 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Closer Look at Few-shot Image Generation
May 08, 2022
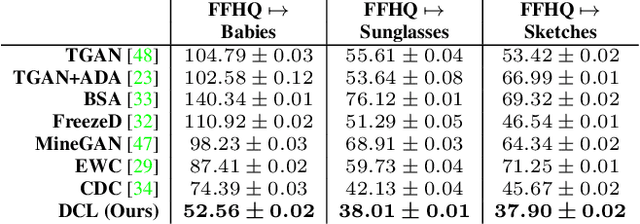
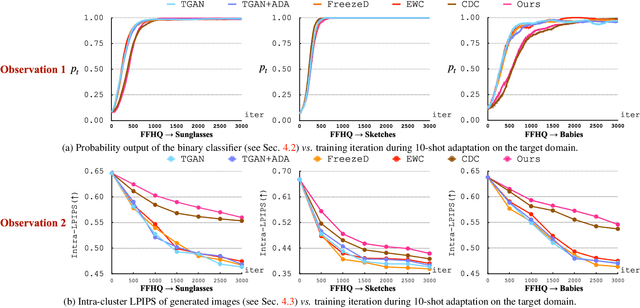
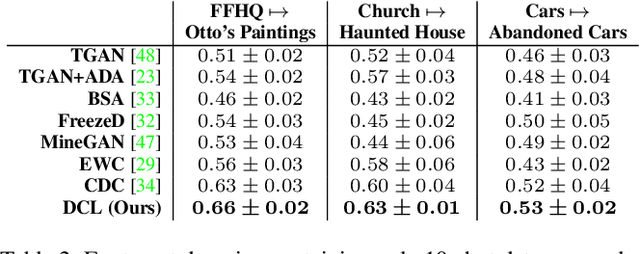
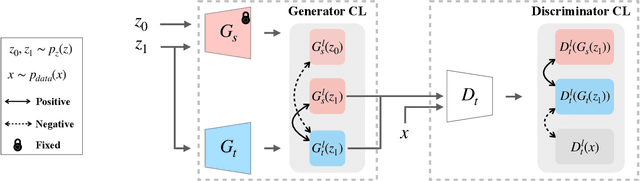
Modern GANs excel at generating high quality and diverse images. However, when transferring the pretrained GANs on small target data (e.g., 10-shot), the generator tends to replicate the training samples. Several methods have been proposed to address this few-shot image generation task, but there is a lack of effort to analyze them under a unified framework. As our first contribution, we propose a framework to analyze existing methods during the adaptation. Our analysis discovers that while some methods have disproportionate focus on diversity preserving which impede quality improvement, all methods achieve similar quality after convergence. Therefore, the better methods are those that can slow down diversity degradation. Furthermore, our analysis reveals that there is still plenty of room to further slow down diversity degradation. Informed by our analysis and to slow down the diversity degradation of the target generator during adaptation, our second contribution proposes to apply mutual information (MI) maximization to retain the source domain's rich multi-level diversity information in the target domain generator. We propose to perform MI maximization by contrastive loss (CL), leverage the generator and discriminator as two feature encoders to extract different multi-level features for computing CL. We refer to our method as Dual Contrastive Learning (DCL). Extensive experiments on several public datasets show that, while leading to a slower diversity-degrading generator during adaptation, our proposed DCL brings visually pleasant quality and state-of-the-art quantitative performance.
