handful of samples. Recent approaches, such as metric learning, adopt the meta-learning strategy in which we have episodic tasks conformed by support (training) data and query (test) data. Metric learning methods have demonstrated that simple models can achieve good performance by learning a similarity function to compare the support and the query data. However, the feature space learned by a given metric learning approach may not exploit the information given by a specific few-shot task. In this work, we explore the use of dimension reduction techniques as a way to find task-significant features helping to make better predictions. We measure the performance of the reduced features by assigning a score based on the intra-class and inter-class distance, and selecting a feature reduction method in which instances of different classes are far away and instances of the same class are close. This module helps to improve the accuracy performance by allowing the similarity function, given by the metric learning method, to have more discriminative features for the classification. Our method outperforms the metric learning baselines in the miniImageNet dataset by around 2% in accuracy performance.
Phase retrieval with physics informed zero-shot learning
Jun 08, 2021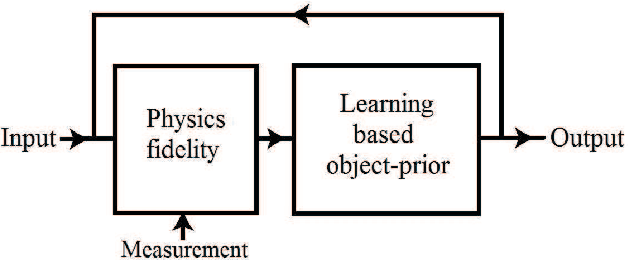
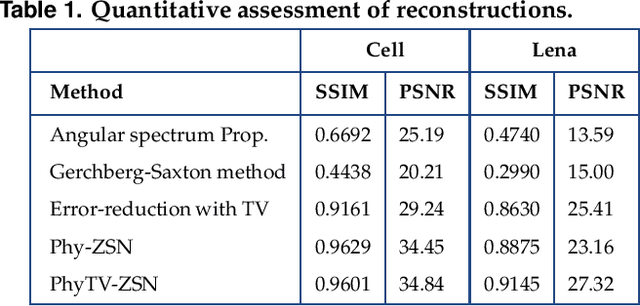
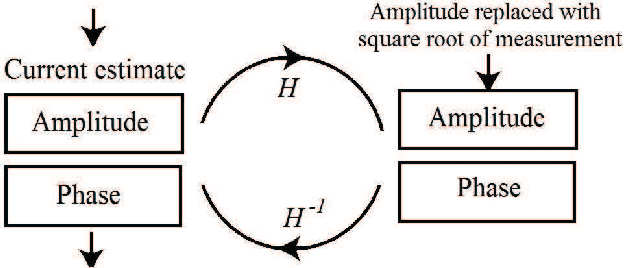
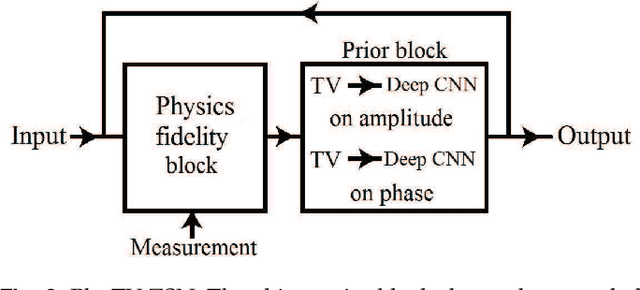
Phase can be reliably estimated from a single diffracted intensity image, if a faithful prior information about the object is available. Examples include amplitude bounds, object support, sparsity in the spatial or a transform domain, deep image prior and the prior learnt from the labelled datasets by a deep neural network. Deep learning facilitates state of art reconstruction quality but requires a large labelled dataset (ground truth-measurement pair acquired in the same experimental conditions) for training. To alleviate this data requirement problem, this letter proposes a zero-shot learning method. The letter demonstrates that the object-prior learnt by a deep neural network while being trained for a denoising task can also be utilized for the phase retrieval, if the diffraction physics is effectively enforced on the network output. The letter additionally demonstrates that the incorporation of total variation in the proposed zero-shot framework facilitates the reconstruction of similar quality in lesser time (e.g. ~8.5 fold, for a test reported in this letter).
