 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Weakly Supervised Semantic Segmentation Ensembles for Medical Imaging Systems
Mar 16, 2023
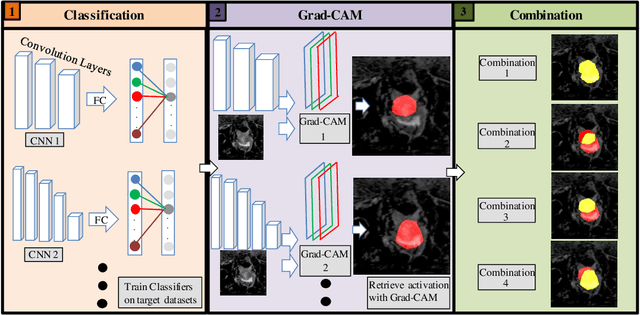
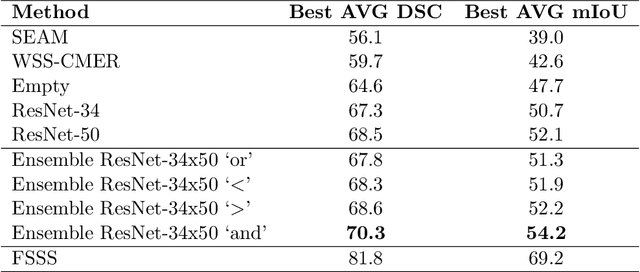
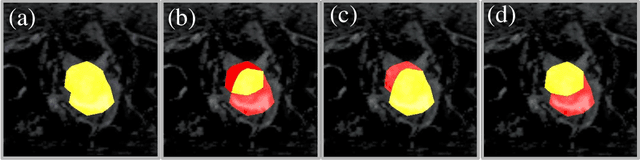
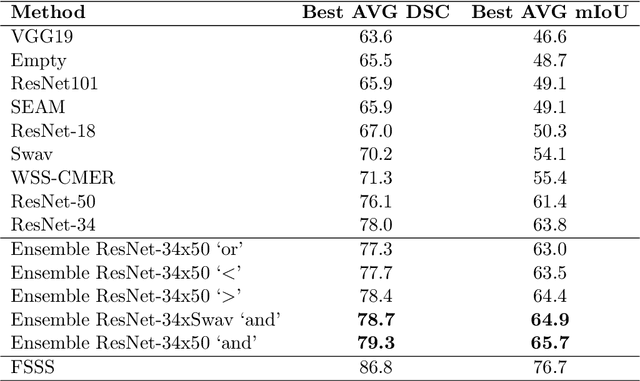
Reliable classification and detection of certain medical conditions, in images, with state-of-the-art semantic segmentation networks, require vast amounts of pixel-wise annotation. However, the public availability of such datasets is minimal. Therefore, semantic segmentation with image-level labels presents a promising alternative to this problem. Nevertheless, very few works have focused on evaluating this technique and its applicability to the medical sector. Due to their complexity and the small number of training examples in medical datasets, classifier-based weakly supervised networks like class activation maps (CAMs) struggle to extract useful information from them. However, most state-of-the-art approaches rely on them to achieve their improvements. Therefore, we propose a framework that can still utilize the low-quality CAM predictions of complicated datasets to improve the accuracy of our results. Our framework achieves that by first utilizing lower threshold CAMs to cover the target object with high certainty; second, by combining multiple low-threshold CAMs that even out their errors while highlighting the target object. We performed exhaustive experiments on the popular multi-modal BRATS and prostate DECATHLON segmentation challenge datasets. Using the proposed framework, we have demonstrated an improved dice score of up to 8% on BRATS and 6% on DECATHLON datasets compared to the previous state-of-the-art.
