 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Asking It All: Generating Contextualized Questions for any Semantic Role
Sep 10, 2021


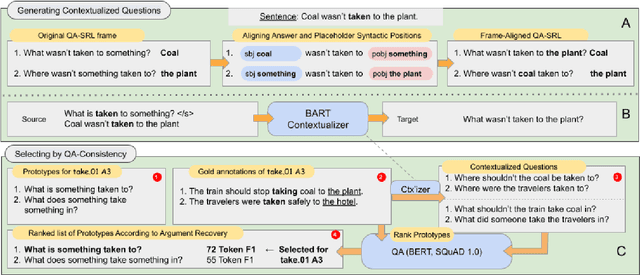
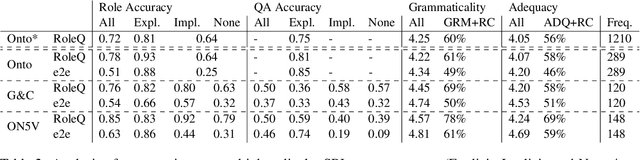
Asking questions about a situation is an inherent step towards understanding it. To this end, we introduce the task of role question generation, which, given a predicate mention and a passage, requires producing a set of questions asking about all possible semantic roles of the predicate. We develop a two-stage model for this task, which first produces a context-independent question prototype for each role and then revises it to be contextually appropriate for the passage. Unlike most existing approaches to question generation, our approach does not require conditioning on existing answers in the text. Instead, we condition on the type of information to inquire about, regardless of whether the answer appears explicitly in the text, could be inferred from it, or should be sought elsewhere. Our evaluation demonstrates that we generate diverse and well-formed questions for a large, broad-coverage ontology of predicates and roles.
Knowledge Graph Enhanced Event Extraction in Financial Documents
Sep 06, 2021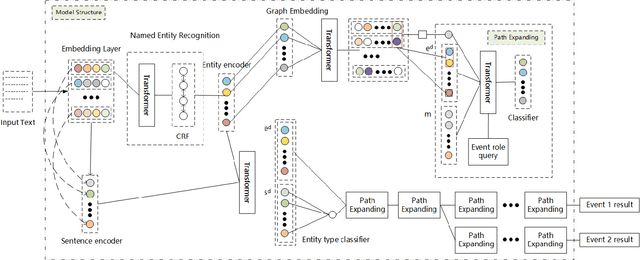
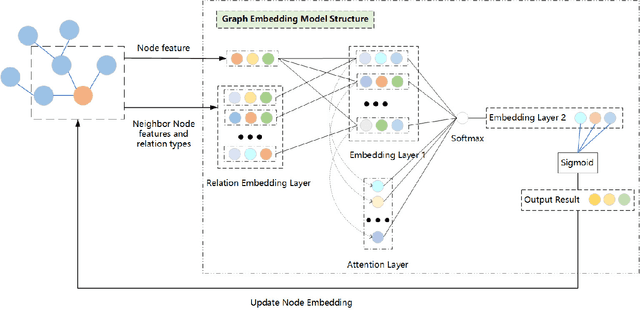

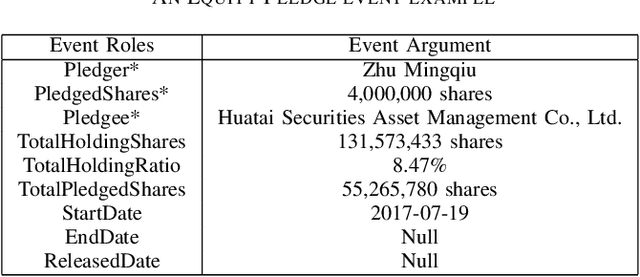
Event extraction is a classic task in natural language processing with wide use in handling large amount of yet rapidly growing financial, legal, medical, and government documents which often contain multiple events with their elements scattered and mixed across the documents, making the problem much more difficult. Though the underlying relations between event elements to be extracted provide helpful contextual information, they are somehow overlooked in prior studies. We showcase the enhancement to this task brought by utilizing the knowledge graph that captures entity relations and their attributes. We propose a first event extraction framework that embeds a knowledge graph through a Graph Neural Network and integrates the embedding with regular features, all at document-level. Specifically, for extracting events from Chinese financial announcements, our method outperforms the state-of-the-art method by 5.3% in F1-score.
