 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Using Supervised Deep-Learning to Model Edge-FBG Shape Sensors
Oct 28, 2022
Continuum robots in robot-assisted minimally invasive surgeries provide adequate access to target anatomies that are not directly reachable through small incisions. Achieving precise and reliable motion control of such snake-like manipulators necessitates an accurate navigation system that requires no line-of-sight and is immune to electromagnetic noises. Fiber Bragg Grating (FBG) shape sensors, particularly edge-FBGs, are promising tools for this task. However, in edge-FBG sensors, the intensity ratio between Bragg wavelengths carries the strain information that can be affected by undesired bending-related phenomena, making standard characterization techniques less suitable for these sensors. We showed in our previous work that a deep learning model has the potential to extract the strain information from the full edge-FBG spectrum and accurately predict the sensor's shape. In this paper, we conduct a more thorough investigation to find a suitable architectural design with lower prediction errors. We use the Hyperband algorithm to search for optimal hyperparameters in two steps. First, we limit the search space to layer settings, where the best-performing configuration gets selected. Then, we modify the search space for tuning the training and loss calculation hyperparameters. We also analyze various data transformations on the input and output variables, as data rescaling can directly influence the model's performance. Moreover, we performed discriminative training using Siamese network architecture that employs two CNNs with identical parameters to learn similarity metrics between the spectra of similar target values. The best-performing network architecture among all evaluated configurations can predict the sensor's shape with a median tip error of 3.11 mm.
Synthetic Model Combination: An Instance-wise Approach to Unsupervised Ensemble Learning
Oct 11, 2022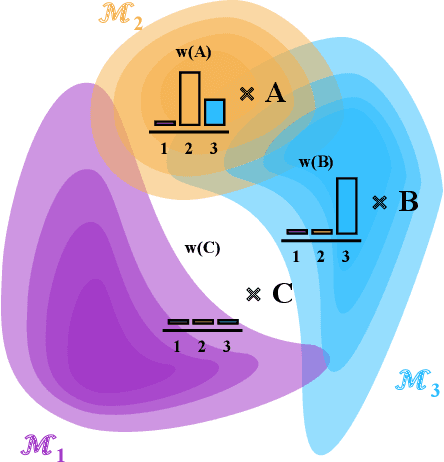

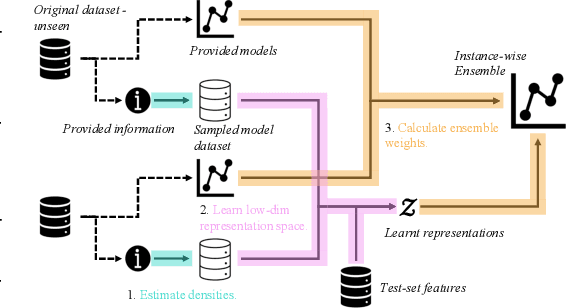
Consider making a prediction over new test data without any opportunity to learn from a training set of labelled data - instead given access to a set of expert models and their predictions alongside some limited information about the dataset used to train them. In scenarios from finance to the medical sciences, and even consumer practice, stakeholders have developed models on private data they either cannot, or do not want to, share. Given the value and legislation surrounding personal information, it is not surprising that only the models, and not the data, will be released - the pertinent question becoming: how best to use these models? Previous work has focused on global model selection or ensembling, with the result of a single final model across the feature space. Machine learning models perform notoriously poorly on data outside their training domain however, and so we argue that when ensembling models the weightings for individual instances must reflect their respective domains - in other words models that are more likely to have seen information on that instance should have more attention paid to them. We introduce a method for such an instance-wise ensembling of models, including a novel representation learning step for handling sparse high-dimensional domains. Finally, we demonstrate the need and generalisability of our method on classical machine learning tasks as well as highlighting a real world use case in the pharmacological setting of vancomycin precision dosing.