Statistical and Computational Phase Transitions in Group Testing
Jun 15, 2022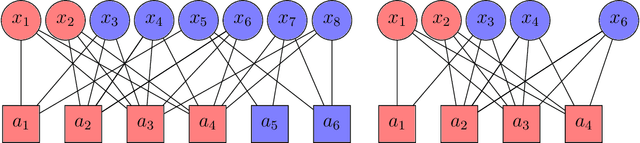
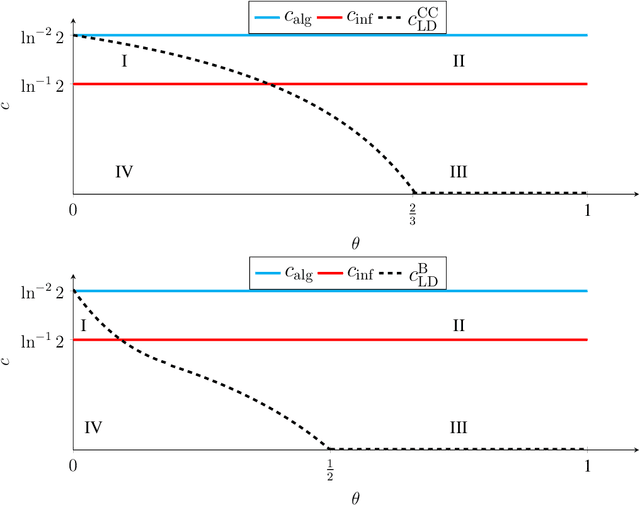
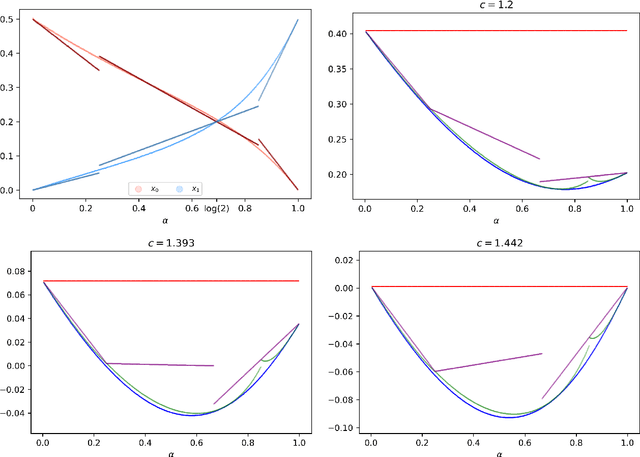
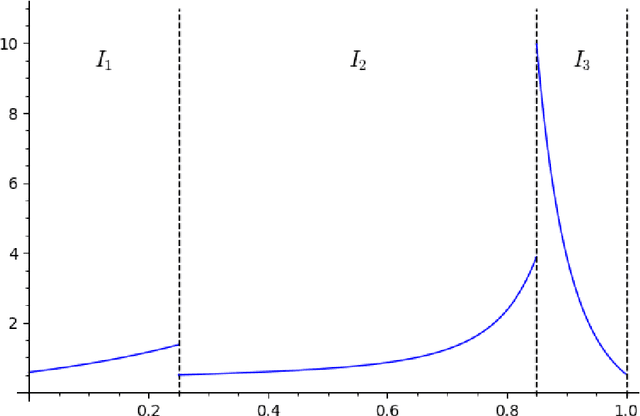
We study the group testing problem where the goal is to identify a set of k infected individuals carrying a rare disease within a population of size n, based on the outcomes of pooled tests which return positive whenever there is at least one infected individual in the tested group. We consider two different simple random procedures for assigning individuals to tests: the constant-column design and Bernoulli design. Our first set of results concerns the fundamental statistical limits. For the constant-column design, we give a new information-theoretic lower bound which implies that the proportion of correctly identifiable infected individuals undergoes a sharp "all-or-nothing" phase transition when the number of tests crosses a particular threshold. For the Bernoulli design, we determine the precise number of tests required to solve the associated detection problem (where the goal is to distinguish between a group testing instance and pure noise), improving both the upper and lower bounds of Truong, Aldridge, and Scarlett (2020). For both group testing models, we also study the power of computationally efficient (polynomial-time) inference procedures. We determine the precise number of tests required for the class of low-degree polynomial algorithms to solve the detection problem. This provides evidence for an inherent computational-statistical gap in both the detection and recovery problems at small sparsity levels. Notably, our evidence is contrary to that of Iliopoulos and Zadik (2021), who predicted the absence of a computational-statistical gap in the Bernoulli design.
