 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LaMemo: Language Modeling with Look-Ahead Memory
Apr 26, 2022
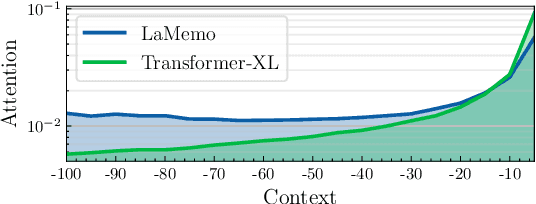

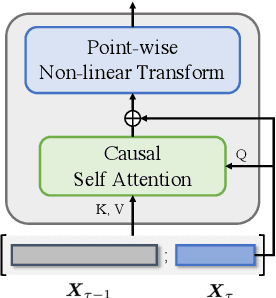
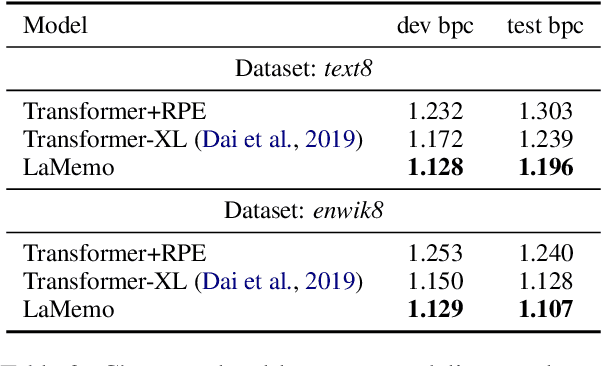
Although Transformers with fully connected self-attentions are powerful to model long-term dependencies, they are struggling to scale to long texts with thousands of words in language modeling. One of the solutions is to equip the model with a recurrence memory. However, existing approaches directly reuse hidden states from the previous segment that encodes contexts in a uni-directional way. As a result, this prohibits the memory to dynamically interact with the current context that provides up-to-date information for token prediction. To remedy this issue, we propose Look-Ahead Memory (LaMemo) that enhances the recurrence memory by incrementally attending to the right-side tokens, and interpolating with the old memory states to maintain long-term information in the history. LaMemo embraces bi-directional attention and segment recurrence with an additional computation overhead only linearly proportional to the memory length. Experiments on widely used language modeling benchmarks demonstrate its superiority over the baselines equipped with different types of memory.
UNeRF: Time and Memory Conscious U-Shaped Network for Training Neural Radiance Fields
Jun 23, 2022
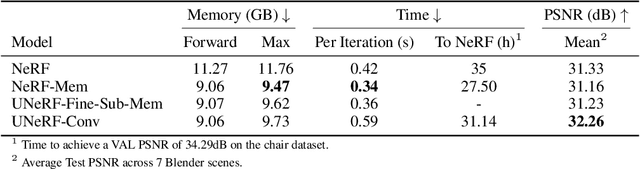
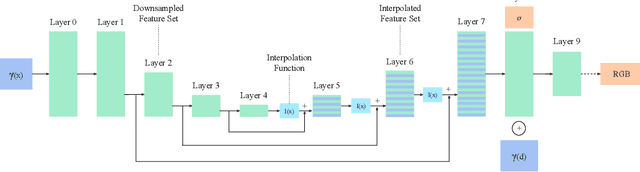

Neural Radiance Fields (NeRFs) increase reconstruction detail for novel view synthesis and scene reconstruction, with applications ranging from large static scenes to dynamic human motion. However, the increased resolution and model-free nature of such neural fields come at the cost of high training times and excessive memory requirements. Recent advances improve the inference time by using complementary data structures yet these methods are ill-suited for dynamic scenes and often increase memory consumption. Little has been done to reduce the resources required at training time. We propose a method to exploit the redundancy of NeRF's sample-based computations by partially sharing evaluations across neighboring sample points. Our UNeRF architecture is inspired by the UNet, where spatial resolution is reduced in the middle of the network and information is shared between adjacent samples. Although this change violates the strict and conscious separation of view-dependent appearance and view-independent density estimation in the NeRF method, we show that it improves novel view synthesis. We also introduce an alternative subsampling strategy which shares computation while minimizing any violation of view invariance. UNeRF is a plug-in module for the original NeRF network. Our major contributions include reduction of the memory footprint, improved accuracy, and reduced amortized processing time both during training and inference. With only weak assumptions on locality, we achieve improved resource utilization on a variety of neural radiance fields tasks. We demonstrate applications to the novel view synthesis of static scenes as well as dynamic human shape and motion.