Designing Efficient Pair-Trading Strategies Using Cointegration for the Indian Stock Market
Nov 14, 2022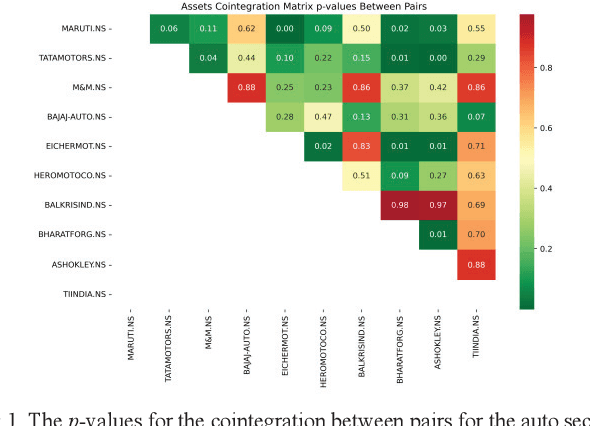
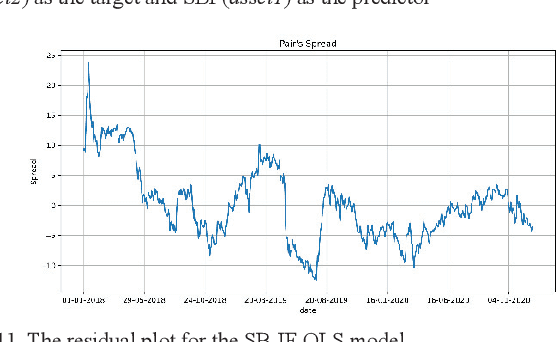
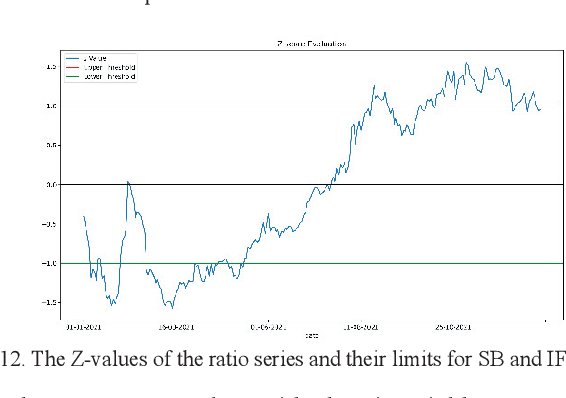
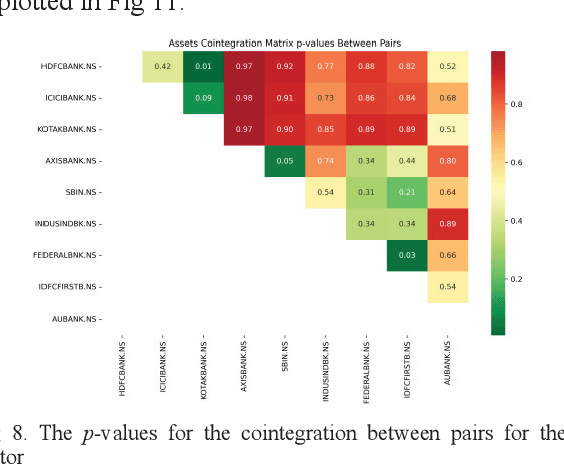
A pair-trading strategy is an approach that utilizes the fluctuations between prices of a pair of stocks in a short-term time frame, while in the long-term the pair may exhibit a strong association and co-movement pattern. When the prices of the stocks exhibit significant divergence, the shares of the stock that gains in price are sold (a short strategy) while the shares of the other stock whose price falls are bought (a long strategy). This paper presents a cointegration-based approach that identifies stocks listed in the five sectors of the National Stock Exchange (NSE) of India for designing efficient pair-trading portfolios. Based on the stock prices from Jan 1, 2018, to Dec 31, 2020, the cointegrated stocks are identified and the pairs are formed. The pair-trading portfolios are evaluated on their annual returns for the year 2021. The results show that the pairs of stocks from the auto and the realty sectors, in general, yielded the highest returns among the five sectors studied in the work. However, two among the five pairs from the information technology (IT) sector are found to have yielded negative returns.
