 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reconfigurable Intelligent Surface Aided Hybrid Beamforming: Optimal Placement and Beamforming Design
Mar 21, 2023
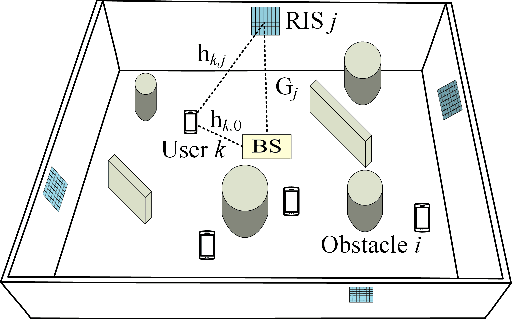
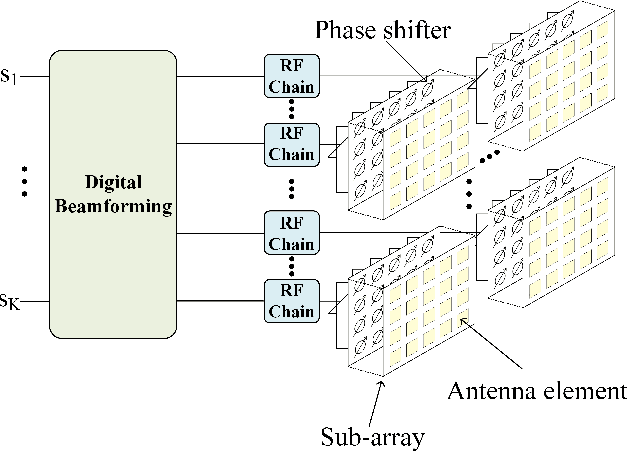
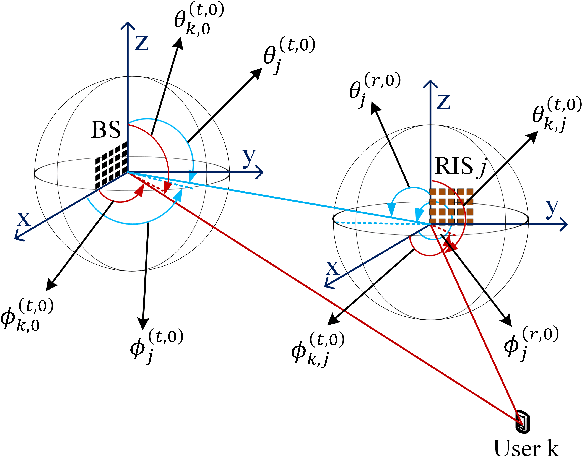
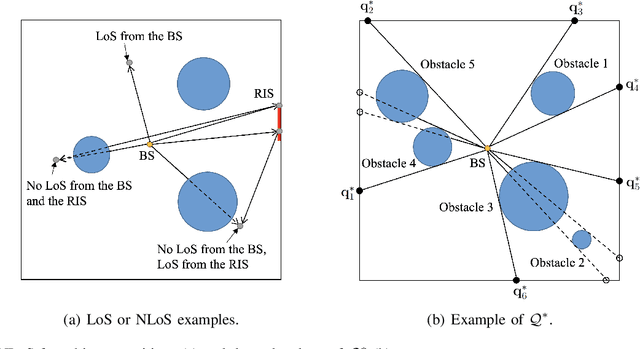
We consider reconfigurable intelligent surface (RIS) aided sixth-generation (6G) terahertz (THz) communications for indoor environment in which a base station (BS) wishes to send independent messages to its serving users with the help of multiple RISs. For indoor environment, various obstacles such as pillars, walls, and other objects can result in no line-of-sight signal path between the BS and a user, which can significantly degrade performance. To overcome such limitation of indoor THz communication, we firstly optimize the placement of RISs to maximize the coverage area. Under the optimized RIS placement, we propose 3D hybrid beamforming at the BS and phase adjustment at RISs, which are jointly performed at the BS and RISs via codebook-based 3D beam scanning with low complexity. Numerical simulations demonstrate that the proposed scheme significantly improves the average sum rate compared to the cases of no RIS and randomly deployed RISs. It is further shown that the proposed codebook-based 3D beam scanning efficiently aligns analog beams between BS--user links or BS--RIS--user links and, as a consequence, achieves the average sum rate close to that of coherent beam alignment requiring global channel state information.
