 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Digging Deeper: Operator Analysis for Optimizing Nonlinearity of Boolean Functions
Feb 12, 2023


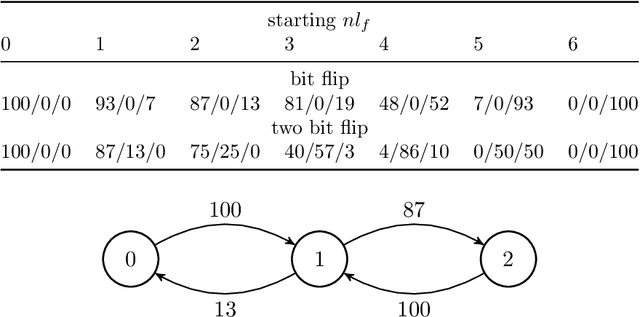
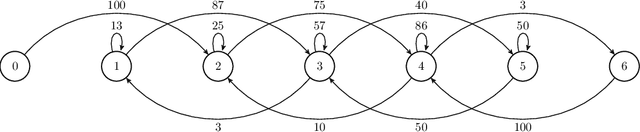
Boolean functions are mathematical objects with numerous applications in domains like coding theory, cryptography, and telecommunications. Finding Boolean functions with specific properties is a complex combinatorial optimization problem where the search space grows super-exponentially with the number of input variables. One common property of interest is the nonlinearity of Boolean functions. Constructing highly nonlinear Boolean functions is difficult as it is not always known what nonlinearity values can be reached in practice. In this paper, we investigate the effects of the genetic operators for bit-string encoding in optimizing nonlinearity. While several mutation and crossover operators have commonly been used, the link between the genotype they operate on and the resulting phenotype changes is mostly obscure. By observing the range of possible changes an operator can provide, as well as relative probabilities of specific transitions in the objective space, one can use this information to design a more effective combination of genetic operators. The analysis reveals interesting insights into operator effectiveness and indicates how algorithm design may improve convergence compared to an operator-agnostic genetic algorithm.
Quantifying Aleatoric and Epistemic Uncertainty in Machine Learning: Are Conditional Entropy and Mutual Information Appropriate Measures?
Sep 07, 2022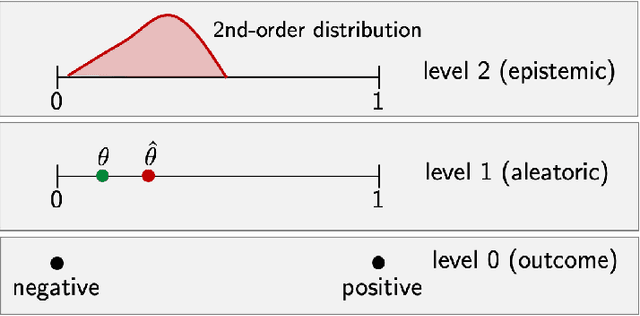
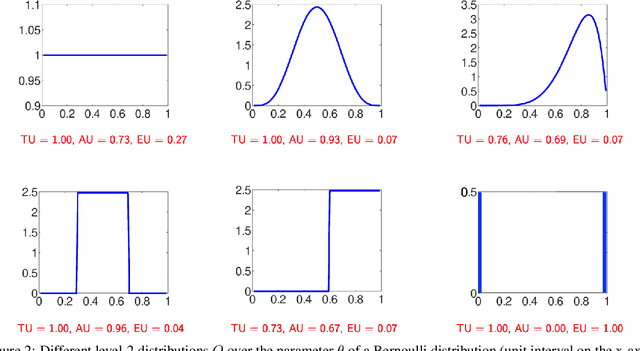
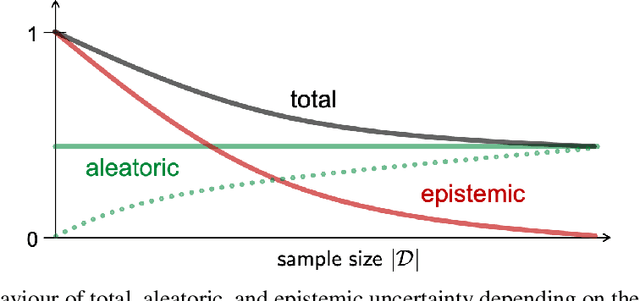
This short note is a critical discussion of the quantification of aleatoric and epistemic uncertainty in terms of conditional entropy and mutual information, respectively, which has recently been proposed in machine learning and has become quite common since then. More generally, we question the idea of an additive decomposition of total uncertainty into its aleatoric and epistemic constituents.
