 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Covered Information Disentanglement: Model Transparency via Unbiased Permutation Importance
Nov 21, 2021
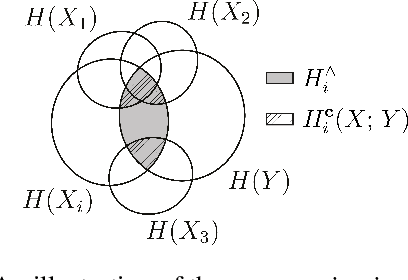
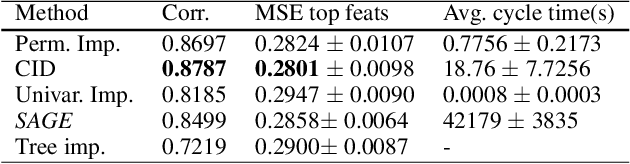
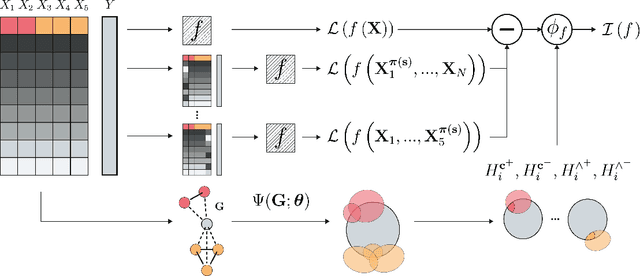
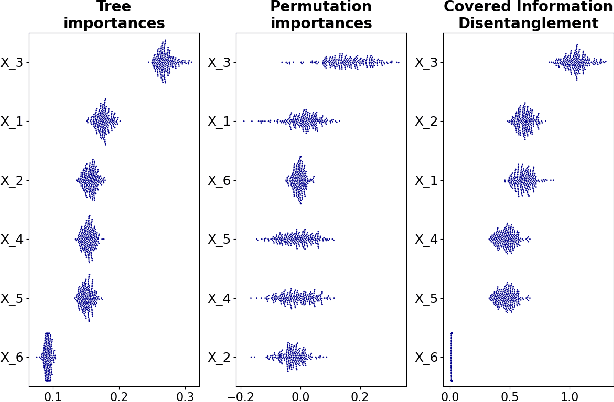
Model transparency is a prerequisite in many domains and an increasingly popular area in machine learning research. In the medical domain, for instance, unveiling the mechanisms behind a disease often has higher priority than the diagnostic itself since it might dictate or guide potential treatments and research directions. One of the most popular approaches to explain model global predictions is the permutation importance where the performance on permuted data is benchmarked against the baseline. However, this method and other related approaches will undervalue the importance of a feature in the presence of covariates since these cover part of its provided information. To address this issue, we propose Covered Information Disentanglement (CID), a method that considers all feature information overlap to correct the values provided by permutation importance. We further show how to compute CID efficiently when coupled with Markov random fields. We demonstrate its efficacy in adjusting permutation importance first on a controlled toy dataset and discuss its effect on real-world medical data.