A Span Extraction Approach for Information Extraction on Visually-Rich Documents
Jun 02, 2021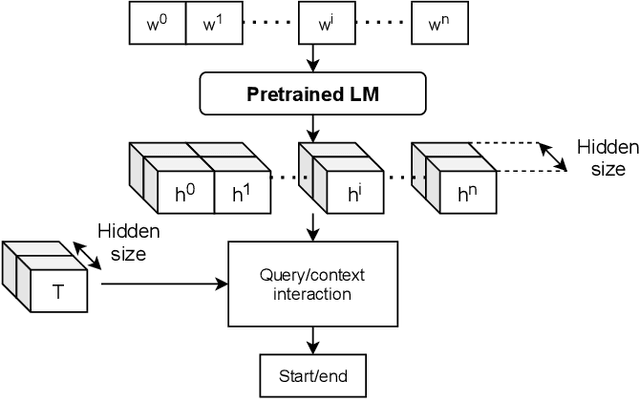

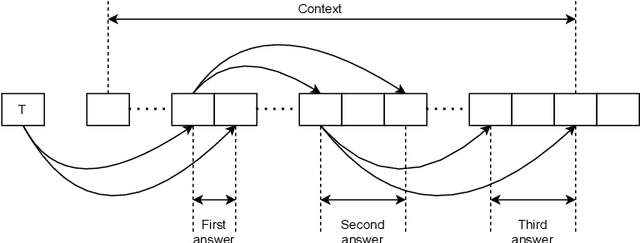

Information extraction (IE) from visually-rich documents (VRDs) has achieved SOTA performance recently thanks to the adaptation of Transformer-based language models, which demonstrates great potential of pre-training methods. In this paper, we present a new approach to improve the capability of language model pre-training on VRDs. Firstly, we introduce a new IE model that is query-based and employs the span extraction formulation instead of the commonly used sequence labelling approach. Secondly, to further extend the span extraction formulation, we propose a new training task which focuses on modelling the relationships between semantic entities within a document. This task enables the spans to be extracted recursively and can be used as both a pre-training objective as well as an IE downstream task. Evaluation on various datasets of popular business documents (invoices, receipts) shows that our proposed method can improve the performance of existing models significantly, while providing a mechanism to accumulate model knowledge from multiple downstream IE tasks.
A Framework for Controlling Multi-Robot Systems Using Bayesian Optimization and Linear Combination of Vectors
Mar 23, 2022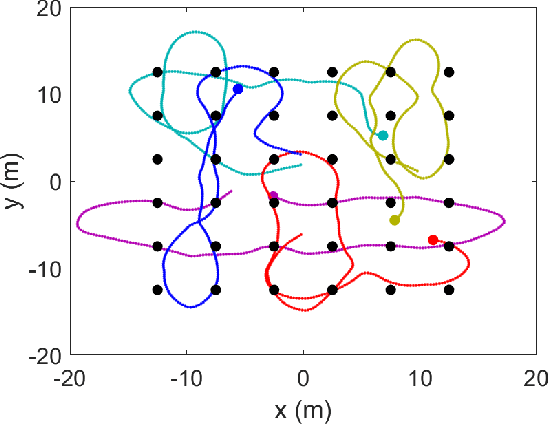
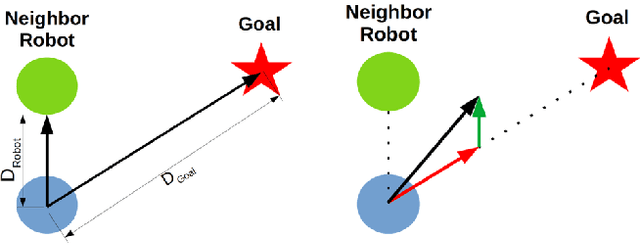
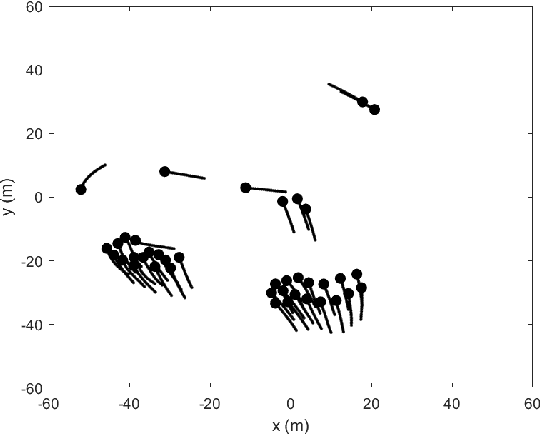
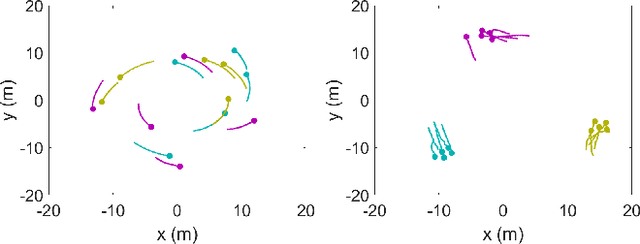
We propose a general framework for creating parameterized control schemes for decentralized multi-robot systems. A variety of tasks can be seen in the decentralized multi-robot literature, each with many possible control schemes. For several of them, the agents choose control velocities using algorithms that extract information from the environment and combine that information