Adaptive Test Generation Using a Large Language Model
Feb 20, 2023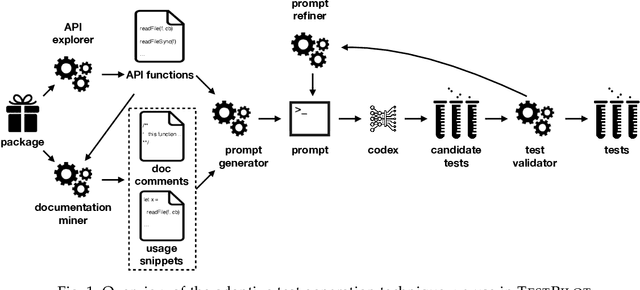
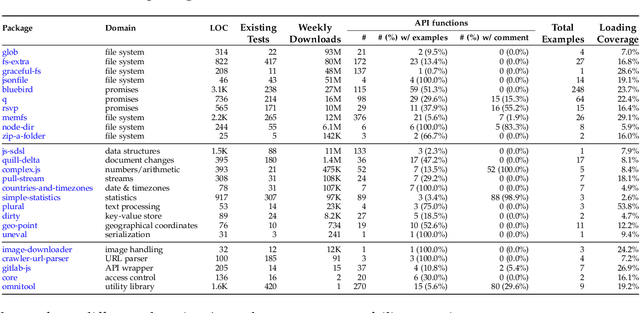

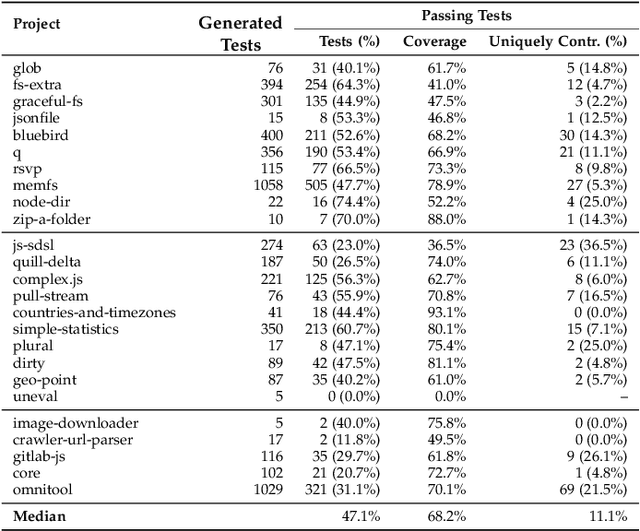
Unit tests play a key role in ensuring the correctness of software. However, manually creating unit tests is a laborious task, motivating the need for automation. This paper presents TestPilot, an adaptive test generation technique that leverages Large Language Models (LLMs). TestPilot uses Codex, an off-the-shelf LLM, to automatically generate unit tests for a given program without requiring additional training or few-shot learning on examples of existing tests. In our approach, Codex is provided with prompts that include the signature and implementation of a function under test, along with usage examples extracted from documentation. If a generated test fails, TestPilot's adaptive component attempts to generate a new test that fixes the problem by re-prompting the model with the failing test and error message. We created an implementation of TestPilot for JavaScript and evaluated it on 25 npm packages with a total of 1,684 API functions to generate tests for. Our results show that the generated tests achieve up to 93.1% statement coverage (median 68.2%). Moreover, on average, 58.5% of the generated tests contain at least one assertion that exercises functionality from the package under test. Our experiments with excluding parts of the information included in the prompts show that all components contribute towards the generation of effective test suites. Finally, we find that TestPilot does not generate memorized tests: 92.7% of our generated tests have $\leq$ 50% similarity with existing tests (as measured by normalized edit distance), with none of them being exact copies.