Focused and Collaborative Feedback Integration for Interactive Image Segmentation
Mar 21, 2023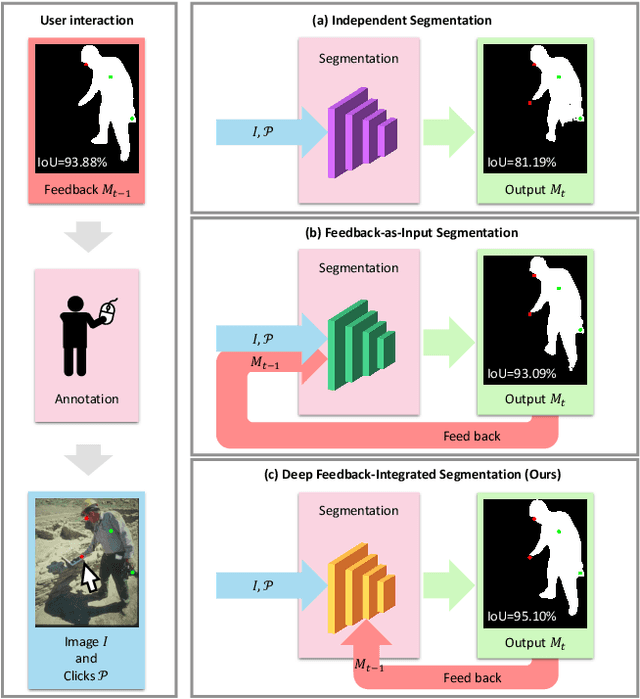
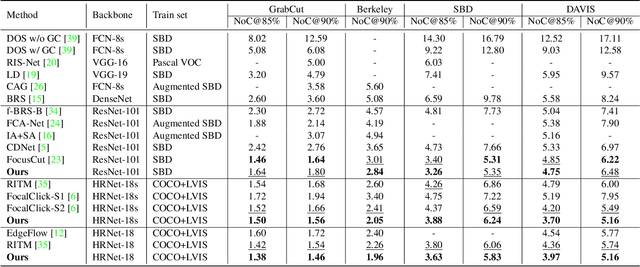
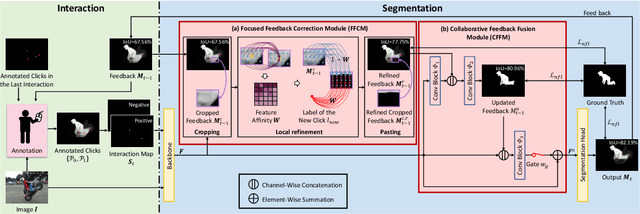
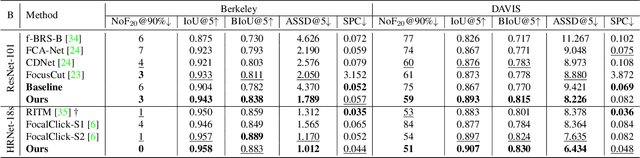
Interactive image segmentation aims at obtaining a segmentation mask for an image using simple user annotations. During each round of interaction, the segmentation result from the previous round serves as feedback to guide the user's annotation and provides dense prior information for the segmentation model, effectively acting as a bridge between interactions. Existing methods overlook the importance of feedback or simply concatenate it with the original input, leading to underutilization of feedback and an increase in the number of required annotations. To address this, we propose an approach called Focused and Collaborative Feedback Integration (FCFI) to fully exploit the feedback for click-based interactive image segmentation. FCFI first focuses on a local area around the new click and corrects the feedback based on the similarities of high-level features. It then alternately and collaboratively updates the feedback and deep features to integrate the feedback into the features. The efficacy and efficiency of FCFI were validated on four benchmarks, namely GrabCut, Berkeley, SBD, and DAVIS. Experimental results show that FCFI achieved new state-of-the-art performance with less computational overhead than previous methods. The source code is available at https://github.com/veizgyauzgyauz/FCFI.