Intelligent Reflecting Surface for Multi-Path Beam Routing with Active/Passive Beam Splitting and Combining
Oct 21, 2021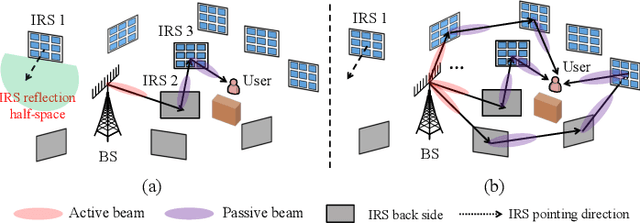
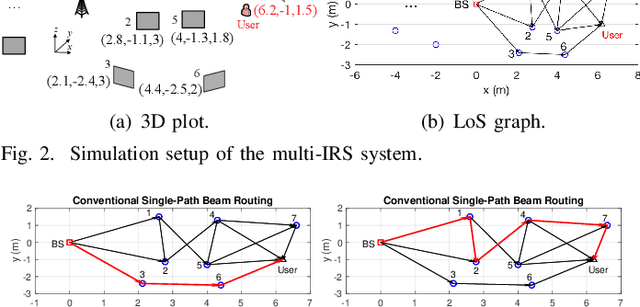
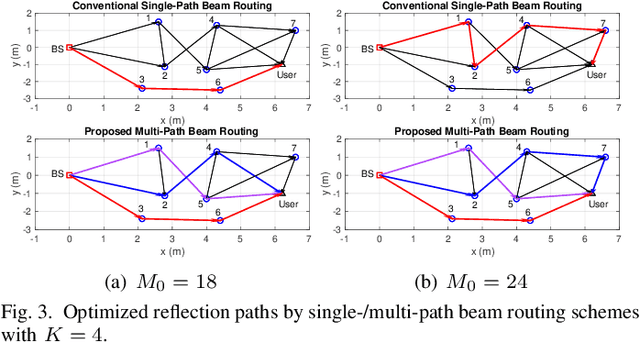
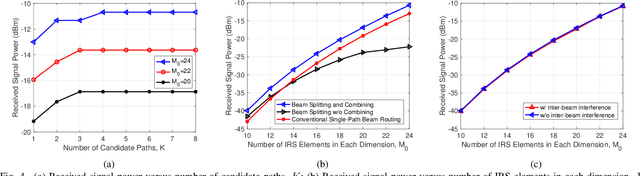
Intelligent reflecting surface (IRS) can be densely deployed in wireless networks to significantly enhance the communication channels. In this letter, we consider the downlink transmission from a multi-antenna base station (BS) to a single-antenna user, by exploiting the cooperative passive beamforming (CPB) and line-of-sight (LoS) path diversity gains of multi-IRS signal reflection. Unlike existing works where only one single multi-IRS reflection path from the BS to user is selected, we propose a new and more general {\it \textbf{multi-path beam routing}} scheme. Specifically, the BS sends the user's information signal via multiple orthogonal active beams (termed as {\it \textbf{active beam splitting}}), which point towards different IRSs. Then, these beamed signals are subsequently reflected by selected IRSs via their CPB in different paths, and finally coherently combined at the user's receiver (thus named {\it \textbf{passive beam combining}}). For this scheme, we formulate a new multi-path beam routing design problem to jointly optimize the number of IRS reflection paths, the selected IRSs for each of the reflection paths, the active/passive beamforming at the BS/each selected IRS, as well as the BS's power allocation over different active beams, so as to maximize the received signal power at the user. To solve this challenging problem, we first derive the optimal BS/IRS beamforming and BS power allocation for a given set of reflection paths. The clique-based approach in graph theory is then applied to solve the remaining multi-path selection problem efficiently. Simulation results show that our proposed multi-path beam routing scheme significantly outperforms its conventional single-path beam routing special case.