Large-Scale Traffic Data Imputation with Spatiotemporal Semantic Understanding
Jan 27, 2023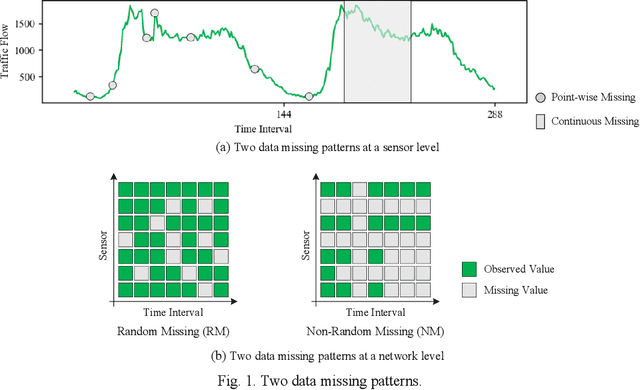
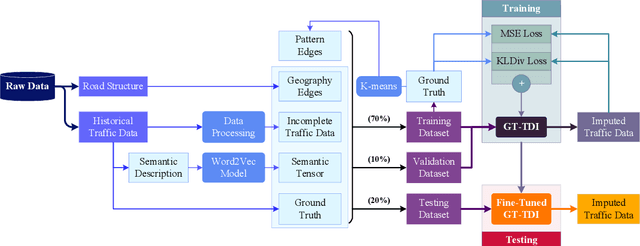
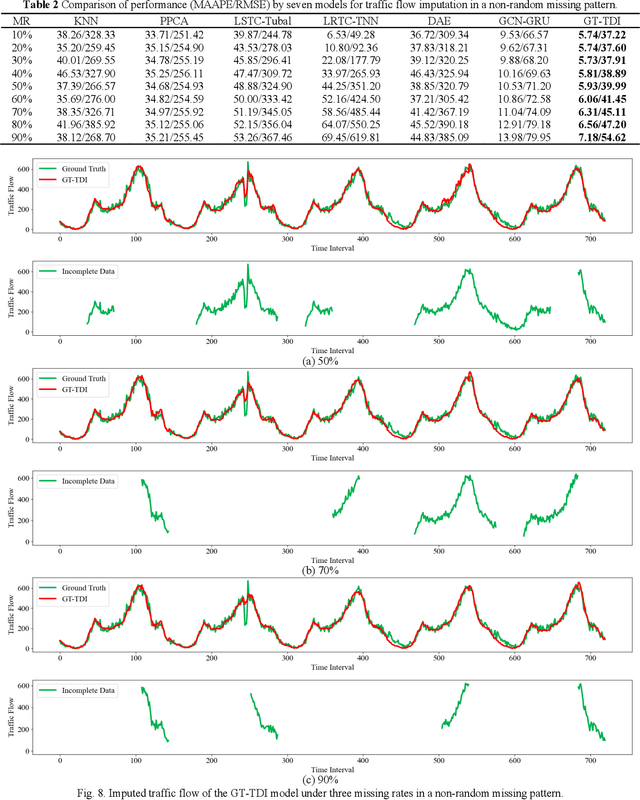
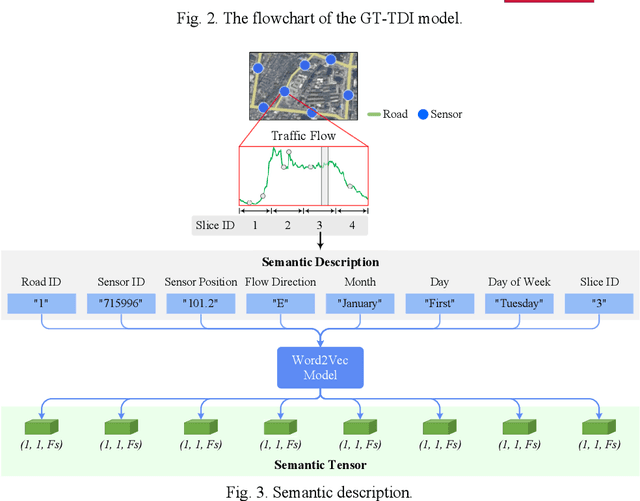
Large-scale data missing is a challenging problem in Intelligent Transportation Systems (ITS). Many studies have been carried out to impute large-scale traffic data by considering their spatiotemporal correlations at a network level. In existing traffic data imputations, however, rich semantic information of a road network has been largely ignored when capturing network-wide spatiotemporal correlations. This study proposes a Graph Transformer for Traffic Data Imputation (GT-TDI) model to impute large-scale traffic data with spatiotemporal semantic understanding of a road network. Specifically, the proposed model introduces semantic descriptions consisting of network-wide spatial and temporal information of traffic data to help the GT-TDI model capture spatiotemporal correlations at a network level. The proposed model takes incomplete data, the social connectivity of sensors, and semantic descriptions as input to perform imputation tasks with the help of Graph Neural Networks (GNN) and Transformer. On the PeMS freeway dataset, extensive experiments are conducted to compare the proposed GT-TDI model with conventional methods, tensor factorization methods, and deep learning-based methods. The results show that the proposed GT-TDI outperforms existing methods in complex missing patterns and diverse missing rates. The code of the GT-TDI model will be available at https://github.com/KP-Zhang/GT-TDI.