Fully Privacy-Preserving Federated Representation Learning via Secure Embedding Aggregation
Jun 18, 2022
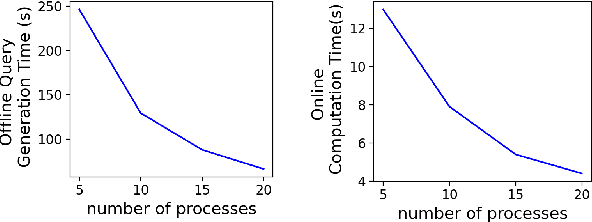
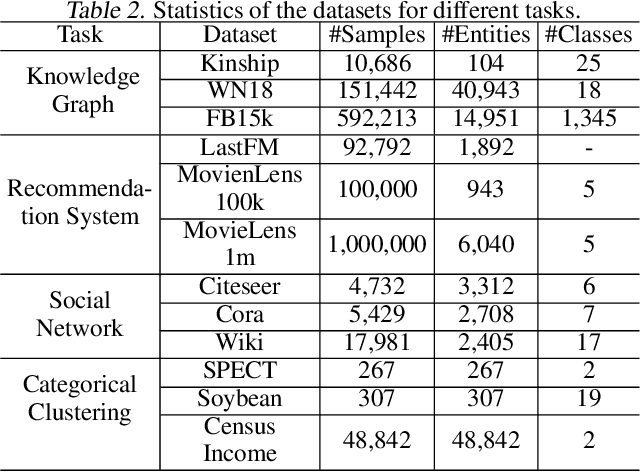
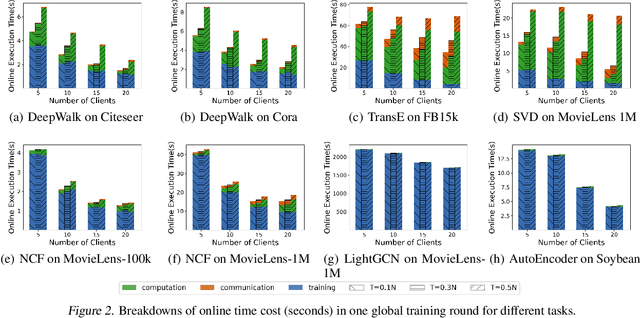
We consider a federated representation learning framework, where with the assistance of a central server, a group of $N$ distributed clients train collaboratively over their private data, for the representations (or embeddings) of a set of entities (e.g., users in a social network). Under this framework, for the key step of aggregating local embeddings trained at the clients in a private manner, we develop a secure embedding aggregation protocol named SecEA, which provides information-theoretical privacy guarantees for the set of entities and the corresponding embeddings at each client $simultaneously$, against a curious server and up to $T < N/2$ colluding clients. As the first step of SecEA, the federated learning system performs a private entity union, for each client to learn all the entities in the system without knowing which entities belong to which clients. In each aggregation round, the local embeddings are secretly shared among the clients using Lagrange interpolation, and then each client constructs coded queries to retrieve the aggregated embeddings for the intended entities. We perform comprehensive experiments on various representation learning tasks to evaluate the utility and efficiency of SecEA, and empirically demonstrate that compared with embedding aggregation protocols without (or with weaker) privacy guarantees, SecEA incurs negligible performance loss (within 5%); and the additional computation latency of SecEA diminishes for training deeper models on larger datasets.
Multi-Modal Mutual Information (MuMMI) Training for Robust Self-Supervised Deep Reinforcement Learning
Jul 06, 2021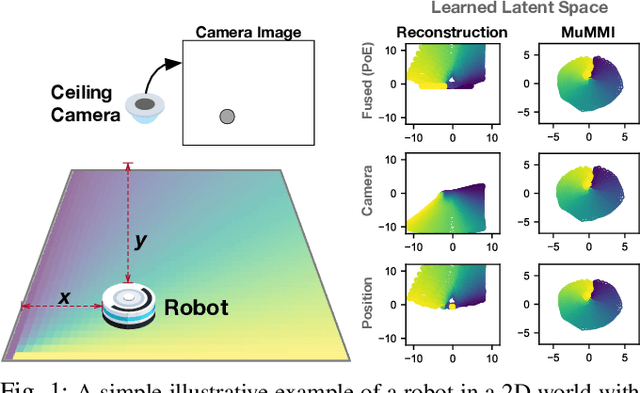
This work focuses on learning useful and robust deep world models using multiple, possibly unreliable, sensors. We find that current methods do not sufficiently encourage a shared representation between modalities; this can cause poor performance on downstream tasks and over-reliance on specific sensors. As a solution, we contribute a new multi-modal deep latent state-space model, trained using a mutual information lower-bound. The key innovation is a specially-designed density ratio estimator that encourages consistency between the latent codes of each modality. We tasked our method to learn policies (in a self-supervised manner) on multi-modal Natural MuJoCo benchmarks and a challenging Table Wiping task. Experiments show our method significantly outperforms state-of-the-art deep reinforcement learning methods, particularly in the presence of missing observations.