Multi-step planning with learned effects of (possibly partial) action executions
Mar 16, 2023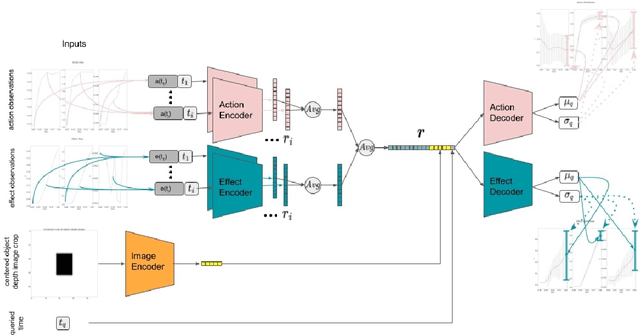
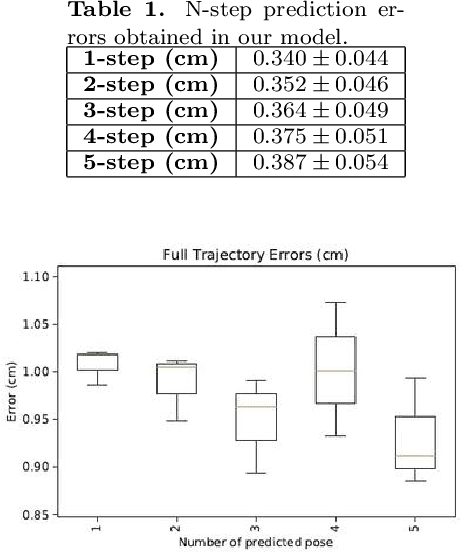
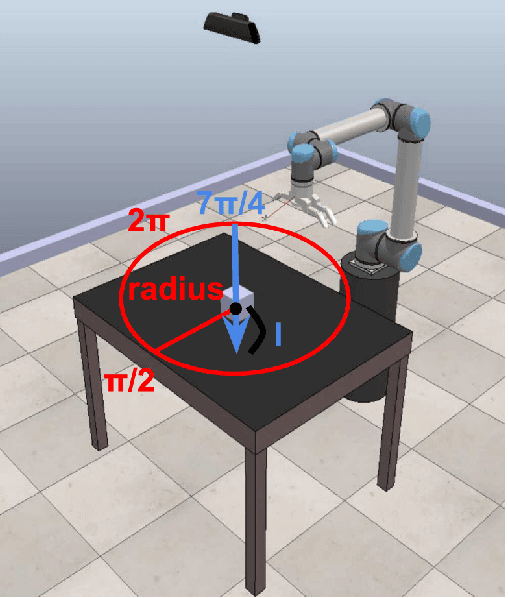
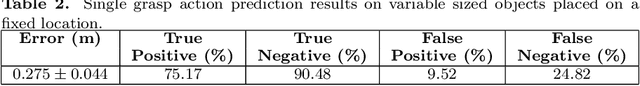
In this paper, we propose an affordance model, which is built on Conditional Neural Processes, that can predict effect trajectories given objects, action or effect information at any time. Affordances are represented in a latent representation that combines object, action and effect channels. This model allows us to make predictions of intermediate effects expected to be obtained from partial action executions, and this capability is used to make multi-step plans that include partial actions in order to achieve goals. We first show that our model can make accurate continuous effect predictions. We compared our model with a recent LSTM-based effect predictor using an existing dataset that includes lever-up actions. Next, we showed that our model can generate accurate effect predictions for push and grasp actions. Finally, we showed that our system can generate successful multi-step plans in order to bring objects to desired positions. Importantly, the proposed system generated more accurate and effective plans with partial action executions compared to plans that only consider full action executions. Although continuous effect prediction and multi-step planning based on learning affordances have been studied in the literature, continuous affordance and effect predictions have not been utilized in making accurate and fine-grained plans.