in meaningful ways. From this basic formation, a framework is proposed that classifies each robots' measurement information as sets of relevant scalars and vectors and creates a linear combination of the measured vector sets. Along with an optimizable parameter set, the scalar measurements are used to generate the coefficients for the linear combination. With this framework and Bayesian optimization, we can create effective control systems for several multi-robot tasks, including cohesion and segregation, pattern formation, and searching/foraging.
DialoKG: Knowledge-Structure Aware Task-Oriented Dialogue Generation
Apr 19, 2022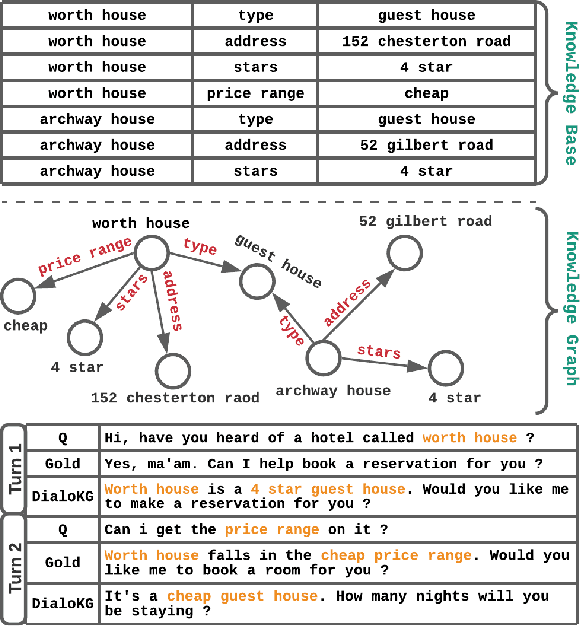

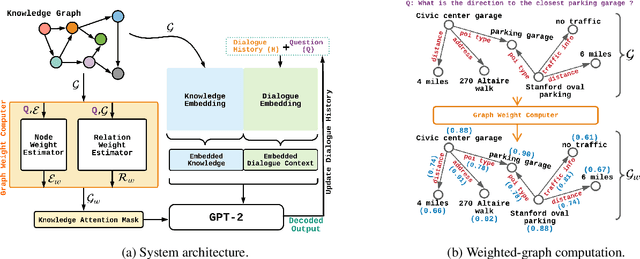
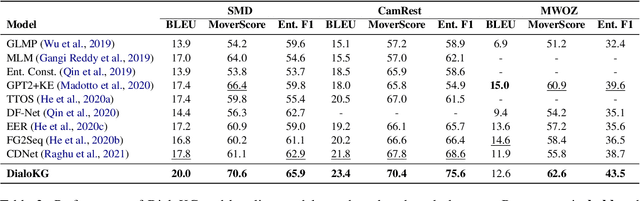
Task-oriented dialogue generation is challenging since the underlying knowledge is often dynamic and effectively incorporating knowledge into the learning process is hard. It is particularly challenging to generate both human-like and informative responses in this setting. Recent research primarily focused on various knowledge distillation methods where the underlying relationship between the facts in a knowledge base is not effectively captured. In this paper, we go one step further and demonstrate how the structural information of a knowledge graph can improve the system's inference capabilities. Specifically, we propose DialoKG, a novel task-oriented dialogue system that effectively incorporates knowledge into a language model. Our proposed system views relational knowledge as a knowledge graph and introduces (1) a structure-aware knowledge embedding technique, and (2) a knowledge graph-weighted attention masking strategy to facilitate the system selecting relevant information during the dialogue generation. An empirical evaluation demonstrates the effectiveness of DialoKG over state-of-the-art methods on several standard benchmark datasets.