APPFLChain: A Privacy Protection Distributed Artificial-Intelligence Architecture Based on Federated Learning and Consortium Blockchain
Jun 26, 2022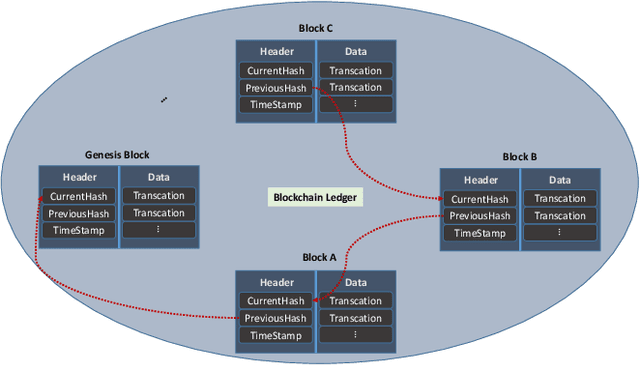
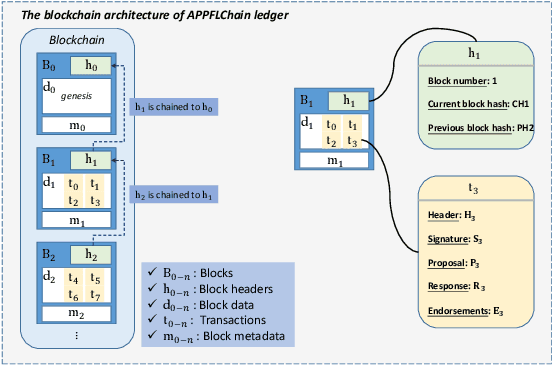
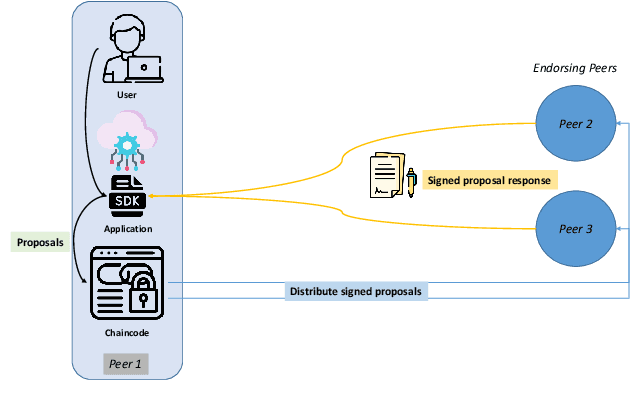
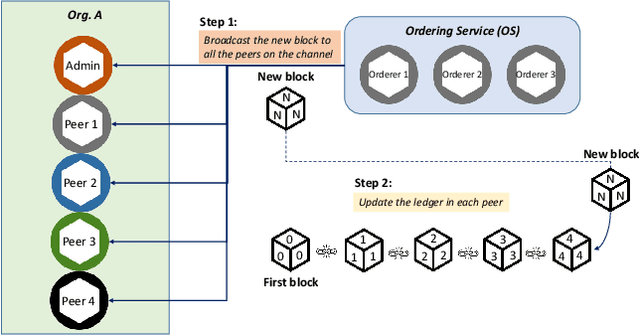
Recent research in Internet of things has been widely applied for industrial practices, fostering the exponential growth of data and connected devices. Henceforth, data-driven AI models would be accessed by different parties through certain data-sharing policies. However, most of the current training procedures rely on the centralized data-collection strategy and a single computational server. However, such a centralized scheme may lead to many issues. Customer data stored in a centralized database may be tampered with so the provenance and authenticity of data cannot be justified. Once the aforementioned security concerns occur, the credibility of the trained AI models would be questionable and even unfavorable outcomes might be produced at the test stage. Lately, blockchain and AI, the two core technologies in Industry 4.0 and Web 3.0, have been explored to facilitate the decentralized AI training strategy. To serve on this very purpose, we propose a new system architecture called APPFLChain, namely an integrated architecture of a Hyperledger Fabric-based blockchain and a federated-learning paradigm. Our proposed new system allows different parties to jointly train AI models and their customers or stakeholders are connected by a consortium blockchain-based network. Our new system can maintain a high degree of security and privacy as users do not need to share sensitive personal information to the server. For numerical evaluation, we simulate a real-world scenario to illustrate the whole operational process of APPFLChain. Simulation results show that taking advantage of the characteristics of consortium blockchain and federated learning, APPFLChain can demonstrate favorable properties including untamperability, traceability, privacy protection, and reliable decision-making.