Exploiting Spiking Dynamics with Spatial-temporal Feature Normalization in Graph Learning
Jun 30, 2021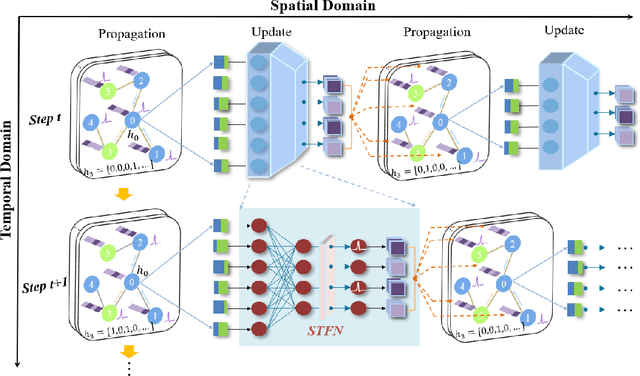
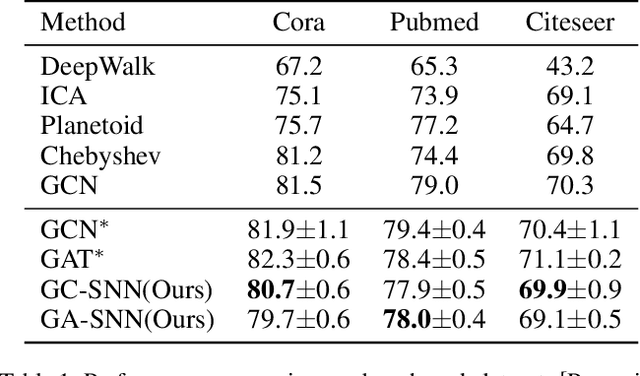
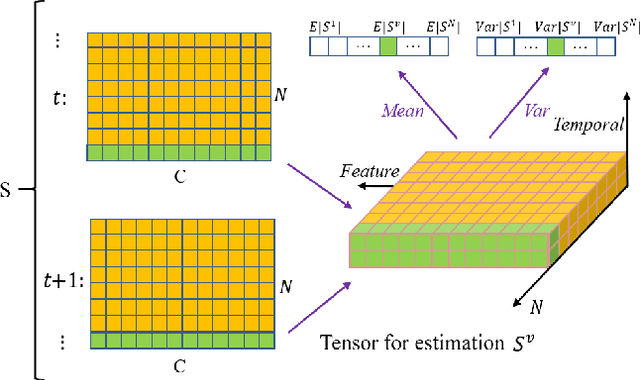
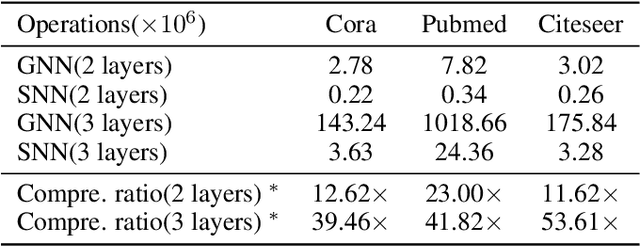
Biological spiking neurons with intrinsic dynamics underlie the powerful representation and learning capabilities of the brain for processing multimodal information in complex environments. Despite recent tremendous progress in spiking neural networks (SNNs) for handling Euclidean-space tasks, it still remains challenging to exploit SNNs in processing non-Euclidean-space data represented by graph data, mainly due to the lack of effective modeling framework and useful training techniques. Here we present a general spike-based modeling framework that enables the direct training of SNNs for graph learning. Through spatial-temporal unfolding for spiking data flows of node features, we incorporate graph convolution filters into spiking dynamics and formalize a synergistic learning paradigm. Considering the unique features of spike representation and spiking dynamics, we propose a spatial-temporal feature normalization (STFN) technique suitable for SNN to accelerate convergence. We instantiate our methods into two spiking graph models, including graph convolution SNNs and graph attention SNNs, and validate their performance on three node-classification benchmarks, including Cora, Citeseer, and Pubmed. Our model can achieve comparable performance with the state-of-the-art graph neural network (GNN) models with much lower computation costs, demonstrating great benefits for the execution on neuromorphic hardware and prompting neuromorphic applications in graphical scenarios.