Bayesian Federated Learning via Predictive Distribution Distillation
Jun 15, 2022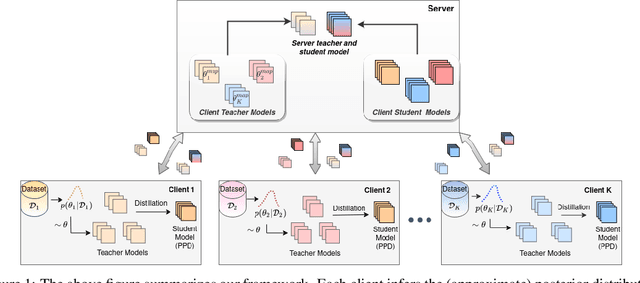
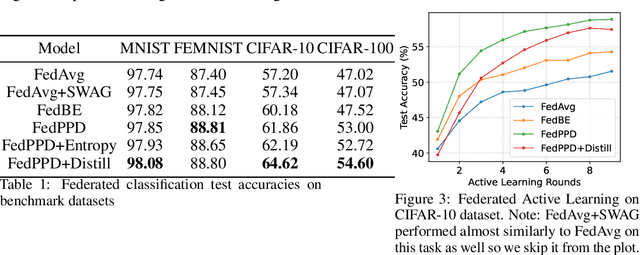
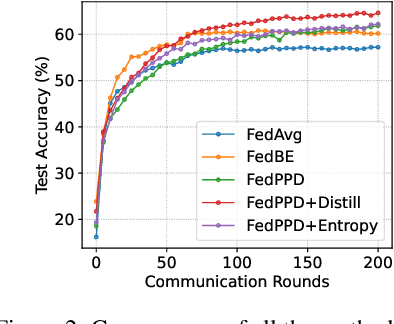
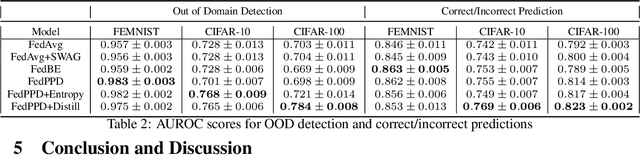
For most existing federated learning algorithms, each round consists of minimizing a loss function at each client to learn an optimal model at the client, followed by aggregating these client models at the server. Point estimation of the model parameters at the clients does not take into account the uncertainty in the models estimated at each client. In many situations, however, especially in limited data settings, it is beneficial to take into account the uncertainty in the client models for more accurate and robust predictions. Uncertainty also provides useful information for other important tasks, such as active learning and out-of-distribution (OOD) detection. We present a framework for Bayesian federated learning where each client infers the posterior predictive distribution using its training data and present various ways to aggregate these client-specific predictive distributions at the server. Since communicating and aggregating predictive distributions can be challenging and expensive, our approach is based on distilling each client's predictive distribution into a single deep neural network. This enables us to leverage advances in standard federated learning to Bayesian federated learning as well. Unlike some recent works that have tried to estimate model uncertainty of each client, our work also does not make any restrictive assumptions, such as the form of the client's posterior distribution. We evaluate our approach on classification in federated setting, as well as active learning and OOD detection in federated settings, on which our approach outperforms various existing federated learning baselines.
