 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic Bandits with an Auto-Regressive Temporal Structure
Oct 28, 2022
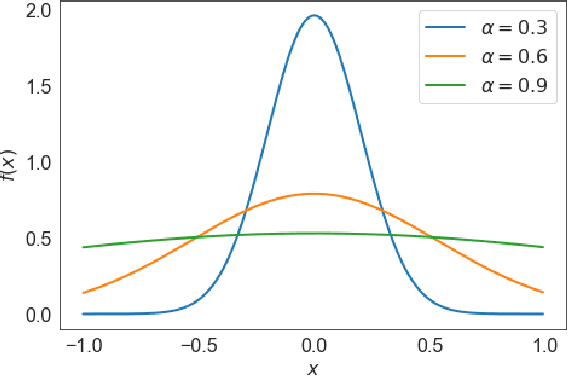
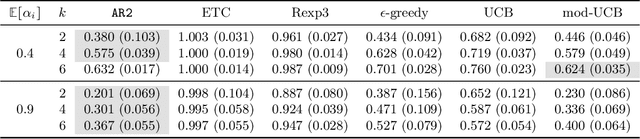
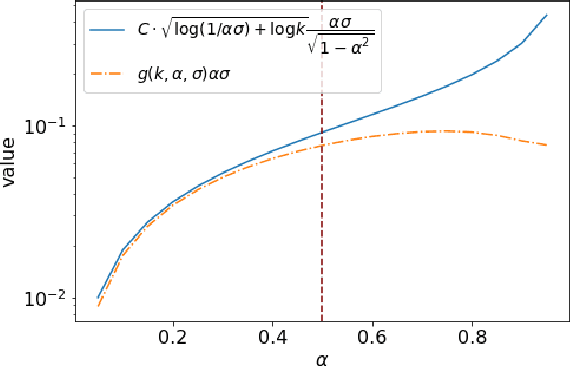
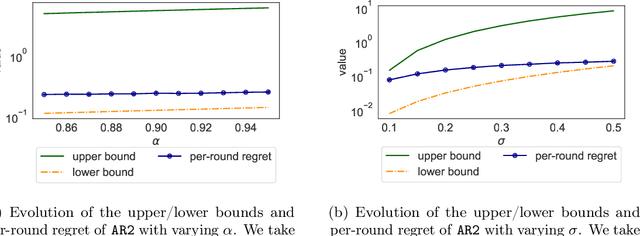
Multi-armed bandit (MAB) problems are mainly studied under two extreme settings known as stochastic and adversarial. These two settings, however, do not capture realistic environments such as search engines and marketing and advertising, in which rewards stochastically change in time. Motivated by that, we introduce and study a dynamic MAB problem with stochastic temporal structure, where the expected reward of each arm is governed by an auto-regressive (AR) model. Due to the dynamic nature of the rewards, simple "explore and commit" policies fail, as all arms have to be explored continuously over time. We formalize this by characterizing a per-round regret lower bound, where the regret is measured against a strong (dynamic) benchmark. We then present an algorithm whose per-round regret almost matches our regret lower bound. Our algorithm relies on two mechanisms: (i) alternating between recently pulled arms and unpulled arms with potential, and (ii) restarting. These mechanisms enable the algorithm to dynamically adapt to changes and discard irrelevant past information at a suitable rate. In numerical studies, we further demonstrate the strength of our algorithm under different types of non-stationary settings.