Cluster Analysis with Deep Embeddings and Contrastive Learning
Sep 26, 2021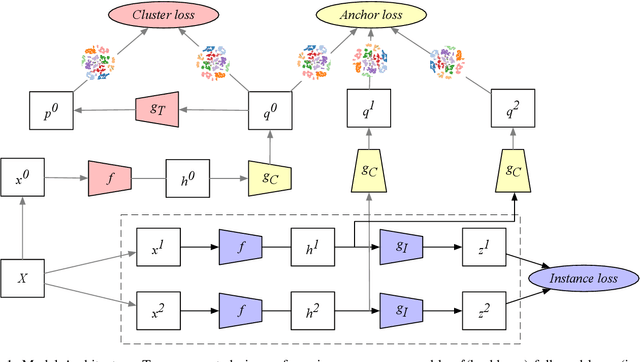
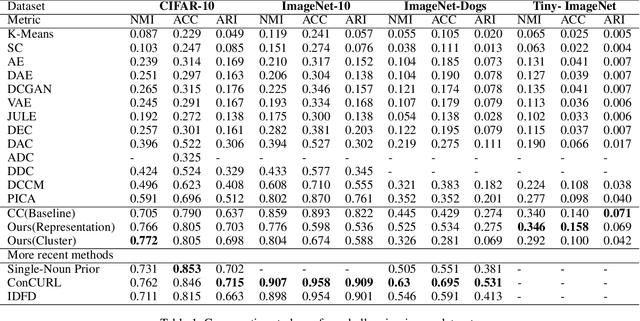
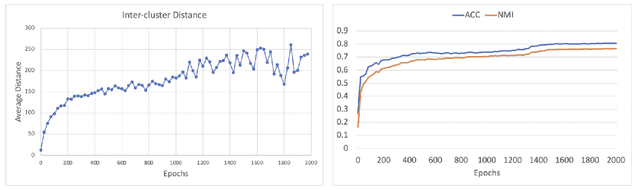
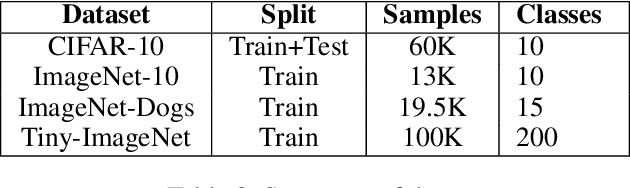
Unsupervised disentangled representation learning is a long-standing problem in computer vision. This work proposes a novel framework for performing image clustering from deep embeddings by combining instance-level contrastive learning with a deep embedding based cluster center predictor. Our approach jointly learns representations and predicts cluster centers in an end-to-end manner. This is accomplished via a three-pronged approach that combines a clustering loss, an instance-wise contrastive loss, and an anchor loss. Our fundamental intuition is that using an ensemble loss that incorporates instance-level features and a clustering procedure focusing on semantic similarity reinforces learning better representations in the latent space. We observe that our method performs exceptionally well on popular vision datasets when evaluated using standard clustering metrics such as Normalized Mutual Information (NMI), in addition to producing geometrically well-separated cluster embeddings as defined by the Euclidean distance. Our framework performs on par with widely accepted clustering methods and outperforms the state-of-the-art contrastive learning method on the CIFAR-10 dataset with an NMI score of 0.772, a 7-8% improvement on the strong baseline.
Wake-Cough: cough spotting and cougher identification for personalised long-term cough monitoring
Oct 07, 2021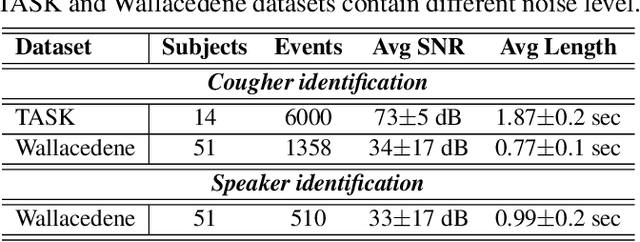

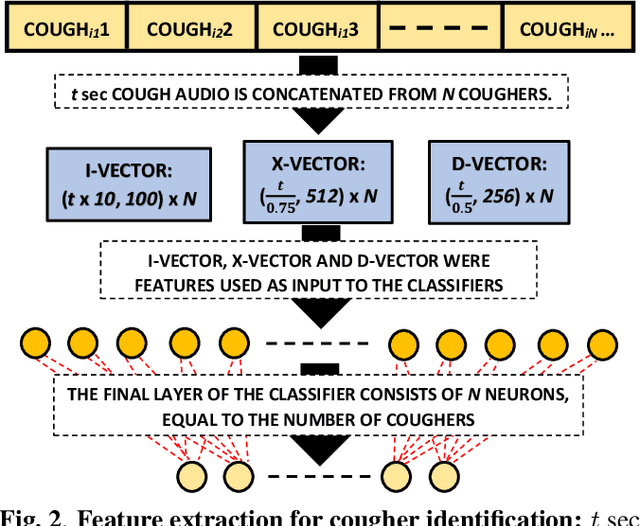
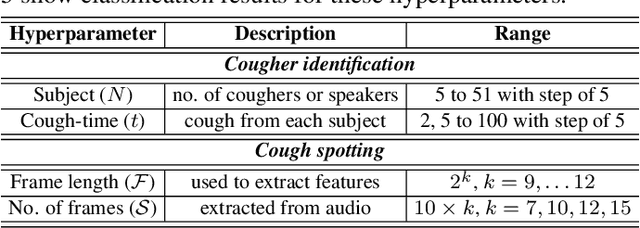
We present 'wake-cough', an application of wake-word spotting to coughs using Resnet50 and identifying coughers using i-vectors, for the purpose of a long-term, personalised cough monitoring system. Coughs, recorded in a quiet (73$\pm$5 dB) and noisy (34$\pm$17 dB) environment, were used to extract i-vectors, x-vectors and d-vectors, used as features to the classifiers. The system achieves 90.02\% accuracy from an MLP to discriminate 51 coughers using 2-sec long cough segments in the noisy environment. When discriminating between 5 and 14 coughers using longer (100 sec) segments in the quiet environment, this accuracy rises to 99.78\% and 98.39\% respectively. Unlike speech, i-vectors