 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
NL-FCOS: Improving FCOS through Non-Local Modules for Object Detection
Mar 29, 2022


During the last years, we have seen significant advances in the object detection task, mainly due to the outperforming results of convolutional neural networks. In this vein, anchor-based models have achieved the best results. However, these models require prior information about the aspect and scales of target objects, needing more hyperparameters to fit. In addition, using anchors to fit bounding boxes seems far from how our visual system does the same visual task. Instead, our visual system uses the interactions of different scene parts to semantically identify objects, called perceptual grouping. An object detection methodology closer to the natural model is anchor-free detection, where models like FCOS or Centernet have shown competitive results, but these have not yet exploited the concept of perceptual grouping. Therefore, to increase the effectiveness of anchor-free models keeping the inference time low, we propose to add non-local attention (NL modules) modules to boost the feature map of the underlying backbone. NL modules implement the perceptual grouping mechanism, allowing receptive fields to cooperate in visual representation learning. We show that non-local modules combined with an FCOS head (NL-FCOS) are practical and efficient. Thus, we establish state-of-the-art performance in clothing detection and handwritten amount recognition problems.
Towards Loosely-Coupling Knowledge Graph Embeddings and Ontology-based Reasoning
Feb 07, 2022
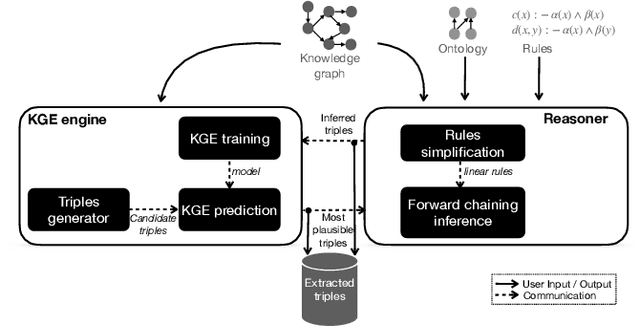

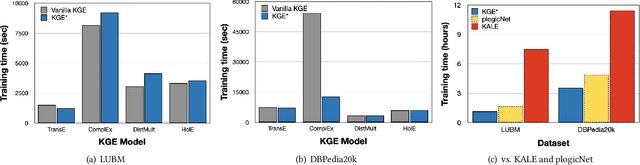
Knowledge graph completion (a.k.a.~link prediction), i.e.,~the task of inferring missing information from knowledge graphs, is a widely used task in many applications, such as product recommendation and question answering. The state-of-the-art approaches of knowledge graph embeddings and/or rule mining and reasoning are data-driven and, thus, solely based on the information the input knowledge graph contains. This leads to unsatisfactory prediction results which make such solutions inapplicable to crucial domains such as healthcare. To further enhance the accuracy of knowledge graph completion we propose to loosely-couple the data-driven power of knowledge graph embeddings with domain-specific reasoning stemming from experts or entailment regimes (e.g., OWL2). In this way, we not only enhance the prediction accuracy with domain knowledge that may not be included in the input knowledge graph but also allow users to plugin their own knowledge graph embedding and reasoning method. Our initial results show that we enhance the MRR accuracy of vanilla knowledge graph embeddings by up to 3x and outperform hybrid solutions that combine knowledge graph embeddings with rule mining and reasoning up to 3.5x MRR.
