 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Universal coding, intrinsic volumes, and metric complexity
Mar 13, 2023
We study sequential probability assignment in the Gaussian setting, where the goal is to predict, or equivalently compress, a sequence of real-valued observations almost as well as the best Gaussian distribution with mean constrained to a given subset of $\mathbf{R}^n$. First, in the case of a convex constraint set $K$, we express the hardness of the prediction problem (the minimax regret) in terms of the intrinsic volumes of $K$; specifically, it equals the logarithm of the Wills functional from convex geometry. We then establish a comparison inequality for the Wills functional in the general nonconvex case, which underlines the metric nature of this quantity and generalizes the Slepian-Sudakov-Fernique comparison principle for the Gaussian width. Motivated by this inequality, we characterize the exact order of magnitude of the considered functional for a general nonconvex set, in terms of global covering numbers and local Gaussian widths. This implies metric isomorphic estimates for the log-Laplace transform of the intrinsic volume sequence of a convex body. As part of our analysis, we also characterize the minimax redundancy for a general constraint set. We finally relate and contrast our findings with classical asymptotic results in information theory.
FusionLoc: Camera-2D LiDAR Fusion Using Multi-Head Self-Attention for End-to-End Serving Robot Relocalization
Mar 13, 2023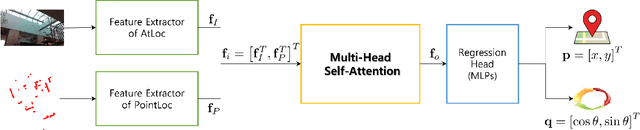
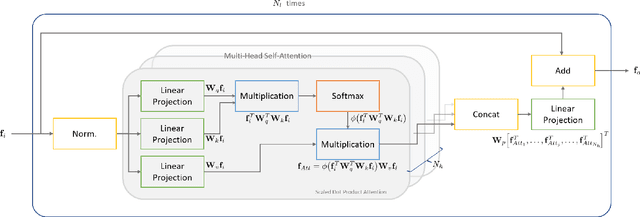
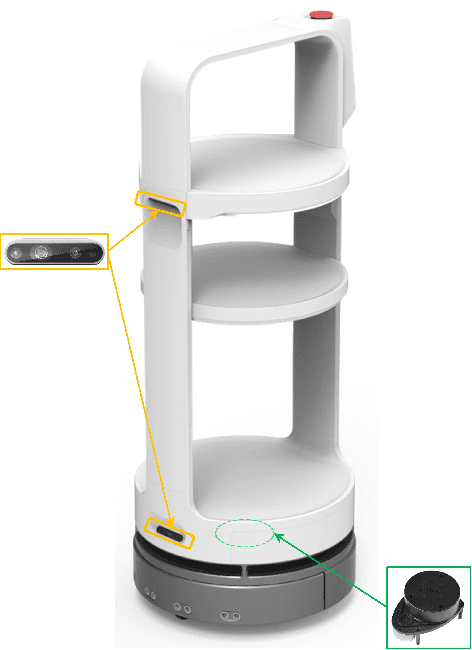
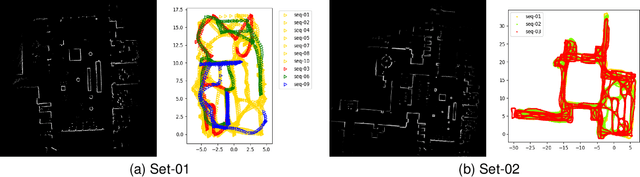
With the recent development of autonomous driving technology, as the pursuit of efficiency for repetitive tasks and the value of non-face-to-face services increase, mobile service robots such as delivery robots and serving robots attract attention, and their demands are increasing day by day. However, when something goes wrong, most commercial serving robots need to return to their starting position and orientation to operate normally again. In this paper, we focus on end-to-end relocalization of serving robots to address the problem. It is to predict robot pose directly from only the onboard sensor data using neural networks. In particular, we propose a deep neural network architecture for the relocalization based on camera-2D LiDAR sensor fusion. We call the proposed method FusionLoc. In the proposed method, the multi-head self-attention complements different types of information captured by the two sensors. Our experiments on a dataset collected by a commercial serving robot demonstrate that FusionLoc can provide better performances than previous relocalization methods taking only a single image or a 2D LiDAR point cloud as well as a straightforward fusion method concatenating their features.