Fiber Tract Shape Measures Inform Prediction of Non-Imaging Phenotypes
Mar 16, 2023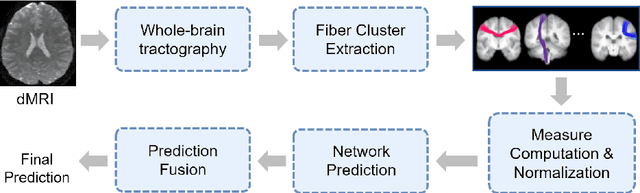
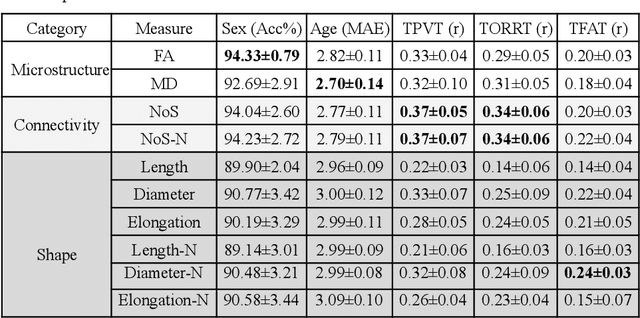
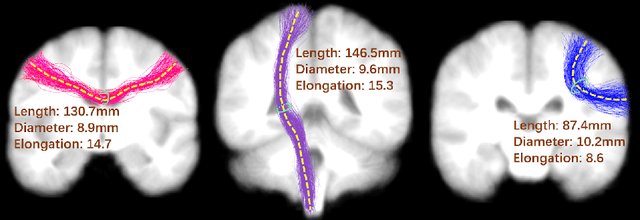
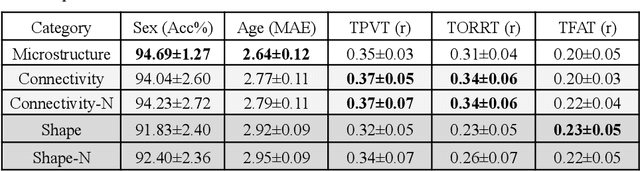
Neuroimaging measures of the brain's white matter connections can enable the prediction of non-imaging phenotypes, such as demographic and cognitive measures. Existing works have investigated traditional microstructure and connectivity measures from diffusion MRI tractography, without considering the shape of the connections reconstructed by tractography. In this paper, we investigate the potential of fiber tract shape features for predicting non-imaging phenotypes, both individually and in combination with traditional features. We focus on three basic shape features: length, diameter, and elongation. Two different prediction methods are used, including a traditional regression method and a deep-learning-based prediction method. Experiments use an efficient two-stage fusion strategy for prediction using microstructure, connectivity, and shape measures. To reduce predictive bias due to brain size, normalized shape features are also investigated. Experimental results on the Human Connectome Project (HCP) young adult dataset (n=1065) demonstrate that individual shape features are predictive of non-imaging phenotypes. When combined with microstructure and connectivity features, shape features significantly improve performance for predicting the cognitive score TPVT (NIH Toolbox picture vocabulary test). Overall, this study demonstrates that the shape of fiber tracts contains useful information for the description and study of the living human brain using machine learning.
Efficient Computation Sharing for Multi-Task Visual Scene Understanding
Mar 16, 2023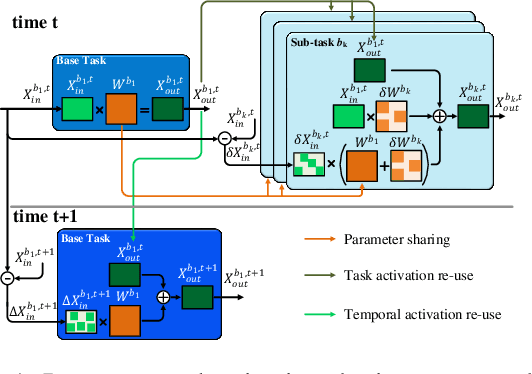
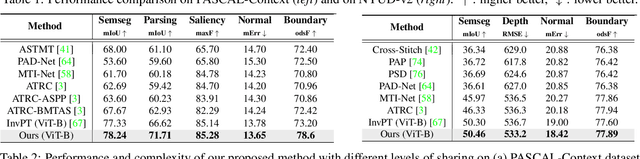
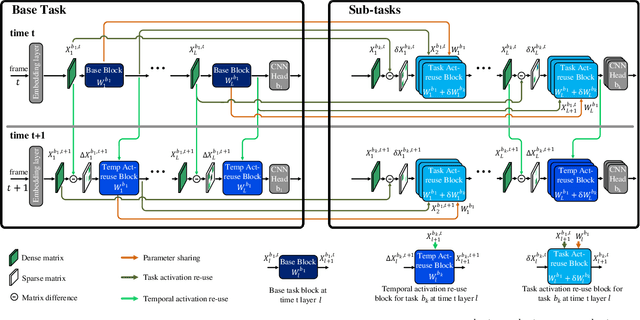
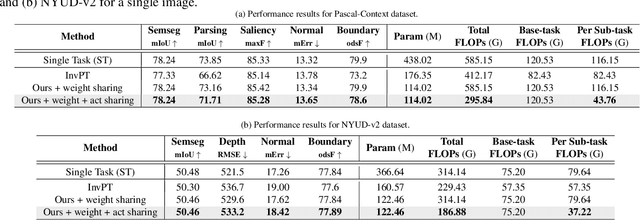
Solving multiple visual tasks using individual models can be resource-intensive, while multi-task learning can conserve resources by sharing knowledge across different tasks. Despite the benefits of multi-task learning, such techniques can struggle with balancing the loss for each task, leading to potential performance degradation. We present a novel computation- and parameter-sharing framework that balances efficiency and accuracy to perform multiple visual tasks utilizing individually-trained