Research Scholar Interest Mining Method based on Load Centrality
Mar 21, 2022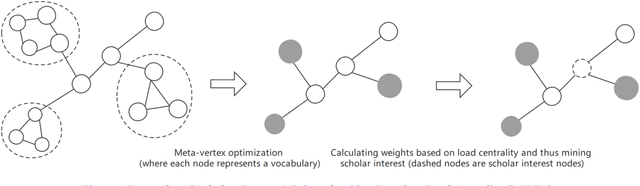
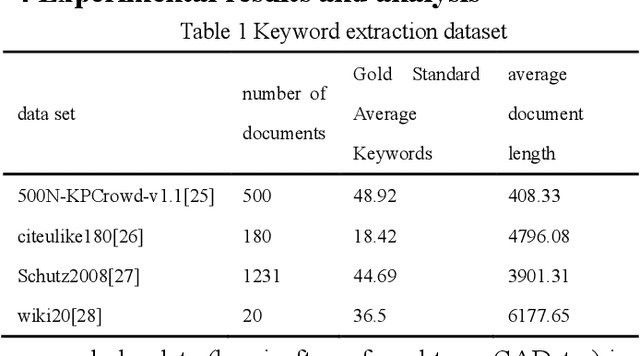
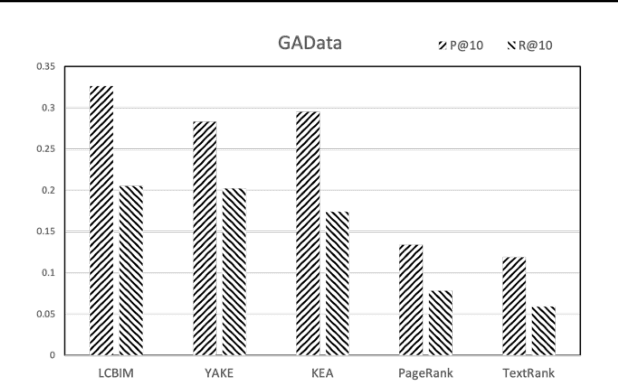
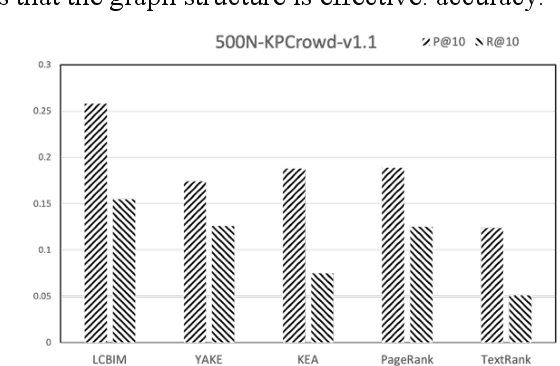
In the era of big data, it is possible to carry out cooperative research on the research results of researchers through papers, patents and other data, so as to study the role of researchers, and produce results in the analysis of results. For the important problems found in the research and application of reality, this paper also proposes a research scholar interest mining algorithm based on load centrality (LCBIM), which can accurately solve the problem according to the researcher's research papers and patent data. Graphs of creative algorithms in various fields of the study aggregated ideas, generated topic graphs by aggregating neighborhoods, used the generated topic information to construct with similar or similar topic spaces, and utilize keywords to construct one or more topics. The regional structure of each topic can be used to closely calculate the weight of the centrality research model of the node, which can analyze the field in the complete coverage principle. The scientific research cooperation based on the load rate center proposed in this paper can effectively extract the interests of scientific research scholars from papers and corpus.
Physics-informed ConvNet: Learning Physical Field from a Shallow Neural Network
Feb 07, 2022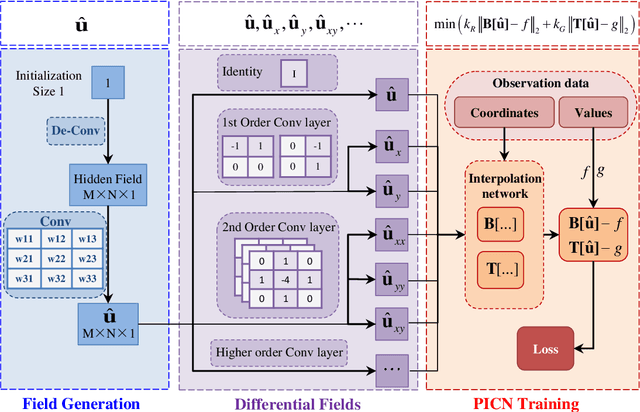

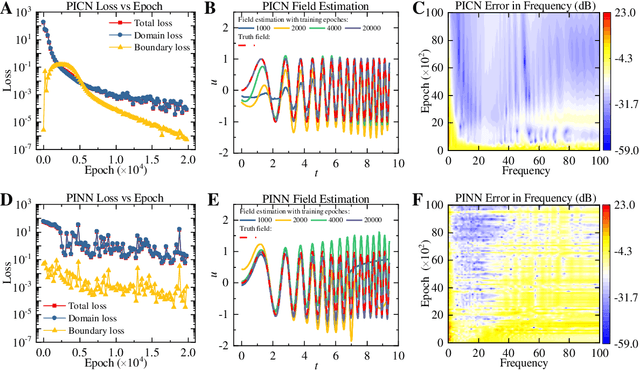
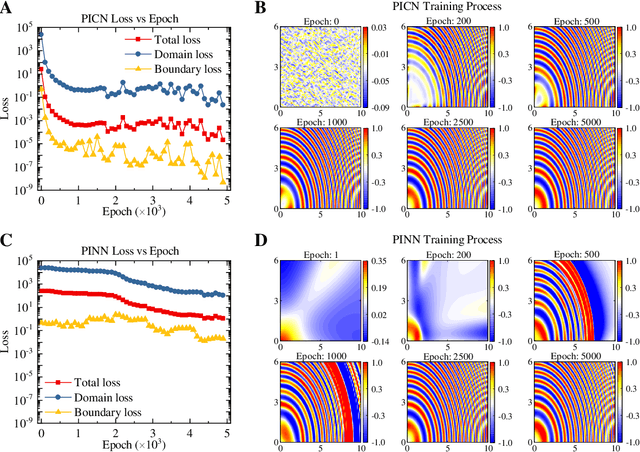
Big-data-based artificial intelligence (AI) supports profound evolution in almost all of science and technology. However, modeling and forecasting multi-physical systems remain a challenge due to unavoidable data scarcity and noise. Improving the generalization ability of neural networks by "teaching" domain knowledge and developing a new generation of models combined with the physical laws have become promising areas of machine learning research. Different from "deep" fully-connected neural networks embedded with physical information (PINN), a novel shallow framework