 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Priori Determination of the Pretest Probability
Jan 08, 2024In this manuscript, we present various proposed methods estimate the prevalence of disease, a critical prerequisite for the adequate interpretation of screening tests. To address the limitations of these approaches, which revolve primarily around their a posteriori nature, we introduce a novel method to estimate the pretest probability of disease, a priori, utilizing the Logit function from the logistic regression model. This approach is a modification of McGee's heuristic, originally designed for estimating the posttest probability of disease. In a patient presenting with $n_\theta$ signs or symptoms, the minimal bound of the pretest probability, $\phi$, can be approximated by: $\phi \approx \frac{1}{5}{ln\left[\displaystyle\prod_{\theta=1}^{i}\kappa_\theta\right]}$ where $ln$ is the natural logarithm, and $\kappa_\theta$ is the likelihood ratio associated with the sign or symptom in question.
Information Threshold, Bayesian Inference and Decision-Making
Jun 05, 2022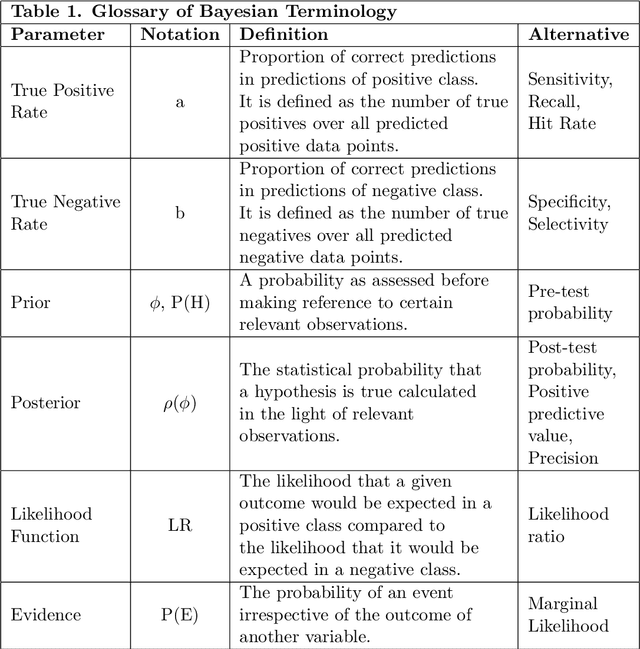
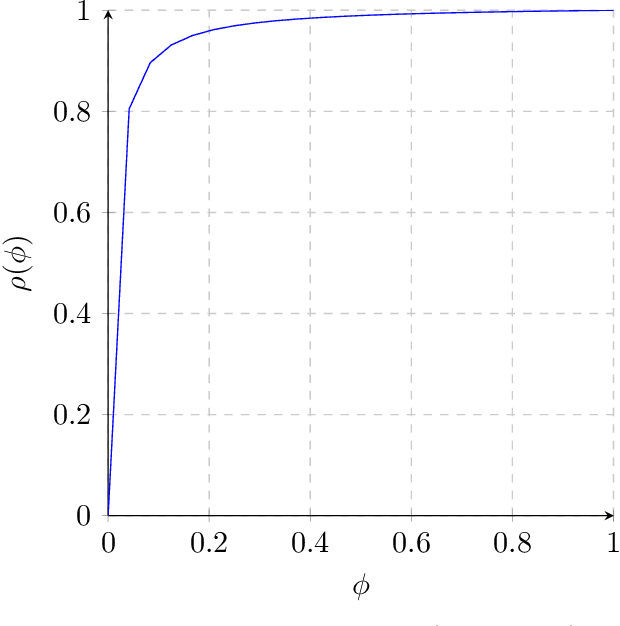

We define the information threshold as the point of maximum curvature in the prior vs. posterior Bayesian curve, both of which are described as a function of the true positive and negative rates of the classification system in question. The nature of the threshold is such that for sufficiently adequate binary classification systems, retrieving excess information beyond the threshold does not significantly alter the reliability of our classification assessment. We hereby introduce the "marital status thought experiment" to illustrate this idea and report a previously undefined mathematical relationship between the Bayesian prior and posterior, which may have significant philosophical and epistemological implications in decision theory. Where the prior probability is a scalar between 0 and 1 given by $\phi$ and the posterior is a scalar between 0 and 1 given by $\rho$, then at the information threshold, $\phi_e$: $\phi_e + \rho_e = 1$ Otherwise stated, given some degree of prior belief, we may assert its persuasiveness when sufficient quality evidence yields a posterior so that their combined sum equals 1. Retrieving further evidence beyond this point does not significantly improve the posterior probability, and may serve as a benchmark for confidence in decision-making.