LAB: Learnable Activation Binarizer for Binary Neural Networks
Oct 25, 2022

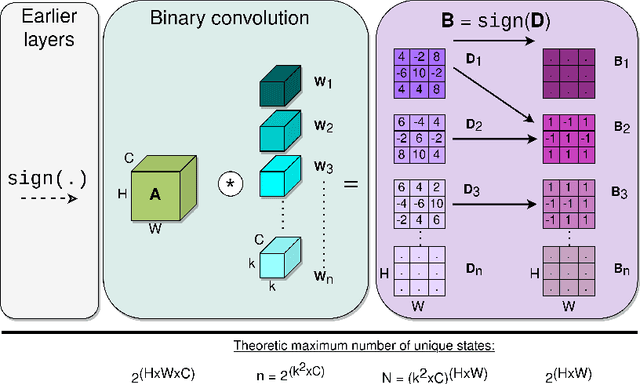
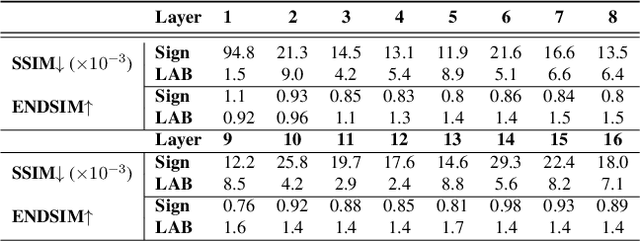
Binary Neural Networks (BNNs) are receiving an upsurge of attention for bringing power-hungry deep learning towards edge devices. The traditional wisdom in this space is to employ sign() for binarizing featuremaps. We argue and illustrate that sign() is a uniqueness bottleneck, limiting information propagation throughout the network. To alleviate this, we propose to dispense sign(), replacing it with a learnable activation binarizer (LAB), allowing the network to learn a fine-grained binarization kernel per layer - as opposed to global thresholding. LAB is a novel universal module that can seamlessly be integrated into existing architectures. To confirm this, we plug it into four seminal BNNs and show a considerable performance boost at the cost of tolerable increase in delay and complexity. Finally, we build an end-to-end BNN (coined as LAB-BNN) around LAB, and demonstrate that it achieves competitive performance on par with the state-of-the-art on ImageNet.
A Survey on Fundamental Concepts and Practical Challenges of Hyperspectral images
Oct 25, 2022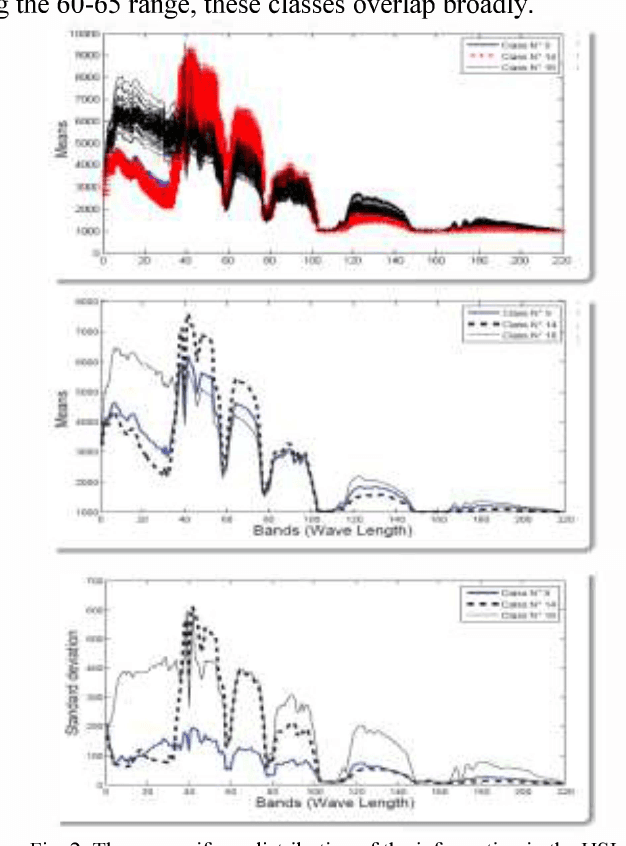
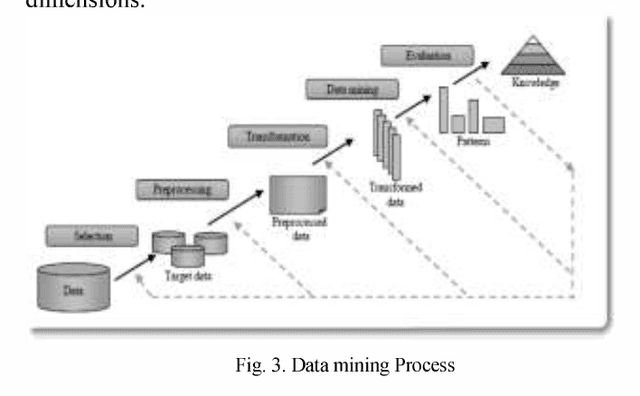

The Remote sensing provides a synoptic view of land by detecting the energy reflected from Earth's surface. The Hyperspectral images (HSI) use perfect sensors that extract more than a hundred of images, with more detailed information than using traditional Multispectral data. In this paper, we aim to study this aspect of communication in the case of passive reception. First, a brief overview of acquisition process and treatment of Hyperspectral images is provided. Then, we explain representation spaces and the various analysis methods of these images. Furthermore, the factors influencing this analysis are investigated and some applications, in this area, are presented. Finally, we explain the relationship between Hyperspectral images and Datamining and we outline the open issues related to this area. So we consider the case study: HSI AVIRIS 92AV3C. This study serves as map of route for integrating classification methods in the higher dimensionality data. Keywords-component: Hyperspectral images, Passive Sensing,Classification, Data mining.