named physics-informed convolutional network (PICN) is recommended from a CNN perspective, in which the physical field is generated by a deconvolution layer and a single convolution layer. The difference fields forming the physical operator are constructed using the pre-trained shallow convolution layer. An efficient linear interpolation network calculates the loss function involving boundary conditions and the physical constraints in irregular geometry domains. The effectiveness of the current development is illustrated through some numerical cases involving the solving (and estimation) of nonlinear physical operator equations and recovering physical information from noisy observations. Its potential advantage in approximating physical fields with multi-frequency components indicates that PICN may become an alternative neural network solver in physics-informed machine learning.
More Information Supervised Probabilistic Deep Face Embedding Learning
Jun 11, 2020

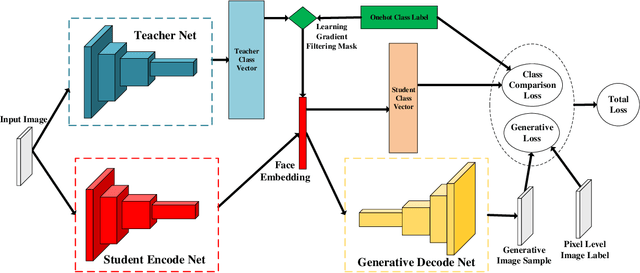
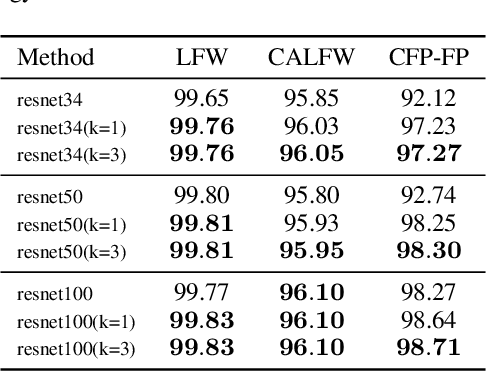
Researches using margin based comparison loss demonstrate the effectiveness of penalizing the distance between face feature and their corresponding class centers. Despite their popularity and excellent performance, they do not explicitly encourage the generic embedding learning for an open set recognition problem. In this paper, we analyse margin based softmax loss in probability view. With this perspective, we propose two general principles: 1) monotonic decreasing and 2) margin probability penalty, for designing new margin loss functions. Unlike methods optimized with single comparison metric, we provide a new perspective to treat open set face recognition as a problem of information transmission. And the generalization capability for face embedding is gained with more clean information. An auto-encoder architecture called Linear-Auto-TS-Encoder(LATSE) is proposed to corroborate this finding. Extensive experiments on several benchmarks demonstrate that LATSE help face embedding to gain more generalization capability and it boosted the single model performance with open training dataset to more than $99\%$ on MegaFace test.
