 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Framework for Event-based Computer Vision on a Mobile Device
May 13, 2022
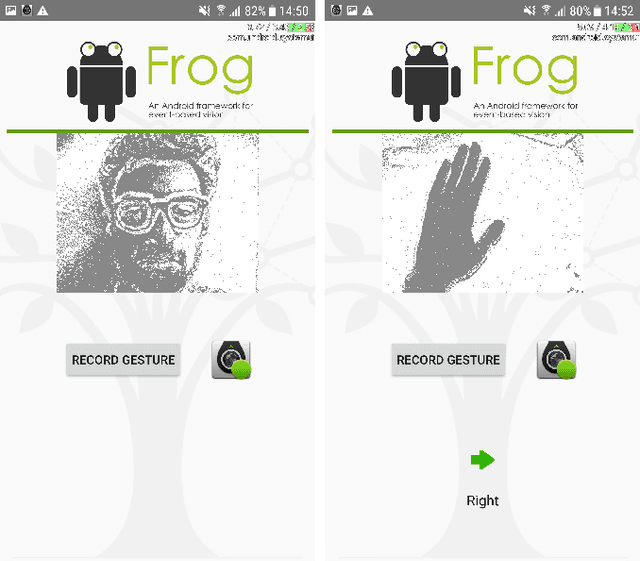
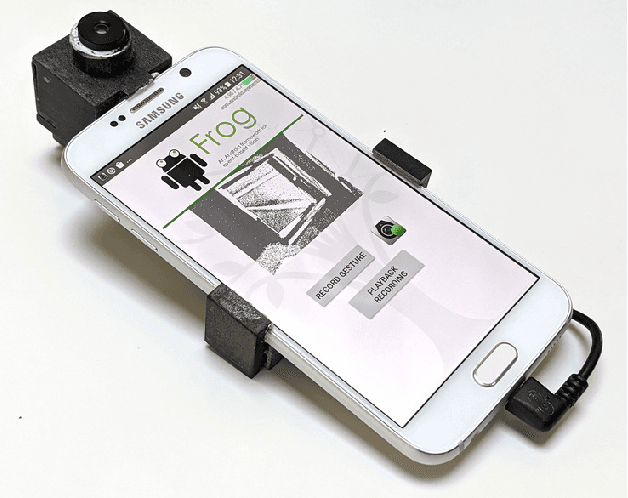
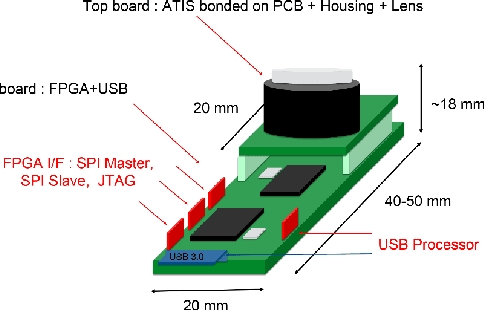
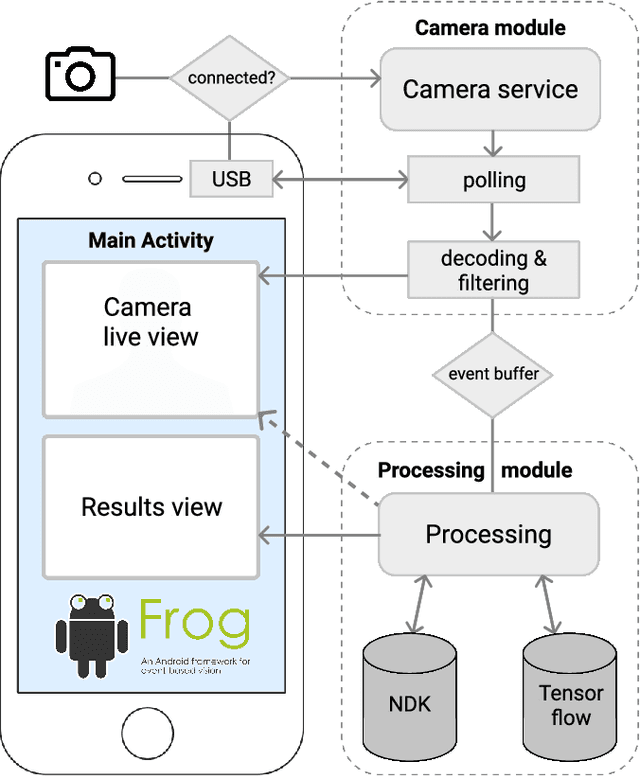
We present the first publicly available Android framework to stream data from an event camera directly to a mobile phone. Today's mobile devices handle a wider range of workloads than ever before and they incorporate a growing gamut of sensors that make devices smarter, more user friendly and secure. Conventional cameras in particular play a central role in such tasks, but they cannot record continuously, as the amount of redundant information recorded is costly to process. Bio-inspired event cameras on the other hand only record changes in a visual scene and have shown promising low-power applications that specifically suit mobile tasks such as face detection, gesture recognition or gaze tracking. Our prototype device is the first step towards embedding such an event camera into a battery-powered handheld device. The mobile framework allows us to stream events in real-time and opens up the possibilities for always-on and on-demand sensing on mobile phones. To liaise the asynchronous event camera output with synchronous von Neumann hardware, we look at how