Marker-based Visual SLAM leveraging Hierarchical Representations
Mar 02, 2023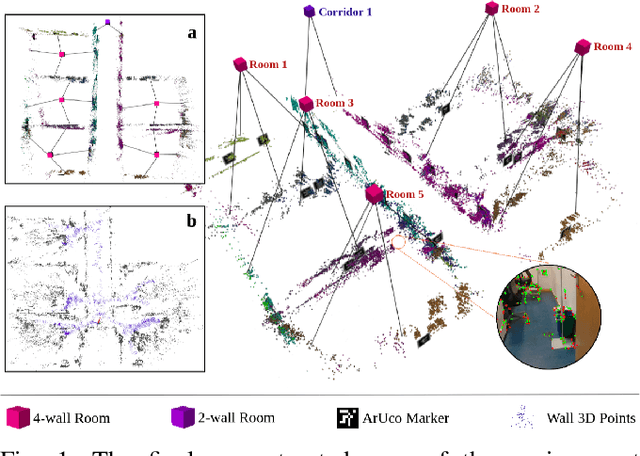
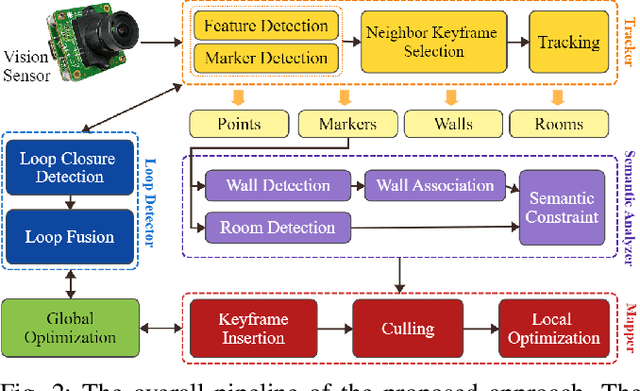
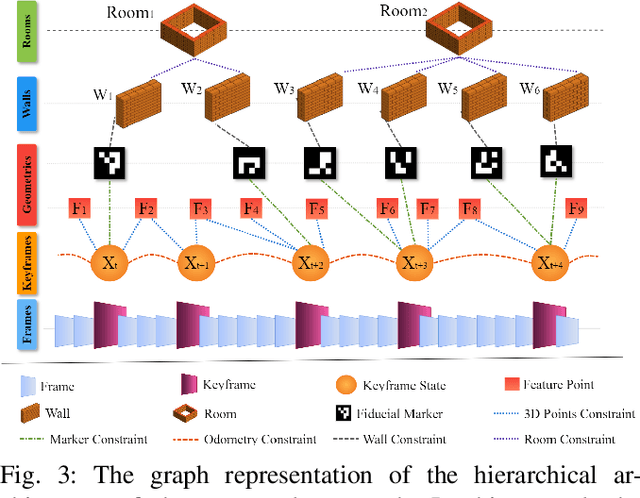

Fiducial markers can encode rich information about the environment and can aid Visual SLAM (VSLAM) approaches in reconstructing maps with practical semantic information. Current marker-based VSLAM approaches mainly utilize markers for improving feature detections in low-feature environments and/or for incorporating loop closure constraints, generating only low-level geometric maps of the environment prone to inaccuracies in complex environments. To bridge this gap, this paper presents a VSLAM approach utilizing a monocular camera along with fiducial markers to generate hierarchical representations of the environment while improving the camera pose estimate. The proposed approach detects semantic entities from the surroundings, including walls, corridors, and rooms encoded within markers, and appropriately adds topological constraints among them. Experimental results on a real-world dataset collected with a robot demonstrate that the proposed approach outperforms a traditional marker-based VSLAM baseline in terms of accuracy, given the addition of new constraints while creating enhanced map representations. Furthermore, it shows satisfactory results when comparing the reconstructed map quality to the one reconstructed using a LiDAR SLAM approach.