Inter-View Depth Consistency Testing in Depth Difference Subspace
Jan 27, 2023
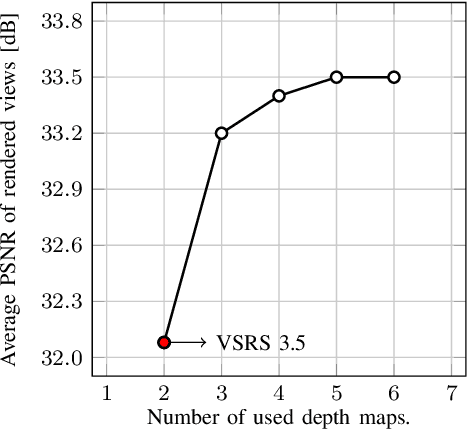
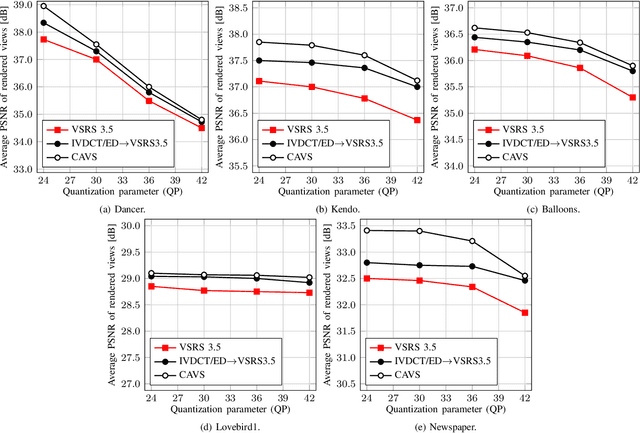
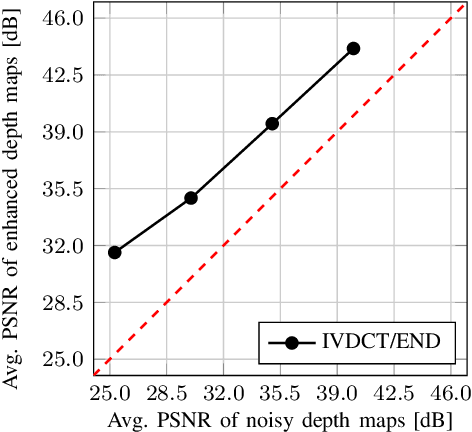
Multiview depth imagery will play a critical role in free-viewpoint television. This technology requires high quality virtual view synthesis to enable viewers to move freely in a dynamic real world scene. Depth imagery at different viewpoints is used to synthesize an arbitrary number of novel views. Usually, depth images at multiple viewpoints are estimated individually by stereo-matching algorithms, and hence, show lack of interview consistency. This inconsistency affects the quality of view synthesis negatively. This paper proposes a method for depth consistency testing in depth difference subspace to enhance the depth representation of a scene across multiple viewpoints. Furthermore, we propose a view synthesis algorithm that uses the obtained consistency information to improve the visual quality of virtual views at arbitrary viewpoints. Our method helps us to find a linear subspace for our depth difference measurements in which we can test the inter-view consistency efficiently. With this, our approach is able to enhance the depth information for real world scenes. In combination with our consistency-adaptive view synthesis, we improve the visual experience of the free-viewpoint user. The experiments show that our approach enhances the objective quality of virtual views by up to 1.4 dB. The advantage for the subjective quality is also demonstrated.