The Stereotyping Problem in Collaboratively Filtered Recommender Systems
Jun 23, 2021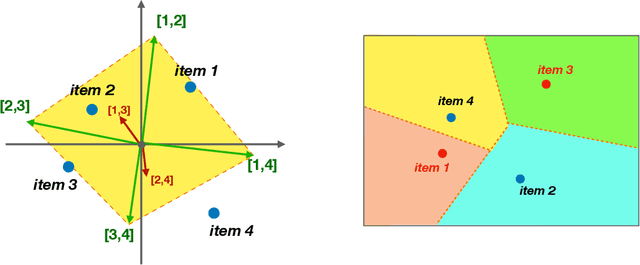
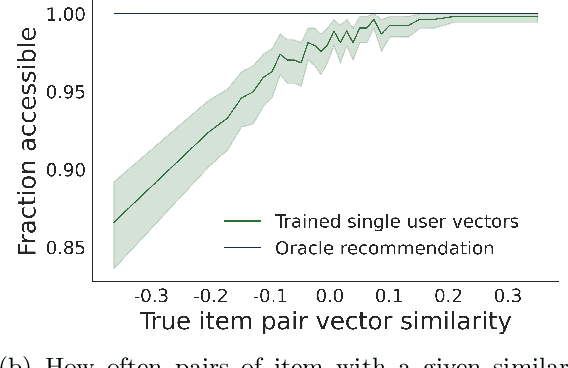
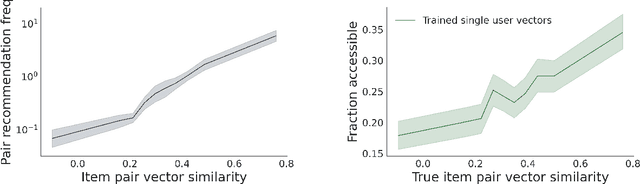
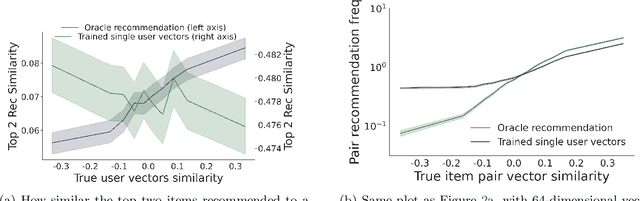
Recommender systems -- and especially matrix factorization-based collaborative filtering algorithms -- play a crucial role in mediating our access to online information. We show that such algorithms induce a particular kind of stereotyping: if preferences for a \textit{set} of items are anti-correlated in the general user population, then those items may not be recommended together to a user, regardless of that user's preferences and ratings history. First, we introduce a notion of \textit{joint accessibility}, which measures the extent to which a set of items can jointly be accessed by users. We then study joint accessibility under the standard factorization-based collaborative filtering framework, and provide theoretical necessary and sufficient conditions when joint accessibility is violated. Moreover, we show that these conditions can easily be violated when the users are represented by a single feature vector. To improve joint accessibility, we further propose an alternative modelling fix, which is designed to capture the diverse multiple interests of each user using a multi-vector representation. We conduct extensive experiments on real and simulated datasets, demonstrating the stereotyping problem with standard single-vector matrix factorization models.
Improving the Authentication with Built-in Camera ProtocolUsing Built-in Motion Sensors: A Deep Learning Solution
Jul 22, 2021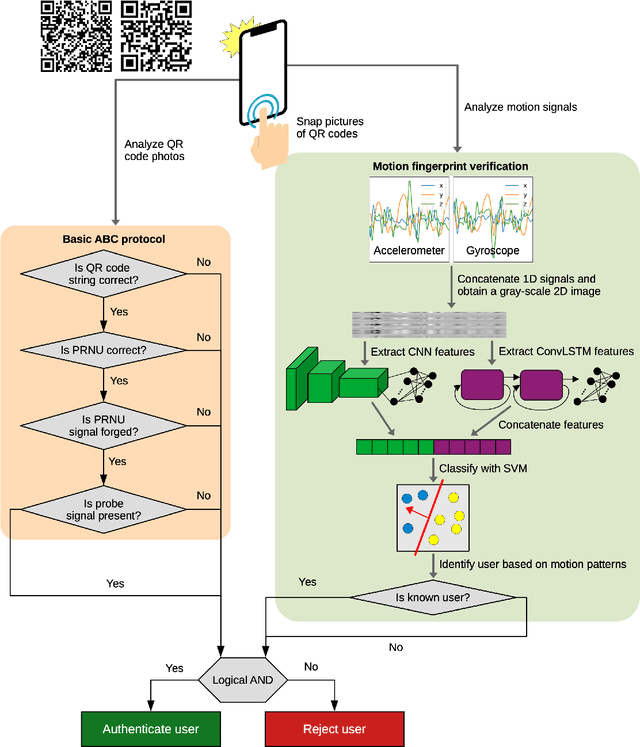