Masked Multi-Step Probabilistic Forecasting for Short-to-Mid-Term Electricity Demand
Feb 14, 2023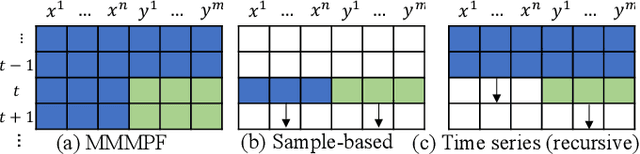
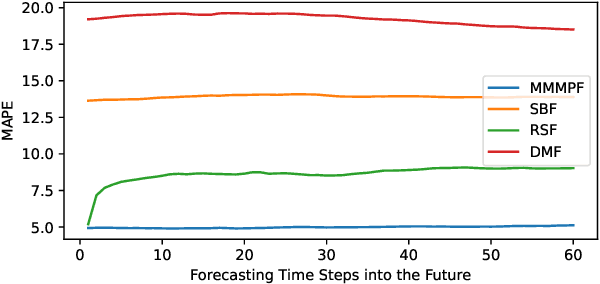
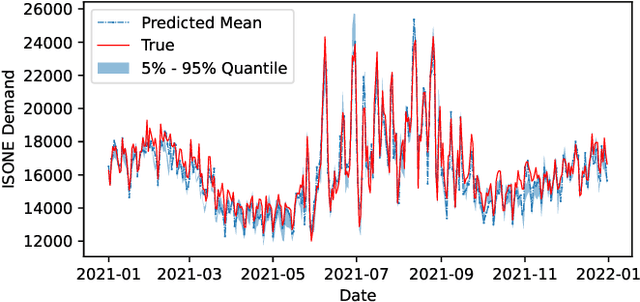
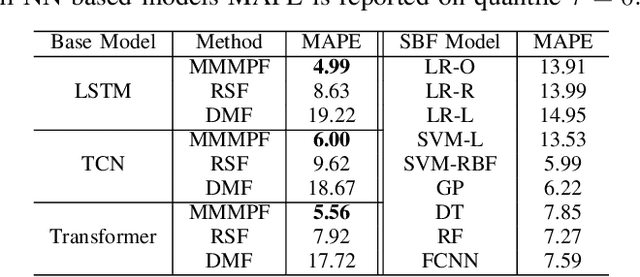
Predicting the demand for electricity with uncertainty helps in planning and operation of the grid to provide reliable supply of power to the consumers. Machine learning (ML)-based demand forecasting approaches can be categorized into (1) sample-based approaches, where each forecast is made independently, and (2) time series regression approaches, where some historical load and other feature information is used. When making a short-to-mid-term electricity demand forecast, some future information is available, such as the weather forecast and calendar variables. However, in existing forecasting models this future information is not fully incorporated. To overcome this limitation of existing approaches, we propose Masked Multi-Step Multivariate Probabilistic Forecasting (MMMPF), a novel and general framework to train any neural network model capable of generating a sequence of outputs, that combines both the temporal information from the past and the known information about the future to make probabilistic predictions. Experiments are performed on a real-world dataset for short-to-mid-term electricity demand forecasting for multiple regions and compared with various ML methods. They show that the proposed MMMPF framework outperforms not only sample-based methods but also existing time-series forecasting models with the exact same base models. Models trainded with MMMPF can also generate desired quantiles to capture uncertainty and enable probabilistic planning for grid of the future.