SA-DPSGD: Differentially Private Stochastic Gradient Descent based on Simulated Annealing
Nov 14, 2022
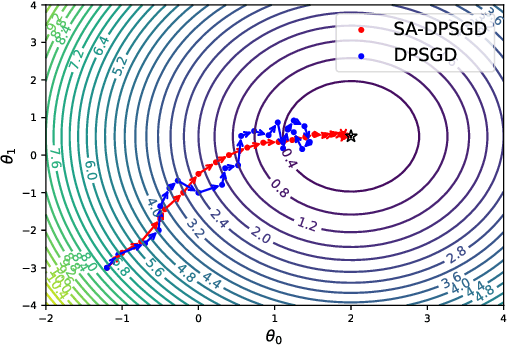

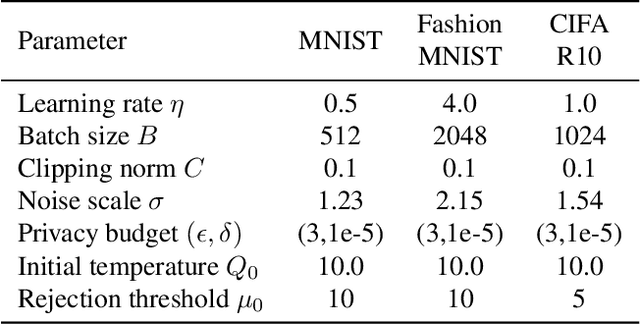
Differential privacy (DP) provides a formal privacy guarantee that prevents adversaries with access to machine learning models from extracting information about individual training points. Differentially private stochastic gradient descent (DPSGD) is the most popular training method with differential privacy in image recognition. However, existing DPSGD schemes lead to significant performance degradation, which prevents the application of differential privacy. In this paper, we propose a simulated annealing-based differentially private stochastic gradient descent scheme (SA-DPSGD) which accepts a candidate update with a probability that depends both on the update quality and on the number of iterations. Through this random update screening, we make the differentially private gradient descent proceed in the right direction in each iteration, and result in a more accurate model finally. In our experiments, under the same hyperparameters, our scheme achieves test accuracies 98.35%, 87.41% and 60.92% on datasets MNIST, FashionMNIST and CIFAR10, respectively, compared to the state-of-the-art result of 98.12%, 86.33% and 59.34%. Under the freely adjusted hyperparameters, our scheme achieves even higher accuracies, 98.89%, 88.50% and 64.17%. We believe that our method has a great contribution for closing the accuracy gap between private and non-private image classification.
C3: Cross-instance guided Contrastive Clustering
Nov 14, 2022
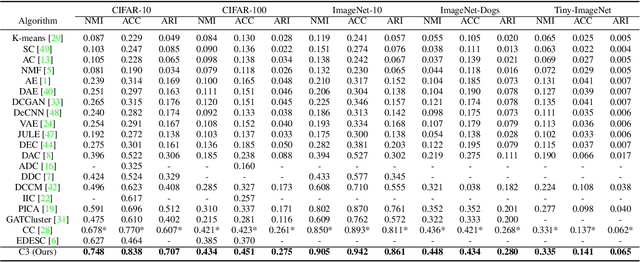
Clustering is the task of gathering similar data samples into clusters without using any predefined labels. It has been widely studied in machine learning literature, and recent advancements in deep learning have revived interest in this field. Contrastive clustering (CC) models are a staple of deep clustering in which positive and negative pairs of each data instance are generated through data augmentation. CC models aim to learn a feature space where instance-level and cluster-level representations of positive pairs are grouped together. Despite improving the SOTA, these algorithms ignore the cross-instance patterns, which carry essential information for improving clustering performance. In this paper, we propose a novel contrastive clustering method, Cross-instance guided Contrastive Clustering (C3), that considers the cross-sample relationships to increase the number of positive pairs. In particular, we define a new loss function that identifies similar instances using the instance-level representation and encourages them to aggregate together. Extensive experimental evaluations show that our proposed method can outperform state-of-the-art algorithms on benchmark computer vision datasets: we improve the clustering accuracy by 6.8%, 2.8%, 4.9%, 1.3% and 0.4% on CIFAR-10, CIFAR-100, ImageNet-10, ImageNet-Dogs, and Tiny-ImageNet, respectively.