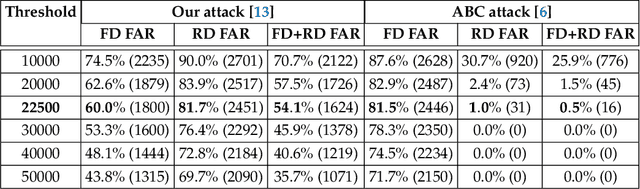
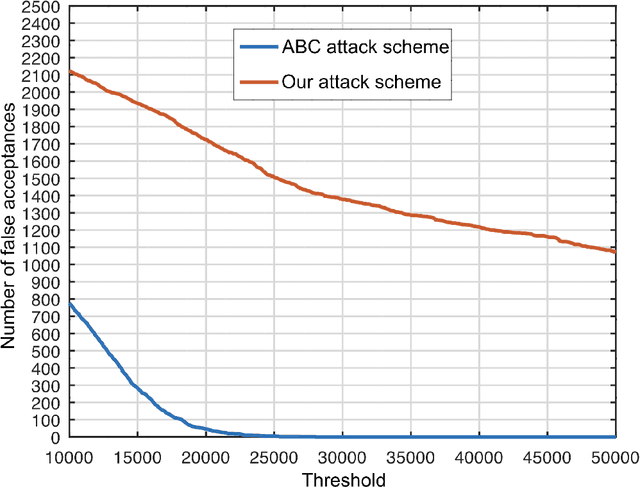
We propose an enhanced version of the Authentication with Built-in Camera (ABC) protocol by employing a deep learning solution based on built-in motion sensors. The standard ABC protocol identifies mobile devices based on the photo-response non-uniformity (PRNU) of the camera sensor, while also considering QR-code-based meta-information. During authentication, the user is required to take two photos that contain two QR codes presented on a screen. The presented QR code images also contain a unique probe signal, similar to a camera fingerprint, generated by the protocol. During verification, the server computes the fingerprint of the received photos and authenticates the user if (i) the probe signal is present, (ii) the metadata embedded in the QR codes is correct and (iii) the camera fingerprint is identified correctly. However, the protocol is vulnerable to forgery attacks when the attacker can compute the camera fingerprint from external photos, as shown in our preliminary work. In this context, we propose an enhancement for the ABC protocol based on motion sensor data, as an additional and passive authentication layer. Smartphones can be identified through their motion sensor data, which, unlike photos, is never posted by users on social media platforms, thus being more secure than using photographs alone. To this end, we transform motion signals into embedding vectors produced by deep neural networks, applying Support Vector Machines for the smartphone identification task. Our change to the ABC protocol results in a multi-modal protocol that lowers the false acceptance rate for the attack proposed in our previous work to a percentage as low as 0.07%.