An IoT Cloud and Big Data Architecture for the Maintenance of Home Appliances
Oct 25, 2022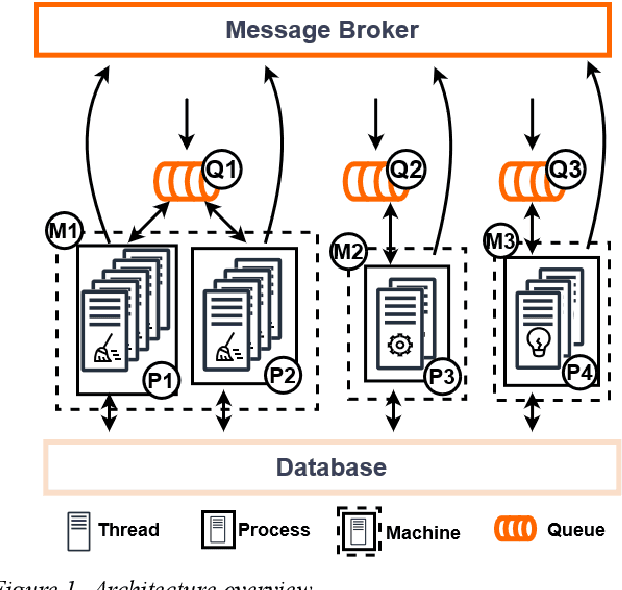
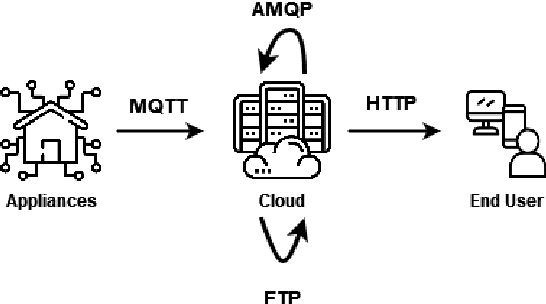
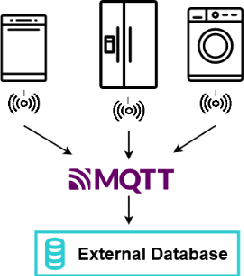
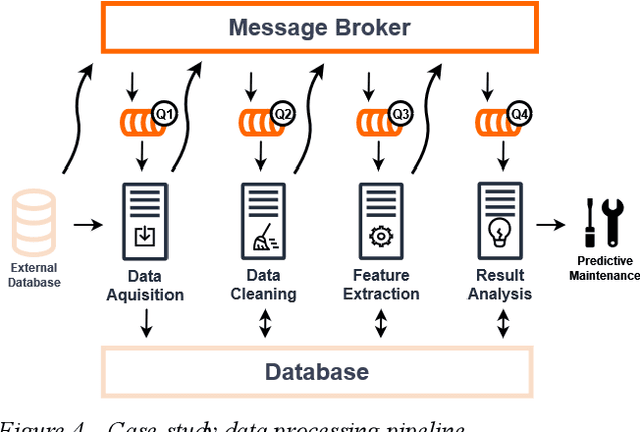
Billions of interconnected Internet of Things (IoT) sensors and devices collect tremendous amounts of data from real-world scenarios. Big data is generating increasing interest in a wide range of industries. Once data is analyzed through compute-intensive Machine Learning (ML) methods, it can derive critical business value for organizations. Powerfulplatforms are essential to handle and process such massive collections of information cost-effectively and conveniently. This work introduces a distributed and scalable platform architecture that can be deployed for efficient real-world big data collection and analytics. The proposed system was tested with a case study for Predictive Maintenance of Home Appliances, where current and vibration sensors with high acquisition frequency were connected to washing machines and refrigerators. The introduced platform was used to collect, store, and analyze the data. The experimental results demonstrated that the presented system could be advantageous for tackling real-world IoT scenarios in a cost-effective and local approach.
