 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semantic Consistency Feature Alignment Object Detection Model Based on Mixed-Class Distribution Metrics
Jun 12, 2022
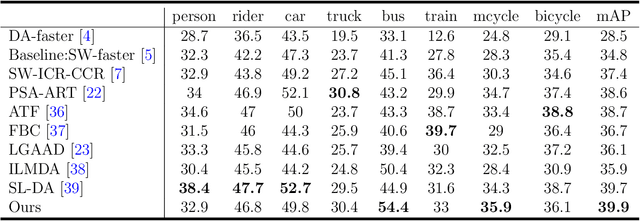
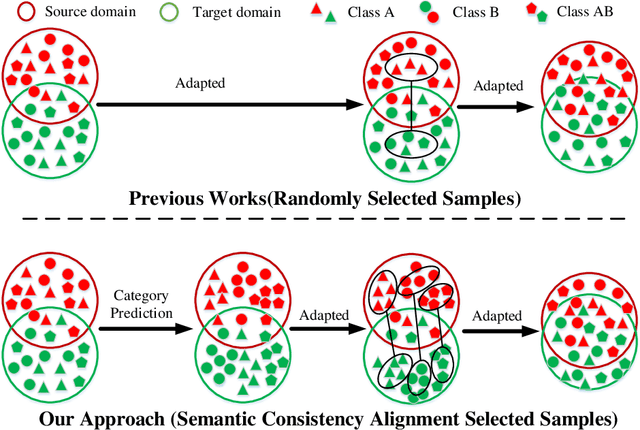
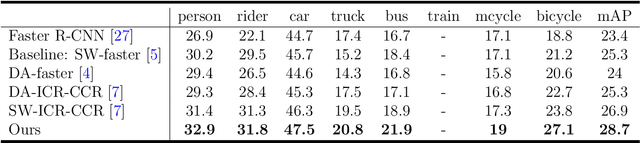
Unsupervised domain adaptation is critical in various computer vision tasks, such as object detection, instance segmentation, etc. They attempt to reduce domain bias-induced performance degradation while also promoting model application speed. Previous works in domain adaptation object detection attempt to align image-level and instance-level shifts to eventually minimize the domain discrepancy, but they may align single-class features to mixed-class features in image-level domain adaptation because each image in the object detection task may be more than one class and object. In order to achieve single-class with single-class alignment and mixed-class with mixed-class alignment, we treat the mixed-class of the feature as a new class and propose a mixed-classes $H-divergence$ for object detection to achieve homogenous feature alignment and reduce negative transfer. Then, a Semantic Consistency Feature Alignment Model (SCFAM) based on mixed-classes $H-divergence$ was also presented. To improve single-class and mixed-class semantic information and accomplish semantic separation, the SCFAM model proposes Semantic Prediction Models (SPM) and Semantic Bridging Components (SBC). And the weight of the pix domain discriminator loss is then changed based on the SPM result to reduce sample imbalance. Extensive unsupervised domain adaption experiments on widely used datasets illustrate our proposed approach's robust object detection in domain bias settings.
Carton dataset synthesis based on foreground texture replacement
Mar 25, 2021



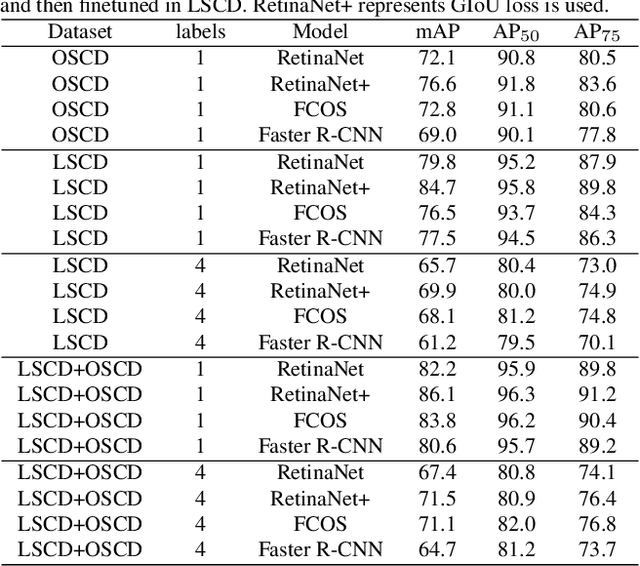
One major impediment in rapidly deploying object detection models for industrial applications is the lack of large annotated datasets. We currently have presented the Sacked Carton Dataset(SCD) that contains carton images from three scenarios such as comprehensive pharmaceutical logistics company(CPLC), e-commerce logistics company(ECLC), fruit market(FM). However, due to domain shift, the model trained with carton datasets from one of the three scenarios in SCD has poor generalization ability when applied to the rest scenarios. To solve this problem, a novel image synthesis method is proposed to replace the foreground texture of the source datasets with the foreground instance texture of the target datasets. This method can greatly augment the target datasets and improve the model's performance. We firstly propose a surfaces segmentation algorithm to identify the different surfaces of the carton instance. Secondly, a contour reconstruction algorithm is proposed to solve the problem of occlusion, truncation, and incomplete contour of carton instances. Finally, the Gaussian fusion algorithm is used to fuse the background from the source datasets with the foreground from the target datasets. The novel image synthesis method can largely boost AP by at least $4.3\%\sim6.5\%$ on RetinaNet and $3.4\%\sim6.8\%$ on Faster R-CNN for the target domain. And on the source domain, the performance AP can be improved by $1.7\%\sim2\%$ on RetinaNet and $0.9\%\sim1.5\%$ on Faster R-CNN. Code is available at https://github.com/hustgetlijun/RCAN.