single-task transformers. Our method is motivated by transfer learning schemes to reduce computational and parameter storage costs while maintaining the desired performance. Our approach involves splitting the tasks into a base task and the other sub-tasks, and sharing a significant portion of activations and parameters/weights between the base and sub-tasks to decrease inter-task redundancies and enhance knowledge sharing. The evaluation conducted on NYUD-v2 and PASCAL-context datasets shows that our method is superior to the state-of-the-art transformer-based multi-task learning techniques with higher accuracy and reduced computational resources. Moreover, our method is extended to video stream inputs, further reducing computational costs by efficiently sharing information across the temporal domain as well as the task domain. Our codes and models will be publicly available.
SpectralCLIP: Preventing Artifacts in Text-Guided Style Transfer from a Spectral Perspective
Mar 16, 2023
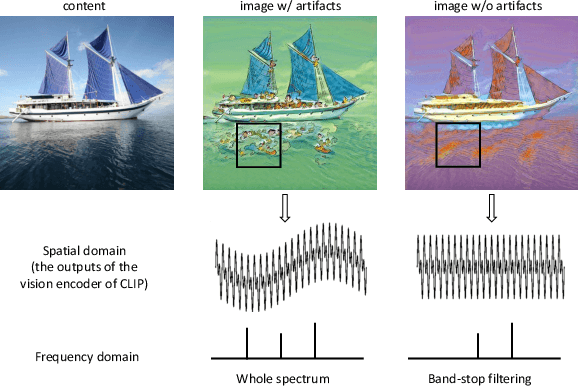
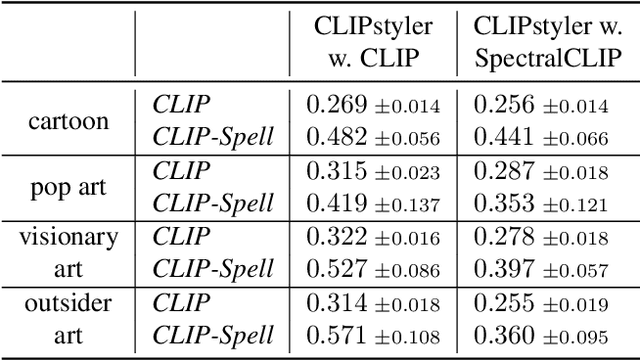

Contrastive Language-Image Pre-Training (CLIP) has refreshed the state of the art for a broad range of vision-language cross-modal tasks. Particularly, it has created an intriguing research line of text-guided image style transfer, dispensing with the need for style reference images as in traditional style transfer methods. However, directly using CLIP to guide the transfer of style leads to undesirable artifacts (mainly written words and unrelated visual entities) spread over the image, partly due to the entanglement of visual and written concepts inherent in CLIP. Inspired by the use of spectral analysis in filtering linguistic information at different granular levels, we analyse the patch embeddings from the last layer of the CLIP vision encoder from the perspective of spectral analysis and find that the presence of undesirable artifacts is highly correlated to some certain frequency components. We propose SpectralCLIP, which implements a spectral filtering layer on top of the CLIP vision encoder, to alleviate the artifact issue. Experimental results show that SpectralCLIP prevents the generation of artifacts effectively in quantitative and qualitative terms, without impairing the stylisation quality. We further apply SpectralCLIP to text-conditioned image generation and show that it prevents written words in the generated images. Code is available at https://github.com/zipengxuc/SpectralCLIP.