Information Threshold, Bayesian Inference and Decision-Making
Jun 05, 2022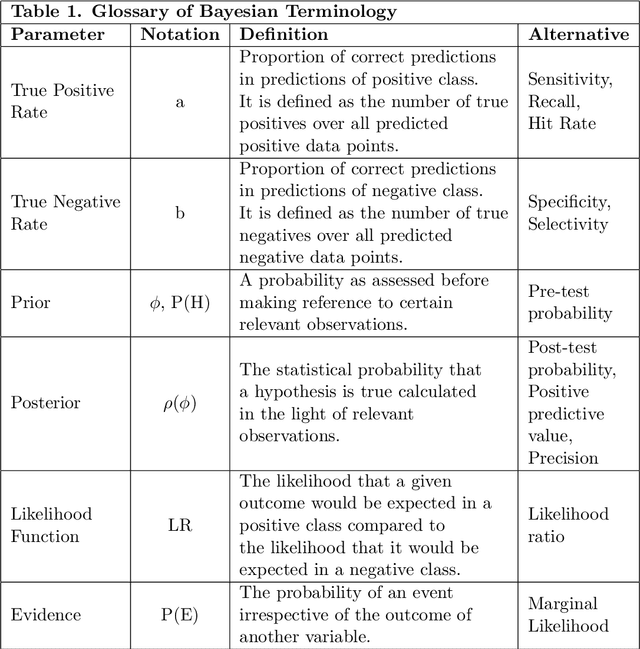
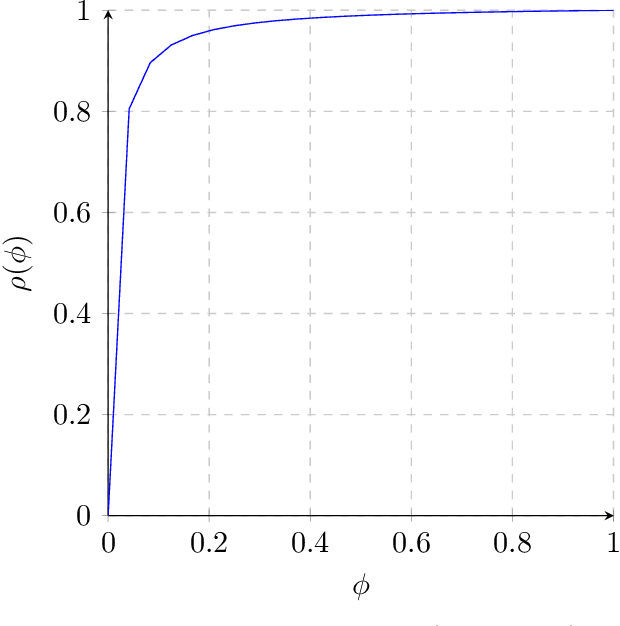

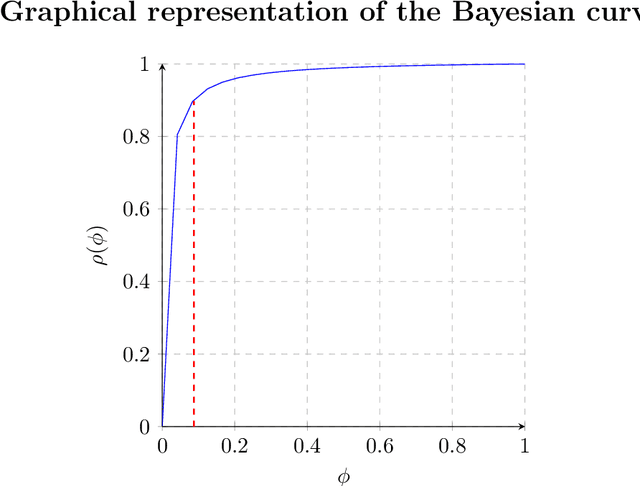
We define the information threshold as the point of maximum curvature in the prior vs. posterior Bayesian curve, both of which are described as a function of the true positive and negative rates of the classification system in question. The nature of the threshold is such that for sufficiently adequate binary classification systems, retrieving excess information beyond the threshold does not significantly alter the reliability of our classification assessment. We hereby introduce the "marital status thought experiment" to illustrate this idea and report a previously undefined mathematical relationship between the Bayesian prior and posterior, which may have significant philosophical and epistemological implications in decision theory. Where the prior probability is a scalar between 0 and 1 given by $\phi$ and the posterior is a scalar between 0 and 1 given by $\rho$, then at the information threshold, $\phi_e$: $\phi_e + \rho_e = 1$ Otherwise stated, given some degree of prior belief, we may assert its persuasiveness when sufficient quality evidence yields a posterior so that their combined sum equals 1. Retrieving further evidence beyond this point does not significantly improve the posterior probability, and may serve as a benchmark for confidence in decision-making.