Pilot-Aided Distributed Multi-Group Multicast Precoding Design for Cell-Free Massive MIMO
Nov 14, 2022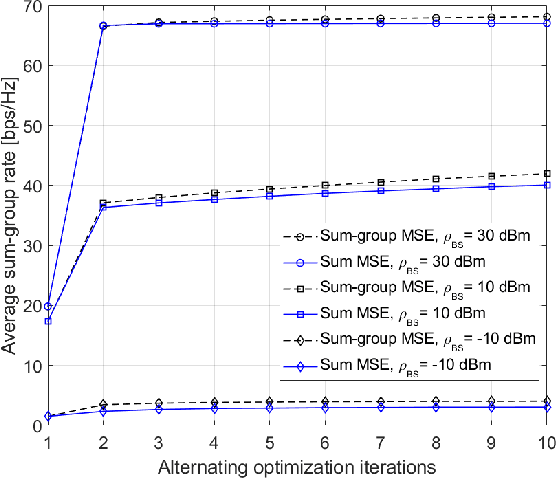
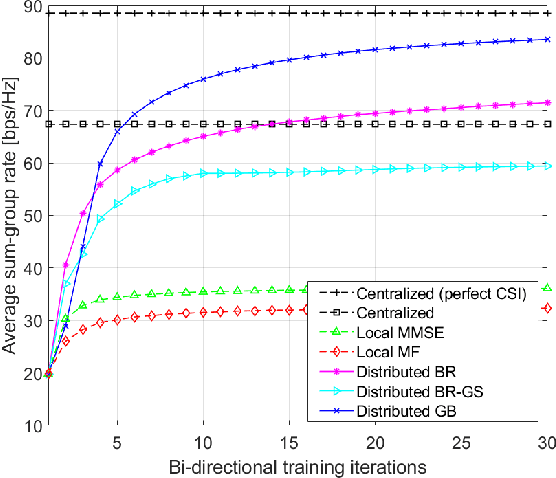
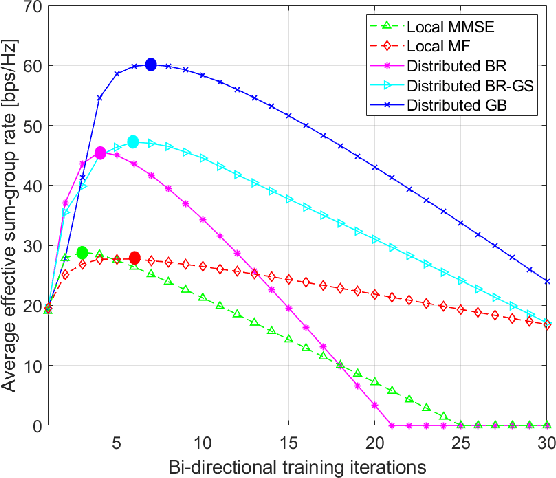
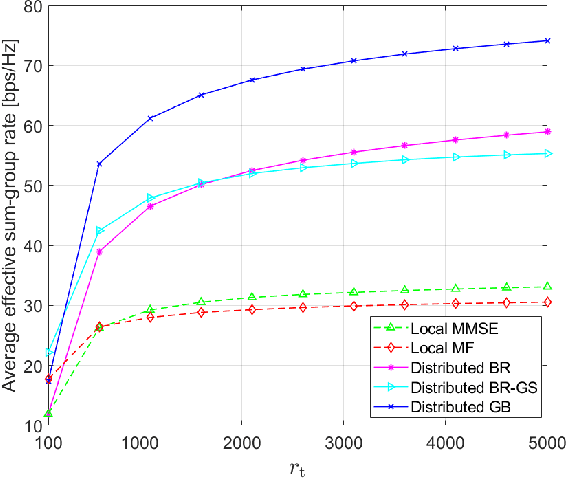
We propose fully distributed multi-group multicast precoding designs for cell-free massive multiple-input multiple-output (MIMO) systems with modest training overhead. We target the minimization of the sum of the maximum mean squared errors (MSEs) over the multicast groups, which is then approximated with a weighted sum MSE minimization to simplify the computation and signaling. To design the joint network-wide multi-group multicast precoders at the base stations (BSs) and the combiners at the user equipments (UEs) in a fully distributed fashion, we adopt an iterative bi-directional training scheme with UE-specific or group-specific precoded uplink pilots and group-specific precoded downlink pilots. To this end, we introduce a new group-specific uplink training resource that entirely eliminates the need for backhaul signaling for the channel state information (CSI) exchange. The precoders are optimized locally at each BS by means of either best-response or gradient-based updates, and the convergence of the two approaches is analyzed with respect to the centralized implementation with perfect CSI. Finally, numerical results show that the proposed distributed methods greatly outperform conventional cell-free massive MIMO precoding designs that rely solely on local CSI.