buffering events and processing them in batches can benefit mobile applications. We evaluate our framework in terms of latency and throughput and show examples of computer vision tasks that involve both event-by-event and pre-trained neural network methods for gesture recognition, aperture robust optical flow and grey-level image reconstruction from events. The code is available at https://github.com/neuromorphic-paris/frog
Financial data analysis application via multi-strategy text processing
Apr 25, 2022
Maintaining financial system stability is critical to economic development, and early identification of risks and opportunities is essential. The financial industry contains a wide variety of data, such as financial statements, customer information, stock trading data, news, etc. Massive heterogeneous data calls for intelligent algorithms for machines to process and understand. This paper mainly focuses on the stock trading data and news about China A-share companies. We present a financial data analysis application, Financial Quotient Porter, designed to combine textual and numerical data by using a multi-strategy data mining approach. Additionally, we present our efforts and plans in deep learning financial text processing application scenarios using natural language processing (NLP) and knowledge graph (KG) technologies. Based on KG technology, risks and opportunities can be identified from heterogeneous data. NLP technology can be used to extract entities, relations, and events from unstructured text, and analyze market sentiment. Experimental results show market sentiments towards a company and an industry, as well as news-level associations between companies.
CNN self-attention voice activity detector
Mar 06, 2022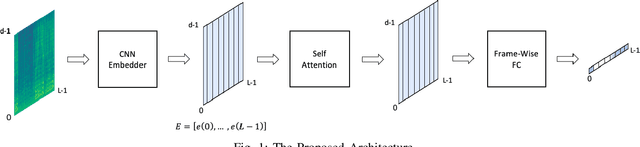
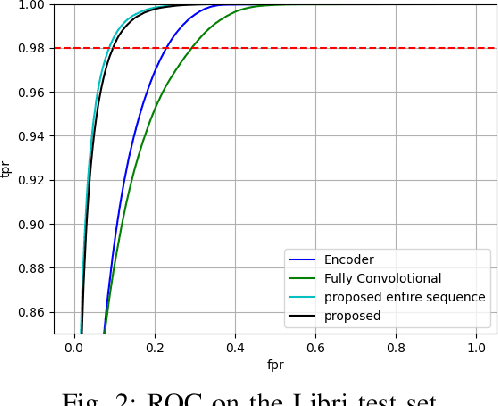
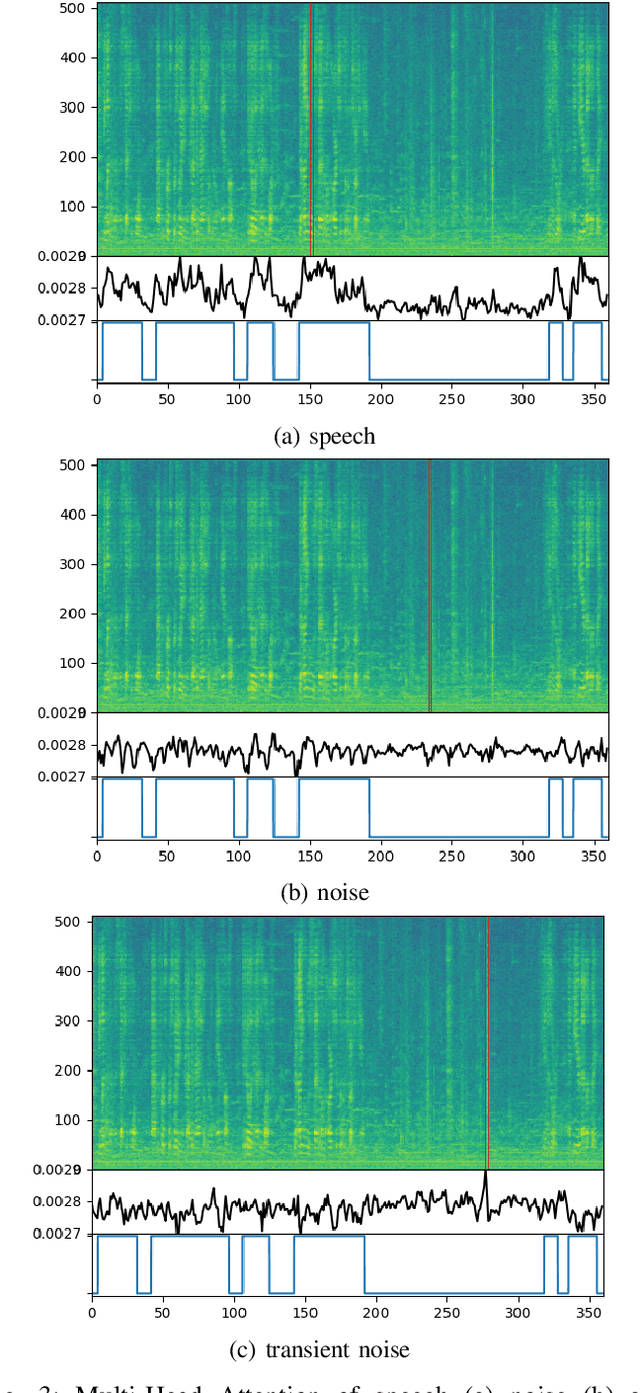
In this work we present a novel single-channel Voice Activity Detector (VAD) approach. We utilize a Convolutional Neural Network (CNN) which exploits the spatial information of the noisy input spectrum to extract frame-wise embedding sequence, followed by a Self Attention (SA) Encoder with a goal of finding contextual information from the embedding sequence. Different from previous works which were employed on each frame (with context frames) separately, our method is capable of processing the entire signal at once, and thus enabling long receptive field. We show that the fusion of CNN and SA architectures outperforms methods based solely on CNN and SA. Extensive experimental-study shows that our model outperforms previous models on real-life benchmarks, and provides State Of The Art (SOTA) results with relatively small and lightweight model.