A Smoothing Algorithm for Minimum Sensing Path Plans in Gaussian Belief Space
Mar 13, 2023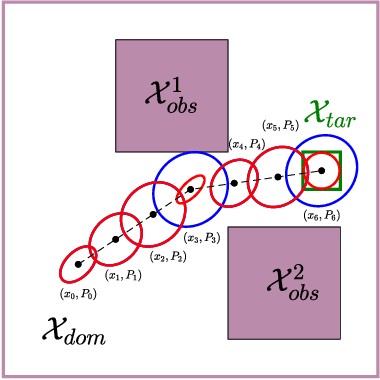
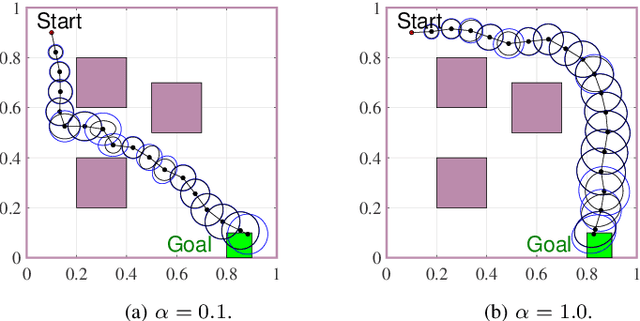
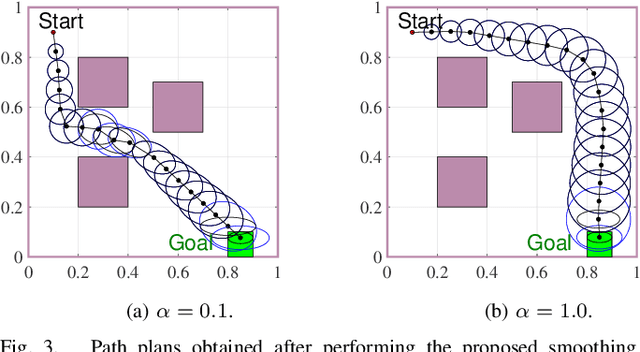
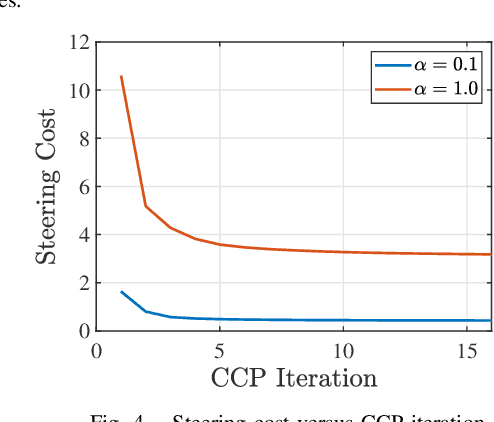
This paper explores minimum sensing navigation of robots in environments cluttered with obstacles. The general objective is to find a path plan to a goal region that requires minimal sensing effort. In [1], the information-geometric RRT* (IG-RRT*) algorithm was proposed to efficiently find such a path. However, like any stochastic sampling-based planner, the computational complexity of IG-RRT* grows quickly, impeding its use with a large number of nodes. To remedy this limitation, we suggest running IG-RRT* with a moderate number of nodes, and then using a smoothing algorithm to adjust the path obtained. To develop a smoothing algorithm, we explicitly formulate the minimum sensing path planning problem as an optimization problem. For this formulation, we introduce a new safety constraint to impose a bound on the probability of collision with obstacles in continuous-time, in contrast to the common discrete-time approach. The problem is amenable to solution via the convex-concave procedure (CCP). We develop a CCP algorithm for the formulated optimization and use this algorithm for path smoothing. We demonstrate the efficacy of the proposed approach through numerical simulations.