The 2022 n2c2/UW Shared Task on Extracting Social Determinants of Health
Jan 13, 2023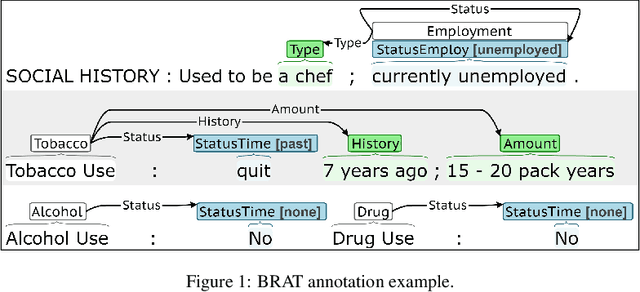
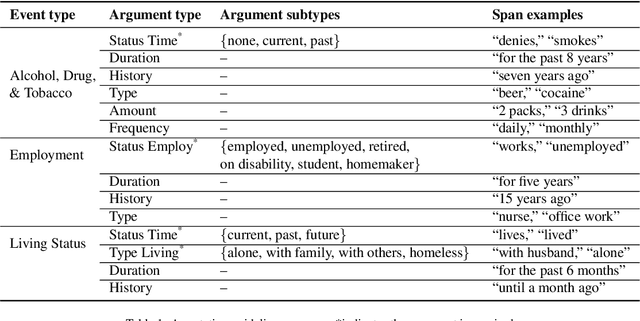

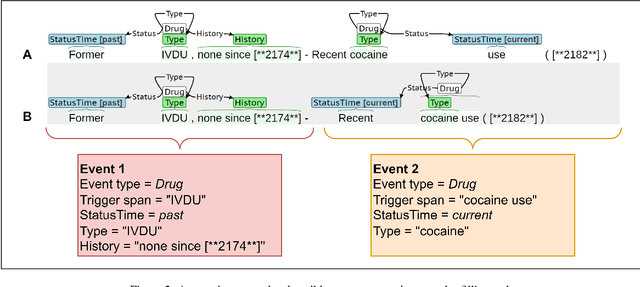
Objective: The n2c2/UW SDOH Challenge explores the extraction of social determinant of health (SDOH) information from clinical notes. The objectives include the advancement of natural language processing (NLP) information extraction techniques for SDOH and clinical information more broadly. This paper presents the shared task, data, participating teams, performance results, and considerations for future work. Materials and Methods: The task used the Social History Annotated Corpus (SHAC), which consists of clinical text with detailed event-based annotations for SDOH events such as alcohol, drug, tobacco, employment, and living situation. Each SDOH event is characterized through attributes related to status, extent, and temporality. The task includes three subtasks related to information extraction (Subtask A), generalizability (Subtask B), and learning transfer (Subtask C). In addressing this task, participants utilized a range of techniques, including rules, knowledge bases, n-grams, word embeddings, and pretrained language models (LM). Results: A total of 15 teams participated, and the top teams utilized pretrained deep learning LM. The top team across all subtasks used a sequence-to-sequence approach achieving 0.901 F1 for Subtask A, 0.774 F1 Subtask B, and 0.889 F1 for Subtask C. Conclusions: Similar to many NLP tasks and domains, pretrained LM yielded the best performance, including generalizability and learning transfer. An error analysis indicates extraction performance varies by SDOH, with lower performance achieved for conditions, like substance use and homelessness, that increase health risks (risk factors) and higher performance achieved for conditions, like substance abstinence and living with family, that reduce health risks (protective factors).