Domain-Knowledge-Aided Airborne Ground Moving Targets Tracking
Mar 12, 2023
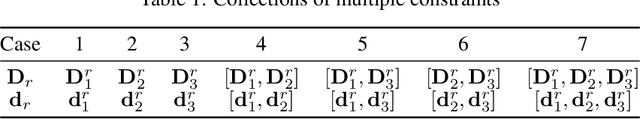
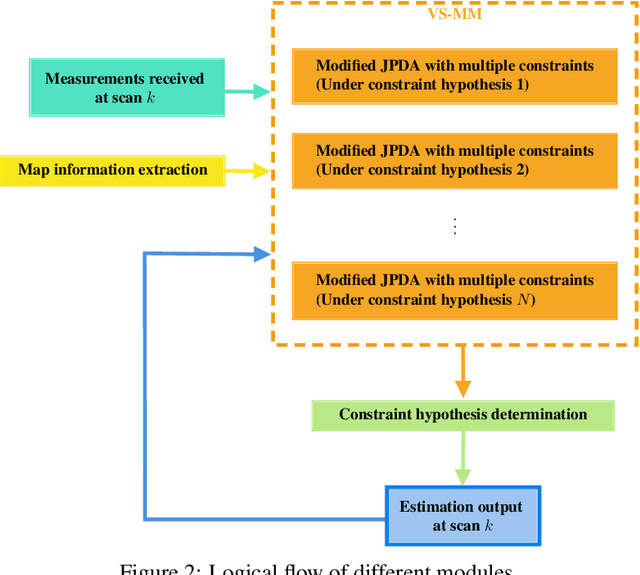
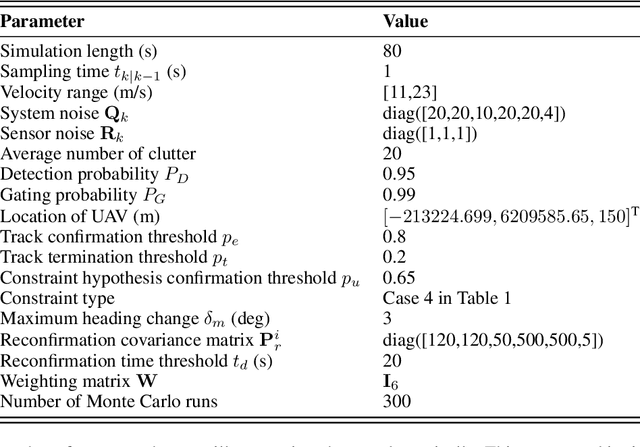
This paper investigates the problem of traffic surveillance using an unmanned aerial vehicle (UAV) and proposes a domain-knowledge-aided airborne ground moving targets tracking algorithm. To improve the accuracy of multiple targets tracking, the proposed algorithm incorporates domain knowledge into the joint probabilistic data association (JPDA) filter as state constraints. The domain knowledge considered in this paper includes both road information extracted from a given map and local traffic regulations. Conventional track update method is modified to enhance the capability of recognition of temporarily track loss. A variable structure multiple model (VS-MM) method is developed to assign the road segment to a given target. The effectiveness of proposed algorithm is demonstrated through extensive numerical simulations.
Does Synthetic Data Generation of LLMs Help Clinical Text Mining?