DRISHTI: Visual Navigation Assistant for Visually Impaired
Mar 13, 2023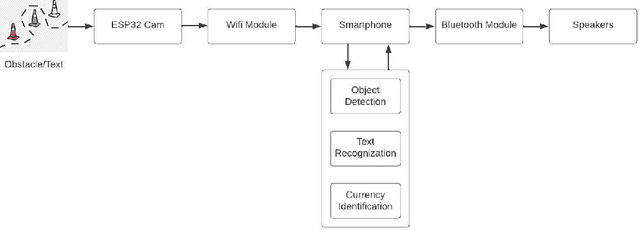
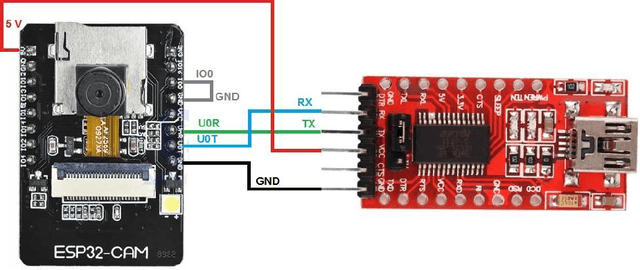


In today's society, where independent living is becoming increasingly important, it can be extremely constricting for those who are blind. Blind and visually impaired (BVI) people face challenges because they need manual support to prompt information about their environment. In this work, we took our first step towards developing an affordable and high-performing eye wearable assistive device, DRISHTI, to provide visual navigation assistance for BVI people. This system comprises a camera module, ESP32 processor, Bluetooth module, smartphone and speakers. Using artificial intelligence, this system is proposed to detect and understand the nature of the users' path and obstacles ahead of the user in that path and then inform BVI users about it via audio output to enable them to acquire directions by themselves on their journey. This first step discussed in this paper involves establishing a proof-of-concept of achieving the right balance of affordability and performance by testing an initial software integration of a currency detection algorithm on a low-cost embedded arrangement. This work will lay the foundation for our upcoming works toward achieving the goal of assisting the maximum of BVI people around the globe in moving independently.
Mirror U-Net: Marrying Multimodal Fission with Multi-task Learning for Semantic Segmentation in Medical Imaging
Mar 13, 2023Positron Emission Tomography (PET) and Computer Tomography (CT) are routinely used together to detect tumors. PET/CT segmentation models can automate tumor delineation, however, current multimodal models do not fully exploit the complementary information in each modality, as they either concatenate PET and CT data or fuse them at the decision level. To combat this, we propose Mirror U-Net, which replaces traditional fusion methods with multimodal fission by factorizing the multimodal representation into modality-specific branches and an auxiliary multimodal decoder. At these branches, Mirror U-Net assigns a task tailored to each modality to reinforce unimodal features while preserving multimodal features in the shared representation. In contrast to previous methods that use either fission or multi-task learning, Mirror U-Net combines both paradigms in a unified framework. We explore various task combinations and examine which parameters to share in the model. We evaluate Mirror U-Net on the AutoPET PET/CT and on the multimodal MSD BrainTumor datasets, demonstrating its effectiveness in multimodal segmentation and achieving state-of-the-art performance on both datasets. Our code will be made publicly available.
Fine-tuning ClimateBert transformer with ClimaText for the disclosure analysis of climate-related financial risks
Mar 21, 2023
In recent years there has been a growing demand from financial agents, especially from particular and institutional investors, for companies to report on climate-related financial risks. A vast amount of information, in text format, can be expected to be disclosed in the short term by firms in order to identify these types of risks in their financial and non financial reports, particularly in response to the growing regulation that is being passed on the matter. To this end, this paper applies state-of-the-art NLP techniques to achieve the detection of climate change in text corpora. We use transfer learning to fine-tune two transformer models, BERT and ClimateBert -a recently published DistillRoBERTa-based model that has been specifically tailored for climate text classification-. These two algorithms are based on the transformer architecture which enables learning the contextual relationships between words in a text. We carry out the fine-tuning process of both models on the novel Clima-Text database, consisting of data collected from Wikipedia, 10K Files Reports and web-based claims. Our text classification model obtained from the ClimateBert fine-tuning process on ClimaText, outperforms the models created with BERT and the current state-of-the-art transformer in this particular problem. Our study is the first one to implement on the ClimaText database the recently published ClimateBert algorithm. Based on our results, it can be said that ClimateBert fine-tuned on ClimaText is an outstanding tool within the NLP pre-trained transformer models that may and should be used by investors, institutional agents and companies themselves to monitor the disclosure of climate risk in financial reports. In addition, our transfer learning methodology is cheap in computational terms, thus allowing any organization to perform it.