outperform x-vectors and d-vectors in identifying coughers. These coughs were added as an extra class in the Google Speech Commands dataset and features were extracted by preserving the end-to-end time-domain information in an event. The highest accuracy of 88.58\% is achieved in spotting coughs among 35 other trigger phrases using a Resnet50. Wake-cough represents a personalised, non-intrusive, cough monitoring system, which is power efficient as using wake-word detection method can keep a smartphone-based monitoring device mostly dormant. This makes wake-cough extremely attractive in multi-bed ward environments to monitor patient's long-term recovery from lung ailments such as tuberculosis and COVID-19.
Explanation as a process: user-centric construction of multi-level and multi-modal explanations
Oct 07, 2021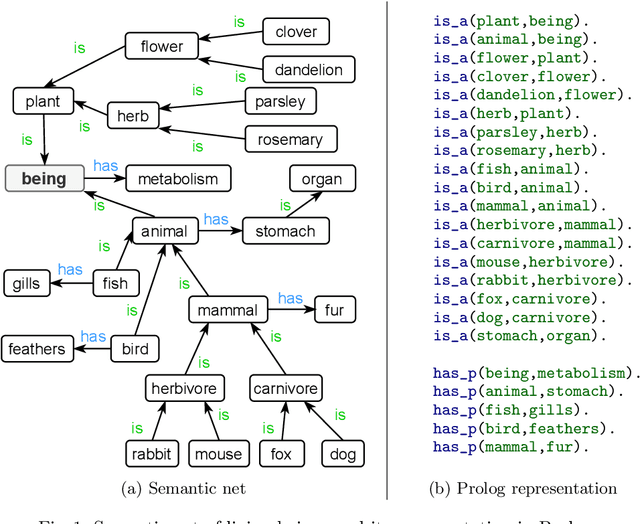


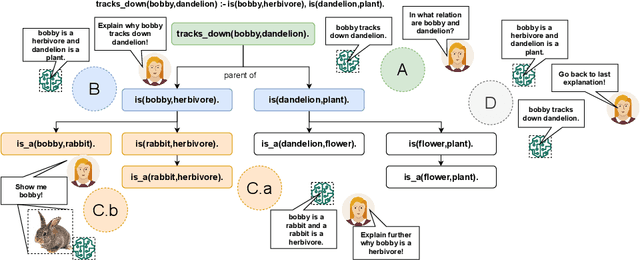
In the last years, XAI research has mainly been concerned with developing new technical approaches to explain deep learning models. Just recent research has started to acknowledge the need to tailor explanations to different contexts and requirements of stakeholders. Explanations must not only suit developers of models, but also domain experts as well as end users. Thus, in order to satisfy different stakeholders, explanation methods need to be combined. While multi-modal explanations have been used to make model predictions more transparent, less research has focused on treating explanation as a process, where users can ask for information according to the level of understanding gained at a certain point in time. Consequently, an opportunity to explore explanations on different levels of abstraction should be provided besides multi-modal explanations. We present a process-based approach that combines multi-level and multi-modal explanations. The user can ask for textual explanations or visualizations through conversational interaction in a drill-down manner. We use Inductive Logic Programming, an interpretable machine learning approach, to learn a comprehensible model. Further, we present an algorithm that creates an explanatory tree for each example for which a classifier decision is to be explained. The explanatory tree can be navigated by the user to get answers of different levels of detail. We provide a proof-of-concept implementation for concepts induced from a semantic net about living beings.