Mar 08, 2023
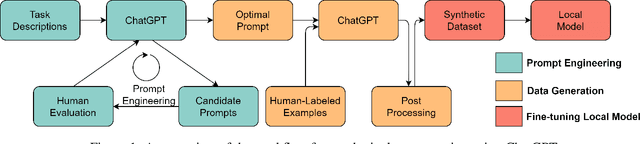
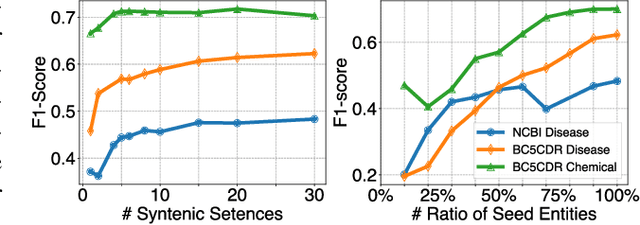

Recent advancements in large language models (LLMs) have led to the development of highly potent models like OpenAI's ChatGPT. These models have exhibited exceptional performance in a variety of tasks, such as question answering, essay composition, and code generation. However, their effectiveness in the healthcare sector remains uncertain. In this study, we seek to investigate the potential of ChatGPT to aid in clinical text mining by examining its ability to extract structured information from unstructured healthcare texts, with a focus on biological named entity recognition and relation extraction. However, our preliminary results indicate that employing ChatGPT directly for these tasks resulted in poor performance and raised privacy concerns associated with uploading patients' information to the ChatGPT API. To overcome these limitations, we propose a new training paradigm that involves generating a vast quantity of high-quality synthetic data with labels utilizing ChatGPT and fine-tuning a local model for the downstream task. Our method has resulted in significant improvements in the performance of downstream tasks, improving the F1-score from 23.37% to 63.99% for the named entity recognition task and from 75.86% to 83.59% for the relation extraction task. Furthermore, generating data using ChatGPT can significantly reduce the time and effort required for data collection and labeling, as well as mitigate data privacy concerns. In summary, the proposed framework presents a promising solution to enhance the applicability of LLM models to clinical text mining.
Focus On Details: Online Multi-object Tracking with Diverse Fine-grained Representation
Mar 08, 2023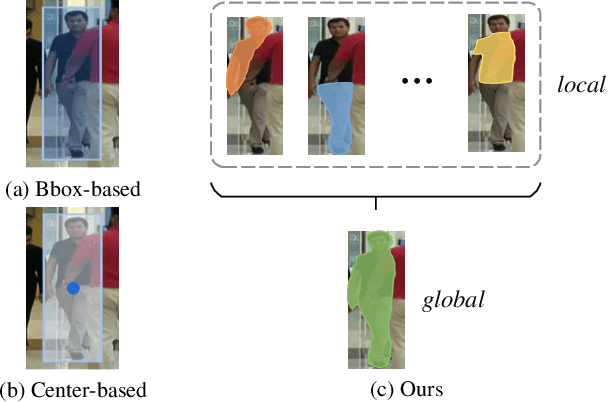