On the Vulnerability of Data Points under Multiple Membership Inference Attacks and Target Models
Oct 28, 2022
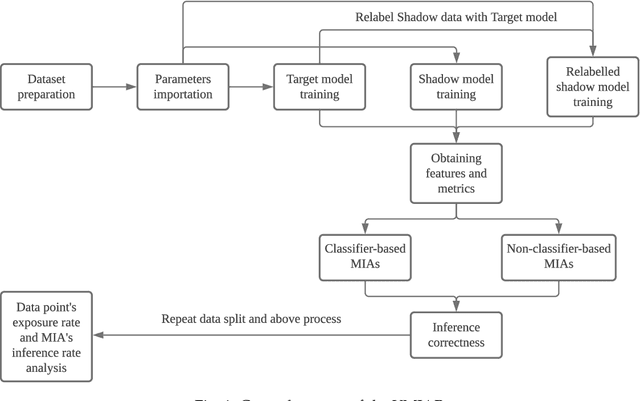
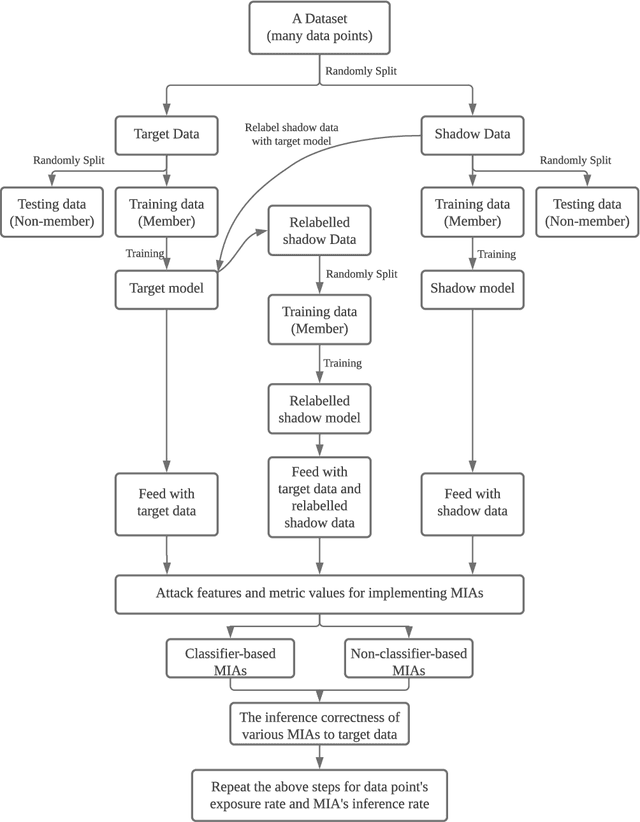
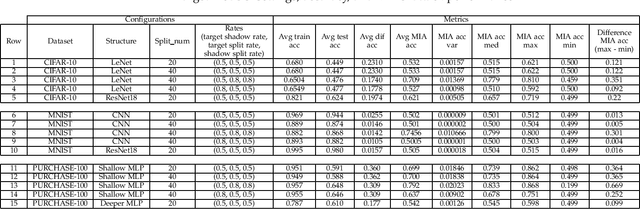
Membership Inference Attacks (MIAs) infer whether a data point is in the training data of a machine learning model. It is a threat while being in the training data is private information of a data point. MIA correctly infers some data points as members or non-members of the training data. Intuitively, data points that MIA accurately detects are vulnerable. Considering those data points may exist in different target models susceptible to multiple MIAs, the vulnerability of data points under multiple MIAs and target models is worth exploring. This paper defines new metrics that can reflect the actual situation of data points' vulnerability and capture vulnerable data points under multiple MIAs and target models. From the analysis, MIA has an inference tendency to some data points despite a low overall inference performance. Additionally, we implement 54 MIAs, whose average attack accuracy ranges from 0.5 to 0.9, to support our analysis with our scalable and flexible platform, Membership Inference Attacks Platform (VMIAP). Furthermore, previous methods are unsuitable for finding vulnerable data points under multiple MIAs and different target models. Finally, we observe that the vulnerability is not characteristic of the data point but related to the MIA and target model.