Unsupervised domain-adaptive person re-identification with multi-camera constraints
Oct 25, 2022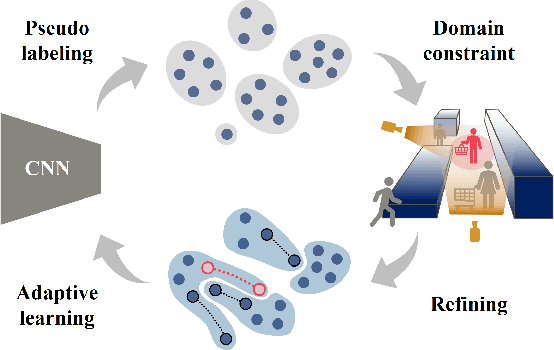
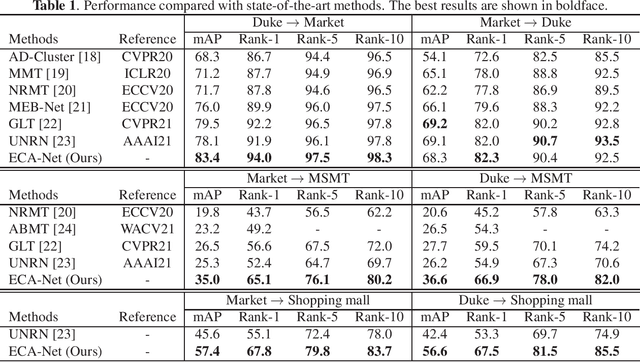
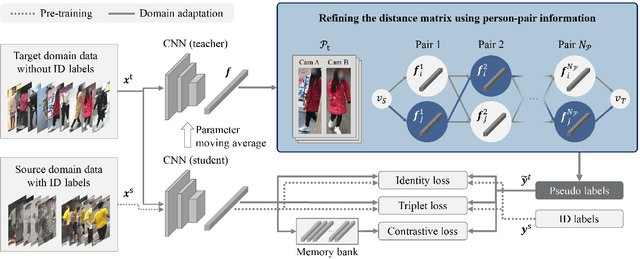
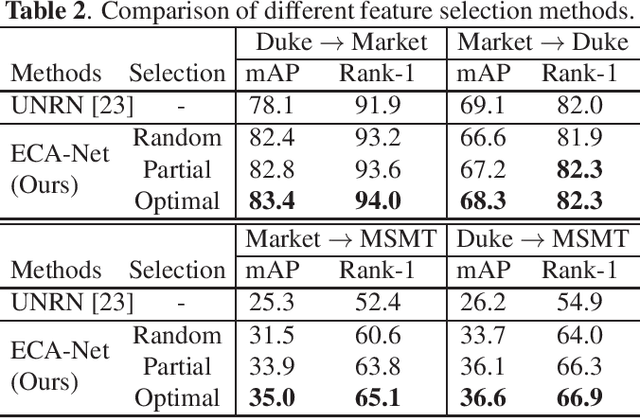
Person re-identification is a key technology for analyzing video-based human behavior; however, its application is still challenging in practical situations due to the performance degradation for domains different from those in the training data. Here, we propose an environment-constrained adaptive network for reducing the domain gap. This network refines pseudo-labels estimated via a self-training scheme by imposing multi-camera constraints. The proposed method incorporates person-pair information without person identity labels obtained from the environment into the model training. In addition, we develop a method that appropriately selects a person from the pair that contributes to the performance improvement. We evaluate the performance of the network using public and private datasets and confirm the performance surpasses state-of-the-art methods in domains with overlapping camera views. To the best of our knowledge, this is the first study on domain-adaptive learning with multi-camera constraints that can be obtained in real environments.