The Joint Weighted Average (JWA) Operator
Feb 23, 2023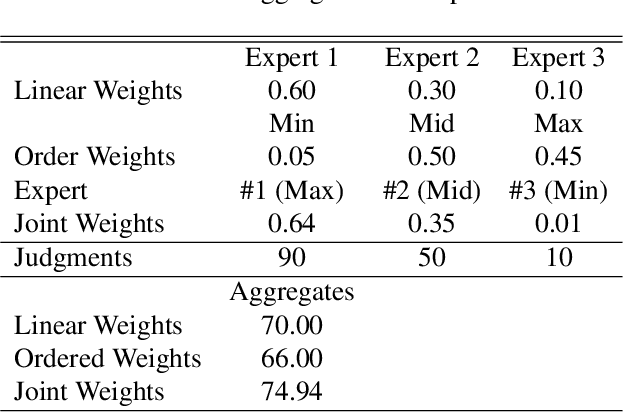
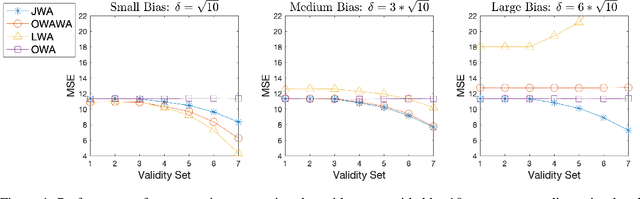
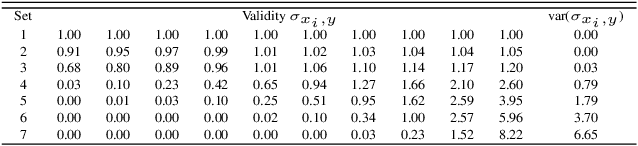
Information aggregation is a vital tool for human and machine decision making, especially in the presence of noise and uncertainty. Traditionally, approaches to aggregation broadly diverge into two categories, those which attribute a worth or weight to information sources and those which attribute said worth to the evidence arising from said sources. The latter is pervasive in particular in the physical sciences, underpinning linear order statistics and enabling non-linear aggregation. The former is popular in the social sciences, providing interpretable insight on the sources. Thus far, limited work has sought to integrate both approaches, applying either approach to a different degree. In this paper, we put forward an approach which integrates--rather than partially applies--both approaches, resulting in a novel joint weighted averaging operator. We show how this operator provides a systematic approach to integrating a priori beliefs about the worth of both source and evidence by leveraging compositional geometry--producing results unachievable by traditional operators. We conclude and highlight the potential of the operator across disciplines, from machine learning to psychology.