Gaussian Guided IoU: A Better Metric for Balanced Learning on Object Detection
Mar 25, 2021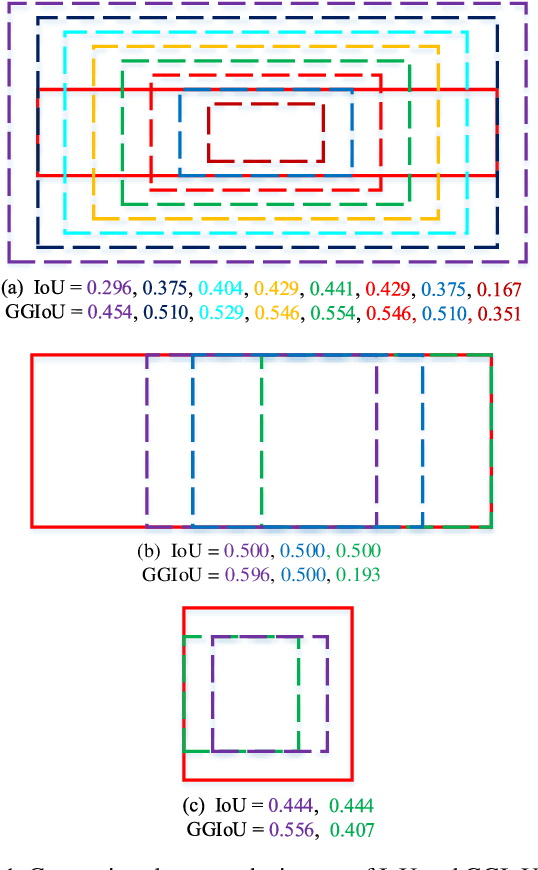
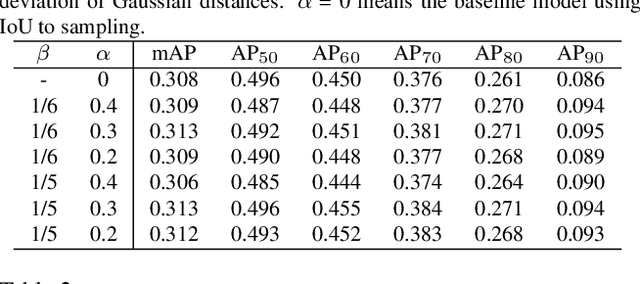
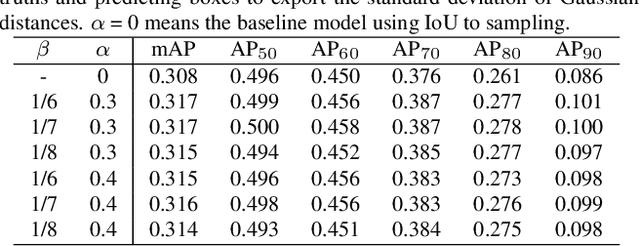
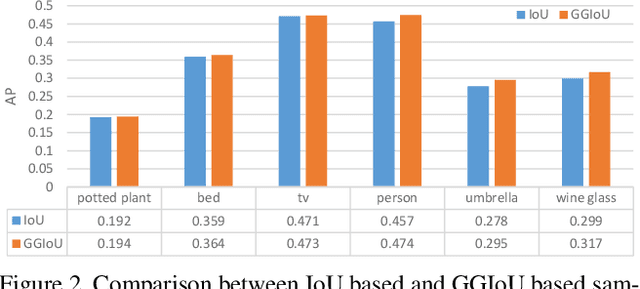
For most of the anchor-based detectors, Intersection over Union(IoU) is widely utilized to assign targets for the anchors during training. However, IoU pays insufficient attention to the closeness of the anchor's center to the truth box's center. This results in two problems: (1) only one anchor is assigned to most of the slender objects which leads to insufficient supervision information for the slender objects during training and the performance on the slender objects is hurt; (2) IoU can not accurately represent the alignment degree between the receptive field of the feature at the anchor's center and the object. Thus during training, some features whose receptive field aligns better with objects are missing while some features whose receptive field aligns worse with objects are adopted. This hurts the localization accuracy of models. To solve these problems, we firstly design Gaussian Guided IoU(GGIoU) which focuses more attention on the closeness of the anchor's center to the truth box's center. Then we propose GGIoU-balanced learning method including GGIoU-guided assignment strategy and GGIoU-balanced localization loss. The method can assign multiple anchors for each slender object and bias the training process to the features well-aligned with objects. Extensive experiments on the popular benchmarks such as PASCAL VOC and MS COCO demonstrate GGIoU-balanced learning can solve the above problems and substantially improve the performance of the object detection model, especially in the localization accuracy.