A Novel Three-Dimensional Navigation Method for the Visually Impaired
Jun 20, 2022
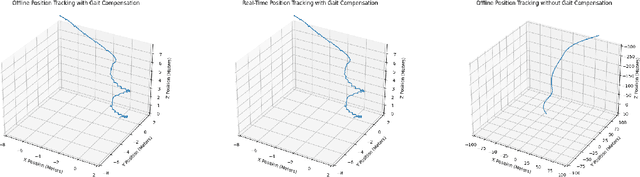
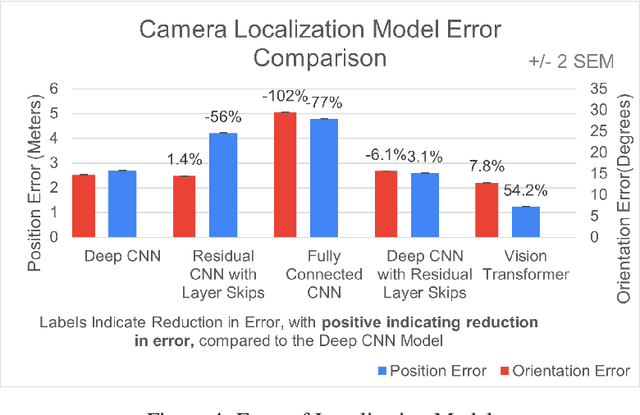

According to the World Health Organization, visual impairment is estimated to affect approximately 2.2 billion people worldwide. The visually impaired must currently rely on navigational aids to replace their sense of sight, like a white cane or GPS (Global Positioning System) based navigation, both of which fail to work well indoors. The white cane cannot be used to determine a user's position within a room, while GPS can often lose connection indoors and does not provide orientation information, making both approaches unsuitable for indoor use. Therefore, this research seeks to develop a 3D-imaging solution that enables contactless navigation through a complex indoor environment. The device can pinpoint a user's position and orientation with 31% less error compared to previous approaches while requiring only 53.1% of the memory, and processing 125% faster. The device can also detect obstacles with 60.2% more accuracy than the previous state-of-the-art models while requiring only 41% of the memory and processing 260% faster. When testing with human participants, the device allows for a 94.5% reduction in collisions with obstacles in the environment and allows for a 48.3% increase in walking speed, showing that my device enables safer and more rapid navigation for the visually impaired. All in all, this research demonstrates a 3D-based navigation system for the visually impaired. The approach can be used by a wide variety of mobile low-power devices, like cell phones, ensuring this research remains accessible to all.
FitGAN: Fit- and Shape-Realistic Generative Adversarial Networks for Fashion
Jun 23, 2022
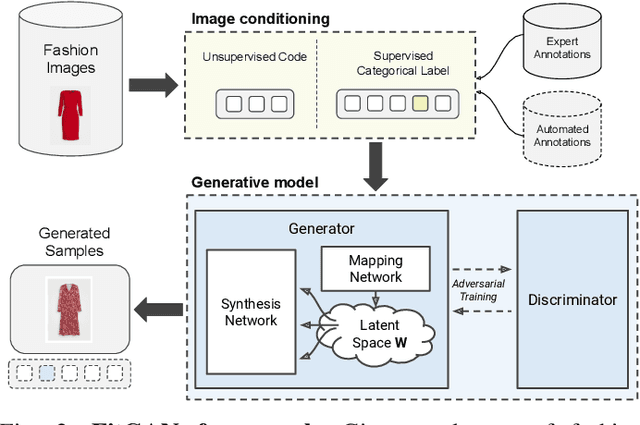


Amidst the rapid growth of fashion e-commerce, remote fitting of fashion articles remains a complex and challenging problem and a main driver of customers' frustration. Despite the recent advances in 3D virtual try-on solutions, such approaches still remain limited to a very narrow - if not only a handful - selection of articles, and often for only one size of those fashion items. Other state-of-the-art approaches that aim to support customers find what fits them online mostly require a high level of customer engagement and privacy-sensitive data (such as height, weight, age, gender, belly shape, etc.), or alternatively need images of customers' bodies in tight clothing. They also often lack the ability to produce fit and shape aware visual guidance at scale, coming up short by simply advising which size to order that would best match a customer's physical body attributes, without providing any information on how the garment may fit and look. Contributing towards taking a leap forward and surpassing the limitations of current approaches, we present FitGAN, a generative adversarial model that explicitly accounts for garments' entangled size and fit characteristics of online fashion at scale. Conditioned on the fit and shape of the articles, our model learns disentangled item representations and generates realistic images reflecting the true fit and shape properties of fashion articles. Through experiments on real world data at scale, we demonstrate how our approach is capable of synthesizing visually realistic and diverse fits of fashion items and explore its ability to control fit and shape of images for thousands of online garments.