A Chinese Spelling Check Framework Based on Reverse Contrastive Learning
Oct 25, 2022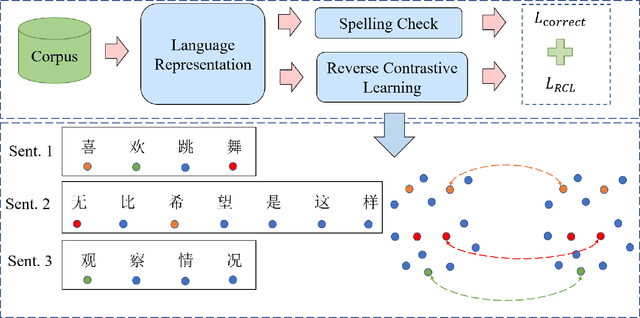
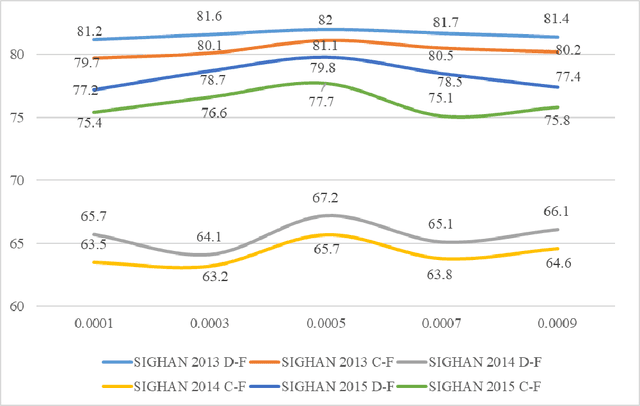
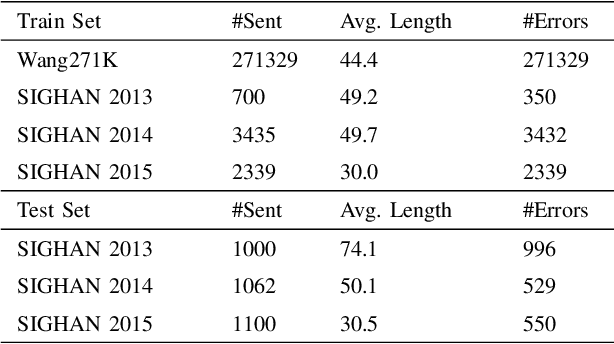
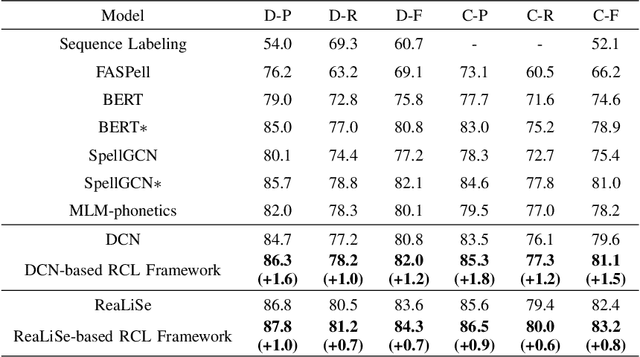
Chinese spelling check is a task to detect and correct spelling mistakes in Chinese text. Existing research aims to enhance the text representation and use multi-source information to improve the detection and correction capabilities of models, but does not pay too much attention to improving their ability to distinguish between confusable words. Contrastive learning, whose aim is to minimize the distance in representation space between similar sample pairs, has recently become a dominant technique in natural language processing. Inspired by contrastive learning, we present a novel framework for Chinese spelling checking, which consists of three modules: language representation, spelling check and reverse contrastive learning. Specifically, we propose a reverse contrastive learning strategy, which explicitly forces the model to minimize the agreement between the similar examples, namely, the phonetically and visually confusable characters. Experimental results show that our framework is model-agnostic and could be combined with existing Chinese spelling check models to yield state-of-the-art performance.