Multiple Domain Causal Networks
May 13, 2022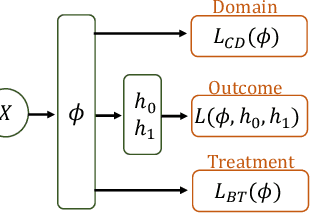
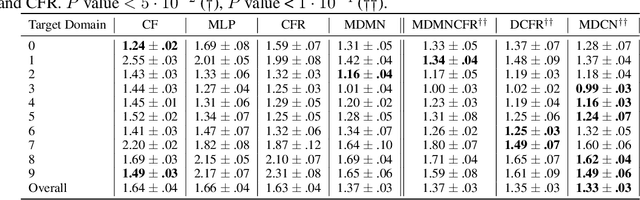
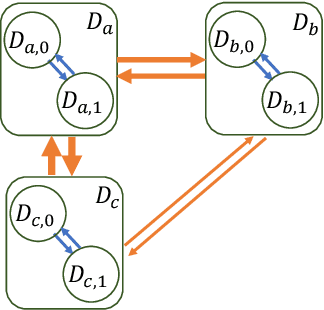
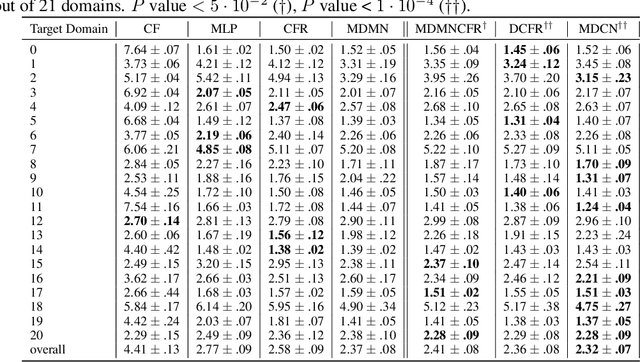
Observational studies are regarded as economic alternatives to randomized trials, often used in their stead to investigate and determine treatment efficacy. Due to lack of sample size, observational studies commonly combine data from multiple sources or different sites/centers. Despite the benefits of an increased sample size, a naive combination of multicenter data may result in incongruities stemming from center-specific protocols for generating cohorts or reactions towards treatments distinct to a given center, among other things. These issues arise in a variety of other contexts, including capturing a treatment effect related to an individual's unique biological characteristics. Existing methods for estimating heterogeneous treatment effects have not adequately addressed the multicenter context, but rather treat it simply as a means to obtain sufficient sample size. Additionally, previous approaches to estimating treatment effects do not straightforwardly generalize to the multicenter design, especially when required to provide treatment insights for patients from a new, unobserved center. To address these shortcomings, we propose Multiple Domain Causal Networks (MDCN), an approach that simultaneously strengthens the information sharing between similar centers while addressing the selection bias in treatment assignment through learning of a new feature embedding. In empirical evaluations, MDCN is consistently more accurate when estimating the heterogeneous treatment effect in new centers compared to benchmarks that adjust solely based on treatment imbalance or general center differences. Finally, we justify our approach by providing theoretical analyses that demonstrate that MDCN improves on the generalization bound of the new, unobserved target center.
All You Need Is Logs: Improving Code Completion by Learning from Anonymous IDE Usage Logs
May 21, 2022

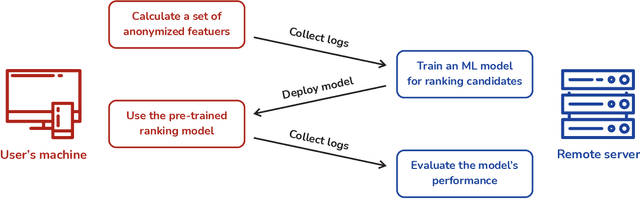
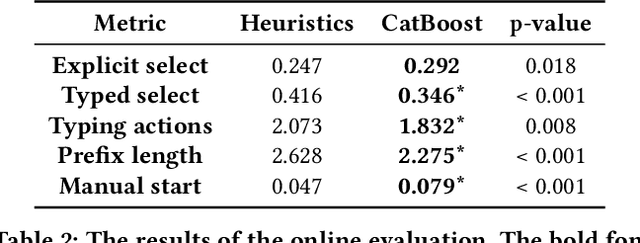
Integrated Development Environments (IDE) are designed to make users more productive, as well as to make their work more comfortable. To achieve this, a lot of diverse tools are embedded into IDEs, and the developers of IDEs can employ anonymous usage logs to collect the data about how they are being used to improve them. A particularly important component that this can be applied to is code completion, since improving code completion using statistical learning techniques is a well-established research area. In this work, we propose an approach for collecting completion usage logs from the users in an IDE and using them to train a machine learning based model for ranking completion candidates. We developed a set of features that describe completion candidates and their context, and deployed their anonymized collection in the Early Access Program of IntelliJ-based IDEs. We used the logs to collect a dataset of code completions from users, and employed it to train a ranking CatBoost model. Then, we evaluated it in two settings: on a held-out set of the collected completions and in a separate A/B test on two different groups of users in the IDE. Our evaluation shows that using a simple ranking model trained on the past user behavior logs significantly improved code completion experience. Compared to the default heuristics-based ranking, our model demonstrated a decrease in the number of typing actions necessary to perform the completion in the IDE from 2.073 to 1.832. The approach adheres to privacy requirements and legal constraints, since it does not require collecting personal information, performing all the necessary anonymization on the client's side. Importantly, it can be improved continuously: implementing new features, collecting new data, and evaluating new models - this way, we have been using it in production since the end of 2020.