Continuous Detection, Rapidly React: Unseen Rumors Detection based on Continual Prompt-Tuning
Mar 16, 2022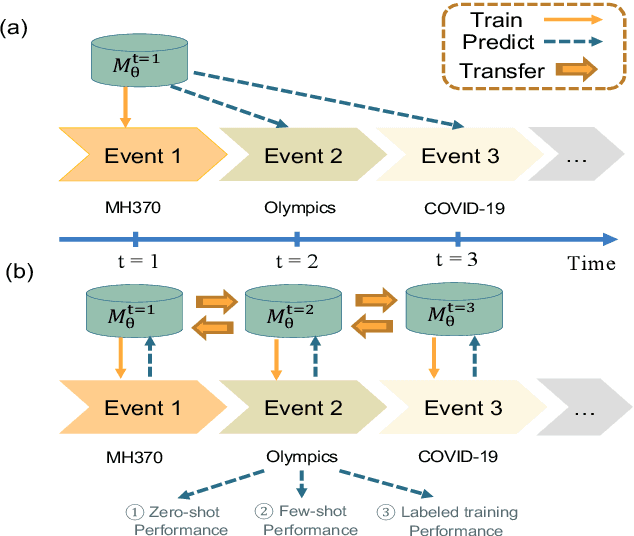
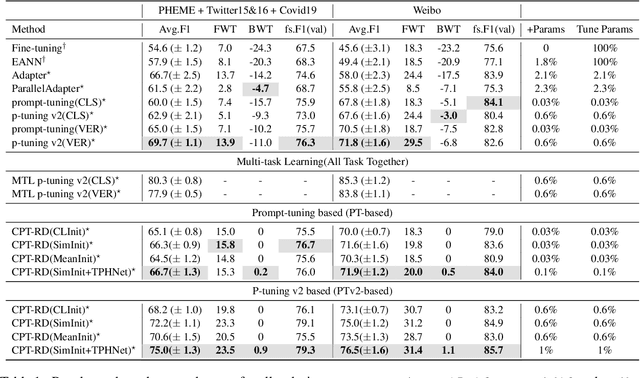
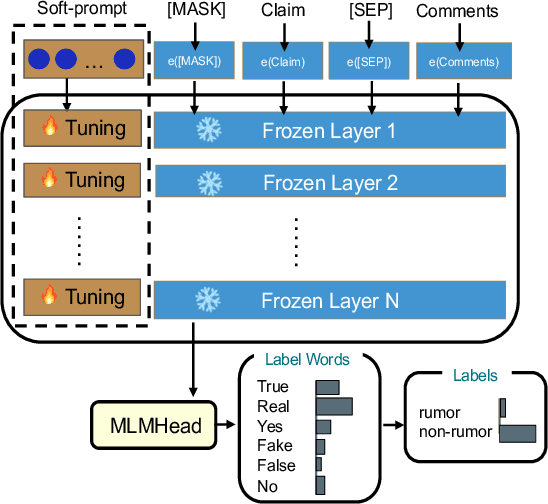
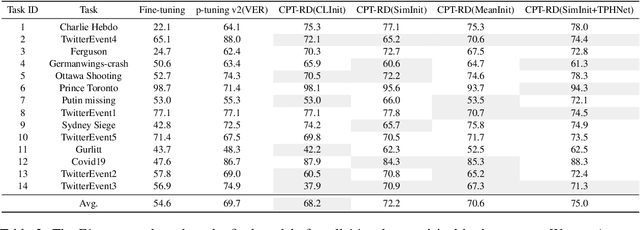
Since open social platforms allow for a large and continuous flow of unverified information, rumors can emerge unexpectedly and spread quickly. However, existing rumor detection (RD) models often assume the same training and testing distributions and cannot cope with the continuously changing social network environment. This paper proposes a Continual Prompt-Tuning RD (CPT-RD) framework, which avoids catastrophic forgetting of upstream tasks during sequential task learning and enables knowledge transfer between domain tasks. To avoid forgetting, we optimize and store task-special soft-prompt for each domain. Furthermore, we also propose several strategies to transfer knowledge of upstream tasks to deal with emergencies and a task-conditioned prompt-wise hypernetwork (TPHNet) to consolidate past domains, enabling bidirectional knowledge transfer. Finally, CPT-RD is evaluated on English and Chinese RD datasets and is effective and efficient compared to state-of-the-art baselines, without data replay techniques and with only a few parameter tuning.