Local Model Reconstruction Attacks in Federated Learning and their Uses
Oct 28, 2022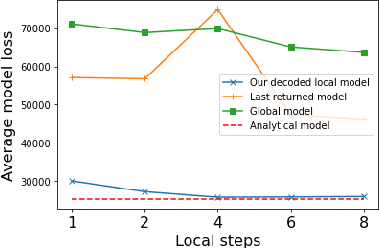

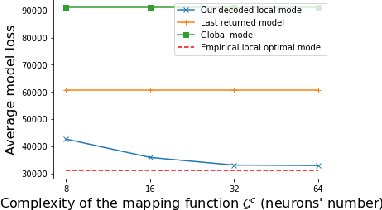
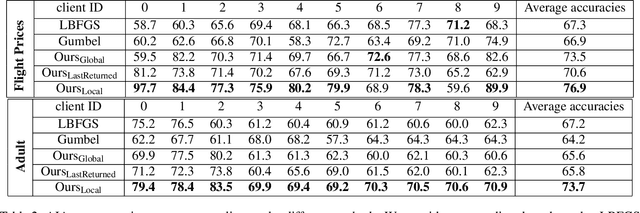
In this paper, we initiate the study of local model reconstruction attacks for federated learning, where a honest-but-curious adversary eavesdrops the messages exchanged between a targeted client and the server, and then reconstructs the local/personalized model of the victim. The local model reconstruction attack allows the adversary to trigger other classical attacks in a more effective way, since the local model only depends on the client's data and can leak more private information than the global model learned by the server. Additionally, we propose a novel model-based attribute inference attack in federated learning leveraging the local model reconstruction attack. We provide an analytical lower-bound for this attribute inference attack. Empirical results using real world datasets confirm that our local reconstruction attack works well for both regression and classification tasks. Moreover, we benchmark our novel attribute inference attack against the state-of-the-art attacks in federated learning. Our attack results in higher reconstruction accuracy especially when the clients' datasets are heterogeneous. Our work provides a new angle for designing powerful and explainable attacks to effectively quantify the privacy risk in FL.
Hyper-Connected Transformer Network for Co-Learning Multi-Modality PET-CT Features
Oct 28, 2022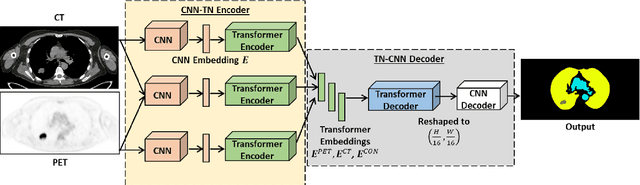

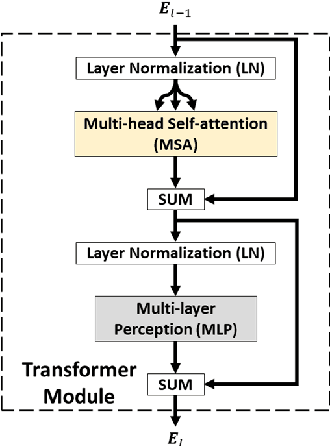
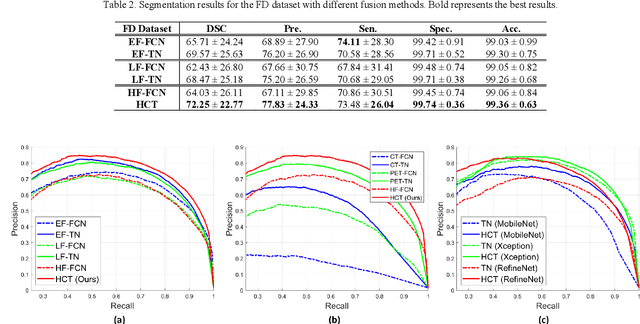
[18F]-Fluorodeoxyglucose (FDG) positron emission tomography - computed tomography (PET-CT) has become the imaging modality of choice for diagnosing many cancers. Co-learning complementary PET-CT imaging features is a fundamental requirement for automatic tumor segmentation and for developing computer aided cancer diagnosis systems. We propose a hyper-connected transformer (HCT) network that integrates a transformer network (TN) with a hyper connected fusion for multi-modality PET-CT images. The TN was leveraged for its ability to provide global dependencies in image feature learning, which was achieved by using image patch embeddings with a self-attention mechanism to capture image-wide contextual information. We extended the single-modality definition of TN with multiple TN based branches to separately extract image features. We introduced a hyper connected fusion to fuse the contextual and complementary image features across multiple transformers in an iterative manner. Our results with two non-small cell lung cancer and soft-tissue sarcoma datasets show that HCT achieved better performance in segmentation accuracy when compared to state-of-the-art methods. We also show that HCT produces consistent performance across various image fusion strategies and network backbones.