Towards Real World HDRTV Reconstruction: A Data Synthesis-based Approach
Nov 06, 2022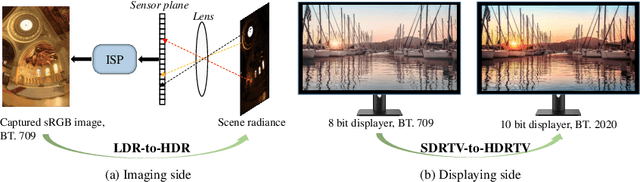
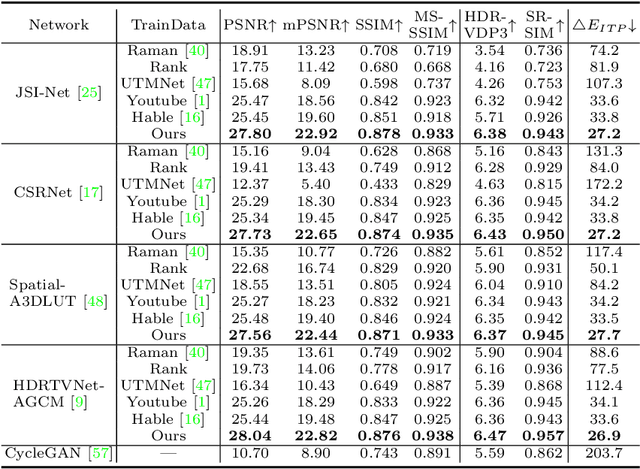


Existing deep learning based HDRTV reconstruction methods assume one kind of tone mapping operators (TMOs) as the degradation procedure to synthesize SDRTV-HDRTV pairs for supervised training. In this paper, we argue that, although traditional TMOs exploit efficient dynamic range compression priors, they have several drawbacks on modeling the realistic degradation: information over-preservation, color bias and possible artifacts, making the trained reconstruction networks hard to generalize well to real-world cases. To solve this problem, we propose a learning-based data synthesis approach to learn the properties of real-world SDRTVs by integrating several tone mapping priors into both network structures and loss functions. In specific, we design a conditioned two-stream network with prior tone mapping results as a guidance to synthesize SDRTVs by both global and local transformations. To train the data synthesis network, we form a novel self-supervised content loss to constraint different aspects of the synthesized SDRTVs at regions with different brightness distributions and an adversarial loss to emphasize the details to be more realistic. To validate the effectiveness of our approach, we synthesize SDRTV-HDRTV pairs with our method and use them to train several HDRTV reconstruction networks. Then we collect two inference datasets containing both labeled and unlabeled real-world SDRTVs, respectively. Experimental results demonstrate that, the networks trained with our synthesized data generalize significantly better to these two real-world datasets than existing solutions.