Prevalence Threshold and bounds in the Accuracy of Binary Classification Systems
Dec 25, 2021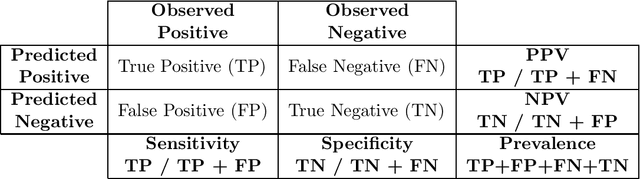
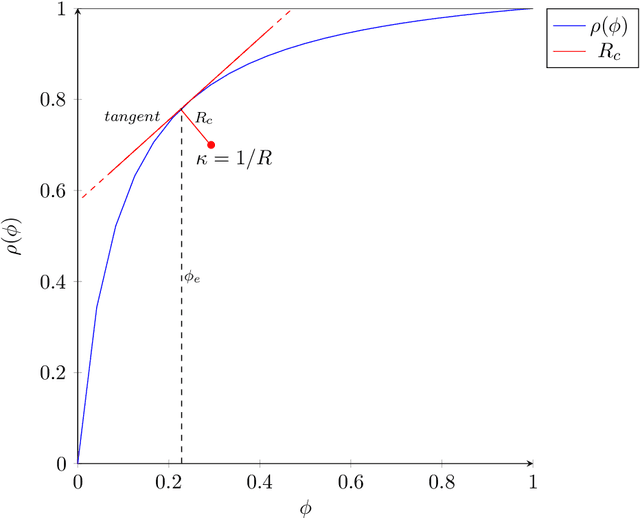
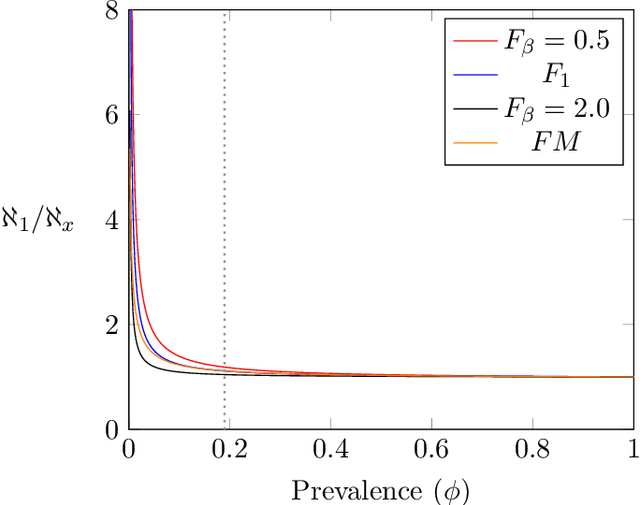
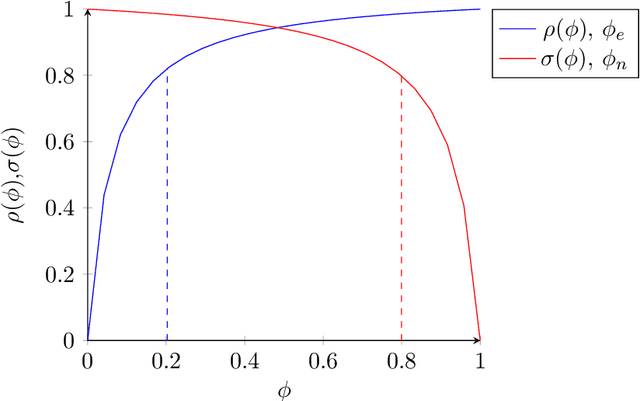
The accuracy of binary classification systems is defined as the proportion of correct predictions - both positive and negative - made by a classification model or computational algorithm. A value between 0 (no accuracy) and 1 (perfect accuracy), the accuracy of a classification model is dependent on several factors, notably: the classification rule or algorithm used, the intrinsic characteristics of the tool used to do the classification, and the relative frequency of the elements being classified. Several accuracy metrics exist, each with its own advantages in different classification scenarios. In this manuscript, we show that relative to a perfect accuracy of 1, the positive prevalence threshold ($\phi_e$), a critical point of maximum curvature in the precision-prevalence curve, bounds the $F{_{\beta}}$ score between 1 and 1.8/1.5/1.2 for $\beta$ values of 0.5/1.0/2.0, respectively; the $F_1$ score between 1 and 1.5, and the Fowlkes-Mallows Index (FM) between 1 and $\sqrt{2} \approx 1.414$. We likewise describe a novel $negative$ prevalence threshold ($\phi_n$), the level of sharpest curvature for the negative predictive value-prevalence curve, such that $\phi_n$ $>$ $\phi_e$. The area between both these thresholds bounds the Matthews Correlation Coefficient (MCC) between $\sqrt{2}/2$ and $\sqrt{2}$. Conversely, the ratio of the maximum possible accuracy to that at any point below the prevalence threshold, $\phi_e$, goes to infinity with decreasing prevalence. Though applications are numerous, the ideas herein discussed may be used in computational complexity theory, artificial intelligence, and medical screening, amongst others. Where computational time is a limiting resource, attaining the prevalence threshold in binary classification systems may be sufficient to yield levels of accuracy comparable to that under maximum prevalence.