URCDC-Depth: Uncertainty Rectified Cross-Distillation with CutFlip for Monocular Depth Estimation
Feb 17, 2023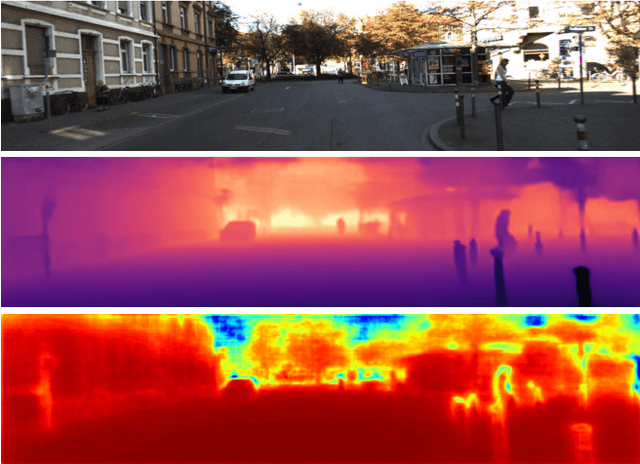
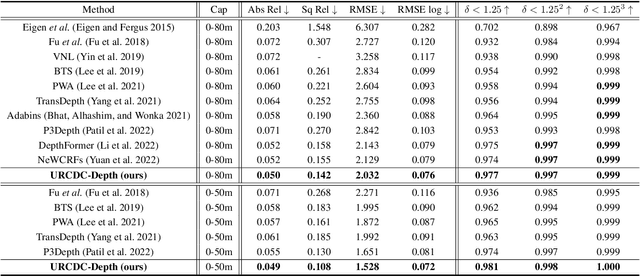
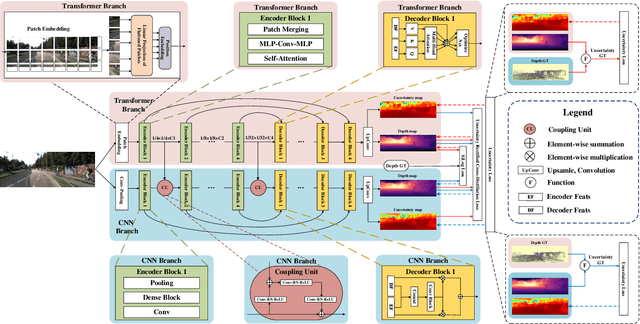
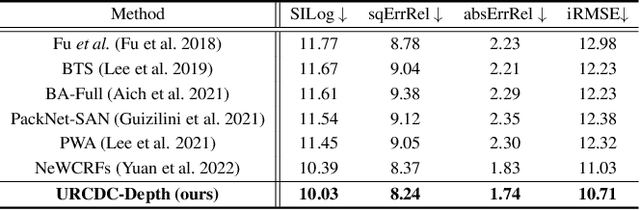
This work aims to estimate a high-quality depth map from a single RGB image. Due to the lack of depth clues, making full use of the long-range correlation and the local information is critical for accurate depth estimation. Towards this end, we introduce an uncertainty rectified cross-distillation between Transformer and convolutional neural network (CNN) to learn a unified depth estimator. Specifically, we use the depth estimates from the Transformer branch and the CNN branch as pseudo labels to teach each other. Meanwhile, we model the pixel-wise depth uncertainty to rectify the loss weights of noisy pseudo labels. To avoid the large capacity gap induced by the strong Transformer branch deteriorating the cross-distillation, we transfer the feature maps from Transformer to CNN and design coupling units to assist the weak CNN branch to leverage the transferred features. Furthermore, we propose a surprisingly simple yet highly effective data augmentation technique CutFlip, which enforces the model to exploit more valuable clues apart from the vertical image position for depth inference. Extensive experiments demonstrate that our model, termed~\textbf{URCDC-Depth}, exceeds previous state-of-the-art methods on the KITTI, NYU-Depth-v2 and SUN RGB-D datasets, even with no additional computational burden at inference time. The source code is publicly available at \url{https://github.com/ShuweiShao/URCDC-Depth}.
