 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Aggregation with Top-K Sparsification in Decentralized Federated Learning
Jun 09, 2026Secure aggregation is a vital component for mitigating gradient leakage in federated learning, but its communication cost conventionally scales with the gradient dimension. This becomes prohibitive for large models and even more pronounced in decentralized federated learning with limited bandwidth and unreliable nodes. Top-K gradient sparsification is an effective approach to reduce communication by transmitting only a few entries of the full gradient, while maintaining competitive model accuracy. Nevertheless, the top-K entries selected by each user are unpredictable and vary across users, which poses a challenge for efficient sparse secure aggregation. This paper studies information-theoretic secure aggregation with top-K sparsification in decentralized federated learning under user dropouts and user collusion. We propose a communication-efficient sparse secure aggregation scheme that offloads dimension-dependent overhead to an offline phase and protects private gradients using random masks and permutations. Experimental results demonstrate that our scheme preserves accuracy comparable to full-gradient aggregation even with only 1% gradient sparsification, while substantially reducing the communication cost.
The Capacity of Information-Theoretic Secure Aggregation in Federated Learning
Jun 05, 2026Secure aggregation allows a server to aggregate users' local updates while preserving update privacy. Existing information-theoretic problems typically assume that correlated random keys are provided by a trusted third party (TTP) or generated via prescribed groupwise structures, while the communication cost for establishing such correlated keys is often ignored. Consequently, the fundamental limits under general key-distribution mechanisms remain unknown. In this paper, we study the $T$-colluding information-theoretic secure aggregation problem with $N$ users under a general two-phase framework consisting of a key distribution phase and an update aggregation phase. Unlike prior work, we model key distribution through user-to-user communication and allow arbitrary user-generated key-distribution mechanisms, eliminating TTP or prescribed structures. This enables a joint characterization of three resources: randomness for security, key-distribution communication, and aggregation communication. We completely characterize the capacity region among these three resources by constructing a novel secure aggregation scheme together with a matching information-theoretic converse. In particular, we develop an explicit deterministic capacity-achieving construction over any finite field of size at least $N$, whereas most existing schemes either rely on TTP or employ randomized or existential constructions over sufficiently large finite fields. We further show that the optimal performance can be achieved using only pairwise shared keys, enabling implementation via Diffie--Hellman key exchange. Compared with Google's seminal secure aggregation scheme, the proposed scheme requires fewer random masking keys while preserving the same aggregation communication overhead.
Fully Privacy-Preserving Federated Representation Learning via Secure Embedding Aggregation
Jun 18, 2022
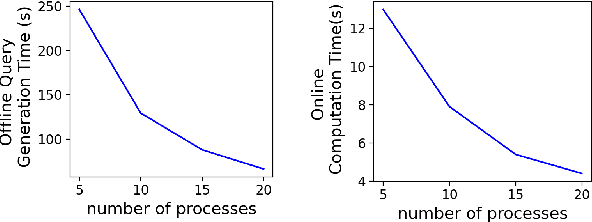
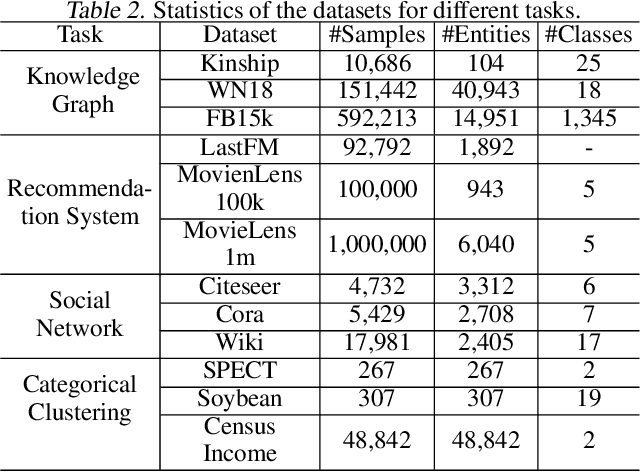
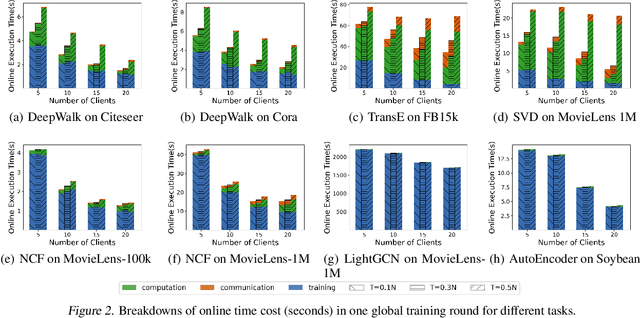
We consider a federated representation learning framework, where with the assistance of a central server, a group of $N$ distributed clients train collaboratively over their private data, for the representations (or embeddings) of a set of entities (e.g., users in a social network). Under this framework, for the key step of aggregating local embeddings trained at the clients in a private manner, we develop a secure embedding aggregation protocol named SecEA, which provides information-theoretical privacy guarantees for the set of entities and the corresponding embeddings at each client $simultaneously$, against a curious server and up to $T < N/2$ colluding clients. As the first step of SecEA, the federated learning system performs a private entity union, for each client to learn all the entities in the system without knowing which entities belong to which clients. In each aggregation round, the local embeddings are secretly shared among the clients using Lagrange interpolation, and then each client constructs coded queries to retrieve the aggregated embeddings for the intended entities. We perform comprehensive experiments on various representation learning tasks to evaluate the utility and efficiency of SecEA, and empirically demonstrate that compared with embedding aggregation protocols without (or with weaker) privacy guarantees, SecEA incurs negligible performance loss (within 5%); and the additional computation latency of SecEA diminishes for training deeper models on larger datasets.
Generalized Lagrange Coded Computing: A Flexible Computation-Communication Tradeoff
Apr 24, 2022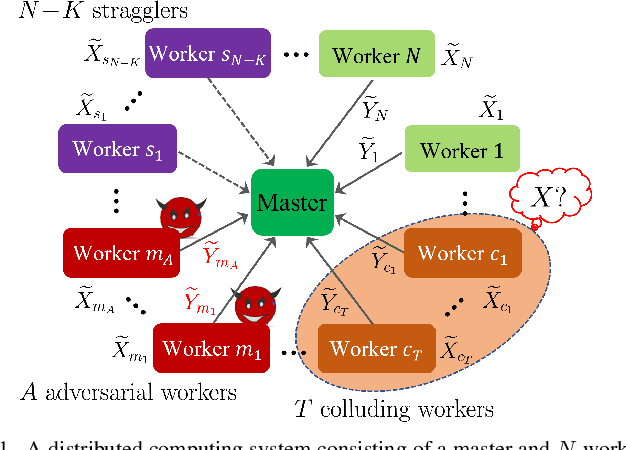
We consider the problem of evaluating arbitrary multivariate polynomials over a massive dataset, in a distributed computing system with a master node and multiple worker nodes. Generalized Lagrange Coded Computing (GLCC) codes are proposed to provide robustness against stragglers who do not return computation results in time, adversarial workers who deliberately modify results for their benefit, and information-theoretic security of the dataset amidst possible collusion of workers. GLCC codes are constructed by first partitioning the dataset into multiple groups, and then encoding the dataset using carefully designed interpolation polynomials, such that interference computation results across groups can be eliminated at the master. Particularly, GLCC codes include the state-of-the-art Lagrange Coded Computing (LCC) codes as a special case, and achieve a more flexible tradeoff between communication and computation overheads in optimizing system efficiency.