Towards Power-Efficient Design of Myoelectric Controller based on Evolutionary Computation
Apr 02, 2022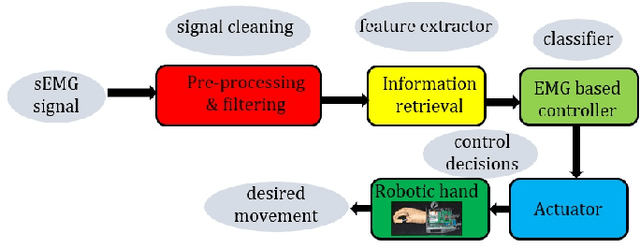
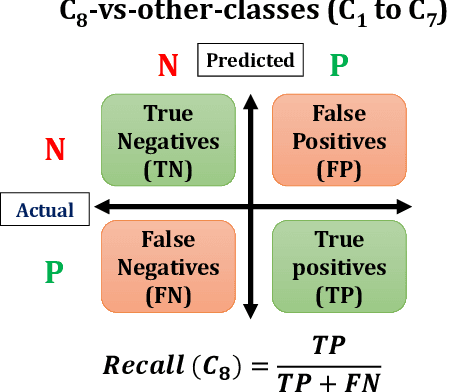
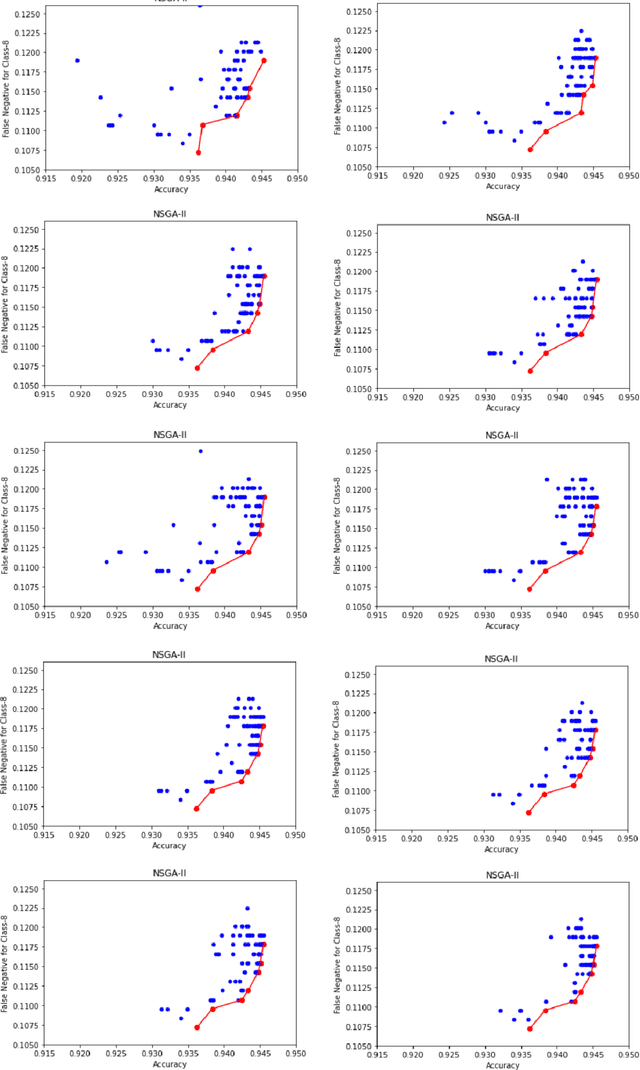
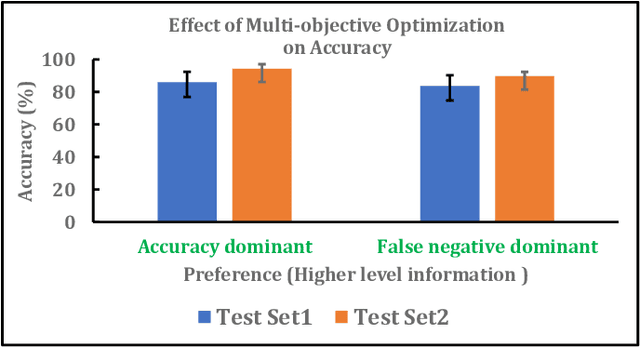
Myoelectric pattern recognition is one of the important aspects in the design of the control strategy for various applications including upper-limb prostheses and bio-robotic hand movement systems. The current work has proposed an approach to design an energy-efficient EMG-based controller by considering a supervised learning framework using a kernelized SVM classifier for decoding the information of surface electromyography (sEMG) signals to infer the underlying muscle movements. In order to achieve the optimized performance of the EMG-based controller, our main strategy of classifier design is to reduce the false movements of the overall system (when the EMG-based controller is at the `Rest' position). To this end, unlike the traditional single training objective of soft margin kernelized SVM, we have formulated the training algorithm of the proposed supervised learning system as a general constrained multi-objective optimization problem. An elitist multi-objective evolutionary algorithm $-$ the non-dominated sorting genetic algorithm II (NSGA-II) has been used for the tuning of SVM hyperparameters. We have presented the experimental results by performing the experiments on a dataset consisting of the sEMG signals collected from eleven subjects at five different upper limb positions. It is evident from the presented result that the proposed approach provides much more flexibility to the designer in selecting the parameters of the classifier to optimize the energy efficiency of the EMG-based controller.