MCWDST: a Minimum-Cost Weighted Directed Spanning Tree Algorithm for Real-Time Fake News Mitigation in Social Media
Feb 23, 2023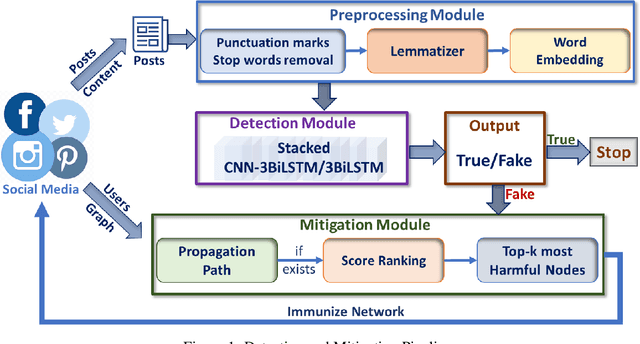

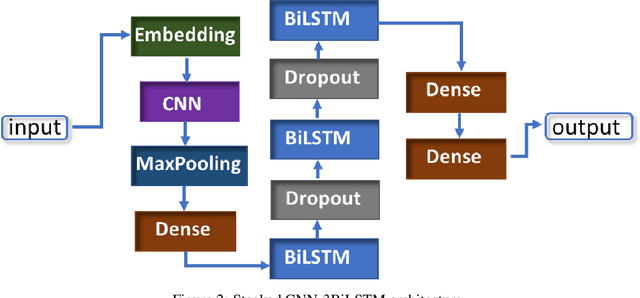
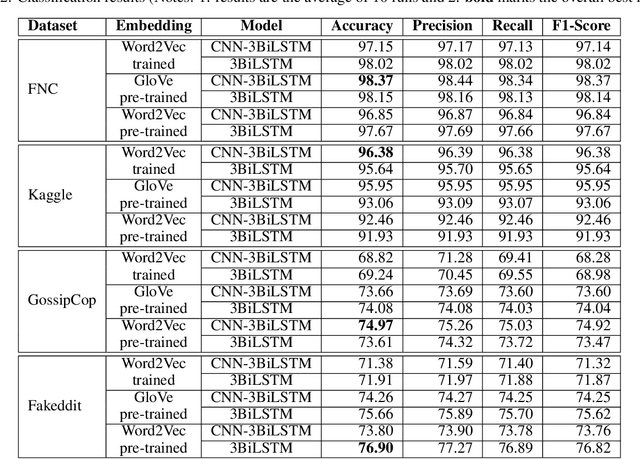
The widespread availability of internet access and handheld devices confers to social media a power similar to the one newspapers used to have. People seek affordable information on social media and can reach it within seconds. Yet this convenience comes with dangers; any user may freely post whatever they please and the content can stay online for a long period, regardless of its truthfulness. A need to detect untruthful information, also known as fake news, arises. In this paper, we present an end-to-end solution that accurately detects fake news and immunizes network nodes that spread them in real-time. To detect fake news, we propose two new stack deep learning architectures that utilize convolutional and bidirectional LSTM layers. To mitigate the spread of fake news, we propose a real-time network-aware strategy that (1) constructs a minimum-cost weighted directed spanning tree for a detected node, and (2) immunizes nodes in that tree by scoring their harmfulness using a novel ranking function. We demonstrate the effectiveness of our solution on five real-world datasets.
An Adam-enhanced Particle Swarm Optimizer for Latent Factor Analysis
Feb 23, 2023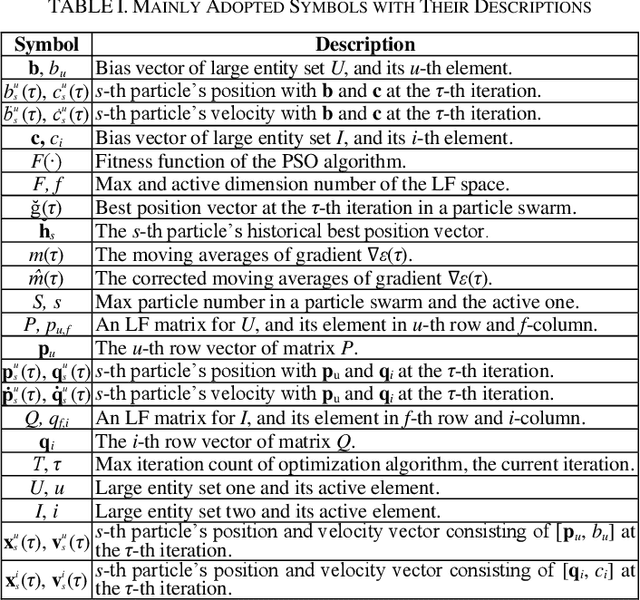
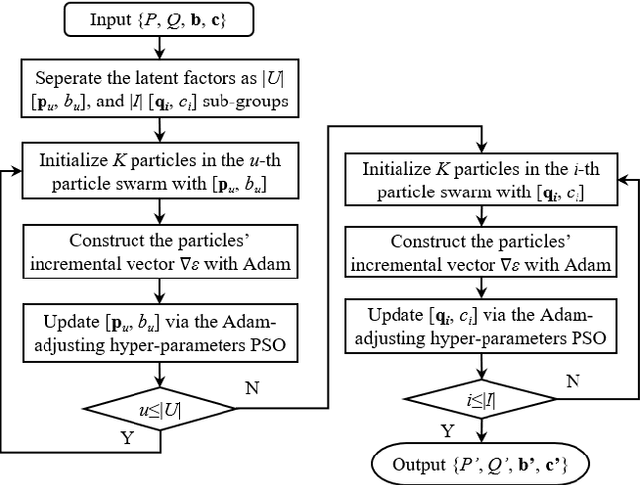
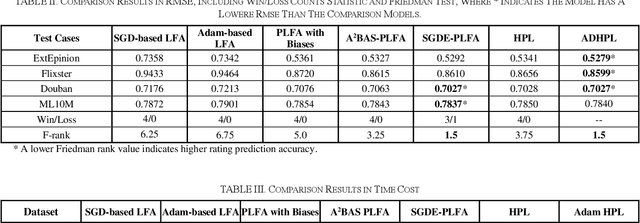