Spatially-Preserving Flattening for Location-Aware Classification of Findings in Chest X-Rays
Apr 19, 2022
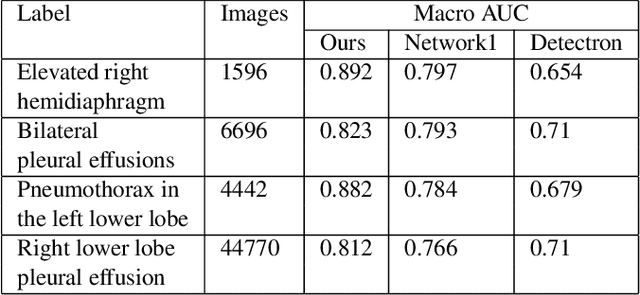

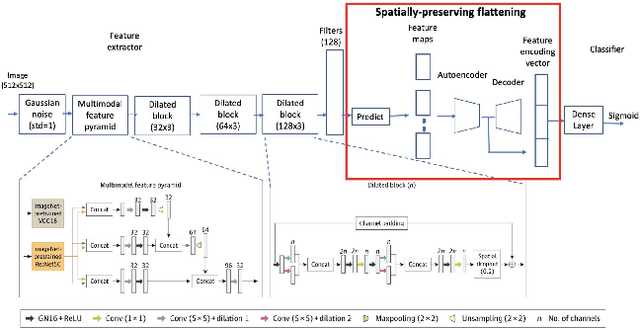
Chest X-rays have become the focus of vigorous deep learning research in recent years due to the availability of large labeled datasets. While classification of anomalous findings is now possible, ensuring that they are correctly localized still remains challenging, as this requires recognition of anomalies within anatomical regions. Existing deep learning networks for fine-grained anomaly classification learn location-specific findings using architectures where the location and spatial contiguity information is lost during the flattening step before classification. In this paper, we present a new spatially preserving deep learning network that preserves location and shape information through auto-encoding of feature maps during flattening. The feature maps, auto-encoder and classifier are then trained in an end-to-end fashion to enable location aware classification of findings in chest X-rays. Results are shown on a large multi-hospital chest X-ray dataset indicating a significant improvement in the quality of finding classification over state-of-the-art methods.
* 5 pages, Paper presented as a poster at the IEEE International Symposium on Biomedical Imaging, 2022, Paper Number 828
Enforcing Morphological Information in Fully Convolutional Networks to Improve Cell Instance Segmentation in Fluorescence Microscopy Images
Jun 10, 2021
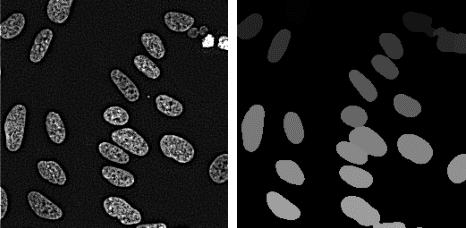
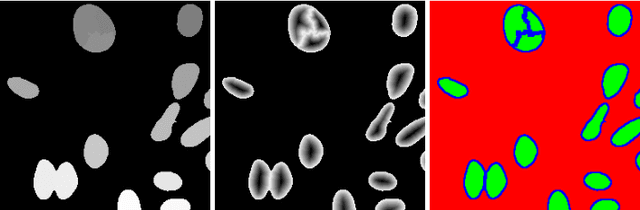
Cell instance segmentation in fluorescence microscopy images is becoming essential for cancer dynamics and prognosis. Data extracted from cancer dynamics allows to understand and accurately model different metabolic processes such as proliferation. This enables customized and more precise cancer treatments. However, accurate cell instance segmentation, necessary for further cell tracking and behavior analysis, is still challenging in scenarios with high cell concentration and overlapping edges. Within this framework, we propose a novel cell instance segmentation approach based on the well-known U-Net architecture. To enforce the learning of morphological information per pixel, a deep distance transformer (DDT) acts as a back-bone model. The DDT output is subsequently used to train a top-model. The following top-models are considered: a three-class (\emph{e.g.,} foreground, background and cell border) U-net, and a watershed transform. The obtained results suggest a performance boost over traditional U-Net architectures. This opens an interesting research line around the idea of injecting morphological information into a fully convolutional model.