A deep-learning--based multimodal depth-aware dynamic hand gesture recognition system
Jul 06, 2021
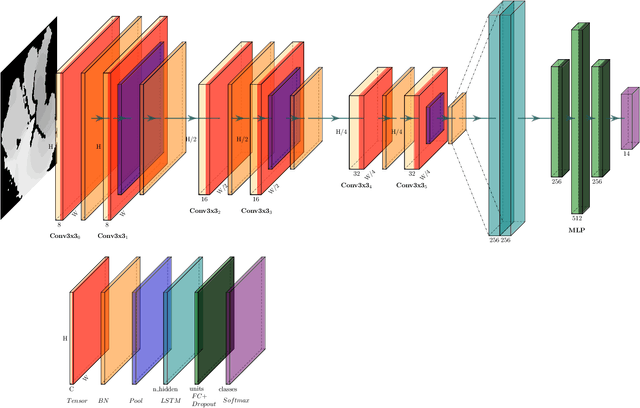

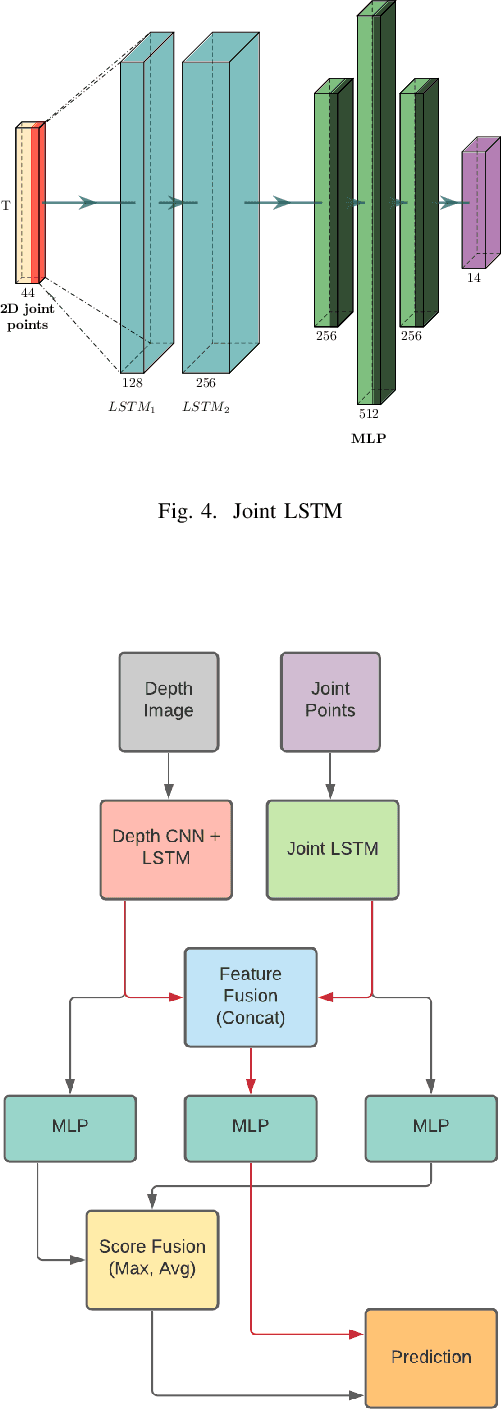
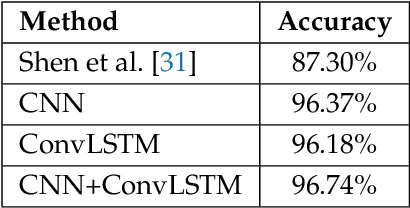
Any spatio-temporal movement or reorientation of the hand, done with the intention of conveying a specific meaning, can be considered as a hand gesture. Inputs to hand gesture recognition systems can be in several forms, such as depth images, monocular RGB, or skeleton joint points. We observe that raw depth images possess low contrasts in the hand regions of interest (ROI). They do not highlight important details to learn, such as finger bending information (whether a finger is overlapping the palm, or another finger). Recently, in deep-learning--based dynamic hand gesture recognition, researchers are tying to fuse different input modalities (e.g. RGB or depth images and hand skeleton joint points) to improve the recognition accuracy. In this paper, we focus on dynamic hand gesture (DHG) recognition using depth quantized image features and hand skeleton joint points. In particular, we explore the effect of using depth-quantized features in Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) based multi-modal fusion networks. We find that our method improves existing results on the SHREC-DHG-14 dataset. Furthermore, using our method, we show that it is possible to reduce the resolution of the input images by more than four times and still obtain comparable or better accuracy to that of the resolutions used in previous methods.