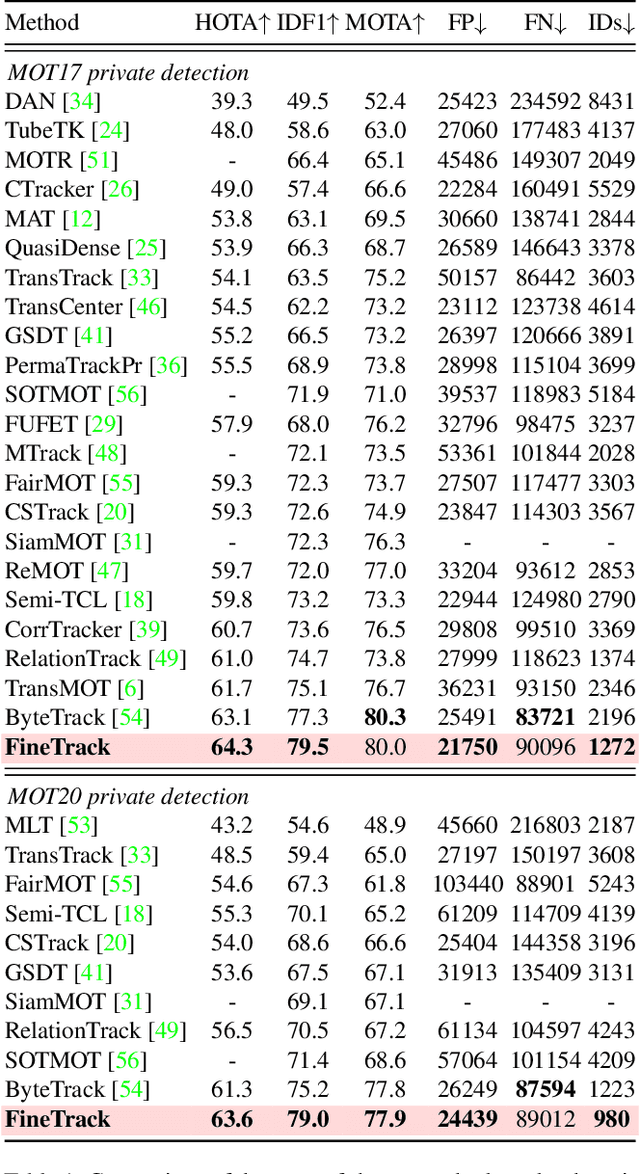
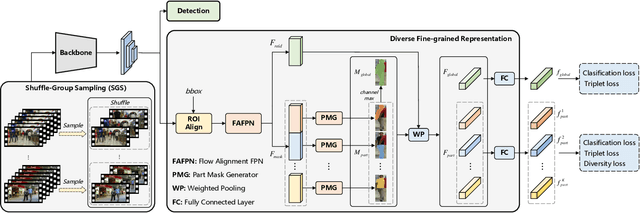
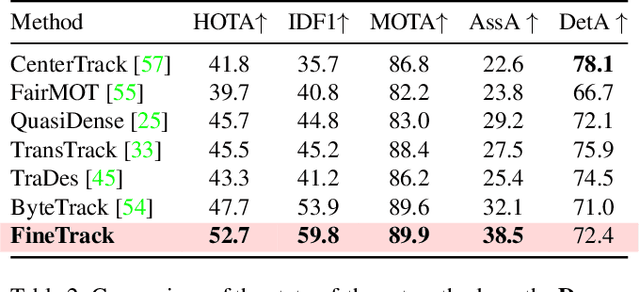
Discriminative representation is essential to keep a unique identifier for each target in Multiple object tracking (MOT). Some recent MOT methods extract features of the bounding box region or the center point as identity embeddings. However, when targets are occluded, these coarse-grained global representations become unreliable. To this end, we propose exploring diverse fine-grained representation, which describes appearance comprehensively from global and local perspectives. This fine-grained representation requires high feature resolution and precise semantic information. To effectively alleviate the semantic misalignment caused by indiscriminate contextual information aggregation, Flow Alignment FPN (FAFPN) is proposed for multi-scale feature alignment aggregation. It generates semantic flow among feature maps from different resolutions to transform their pixel positions. Furthermore, we present a Multi-head Part Mask Generator (MPMG) to extract fine-grained representation based on the aligned feature maps. Multiple parallel branches of MPMG allow it to focus on different parts of targets to generate local masks without label supervision. The diverse details in target masks facilitate fine-grained representation. Eventually, benefiting from a Shuffle-Group Sampling (SGS) training strategy with positive and negative samples balanced, we achieve state-of-the-art performance on MOT17 and MOT20 test sets. Even on DanceTrack, where the appearance of targets is extremely similar, our method significantly outperforms ByteTrack by 5.0% on HOTA and 5.6% on IDF1. Extensive experiments have proved that diverse fine-grained representation makes Re-ID great again in MOT.