Migratable AI : Investigating users' affect on identity and information migration of a conversational AI agent
Oct 22, 2020
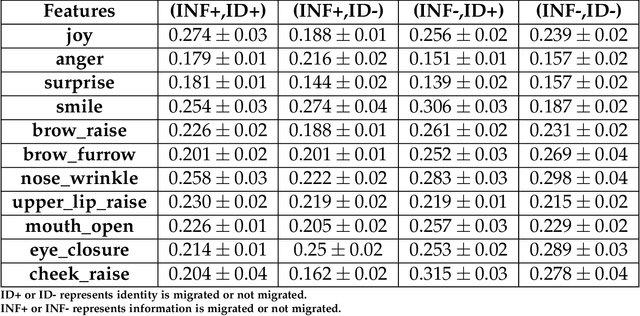
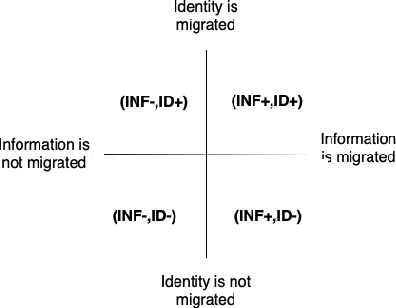
Conversational AI agents are becoming ubiquitous and provide assistance to us in our everyday activities. In recent years, researchers have explored the migration of these agents across different embodiments in order to maintain the continuity of the task and improve user experience. In this paper, we investigate user's affective responses in different configurations of the migration parameters. We present a 2x2 between-subjects study in a task-based scenario using information migration and identity migration as parameters. We outline the affect processing pipeline from the video footage collected during the study and report user's responses in each condition. Our results show that users reported highest joy and were most surprised when both the information and identity was migrated; and reported most anger when the information was migrated without the identity of their agent.
Medical Application of Geometric Deep Learning for the Diagnosis of Glaucoma
Apr 14, 2022
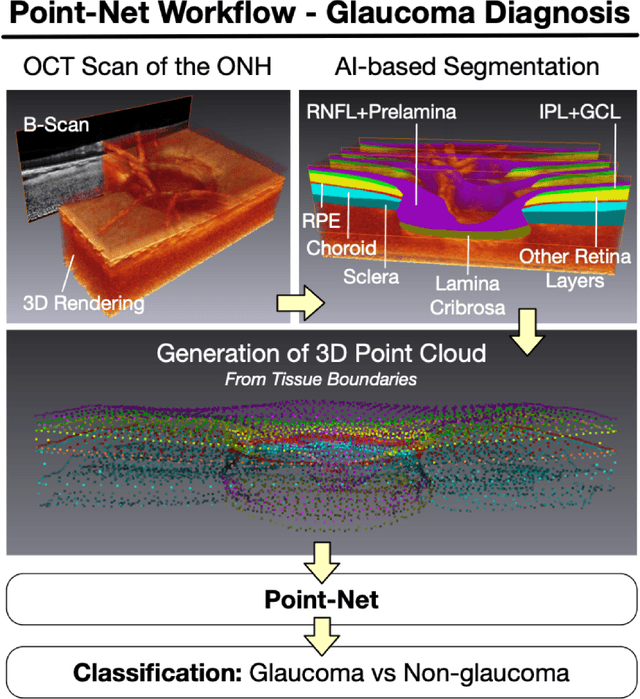
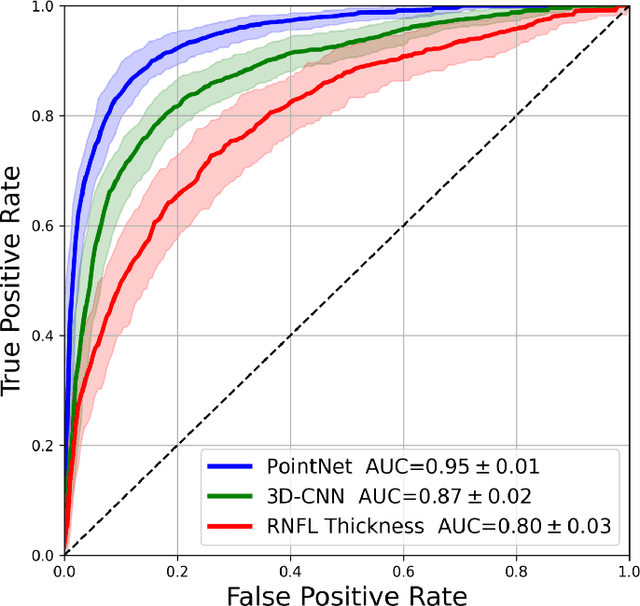
Purpose: (1) To assess the performance of geometric deep learning (PointNet) in diagnosing glaucoma from a single optical coherence tomography (OCT) 3D scan of the optic nerve head (ONH); (2) To compare its performance to that obtained with a standard 3D convolutional neural network (CNN), and with a gold-standard glaucoma parameter, i.e. retinal nerve fiber layer (RNFL) thickness. Methods: 3D raster scans of the ONH were acquired with Spectralis OCT for 477 glaucoma and 2,296 non-glaucoma subjects at the Singapore National Eye Centre. All volumes were automatically segmented using deep learning to identify 7 major neural and connective tissues including the RNFL, the prelamina, and the lamina cribrosa (LC). Each ONH was then represented as a 3D point cloud with 1,000 points chosen randomly from all tissue