Analyzing vehicle pedestrian interactions combining data cube structure and predictive collision risk estimation model
Jul 26, 2021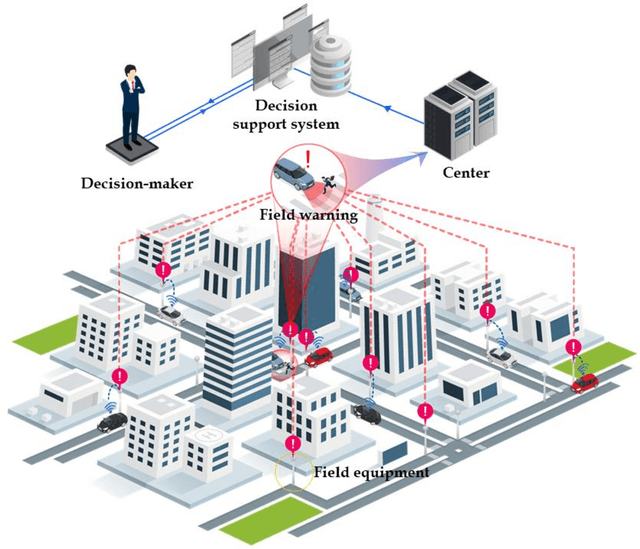
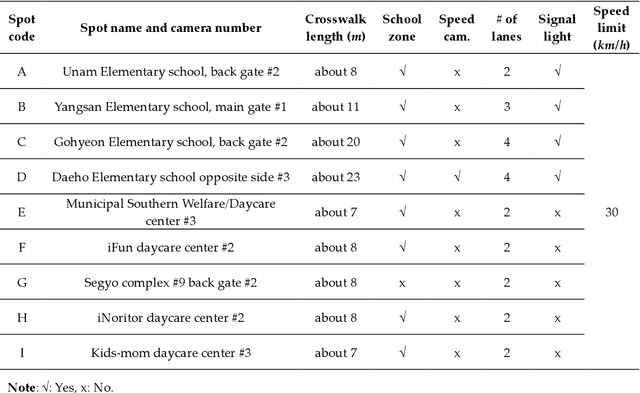
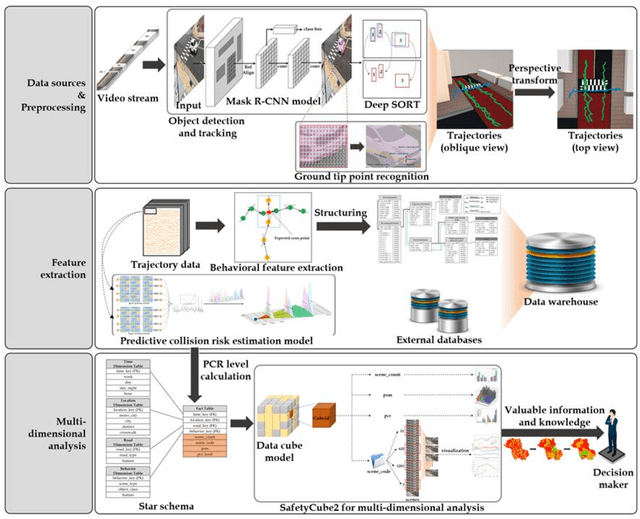
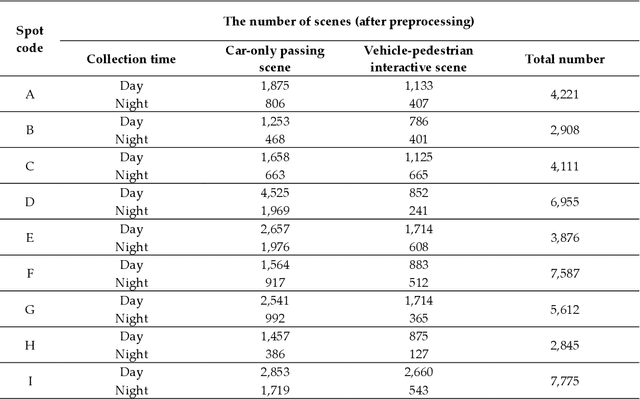
Traffic accidents are a threat to human lives, particularly pedestrians causing premature deaths. Therefore, it is necessary to devise systems to prevent accidents in advance and respond proactively, using potential risky situations as one of the surrogate safety measurements. This study introduces a new concept of a pedestrian safety system that combines the field and the centralized processes. The system can warn of upcoming risks immediately in the field and improve the safety of risk frequent areas by assessing the safety levels of roads without actual collisions. In particular, this study focuses on the latter by introducing a new analytical framework for a crosswalk safety assessment with behaviors of vehicle/pedestrian and environmental features. We obtain these behavioral features from actual traffic video footage in the city with complete automatic processing. The proposed framework mainly analyzes these behaviors in multidimensional perspectives by constructing a data cube structure, which combines the LSTM based predictive collision risk estimation model and the on line analytical processing operations. From the PCR estimation model, we categorize the severity of risks as four levels and apply the proposed framework to assess the crosswalk safety with behavioral features. Our analytic experiments are based on two scenarios, and the various descriptive results are harvested the movement patterns of vehicles and pedestrians by road environment and the relationships between risk levels and car speeds. Thus, the proposed framework can support decision makers by providing valuable information to improve pedestrian safety for future accidents, and it can help us better understand their behaviors near crosswalks proactively. In order to confirm the feasibility and applicability of the proposed framework, we implement and apply it to actual operating CCTVs in Osan City, Korea.