A robust basis for multi-bit optical communication with vectorial light
Sep 30, 2022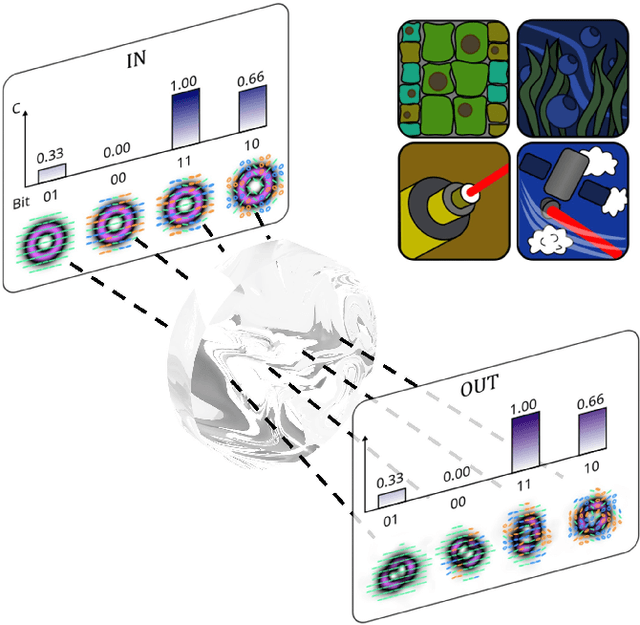
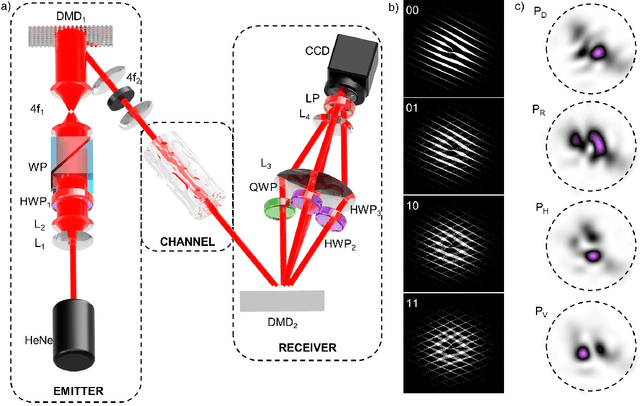
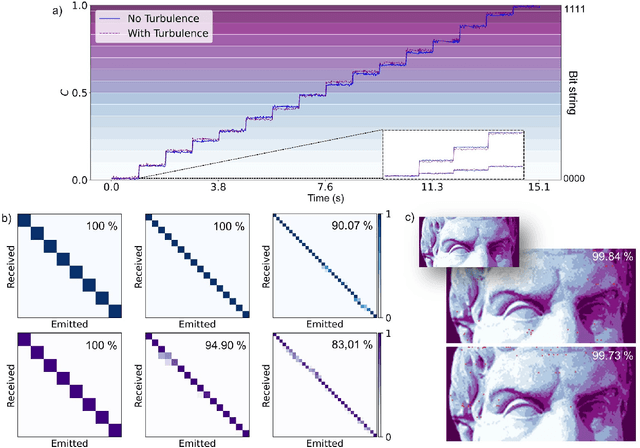
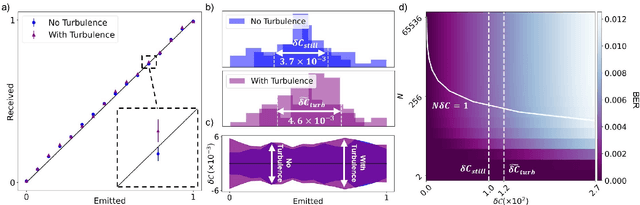
Increasing the information capacity of communication channels is a pressing need, driven by growing data demands and the consequent impending data crunch with existing modulation schemes. In this regard, mode division multiplexing (MDM), where the spatial modes of light form the encoding basis, has enormous potential and appeal, but is impeded by modal noise due to imperfect channels. Here we overcome this challenge by breaking the existing MDM paradigm of using the modes themselves as a discrete basis, instead exploiting the polarization inhomogeneity (vectorness) of vectorial light as our information carrier. We show that this encoding basis can be partitioned and detected almost at will, and measured in a channel independent fashion, a fact we confirm experimentally using atmospheric turbulence as a highly perturbing channel example. Our approach replaces conventional amplitude modulation with a novel modal alternative for potentially orders of magnitude channel information enhancement, yet is robust to fading even through noisy channels, offering a new paradigm to exploiting the spatial mode basis for optical communication.