A Semantic Consistency Feature Alignment Object Detection Model Based on Mixed-Class Distribution Metrics
Jun 12, 2022
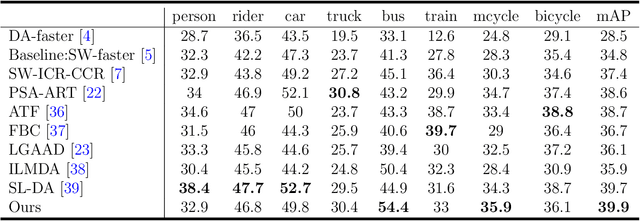
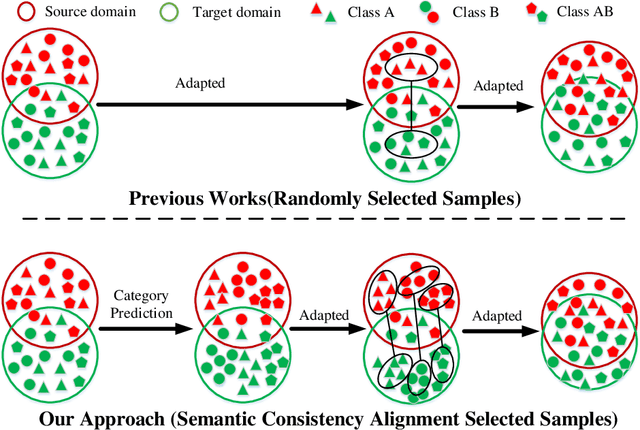
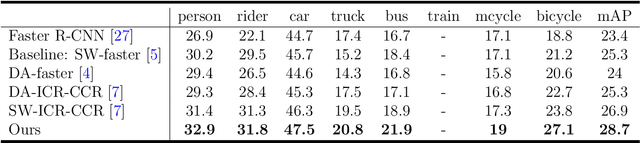
Unsupervised domain adaptation is critical in various computer vision tasks, such as object detection, instance segmentation, etc. They attempt to reduce domain bias-induced performance degradation while also promoting model application speed. Previous works in domain adaptation object detection attempt to align image-level and instance-level shifts to eventually minimize the domain discrepancy, but they may align single-class features to mixed-class features in image-level domain adaptation because each image in the object detection task may be more than one class and object. In order to achieve single-class with single-class alignment and mixed-class with mixed-class alignment, we treat the mixed-class of the feature as a new class and propose a mixed-classes $H-divergence$ for object detection to achieve homogenous feature alignment and reduce negative transfer. Then, a Semantic Consistency Feature Alignment Model (SCFAM) based on mixed-classes $H-divergence$ was also presented. To improve single-class and mixed-class semantic information and accomplish semantic separation, the SCFAM model proposes Semantic Prediction Models (SPM) and Semantic Bridging Components (SBC). And the weight of the pix domain discriminator loss is then changed based on the SPM result to reduce sample imbalance. Extensive unsupervised domain adaption experiments on widely used datasets illustrate our proposed approach's robust object detection in domain bias settings.