Information-Theoretic Bayes Risk Lower Bounds for Realizable Models
Nov 08, 2021We derive information-theoretic lower bounds on the Bayes risk and generalization error of realizable machine learning models. In particular, we employ an analysis in which the rate-distortion function of the model parameters bounds the required mutual information between the training samples and the model parameters in order to learn a model up to a Bayes risk constraint. For realizable models, we show that both the rate distortion function and mutual information admit expressions that are convenient for analysis. For models that are (roughly) lower Lipschitz in their parameters, we bound the rate distortion function from below, whereas for VC classes, the mutual information is bounded above by $d_\mathrm{vc}\log(n)$. When these conditions match, the Bayes risk with respect to the zero-one loss scales no faster than $\Omega(d_\mathrm{vc}/n)$, which matches known outer bounds and minimax lower bounds up to logarithmic factors. We also consider the impact of label noise, providing lower bounds when training and/or test samples are corrupted.
S^2-Transformer for Mask-Aware Hyperspectral Image Reconstruction
Sep 24, 2022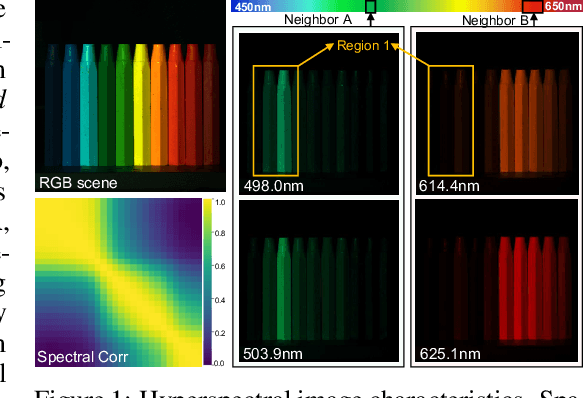
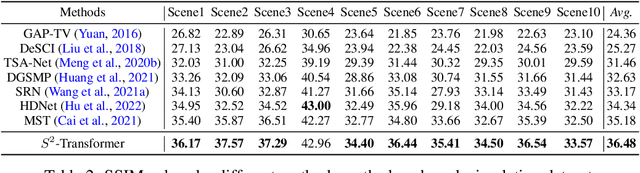
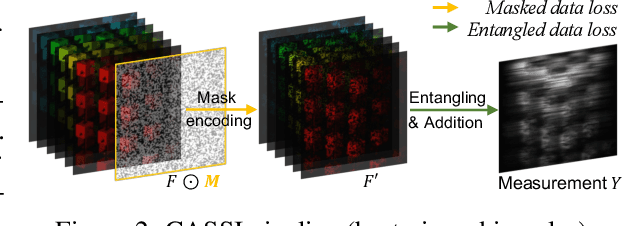
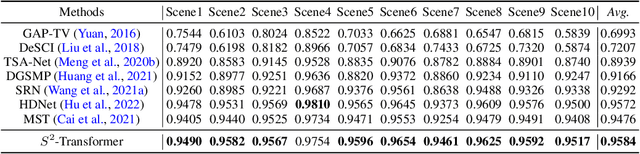
The technology of hyperspectral imaging (HSI) records the visual information upon long-range-distributed spectral wavelengths. A representative hyperspectral image acquisition procedure conducts a 3D-to-2D encoding by the coded aperture snapshot spectral imager (CASSI), and requires a software decoder for the 3D signal reconstruction. Based on this encoding procedure, two major challenges stand in the way of a high-fidelity reconstruction: (i) To obtain 2D measurements, CASSI dislocates multiple channels by disperser-titling and squeezes them onto the same spatial region, yielding an entangled data loss. (ii) The physical coded aperture (mask) will lead to a masked data loss by selectively blocking the pixel-wise light exposure. To tackle these challenges, we propose a spatial-spectral (S2-) transformer architecture with a mask-aware learning strategy. Firstly, we simultaneously leverage spatial and spectral attention modelings to disentangle the blended information in the 2D measurement along both two dimensions. A series of Transformer structures across spatial & spectral clues are systematically designed, which considers the information inter-dependency between the two-fold cues. Secondly, the masked pixels will induce higher prediction difficulty and should be treated differently from unmasked ones. Thereby, we adaptively prioritize the loss penalty attributing to the mask structure by inferring the difficulty-level upon the mask-aware prediction. Our proposed method not only sets a new state-of-the-art quantitatively, but also yields a better perceptual quality upon structured areas.
