 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Retrieve Videos by Asking Questions
Paper and Code
May 13, 2022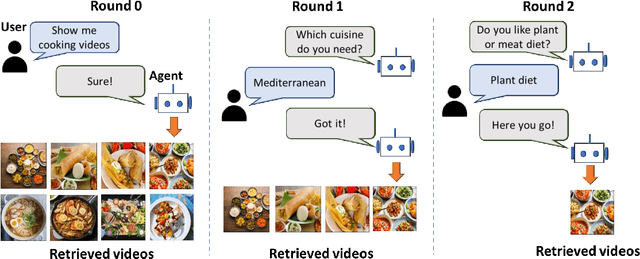

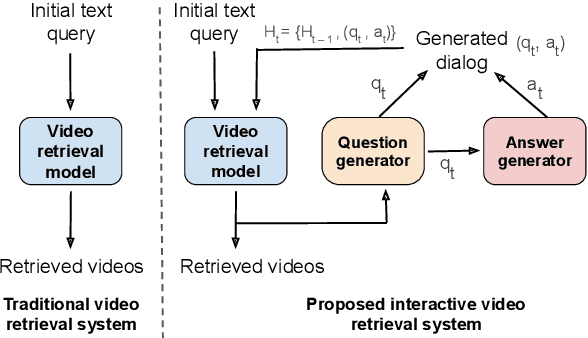
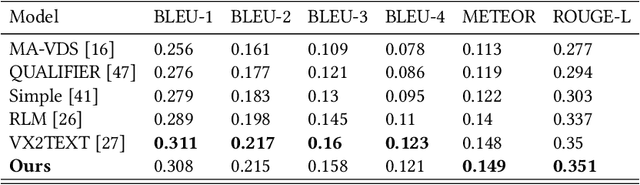
The majority of traditional text-to-video retrieval systems operate in static environments, i.e., there is no interaction between the user and the agent beyond the initial textual query provided by the user. This can be suboptimal if the initial query has ambiguities, which would lead to many falsely retrieved videos. To overcome this limitation, we propose a novel framework for Video Retrieval using Dialog (ViReD), which enables the user to interact with an AI agent via multiple rounds of dialog. The key contribution of our framework is a novel multimodal question generator that learns to ask questions that maximize the subsequent video retrieval performance. Our multimodal question generator uses (i) the video candidates retrieved during the last round of interaction with the user and (ii) the text-based dialog history documenting all previous interactions, to generate questions that incorporate both visual and linguistic cues relevant to video retrieval. Furthermore, to generate maximally informative questions, we propose an Information-Guided Supervision (IGS), which guides the question generator to ask questions that would boost subsequent video retrieval accuracy. We validate the effectiveness of our interactive ViReD framework on the AVSD dataset, showing that our interactive method performs significantly better than traditional non-interactive video retrieval systems. Furthermore, we also demonstrate that our proposed approach also generalizes to the real-world settings that involve interactions with real humans, thus, demonstrating the robustness and generality of our framework