SCD: A Stacked Carton Dataset for Detection and Segmentation
Feb 25, 2021
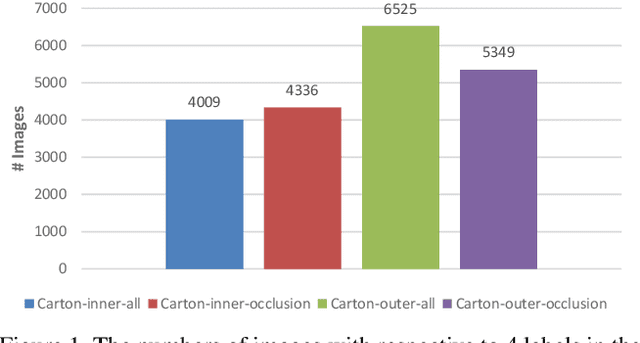
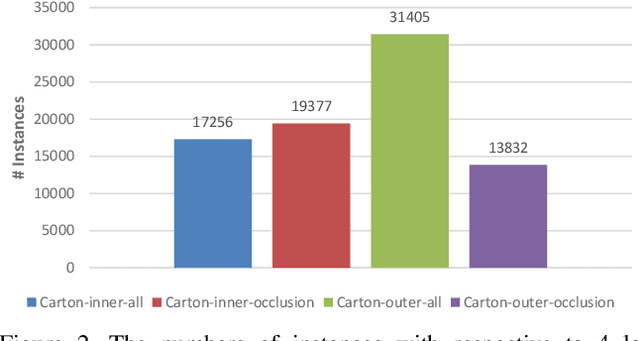
Carton detection is an important technique in the automatic logistics system and can be applied to many applications such as the stacking and unstacking of cartons, the unloading of cartons in the containers. However, there is no public large-scale carton dataset for the research community to train and evaluate the carton detection models up to now, which hinders the development of carton detection. In this paper, we present a large-scale carton dataset named Stacked Carton Dataset(SCD) with the goal of advancing the state-of-the-art in carton detection. Images are collected from the internet and several warehourses, and objects are labeled using per-instance segmentation for precise localization. There are totally 250,000 instance masks from 16,136 images. In addition, we design a carton detector based on RetinaNet by embedding Offset Prediction between Classification and Localization module(OPCL) and Boundary Guided Supervision module(BGS). OPCL alleviates the imbalance problem between classification and localization quality which boosts AP by 3.1% - 4.7% on SCD while BGS guides the detector to pay more attention to boundary information of cartons and decouple repeated carton textures. To demonstrate the generalization of OPCL to other datasets, we conduct extensive experiments on MS COCO and PASCAL VOC. The improvement of AP on MS COCO and PASCAL VOC is 1.8% - 2.2% and 3.4% - 4.3% respectively.