Scalable algorithms for physics-informed neural and graph networks
May 16, 2022


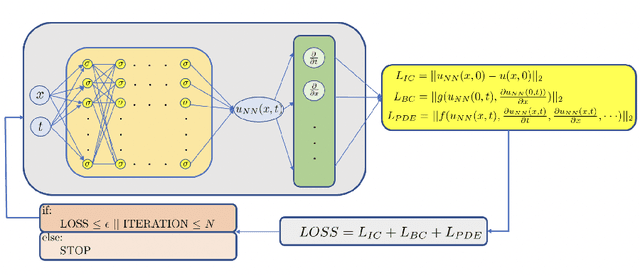
Physics-informed machine learning (PIML) has emerged as a promising new approach for simulating complex physical and biological systems that are governed by complex multiscale processes for which some data are also available. In some instances, the objective is to discover part of the hidden physics from the available data, and PIML has been shown to be particularly effective for such problems for which conventional methods may fail. Unlike commercial machine learning where training of deep neural networks requires big data, in PIML big data are not available. Instead, we can train such networks from additional information obtained by employing the physical laws and evaluating them at random points in the space-time domain. Such physics-informed machine learning integrates multimodality and multifidelity data with mathematical models, and implements them using neural networks or graph networks. Here, we review some of the prevailing trends in embedding physics into machine learning, using physics-informed neural networks (PINNs) based primarily on feed-forward neural networks and automatic differentiation. For more complex systems or systems of systems and unstructured data, graph neural networks (GNNs) present some distinct advantages, and here we review how physics-informed learning can be accomplished with GNNs based on graph exterior calculus to construct differential operators; we refer to these architectures as physics-informed graph networks (PIGNs). We present representative examples for both forward and inverse problems and discuss what advances are needed to scale up PINNs, PIGNs and more broadly GNNs for large-scale engineering problems.
Learning to Retrieve Videos by Asking Questions
May 13, 2022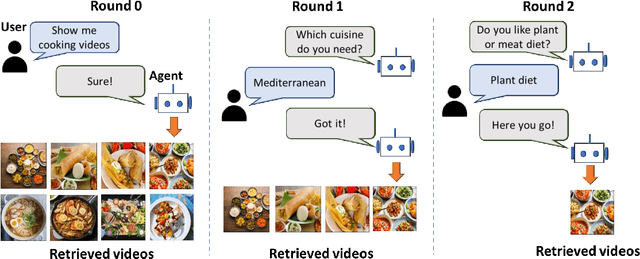

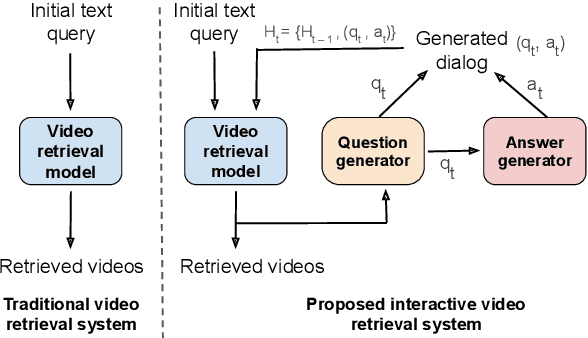
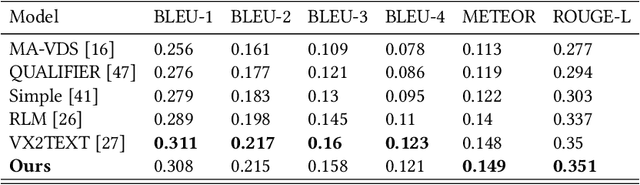
The majority of traditional text-to-video retrieval systems operate in static environments, i.e., there is no interaction between the user and the agent beyond the initial textual query provided by the user. This can be suboptimal if the initial query has ambiguities, which would lead to many falsely retrieved videos. To overcome this limitation, we propose a novel framework for Video Retrieval using Dialog (ViReD), which enables the user to interact with an AI agent via multiple rounds of dialog. The key contribution of our framework is a novel multimodal question generator