Convergence of Stein Variational Gradient Descent under a Weaker Smoothness Condition
Jun 01, 2022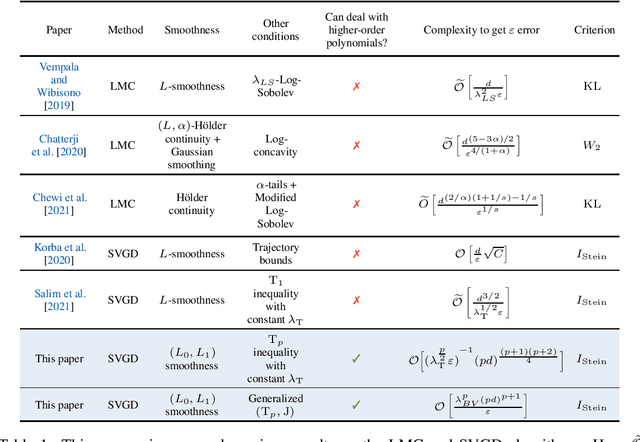
Stein Variational Gradient Descent (SVGD) is an important alternative to the Langevin-type algorithms for sampling from probability distributions of the form $\pi(x) \propto \exp(-V(x))$. In the existing theory of Langevin-type algorithms and SVGD, the potential function $V$ is often assumed to be $L$-smooth. However, this restrictive condition excludes a large class of potential functions such as polynomials of degree greater than $2$. Our paper studies the convergence of the SVGD algorithm for distributions with $(L_0,L_1)$-smooth potentials. This relaxed smoothness assumption was introduced by Zhang et al. [2019a] for the analysis of gradient clipping algorithms. With the help of trajectory-independent auxiliary conditions, we provide a descent lemma establishing that the algorithm decreases the $\mathrm{KL}$ divergence at each iteration and prove a complexity bound for SVGD in the population limit in terms of the Stein Fisher information.
Proximally Sensitive Error for Anomaly Detection and Feature Learning
Jun 01, 2022
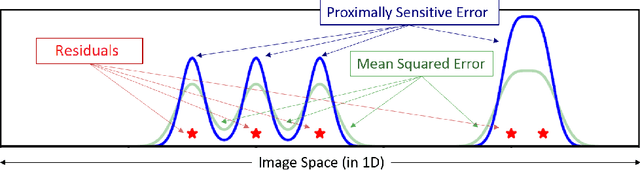
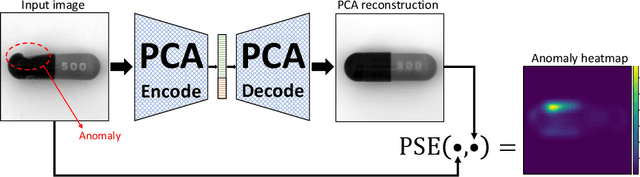
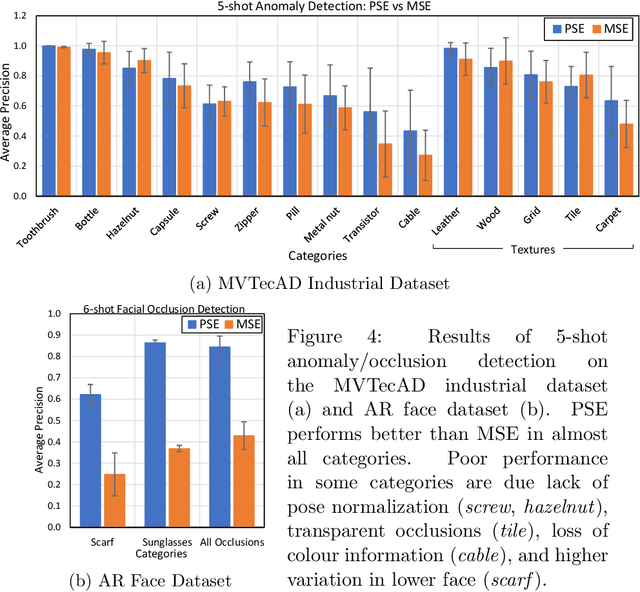
Mean squared error (MSE) is one of the most widely used metrics to expression differences between multi-dimensional entities, including images. However, MSE is not locally sensitive as it does not take into account the spatial arrangement of the (pixel) differences, which matters for structured data types like images. Such spatial arrangements carry information about the source of the differences; therefore, an error function that also incorporates the location of errors can lead to a more meaningful distance measure. We introduce Proximally Sensitive Error (PSE), through which we suggest that a regional emphasis in the error measure can 'highlight' semantic differences between images over