Towards Unsupervised Dense Information Retrieval with Contrastive Learning
Dec 16, 2021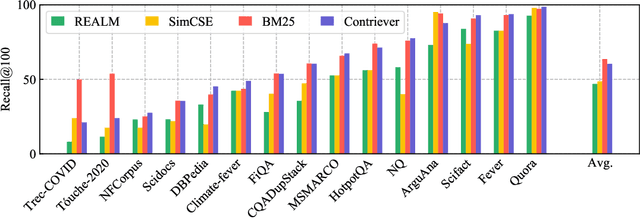
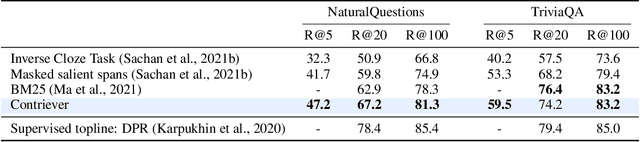
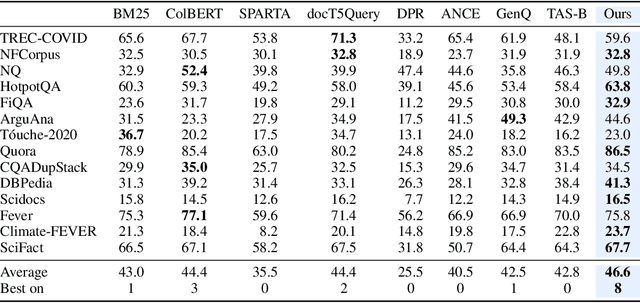
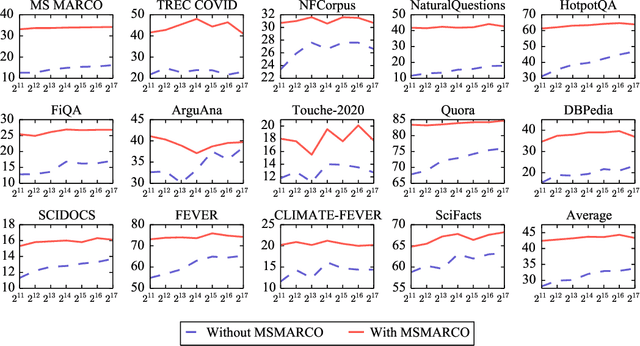
Information retrieval is an important component in natural language processing, for knowledge intensive tasks such as question answering and fact checking. Recently, information retrieval has seen the emergence of dense retrievers, based on neural networks, as an alternative to classical sparse methods based on term-frequency. These models have obtained state-of-the-art results on datasets and tasks where large training sets are available. However, they do not transfer well to new domains or applications with no training data, and are often outperformed by term-frequency methods such as BM25 which are not supervised. Thus, a natural question is whether it is possible to train dense retrievers without supervision. In this work, we explore the limits of contrastive learning as a way to train unsupervised dense retrievers, and show that it leads to strong retrieval performance. More precisely, we show on the BEIR benchmark that our model outperforms BM25 on 11 out of 15 datasets. Furthermore, when a few thousands examples are available, we show that fine-tuning our model on these leads to strong improvements compared to BM25. Finally, when used as pre-training before fine-tuning on the MS-MARCO dataset, our technique obtains state-of-the-art results on the BEIR benchmark.