that learns to ask questions that maximize the subsequent video retrieval performance. Our multimodal question generator uses (i) the video candidates retrieved during the last round of interaction with the user and (ii) the text-based dialog history documenting all previous interactions, to generate questions that incorporate both visual and linguistic cues relevant to video retrieval. Furthermore, to generate maximally informative questions, we propose an Information-Guided Supervision (IGS), which guides the question generator to ask questions that would boost subsequent video retrieval accuracy. We validate the effectiveness of our interactive ViReD framework on the AVSD dataset, showing that our interactive method performs significantly better than traditional non-interactive video retrieval systems. Furthermore, we also demonstrate that our proposed approach also generalizes to the real-world settings that involve interactions with real humans, thus, demonstrating the robustness and generality of our framework
Cognitive Visual-learning Environment for PostgreSQL
May 10, 2022

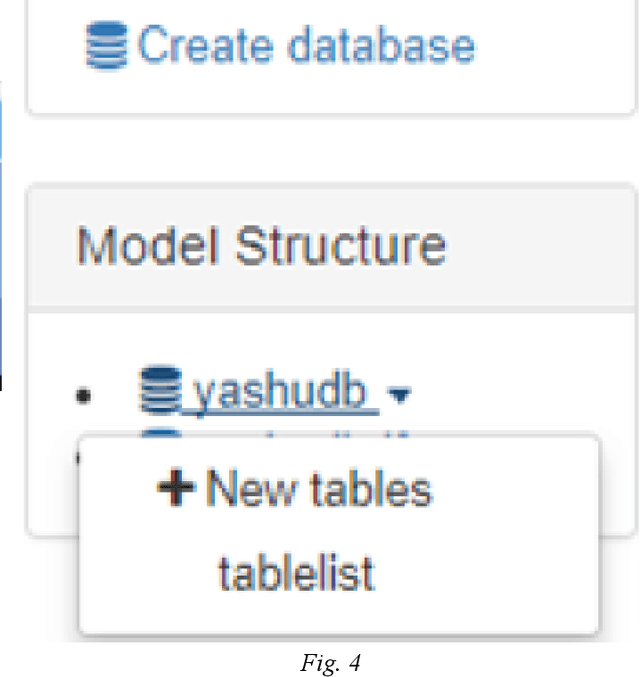
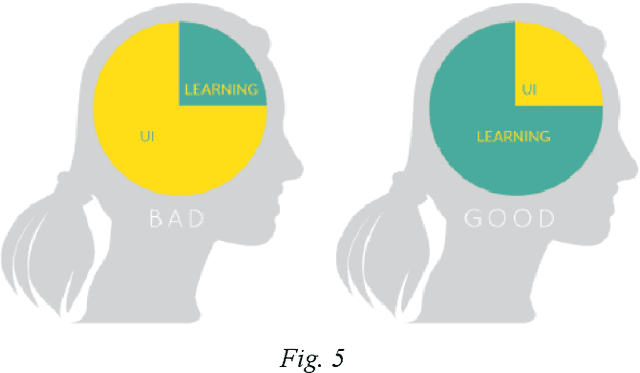
PostgreSQL is an object-relational database (ORDBMS) that was introduced into the database community and has been avidly used for a variety of information extraction use cases. It is also known to be an advanced SQL-compliant open source Object RDBMS. However, users have not yet resolved to PostgreSQL due to the fact that it is still under the layers and the complexity of its persistent textual environment for an amateur user. Hence, there is a dire need to provide an easy environment for users to comprehend the procedure and standards with which databases are created, tables and the relationships among them, manipulating queries and their flow based on conditions in PostgreSQL. As such, this project identifies the dominant features offered by Postgresql, analyzes the constraints that exist in the database user community in migrating to PostgreSQL and based on the scope and constraints identified, develop a system that will serve as a query generation platform as well as a learning tool that will provide an interactive environment to cognitively learn PostgreSQL query building. This is achieved using a visual editor incorporating a textual editor for a well-versed user. By providing visually-draggable query components to work with, this research aims to offer a cognitive, visual and tactile environment where users can interactively learn PostgreSQL query generation.