syntactic/random deviations. We demonstrate that this emphasis can be leveraged upon for the task of anomaly/occlusion detection. We further explore its utility as a loss function to help a model focus on learning representations of semantic objects instead of minimizing syntactic reconstruction noise.
Energy reconstruction for large liquid scintillator detectors with machine learning techniques: aggregated features approach
Jun 17, 2022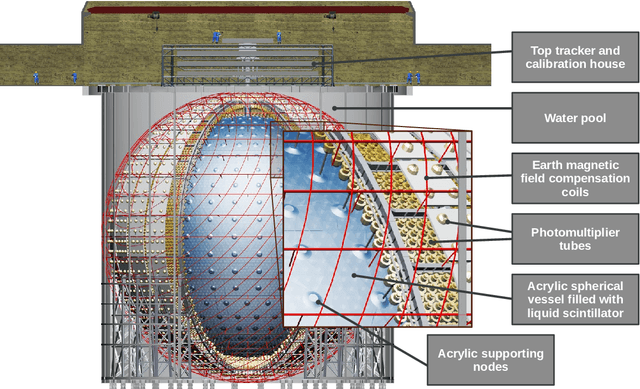
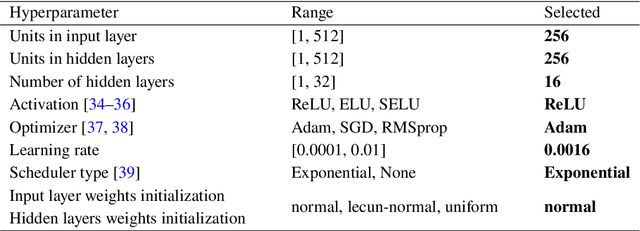
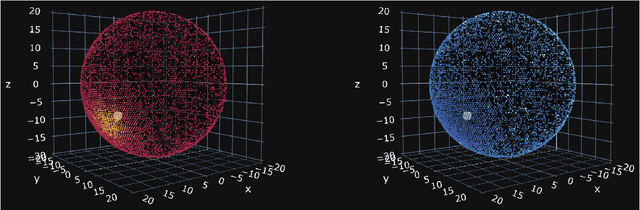

Large scale detectors consisting of a liquid scintillator (LS) target surrounded by an array of photo-multiplier tubes (PMT) are widely used in modern neutrino experiments: Borexino, KamLAND, Daya Bay, Double Chooz, RENO, and upcoming JUNO with its satellite detector TAO. Such apparatuses are able to measure neutrino energy, which can be derived from the amount of light and its spatial and temporal distribution over PMT-channels. However, achieving a fine energy resolution in large scale detectors is challenging. In this work, we present machine learning methods for energy reconstruction in JUNO, the most advanced detector of its type. We focus on positron events in the energy range of 0-10 MeV which corresponds to the main signal in JUNO $-$ neutrinos originated from nuclear reactor cores and detected via an inverse beta-decay channel. We consider Boosted Decision Trees and Fully Connected Deep Neural Network trained on aggregated features, calculated using information collected by PMTs. We describe the details of our feature engineering procedure and show that machine learning models can provide energy resolution $\sigma = 3\%$ at 1 MeV using subsets of engineered features. The dataset for model training and testing is generated by the Monte Carlo method with the official JUNO software. Consideration of calibration sources for evaluation of the reconstruction algorithms performance on real data is also presented.