Asymmetric Distillation Post-Segmentation Method for Image Anomaly Detection
Oct 19, 2022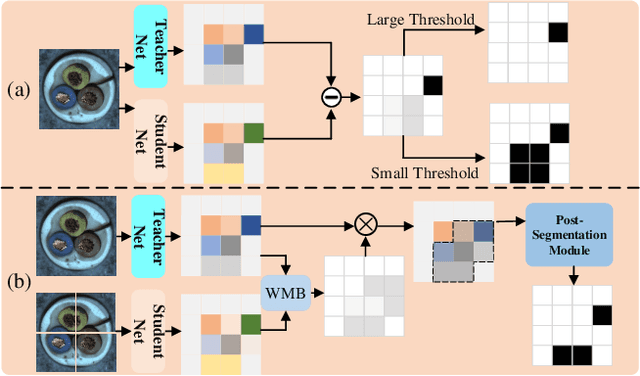
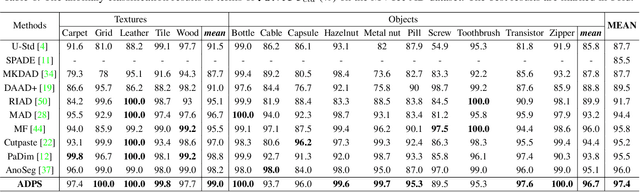
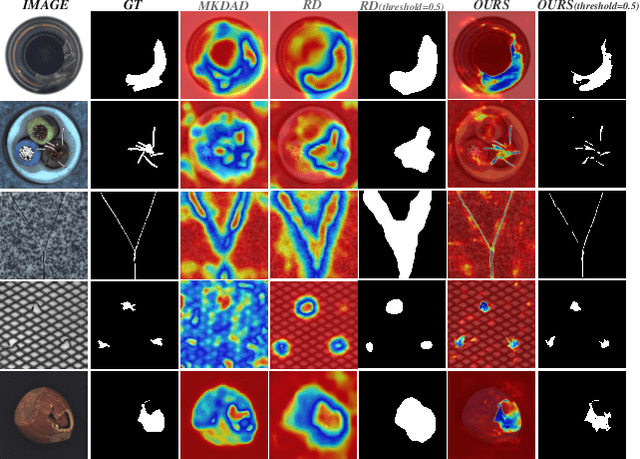
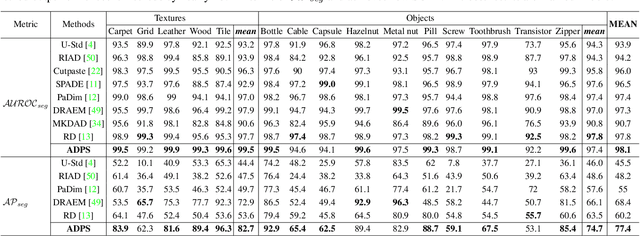
Knowledge distillation-based anomaly detection methods generate same outputs for unknown classes due to the symmetric form of the input and ignore the powerful semantic information of the output of the teacher network since it is only used as a "reference standard". Towards this end, this work proposes a novel Asymmetric Distillation Post-Segmentation (ADPS) method to effectively explore the asymmetric structure of the input and the discriminative features of the teacher network. Specifically, a simple yet effective asymmetric input approach is proposed to make different data flows through the teacher and student networks. The student network enables to have different inductive and expressive abilities, which can generate different outputs in anomalous regions. Besides, to further explore the semantic information of the teacher network and obtain effective discriminative boundaries, the Weight Mask Block (WMB) and the post-segmentation module are proposede. WMB leverages a weighted strategy by exploring teacher-student feature maps to highlight anomalous features. The post-segmentation module further learns the anomalous features and obtains valid discriminative boundaries. Experimental results on three benchmark datasets demonstrate that the proposed ADPS achieves state-of-the-art anomaly segmentation results.