Finding Minimum-Cost Explanations for Predictions made by Tree Ensembles
Mar 16, 2023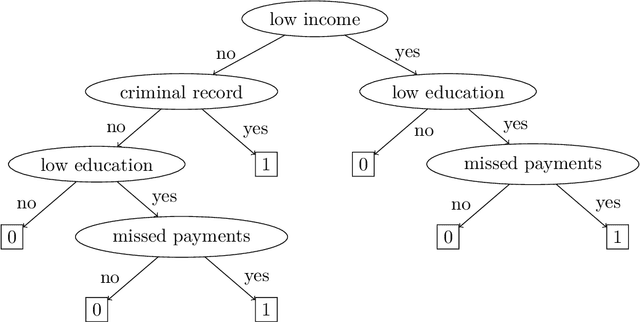

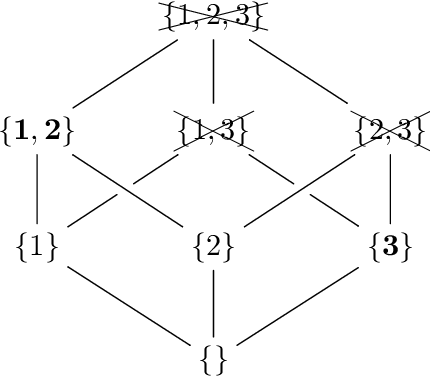
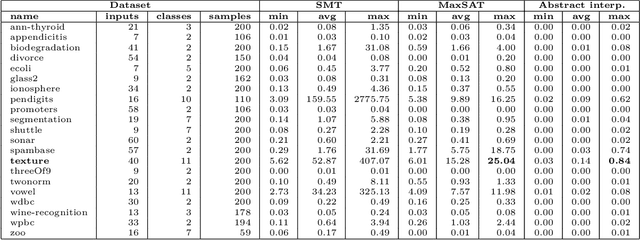
The ability to explain why a machine learning model arrives at a particular prediction is crucial when used as decision support by human operators of critical systems. The provided explanations must be provably correct, and preferably without redundant information, called minimal explanations. In this paper, we aim at finding explanations for predictions made by tree ensembles that are not only minimal, but also minimum with respect to a cost function. To this end, we first present a highly efficient oracle that can determine the correctness of explanations, surpassing the runtime performance of current state-of-the-art alternatives by several orders of magnitude when computing minimal explanations. Secondly, we adapt an algorithm called MARCO from related works (calling it m-MARCO) for the purpose of computing a single minimum explanation per prediction, and demonstrate an overall speedup factor of two compared to the MARCO algorithm which enumerates all minimal explanations. Finally, we study the obtained explanations from a range of use cases, leading to further insights of their characteristics. In particular, we observe that in several cases, there are more than 100,000 minimal explanations to choose from for a single prediction. In these cases, we see that only a small portion of the minimal explanations are also minimum, and that the minimum explanations are significantly less verbose, hence motivating the aim of this work.
MICO: Selective Search with Mutual Information Co-training
Sep 09, 2022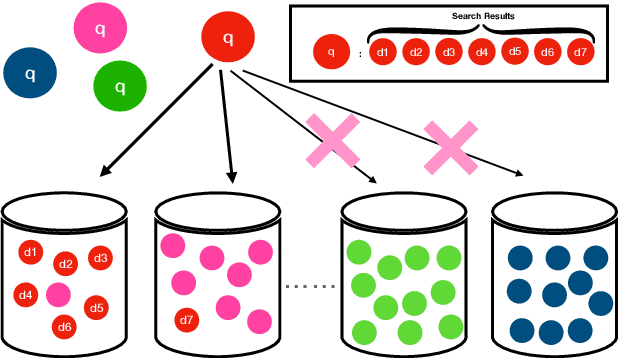
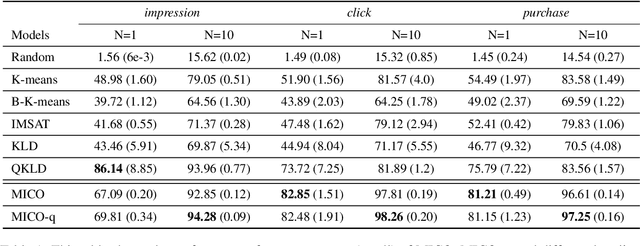
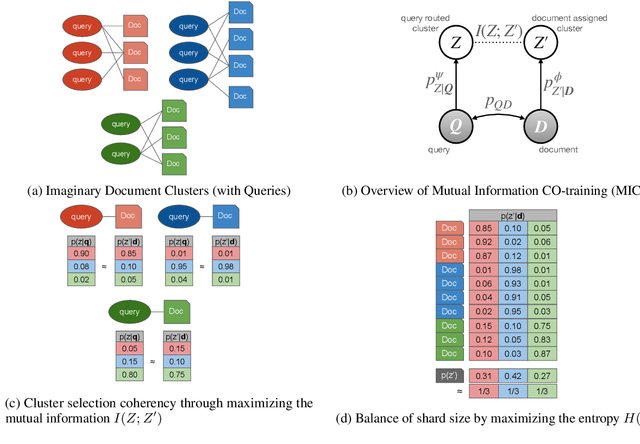
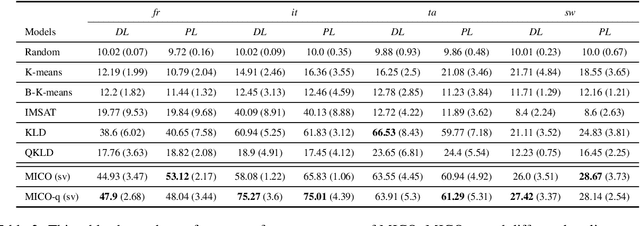