Digging out the latent information from large-scale incomplete matrices is a key issue with challenges. The Latent Factor Analysis (LFA) model has been investigated in depth to an alyze the latent information. Recently, Swarm Intelligence-related LFA models have been proposed and adopted widely to improve the optimization process of LFA with high efficiency, i.e., the Particle Swarm Optimization (PSO)-LFA model. However, the hyper-parameters of the PSO-LFA model have to tune manually, which is inconvenient for widely adoption and limits the learning rate as a fixed value. To address this issue, we propose an Adam-enhanced Hierarchical PSO-LFA model, which refines the latent factors with a sequential Adam-adjusting hyper-parameters PSO algorithm. First, we design the Adam incremental vector for a particle and construct the Adam-enhanced evolution process for particles. Second, we refine all the latent factors of the target matrix sequentially with our proposed Adam-enhanced PSO's process. The experimental results on four real datasets demonstrate that our proposed model achieves higher prediction accuracy with its peers.
PLU-Net: Extraction of multi-scale feature fusion
Feb 23, 2023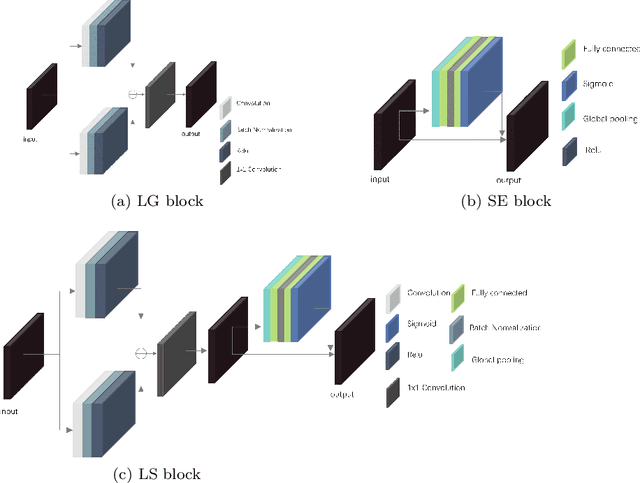

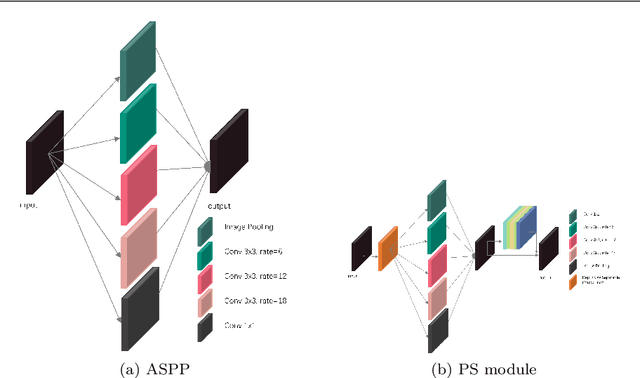
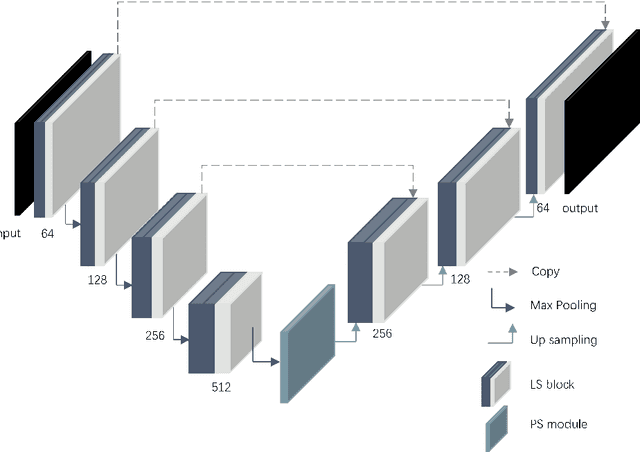
Deep learning algorithms have achieved remarkable results in medical image segmentation in recent years. These networks are unable to handle with image boundaries and details with enormous parameters, resulting in poor segmentation results. To address the issue, we develop atrous spatial pyramid pooling (ASPP) and combine it with the Squeeze-and-Excitation block (SE block), as well as present the PS module, which employs a broader and multi-scale receptive field at the network's bottom to obtain more detailed semantic information. We