A Game Benchmark for Real-Time Human-Swarm Control
Oct 28, 2022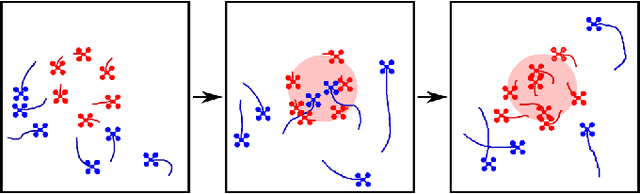
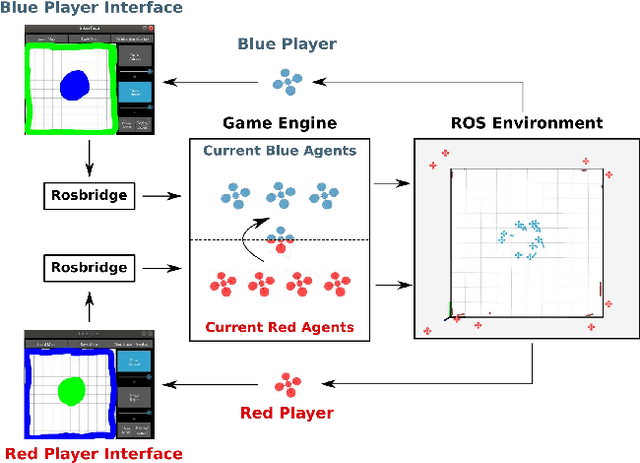
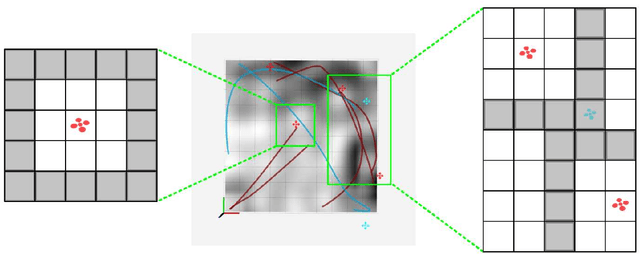

We present a game benchmark for testing human-swarm control algorithms and interfaces in a real-time, high-cadence scenario. Our benchmark consists of a swarm vs. swarm game in a virtual ROS environment in which the goal of the game is to capture all agents from the opposing swarm; the game's high-cadence is a result of the capture rules, which cause agent team sizes to fluctuate rapidly. These rules require players to consider both the number of agents currently at their disposal and the behavior of their opponent's swarm when they plan actions. We demonstrate our game benchmark with a default human-swarm control system that enables a player to interact with their swarm through a high-level touchscreen interface. The touchscreen interface transforms player gestures into swarm control commands via a low-level decentralized ergodic control framework. We compare our default human-swarm control system to a flocking-based control system, and discuss traits that are crucial for swarm control algorithms and interfaces operating in real-time, high-cadence scenarios like our game benchmark. Our game benchmark code is available on Github; more information can be found at https://sites.google.com/view/swarm-game-benchmark.
UX-NET: Filter-and-Process-based Improved U-Net for Real-time Time-domain Audio Separation
Oct 28, 2022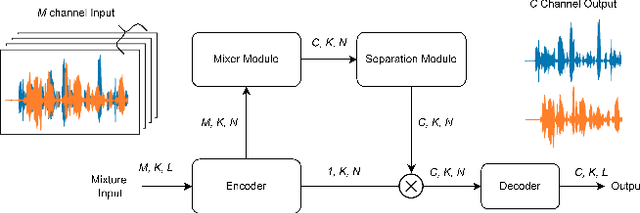
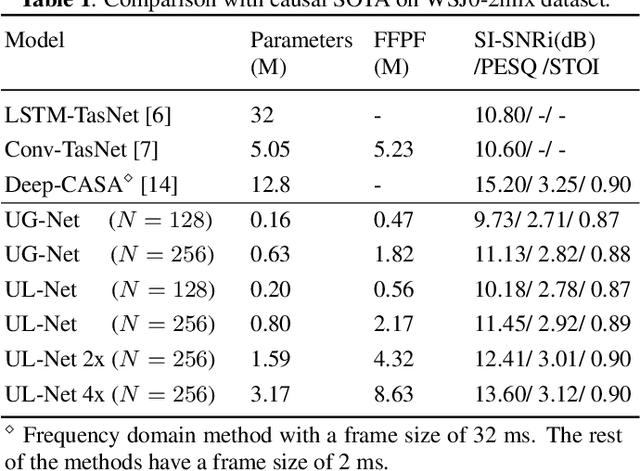
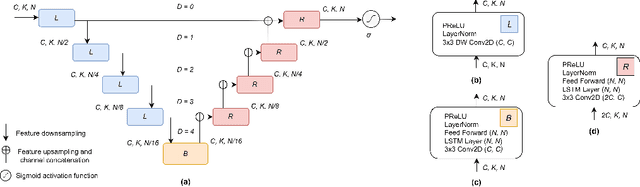
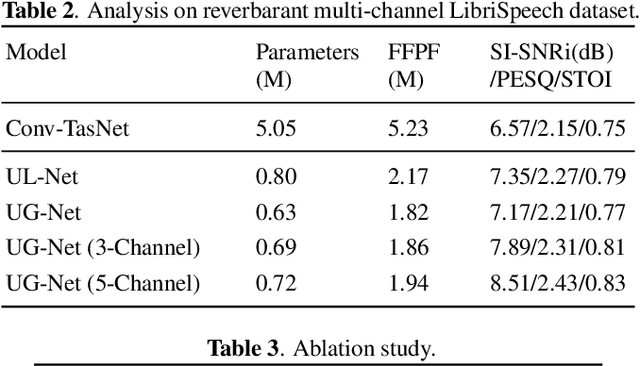
This study presents UX-Net, a time-domain audio separation network (TasNet) based on a modified U-Net architecture. The proposed UX-Net works in real-time and handles either single or multi-microphone input. Inspired by the filter-and-process-based human auditory behavior, the proposed system introduces novel mixer and separation modules, which result in cost and memory efficient modeling of speech sources. The mixer module combines encoded input in a latent feature space and outputs a desired number of output streams. Then, in the separation module, a modified U-Net (UX) block is applied. The UX block first filters the encoded input at various resolutions followed by aggregating the filtered information and applying recurrent processing to estimate masks of separated