In contrast to traditional exhaustive search, selective search first clusters documents into several groups before all the documents are searched exhaustively by a query, to limit the search executed within one group or only a few groups. Selective search is designed to reduce the latency and computation in modern large-scale search systems. In this study, we propose MICO, a Mutual Information CO-training framework for selective search with minimal supervision using the search logs. After training, MICO does not only cluster the documents, but also routes unseen queries to the relevant clusters for efficient retrieval. In our empirical experiments, MICO significantly improves the performance on multiple metrics of selective search and outperforms a number of existing competitive baselines.
Censored Deep Reinforcement Patrolling with Information Criterion for Monitoring Large Water Resources using Autonomous Surface Vehicles
Oct 12, 2022
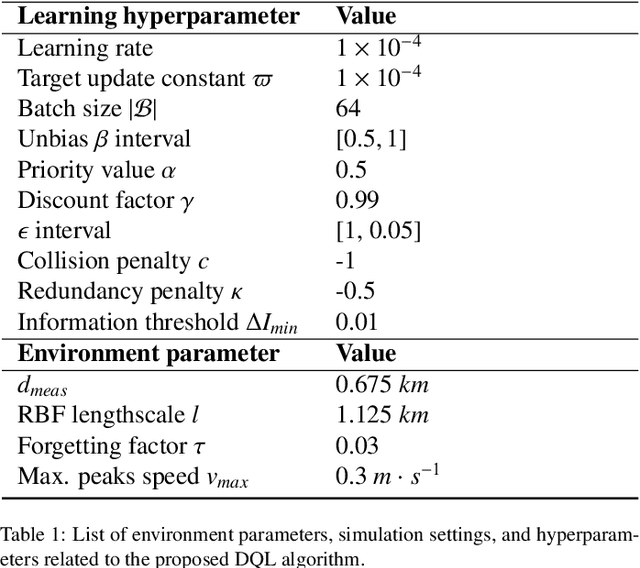
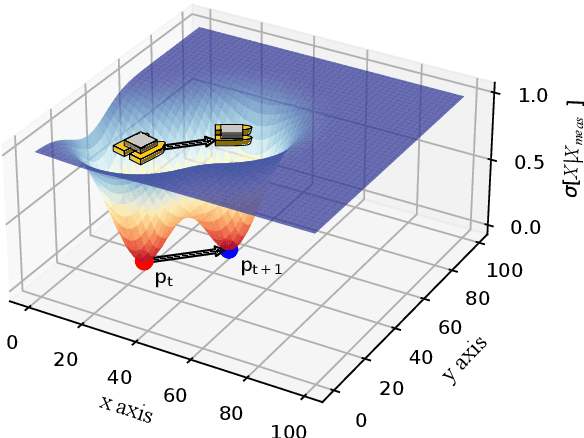
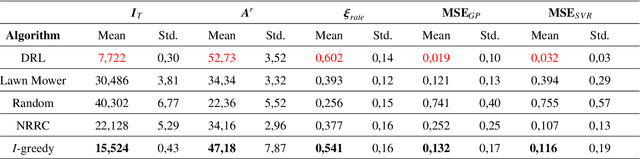
Monitoring and patrolling large water resources is a major challenge for conservation. The problem of acquiring data of an underlying environment that usually changes within time involves a proper formulation of the information. The use of Autonomous Surface Vehicles equipped with water quality sensor modules can serve as an early-warning system agents for contamination peak-detection, algae blooms monitoring, or oil-spill scenarios. In addition to information gathering, the vehicle must plan routes that are free of obstacles on non-convex maps. This work proposes a framework to obtain a collision-free policy that addresses the patrolling task for static and dynamic scenarios. Using information gain as a measure of the uncertainty reduction over data, it is proposed a Deep Q-Learning algorithm improved by a Q-Censoring mechanism for model-based obstacle avoidance. The obtained results demonstrate the usefulness of the proposed algorithm for water resource monitoring for static