Depression Recognition using Remote Photoplethysmography from Facial Videos
Jun 09, 2022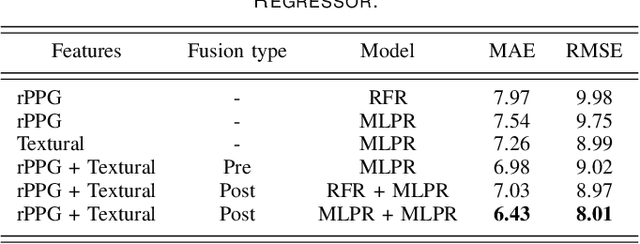
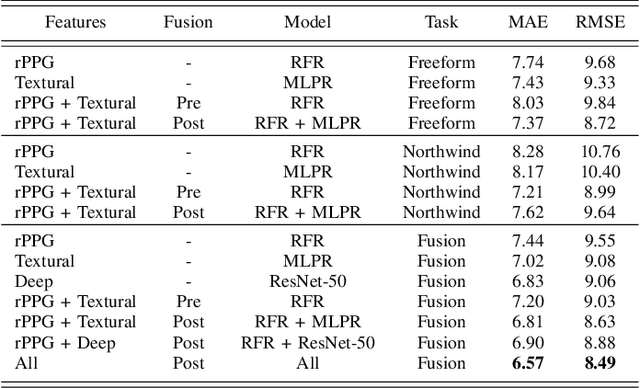
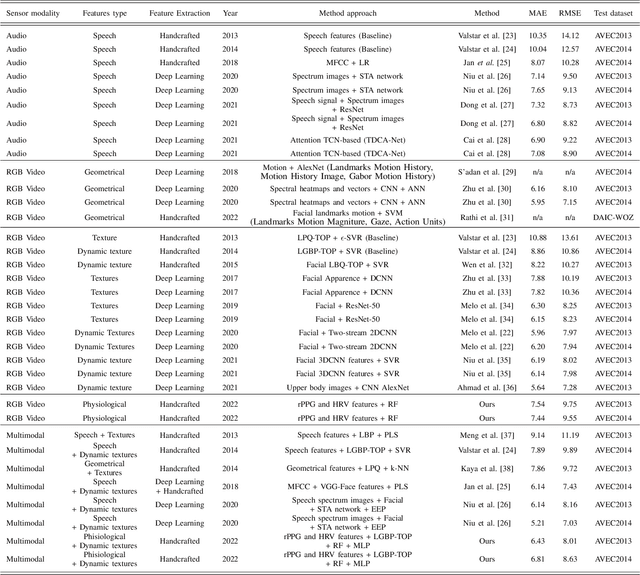
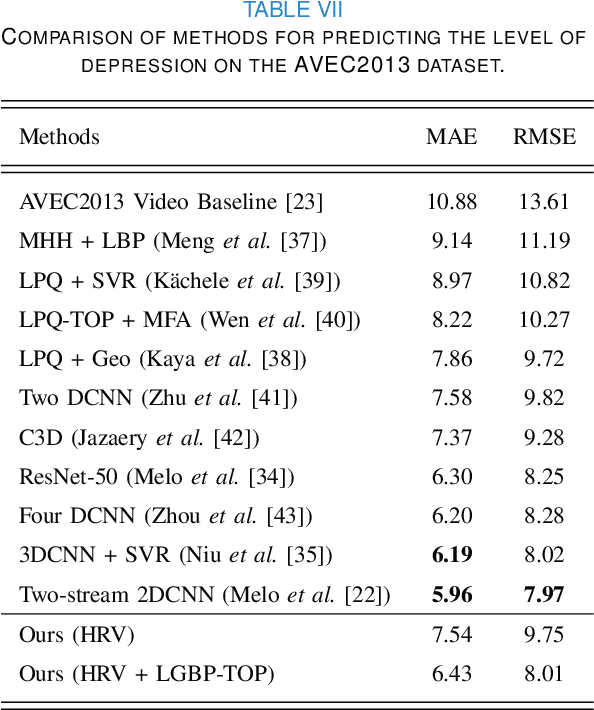
Depression is a mental illness that may be harmful to an individual's health. The detection of mental health disorders in the early stages and a precise diagnosis are critical to avoid social, physiological, or psychological side effects. This work analyzes physiological signals to observe if different depressive states have a noticeable impact on the blood volume pulse (BVP) and the heart rate variability (HRV) response. Although typically, HRV features are calculated from biosignals obtained with contact-based sensors such as wearables, we propose instead a novel scheme that directly extracts them from facial videos, just based on visual information, removing the need for any contact-based device. Our solution is based on a pipeline that is able to extract complete remote photoplethysmography signals (rPPG) in a fully unsupervised manner. We use these rPPG signals to calculate over 60 statistical, geometrical, and physiological features that are further used to train several machine learning regressors to recognize different levels of depression. Experiments on two benchmark datasets indicate that this approach offers comparable results to other audiovisual modalities based on voice or facial expression, potentially complementing them. In addition, the results achieved for the proposed method show promising and solid performance that outperforms hand-engineered methods and is comparable to deep learning-based approaches.