Improved Pillar with Fine-grained Feature for 3D Object Detection
Oct 12, 2021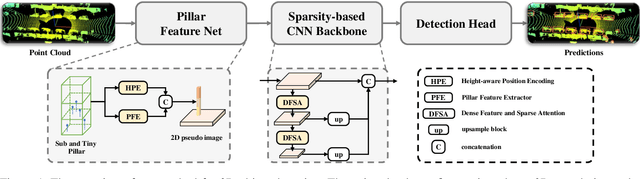
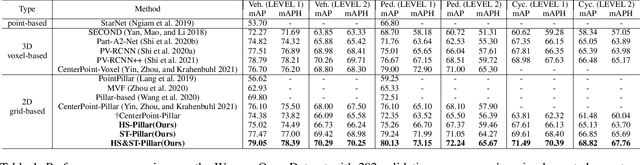
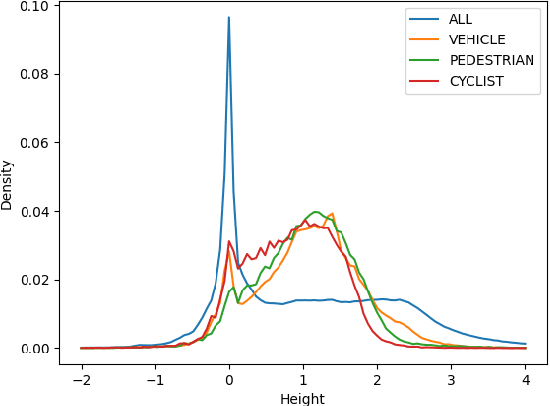
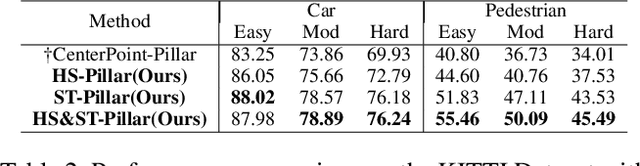
3D object detection with LiDAR point clouds plays an important role in autonomous driving perception module that requires high speed, stability and accuracy. However, the existing point-based methods are challenging to reach the speed requirements because of too many raw points, and the voxel-based methods are unable to ensure stable speed because of the 3D sparse convolution. In contrast, the 2D grid-based methods, such as PointPillar, can easily achieve a stable and efficient speed based on simple 2D convolution, but it is hard to get the competitive accuracy limited by the coarse-grained point clouds representation. So we propose an improved pillar with fine-grained feature based on PointPillar that can significantly improve detection accuracy. It consists of two modules, including height-aware sub-pillar and sparsity-based tiny-pillar, which get fine-grained representation respectively in the vertical and horizontal direction of 3D space. For height-aware sub-pillar, we introduce a height position encoding to keep height information of each sub-pillar during projecting to a 2D pseudo image. For sparsity-based tiny-pillar, we introduce sparsity-based CNN backbone stacked by dense feature and sparse attention module to extract feature with larger receptive field efficiently. Experimental results show that our proposed method significantly outperforms previous state-of-the-art 3D detection methods on the Waymo Open Dataset. The related code will be released to facilitate the academic and industrial study.
RLIRank: Learning to Rank with Reinforcement Learning for Dynamic Search
May 21, 2021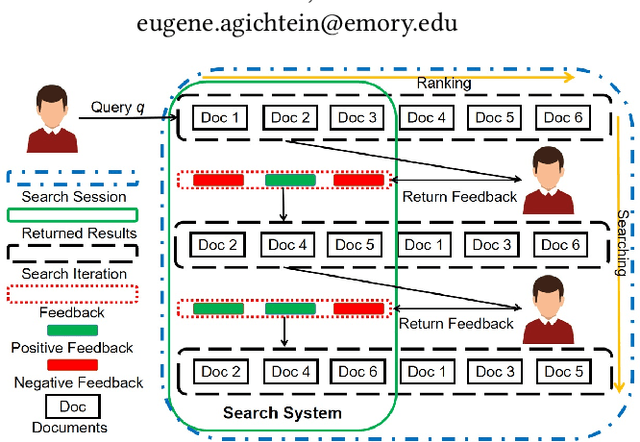
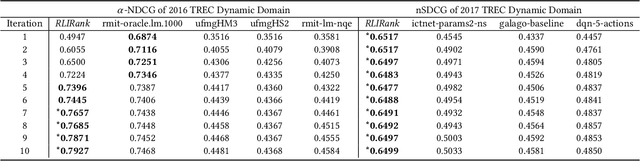
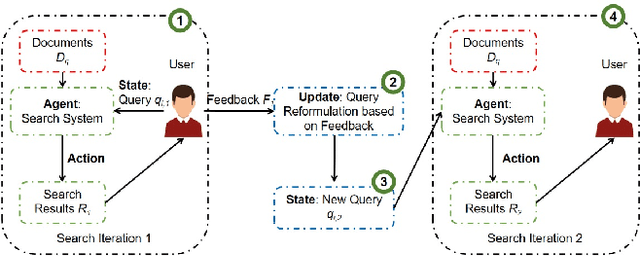

To support complex search tasks, where the initial information requirements are complex or may change during the search, a search engine must adapt the information delivery as the user's information requirements evolve. To support this dynamic ranking paradigm effectively, search result ranking must incorporate both the user feedback received, and the information displayed so far. To address this problem, we introduce a novel reinforcement learning-based approach, RLIrank. We first build an adapted reinforcement learning framework to integrate the key components of the dynamic search. Then, we implement a new Learning to Rank (LTR) model for each iteration of the dynamic search, using a recurrent Long Short Term Memory neural network (LSTM), which estimates the gain for each next result, learning from each previously ranked document. To incorporate the user's feedback, we develop a word-embedding variation of the classic Rocchio Algorithm, to help guide the ranking towards the high-value documents. Those innovations enable RLIrank to outperform the previously reported methods from the TREC Dynamic Domain Tracks 2017 and exceed all the methods in 2016 TREC Dynamic Domain after multiple search iterations, advancing the state of the art for dynamic search.
