 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYABLoCo: Yet Another Benchmark for Long Context Code Generation
May 07, 2025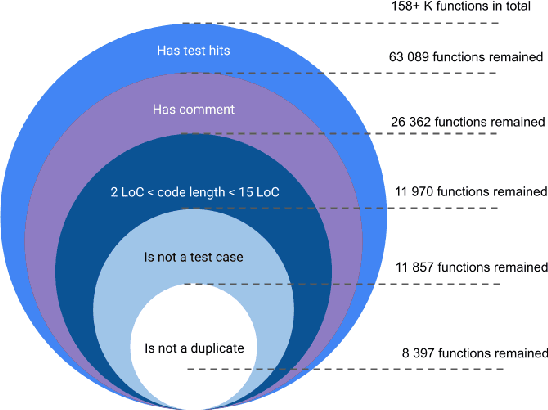
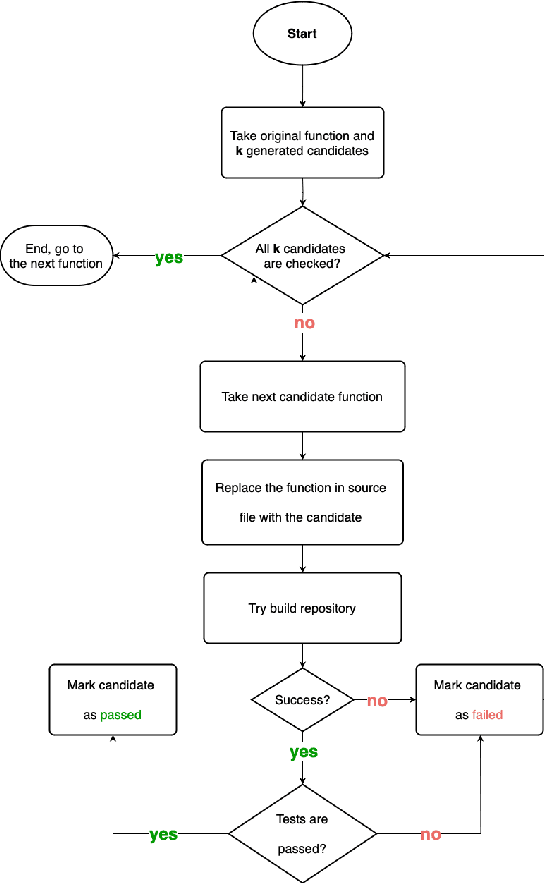
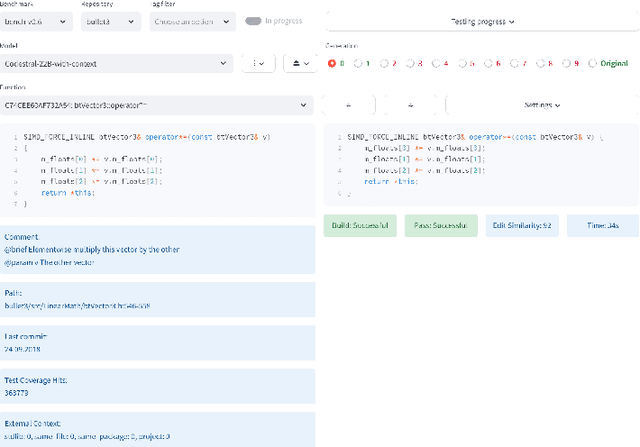
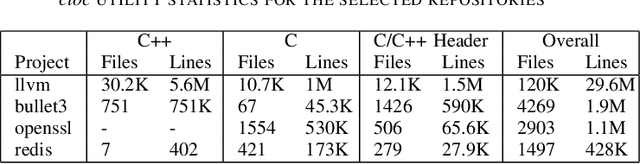
Large Language Models demonstrate the ability to solve various programming tasks, including code generation. Typically, the performance of LLMs is measured on benchmarks with small or medium-sized context windows of thousands of lines of code. At the same time, in real-world software projects, repositories can span up to millions of LoC. This paper closes this gap by contributing to the long context code generation benchmark (YABLoCo). The benchmark featured a test set of 215 functions selected from four large repositories with thousands of functions. The dataset contained metadata of functions, contexts of the functions with different levels of dependencies, docstrings, functions bodies, and call graphs for each repository. This paper presents three key aspects of the contribution. First, the benchmark aims at function body generation in large repositories in C and C++, two languages not covered by previous benchmarks. Second, the benchmark contains large repositories from 200K to 2,000K LoC. Third, we contribute a scalable evaluation pipeline for efficient computing of the target metrics and a tool for visual analysis of generated code. Overall, these three aspects allow for evaluating code generation in large repositories in C and C++.
All You Need Is Logs: Improving Code Completion by Learning from Anonymous IDE Usage Logs
May 21, 2022

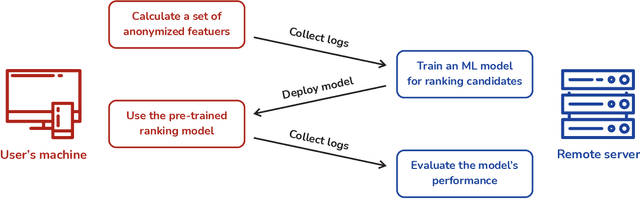
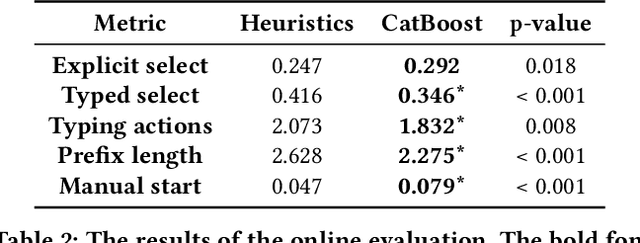
Integrated Development Environments (IDE) are designed to make users more productive, as well as to make their work more comfortable. To achieve this, a lot of diverse tools are embedded into IDEs, and the developers of IDEs can employ anonymous usage logs to collect the data about how they are being used to improve them. A particularly important component that this can be applied to is code completion, since improving code completion using statistical learning techniques is a well-established research area. In this work, we propose an approach for collecting completion usage logs from the users in an IDE and using them to train a machine learning based model for ranking completion candidates. We developed a set of features that describe completion candidates and their context, and deployed their anonymized collection in the Early Access Program of IntelliJ-based IDEs. We used the logs to collect a dataset of code completions from users, and employed it to train a ranking CatBoost model. Then, we evaluated it in two settings: on a held-out set of the collected completions and in a separate A/B test on two different groups of users in the IDE. Our evaluation shows that using a simple ranking model trained on the past user behavior logs significantly improved code completion experience. Compared to the default heuristics-based ranking, our model demonstrated a decrease in the number of typing actions necessary to perform the completion in the IDE from 2.073 to 1.832. The approach adheres to privacy requirements and legal constraints, since it does not require collecting personal information, performing all the necessary anonymization on the client's side. Importantly, it can be improved continuously: implementing new features, collecting new data, and evaluating new models - this way, we have been using it in production since the end of 2020.