Supervised Contrastive Learning with TPE-based Bayesian Optimization of Tabular Data for Imbalanced Learning
Oct 19, 2022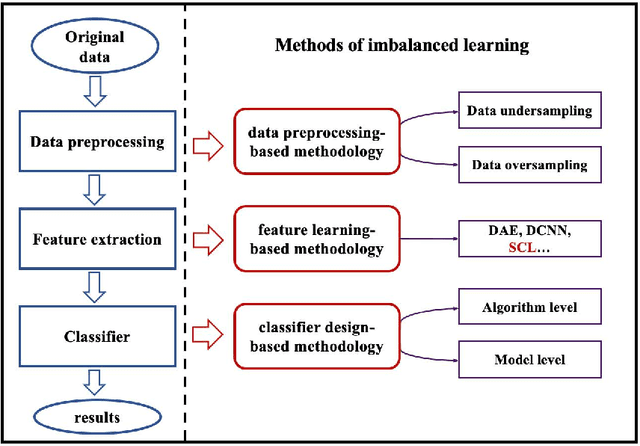
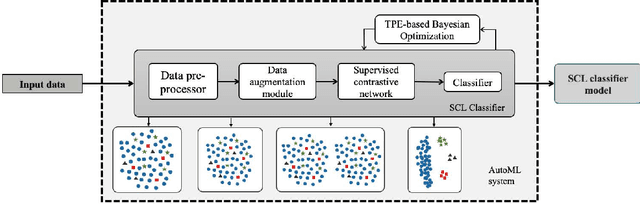
Class imbalance has a detrimental effect on the predictive performance of most supervised learning algorithms as the imbalanced distribution can lead to a bias preferring the majority class. To solve this problem, we propose a Supervised Contrastive Learning (SCL) method with Bayesian optimization technique based on Tree-structured Parzen Estimator (TPE) for imbalanced tabular datasets. Compared with supervised learning, contrastive learning can avoid "label bias" by extracting the information hidden in data. Based on contrastive loss, SCL can exploit the label information to address insufficient data augmentation of tabular data, and is thus used in the proposed SCL-TPE method to learn a discriminative representation of data. Additionally, as the hyper-parameter temperature has a decisive influence on the SCL performance and is difficult to tune, TPE-based Bayesian optimization is introduced to automatically select the best temperature. Experiments are conducted on both binary and multi-class imbalanced tabular datasets. As shown in the results obtained, TPE outperforms other hyper-parameter optimization (HPO) methods such as grid search, random search, and genetic algorithm. More importantly, the proposed SCL-TPE method achieves much-improved performance compared with the state-of-the-art methods.
Causality Detection using Multiple Annotation Decision
Oct 26, 2022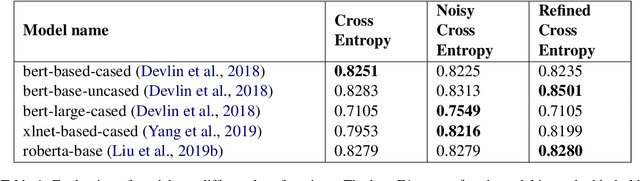
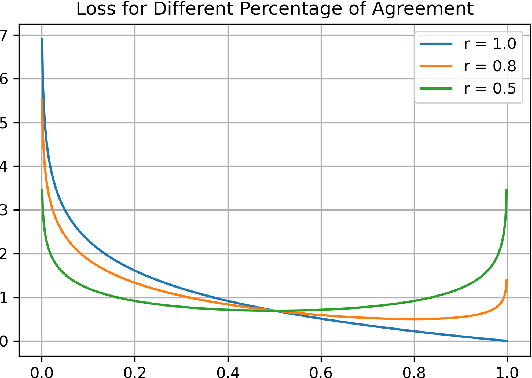
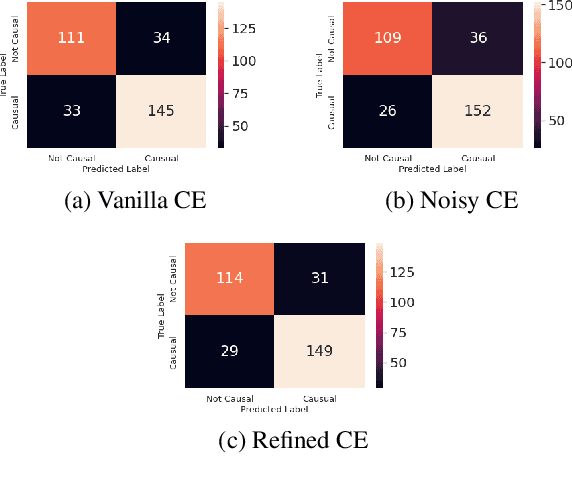
The paper describes the work that has been submitted to the 5th workshop on Challenges and Applications of Automated Extraction of socio-political events from text (CASE 2022). The work is associated with Subtask 1 of Shared Task 3 that aims to detect causality in protest news corpus. The authors used different large language models with customized cross-entropy loss functions that exploit annotation information. The experiments showed that bert-based-uncased with refined cross-entropy outperformed the others, achieving a F1 score of 0.8501 on the Causal News Corpus dataset.