also propose the Local Guided block (LG block) and also its combination with the SE block to form the LS block, which can obtain more abundant local features in the feature map, so that more edge information can be retained in each down sampling process, thereby improving the performance of boundary segmentation. We propose PLU-Net and integrate our PS module and LS block into U-Net. We put our PLU-Net to the test on three benchmark datasets, and the results show that by fewer parameters and FLOPs, it outperforms on medical semantic segmentation tasks.
LAPTNet-FPN: Multi-scale LiDAR-aided Projective Transform Network for Real Time Semantic Grid Prediction
Feb 10, 2023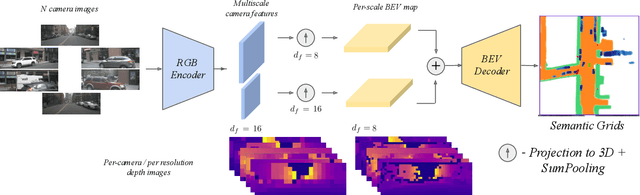

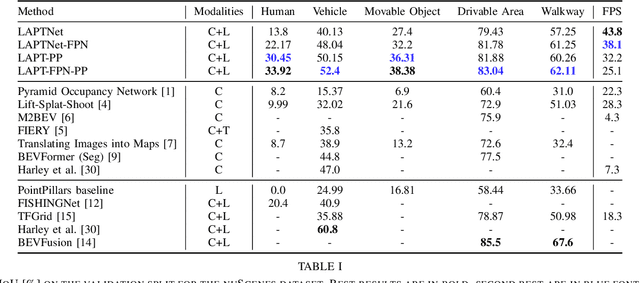
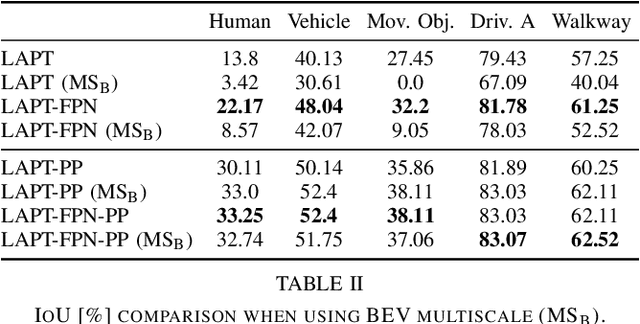
Semantic grids can be useful representations of the scene around an autonomous system. By having information about the layout of the space around itself, a robot can leverage this type of representation for crucial tasks such as navigation or tracking. By fusing information from multiple sensors, robustness can be increased and the computational load for the task can be lowered, achieving real time performance. Our multi-scale LiDAR-Aided Perspective Transform network uses information available in point clouds to guide the projection of image features to a top-view representation, resulting in a relative improvement in the state of the art for semantic grid generation for human (+8.67%) and movable object (+49.07%) classes in the nuScenes dataset, as well as achieving results close to the state of the art for the vehicle, drivable area and walkway classes, while performing inference at 25 FPS.