sources. The letter 'X' in UX-Net is a name placeholder for the type of recurrent layer employed in the UX block. Empirical findings on the WSJ0-2mix benchmark dataset show that one of the UX-Net configurations outperforms the state-of-the-art Conv-TasNet system by 0.85 dB SI-SNR while using only 16% of the model parameters, 58% fewer computations, and maintaining low latency.
Outcome-Oriented Prescriptive Process Monitoring Based on Temporal Logic Patterns
Nov 09, 2022
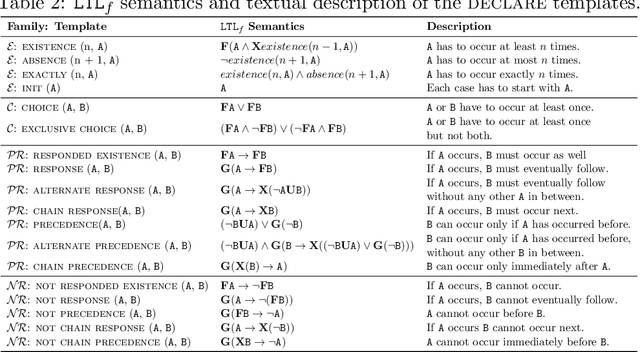
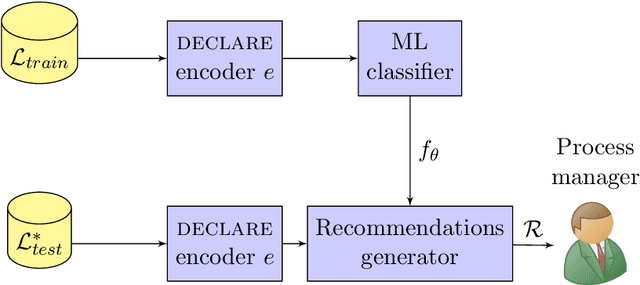

Prescriptive Process Monitoring systems recommend, during the execution of a business process, interventions that, if followed, prevent a negative outcome of the process. Such interventions have to be reliable, that is, they have to guarantee the achievement of the desired outcome or performance, and they have to be flexible, that is, they have to avoid overturning the normal process execution or forcing the execution of a given activity. Most of the existing Prescriptive Process Monitoring solutions, however, while performing well in terms of recommendation reliability, provide the users with very specific (sequences of) activities that have to be executed without caring about the feasibility of these recommendations. In order to face this issue, we propose a new Outcome-Oriented Prescriptive Process Monitoring system recommending temporal relations between activities that have to be guaranteed during the process execution in order to achieve a desired outcome. This softens the mandatory execution of an activity at a given point in time, thus leaving more freedom to the user in deciding the interventions to put in place. Our approach defines these temporal relations with Linear Temporal Logic over finite traces patterns that are used as features to describe the historical process data recorded in an event log by the information systems supporting the execution of the process. Such encoded log is used to train a Machine Learning classifier to learn a mapping between the temporal patterns and the outcome of a process execution. The classifier is then queried at runtime to return as recommendations the most salient temporal patterns to be satisfied to maximize the likelihood of a certain outcome for an input ongoing process execution. The proposed system is assessed using a pool of 22 real-life event logs that have already been used as a benchmark in the Process Mining community.