Locomotion Policy Guided Traversability Learning using Volumetric Representations of Complex Environments
Mar 29, 2022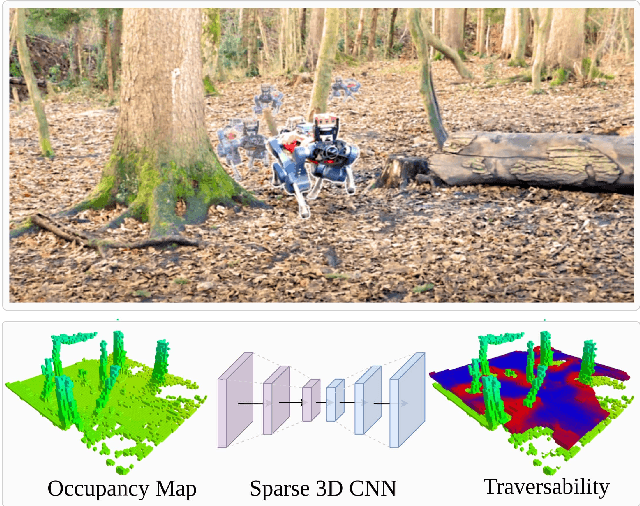


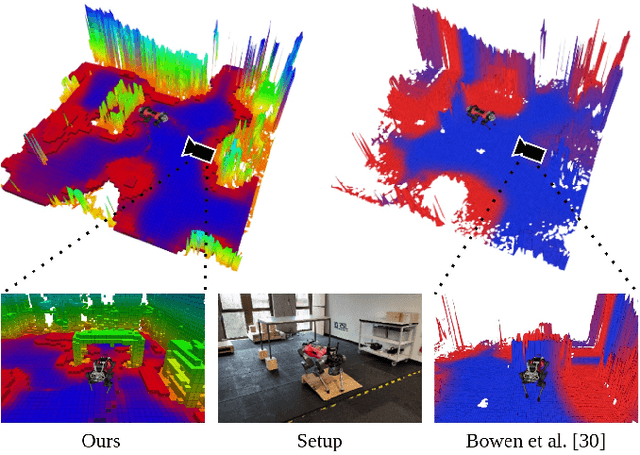
Despite the progress in legged robotic locomotion, autonomous navigation in unknown environments remains an open problem. Ideally, the navigation system utilizes the full potential of the robots' locomotion capabilities while operating within safety limits under uncertainty. The robot must sense and analyze the traversability of the surrounding terrain, which depends on the hardware, locomotion control, and terrain properties. It may contain information about the risk, energy, or time consumption needed to traverse the terrain. To avoid hand-crafted traversability cost functions we propose to collect traversability information about the robot and locomotion policy by simulating the traversal over randomly generated terrains using a physics simulator. Thousand of robots are simulated in parallel controlled by the same locomotion policy used in reality to acquire 57 years of real-world locomotion experience equivalent. For deployment on the real robot, a sparse convolutional network is trained to predict the simulated traversability cost, which is tailored to the deployed locomotion policy, from an entirely geometric representation of the environment in the form of a 3D voxel-occupancy map. This representation avoids the need for commonly used elevation maps, which are error-prone in the presence of overhanging obstacles and multi-floor or low-ceiling scenarios. The effectiveness of the proposed traversability prediction network is demonstrated for path planning for the legged robot ANYmal in various indoor and natural environments.