boundaries. To simplify the problem, all ONH point clouds were aligned with respect to the plane and center of Bruch's membrane opening. Geometric deep learning (PointNet) was then used to provide a glaucoma diagnosis from a single OCT point cloud. The performance of our approach was compared to that obtained with a 3D CNN, and with RNFL thickness. Results: PointNet was able to provide a robust glaucoma diagnosis solely from the ONH represented as a 3D point cloud (AUC=95%). The performance of PointNet was superior to that obtained with a standard 3D CNN (AUC=87%) and with that obtained from RNFL thickness alone (AUC=80%). Discussion: We provide a proof-of-principle for the application of geometric deep learning in the field of glaucoma. Our technique requires significantly less information as input to perform better than a 3D CNN, and with an AUC superior to that obtained from RNFL thickness alone. Geometric deep learning may have wide applicability in the field of Ophthalmology.
Abstractive Information Extraction from Scanned Invoices (AIESI) using End-to-end Sequential Approach
Sep 12, 2020


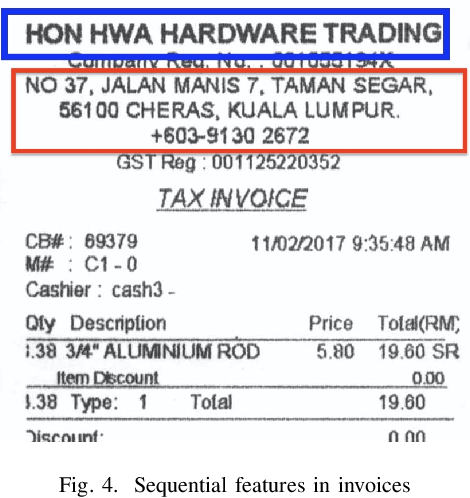
Recent proliferation in the field of Machine Learning and Deep Learning allows us to generate OCR models with higher accuracy. Optical Character Recognition(OCR) is the process of extracting text from documents and scanned images. For document data streamlining, we are interested in data like, Payee name, total amount, address, and etc. Extracted information helps to get complete insight of data, which can be helpful for fast document searching, efficient indexing in databases, data analytics, and etc. Using AIESI we can eliminate human effort for key parameters extraction from scanned documents. Abstract Information Extraction from Scanned Invoices (AIESI) is a process of extracting information like, date, total amount, payee name, and etc from scanned receipts. In this paper we proposed an improved method to ensemble all visual and textual features from invoices to extract key invoice parameters using Word wise BiLSTM.