Stereo Superpixel Segmentation Via Decoupled Dynamic Spatial-Embedding Fusion Network
Aug 17, 2022



Stereo superpixel segmentation aims at grouping the discretizing pixels into perceptual regions through left and right views more collaboratively and efficiently. Existing superpixel segmentation algorithms mostly utilize color and spatial features as input, which may impose strong constraints on spatial information while utilizing the disparity information in terms of stereo image pairs. To alleviate this issue, we propose a stereo superpixel segmentation method with a decoupling mechanism of spatial information in this work. To decouple stereo disparity information and spatial information, the spatial information is temporarily removed before fusing the features of stereo image pairs, and a decoupled stereo fusion module (DSFM) is proposed to handle the stereo features alignment as well as occlusion problems. Moreover, since the spatial information is vital to superpixel segmentation, we further design a dynamic spatiality embedding module (DSEM) to re-add spatial information, and the weights of spatial information will be adaptively adjusted through the dynamic fusion (DF) mechanism in DSEM for achieving a finer segmentation. Comprehensive experimental results demonstrate that our method can achieve the state-of-the-art performance on the KITTI2015 and Cityscapes datasets, and also verify the efficiency when applied in salient object detection on NJU2K dataset. The source code will be available publicly after paper is accepted.
Competing Mutual Information Constraints with Stochastic Competition-based Activations for Learning Diversified Representations
Jan 10, 2022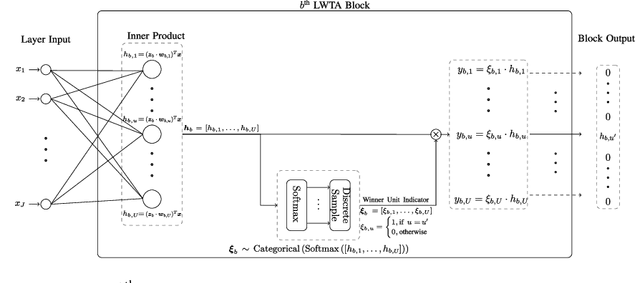
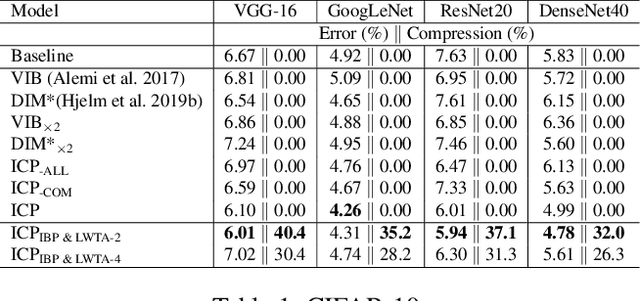
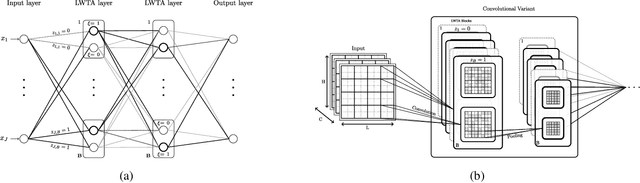
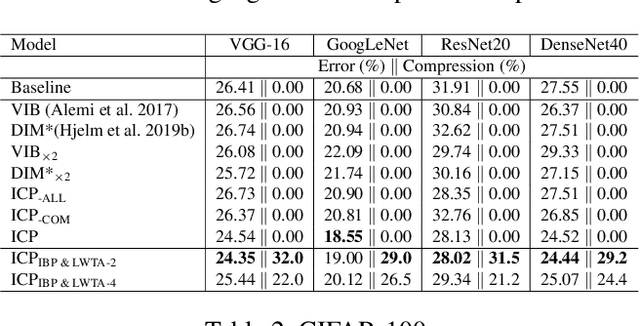
This work aims to address the long-established problem of learning diversified representations. To this end, we combine information-theoretic arguments with stochastic competition-based activations, namely Stochastic Local Winner-Takes-All (LWTA) units. In this context, we ditch the conventional deep architectures commonly used in Representation Learning, that rely on non-linear activations; instead, we replace them with sets of locally and stochastically competing linear units. In this setting, each network layer yields sparse