Detection of Epilepsy Seizure using Different Dimensionality Reduction Techniques and Machine Learning on Transform Domain
Feb 17, 2023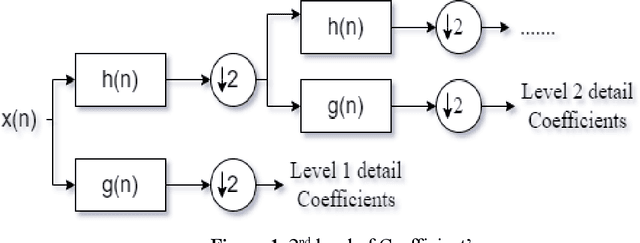
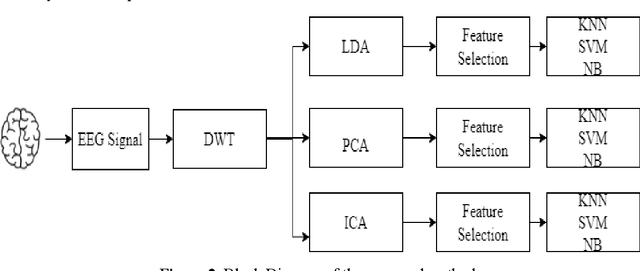
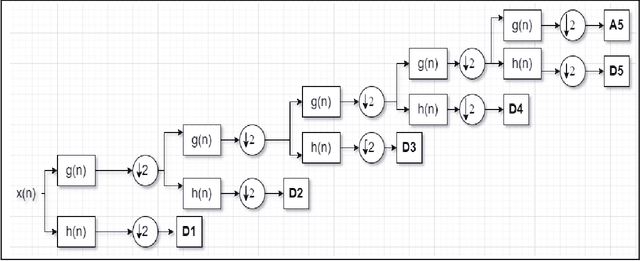
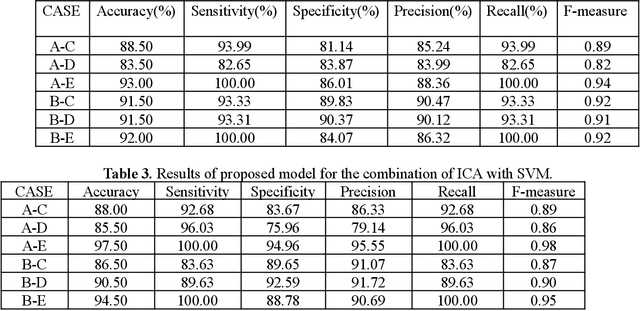
An Electroencephalogram (EEG) is a non-invasive exam that records the electrical activity of the brain. This exam is used to help diagnose conditions such as different brain problems. EEG signals are taken for the purpose of epilepsy detection and with Discrete Wavelet Transform (DWT) and machine learning classifier, they perform epilepsy detection. In Epilepsy seizure detection, mainly machine learning classifiers and statistical features are used. The hidden information in the EEG signal is useful for detecting diseases affecting the brain. Sometimes it is very difficult to identify the minimum changes in the EEG in time and frequency domains purpose. The DWT can give a good decomposition of the signals in different frequency bands and feature extraction. We use the tri-dimensionality reduction algorithm.; Principal Component Analysis (PCA), Independent Component Analysis (ICA) and Linear Discriminant Analysis (LDA). Finally, features are selected by using a fusion rule and at the last step three different classifiers Support Vector Machine (SVM), Naive Bayes (NB) and K-Nearest-Neighbor (KNN) has been used for the classification. The proposed framework is tested on the Bonn dataset and the simulation results provide the maximum accuracy for the combination of LDA and NB for 10-fold cross validation technique. It shows the maximum average sensitivity, specificity, accuracy, Precision and Recall of 100%, 100%, 100%, 100% and 100%. The results prove the effectiveness of this model.
Apple scab detection in orchards using deep learning on colour and multispectral images
Feb 17, 2023


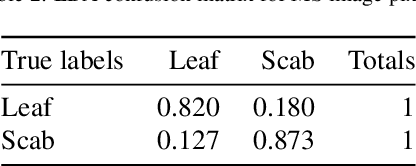
Apple scab is a fungal disease caused by Venturia inaequalis. Disease is of particular concern for growers, as it causes significant damage to fruit and leaves, leading to loss of fruit and yield. This article examines the ability of deep learning and hyperspectral imaging to accurately identify an apple symptom infection in apple trees. In total, 168 image scenes were collected using conventional RGB and Visible to Near-infrared (VIS-NIR) spectral imaging (8 channels) in infected orchards. Spectral data were preprocessed with an Artificial Neural Network (ANN) trained in segmentation to detect scab pixels based on spectral information. Linear Discriminant Analysis (LDA) was used to find the most discriminating channels in spectral data based on the healthy leaf and scab infested leaf spectra. Five combinations of false-colour images were created from the spectral data and the segmentation net results. The images were trained and evaluated with a modified version of the YOLOv5 network. Despite the promising results of deep learning using RGB images (P=0.8, mAP@50=0.73), the detection of apple scab in apple trees using multispectral imaging proved to be a difficult task. The high-light environment of the open field made it difficult to collect a balanced spectrum from the multispectral camera, since the infrared channel and the visible channels needed to be constantly balanced so that they did not overexpose in the images.