and dynamic scenarios. Simulations showed the use of noise-networks are a good choice for enhanced exploration, with 3 times less redundancy in the paths. Previous coverage strategies are also outperformed both in the accuracy of the obtained contamination model by a 13% on average and by a 37% in the detection of dangerous contamination peaks. Finally, these results indicate the appropriateness of the proposed framework for monitoring scenarios with autonomous vehicles.
Extracting Victim Counts from Text
Feb 23, 2023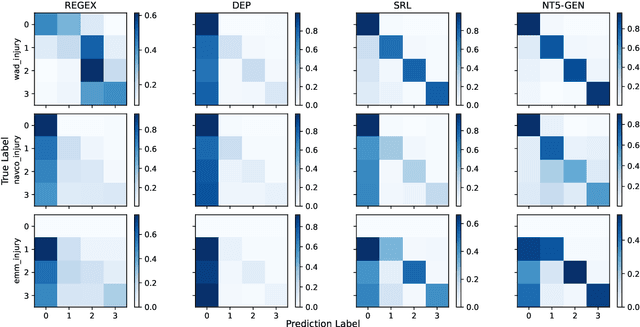
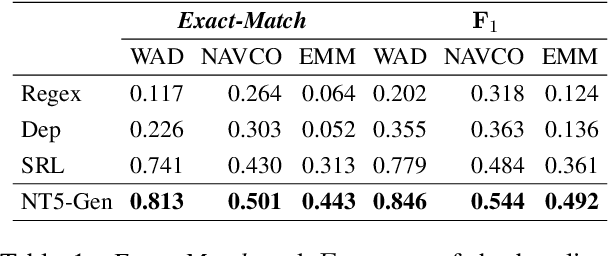

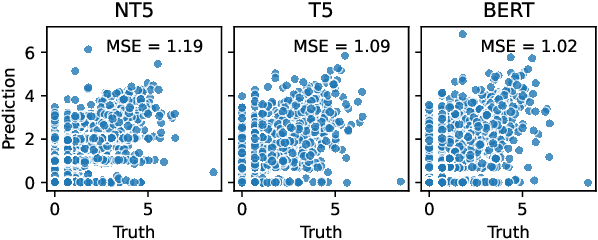
Decision-makers in the humanitarian sector rely on timely and exact information during crisis events. Knowing how many civilians were injured during an earthquake is vital to allocate aids properly. Information about such victim counts is often only available within full-text event descriptions from newspapers and other reports. Extracting numbers from text is challenging: numbers have different formats and may require numeric reasoning. This renders purely string matching-based approaches insufficient. As a consequence, fine-grained counts of injured, displaced, or abused victims beyond fatalities are often not extracted and remain unseen. We cast victim count extraction as a question answering (QA) task with a regression or classification objective. We compare regex, dependency parsing, semantic role labeling-based approaches, and advanced text-to-text models. Beyond model accuracy, we analyze extraction reliability and robustness which are key for this sensitive task. In particular, we discuss model calibration and investigate few-shot and out-of-distribution performance. Ultimately, we make a comprehensive recommendation on which model to select for different desiderata and data domains. Our work is among the first to apply numeracy-focused large language models in a real-world use case with a positive impact.