* Proceedings of The Web Conference 2020 (WWW '20), April 20--24, 2020, Taipei, Taiwan
Making Things Explainable vs Explaining: Requirements and Challenges under the GDPR
Oct 02, 2021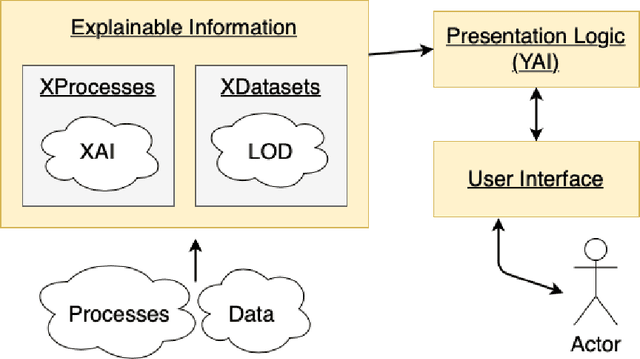

The European Union (EU) through the High-Level Expert Group on Artificial Intelligence (AI-HLEG) and the General Data Protection Regulation (GDPR) has recently posed an interesting challenge to the eXplainable AI (XAI) community, by demanding a more user-centred approach to explain Automated Decision-Making systems (ADMs). Looking at the relevant literature, XAI is currently focused on producing explainable software and explanations that generally follow an approach we could term One-Size-Fits-All, that is unable to meet a requirement of centring on user needs. One of the causes of this limit is the belief that making things explainable alone is enough to have pragmatic explanations. Thus, insisting on a clear separation between explainabilty (something that can be explained) and explanations, we point to explanatorY AI (YAI) as an alternative and more powerful approach to win the AI-HLEG challenge. YAI builds over XAI with the goal to collect and organize explainable information, articulating it into something we called user-centred explanatory discourses. Through the use of explanatory discourses/narratives we represent the problem of generating explanations for Automated Decision-Making systems (ADMs) into the identification of an appropriate path over an explanatory space, allowing explainees to interactively explore it and produce the explanation best suited to their needs.
Edge-similarity-aware Graph Neural Networks
Sep 20, 2021
Graph are a ubiquitous data representation, as they represent a flexible and compact representation. For instance, the 3D structure of RNA can be efficiently represented as $\textit{2.5D graphs}$, graphs whose nodes are nucleotides and edges represent chemical interactions. In this setting, we have biological evidence of the similarity between the edge types, as some chemical interactions are more similar than others. Machine learning on graphs have recently experienced a breakthrough with the introduction of Graph Neural Networks. This algorithm can be framed as a message passing algorithm between graph nodes over graph edges. These messages can depend on the edge type they are transmitted through, but no method currently constrains how a message is altered when the edge type changes. Motivated by the RNA use case, in this project we introduce a graph neural network layer which can leverage prior information about similarities between edges. We show that despite the theoretical appeal of including this similarity prior, the empirical performance is not enhanced on the tasks and datasets we include here.