outputs, determined by the outcome of the competition between units that are organized into blocks of competitors. We adopt stochastic arguments for the competition mechanism, which perform posterior sampling to determine the winner of each block. We further endow the considered networks with the ability to infer the sub-part of the network that is essential for modeling the data at hand; we impose appropriate stick-breaking priors to this end. To further enrich the information of the emerging representations, we resort to information-theoretic principles, namely the Information Competing Process (ICP). Then, all the components are tied together under the stochastic Variational Bayes framework for inference. We perform a thorough experimental investigation for our approach using benchmark datasets on image classification. As we experimentally show, the resulting networks yield significant discriminative representation learning abilities. In addition, the introduced paradigm allows for a principled investigation mechanism of the emerging intermediate network representations.
CMR3D: Contextualized Multi-Stage Refinement for 3D Object Detection
Sep 13, 2022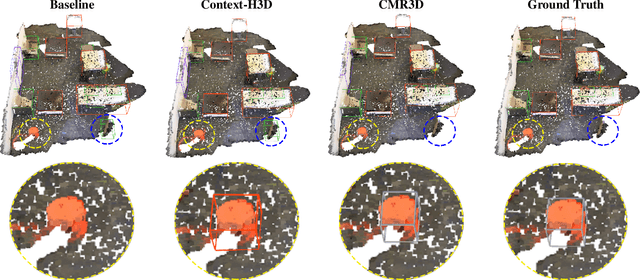
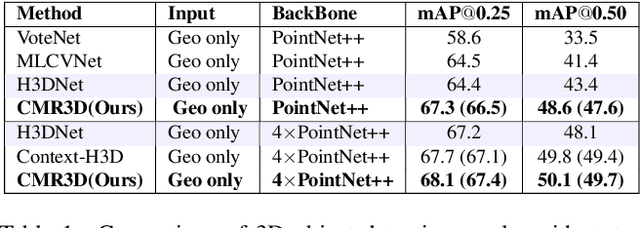
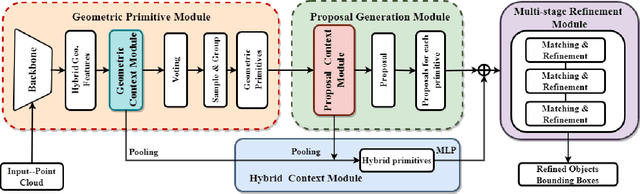

Existing deep learning-based 3D object detectors typically rely on the appearance of individual objects and do not explicitly pay attention to the rich contextual information of the scene. In this work, we propose Contextualized Multi-Stage Refinement for 3D Object Detection (CMR3D) framework, which takes a 3D scene as input and strives to explicitly integrate useful contextual information of the scene at multiple levels to predict a set of object bounding-boxes along with their corresponding semantic labels. To this end, we propose to utilize a context enhancement network that captures the contextual information at different levels of granularity followed by a multi-stage refinement module to progressively refine the box positions and class predictions. Extensive experiments on the large-scale ScanNetV2 benchmark reveal the benefits of our proposed method, leading to an absolute improvement of 2.0% over the baseline. In addition to 3D object detection, we investigate the effectiveness of our CMR3D framework for the problem of 3D object counting. Our source code will be publicly released.