Information-Driven Adaptive Sensing Based on Deep Reinforcement Learning
Oct 08, 2020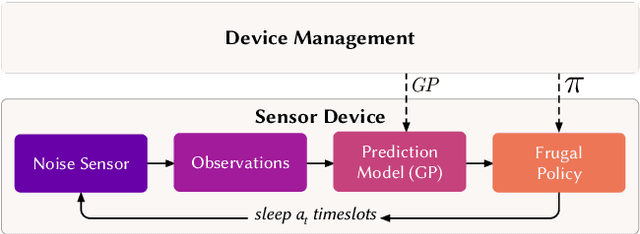
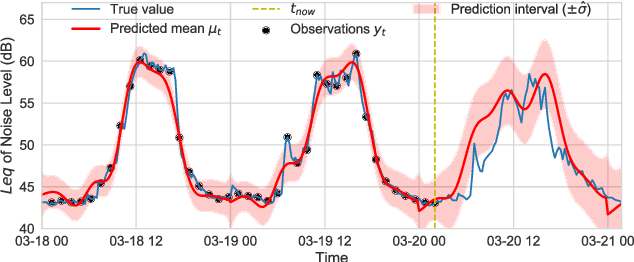
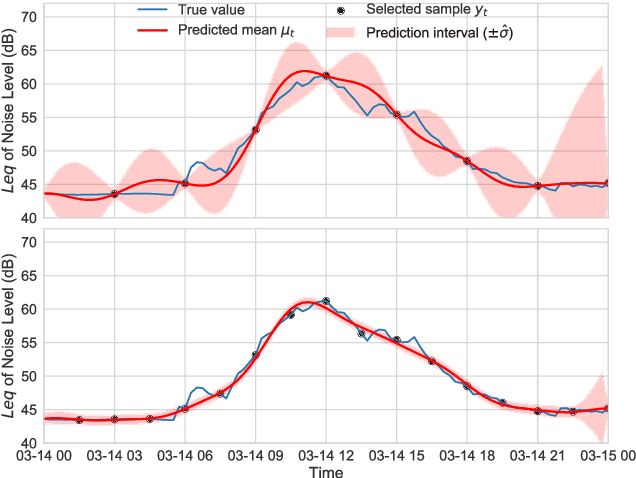
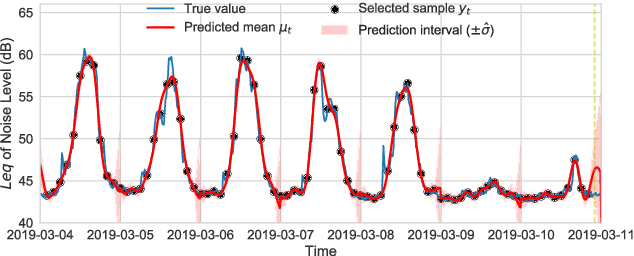
In order to make better use of deep reinforcement learning in the creation of sensing policies for resource-constrained IoT devices, we present and study a novel reward function based on the Fisher information value. This reward function enables IoT sensor devices to learn to spend available energy on measurements at otherwise unpredictable moments, while conserving energy at times when measurements would provide little new information. This is a highly general approach, which allows for a wide range of use cases without significant human design effort or hyper-parameter tuning. We illustrate the approach in a scenario of workplace noise monitoring, where results show that the learned behavior outperforms a uniform sampling strategy and comes close to a near-optimal oracle solution.
* 8 pages, 8 figures