CrossSpeech: Speaker-independent Acoustic Representation for Cross-lingual Speech Synthesis
Feb 28, 2023
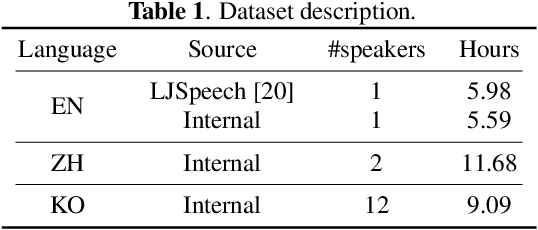
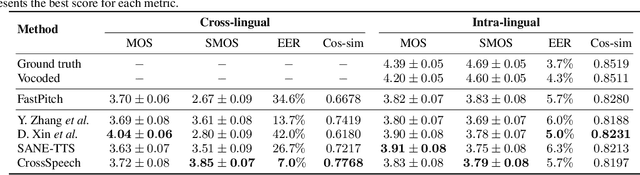
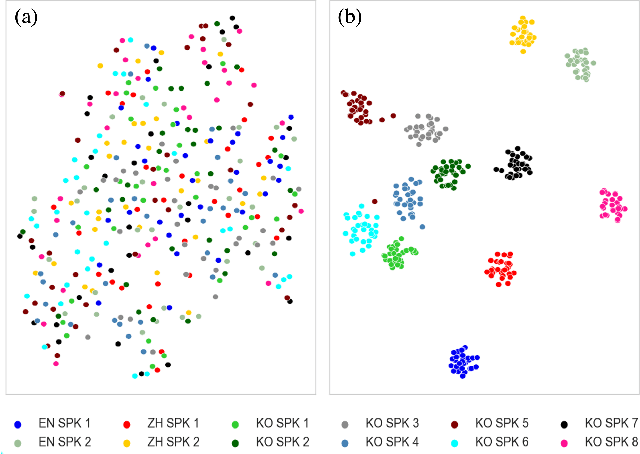
While recent text-to-speech (TTS) systems have made remarkable strides toward human-level quality, the performance of cross-lingual TTS lags behind that of intra-lingual TTS. This gap is mainly rooted from the speaker-language entanglement problem in cross-lingual TTS. In this paper, we propose CrossSpeech which improves the quality of cross-lingual speech by effectively disentangling speaker and language information in the level of acoustic feature space. Specifically, CrossSpeech decomposes the speech generation pipeline into the speaker-independent generator (SIG) and speaker-dependent generator (SDG). The SIG produces the speaker-independent acoustic representation which is not biased to specific speaker distributions. On the other hand, the SDG models speaker-dependent speech variation that characterizes speaker attributes. By handling each information separately, CrossSpeech can obtain disentangled speaker and language representations. From the experiments, we verify that CrossSpeech achieves significant improvements in cross-lingual TTS, especially in terms of speaker similarity to the target speaker.
Mapper Side Geometric Shaping for QAM Constellations in 5G MIMO Wireless Channel with Realistic LDPC Codes
Mar 05, 2023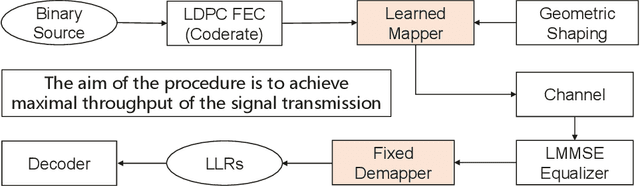
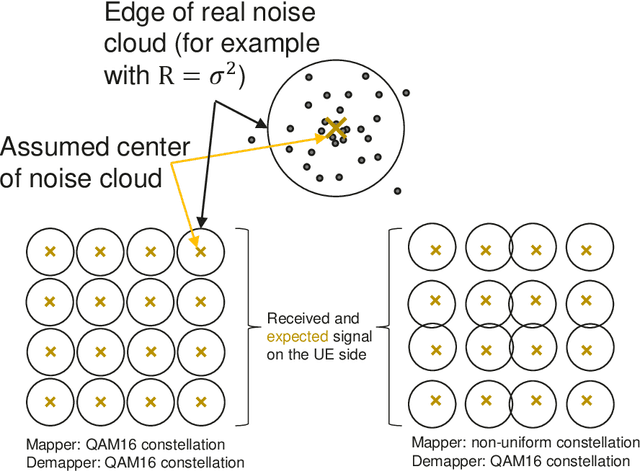
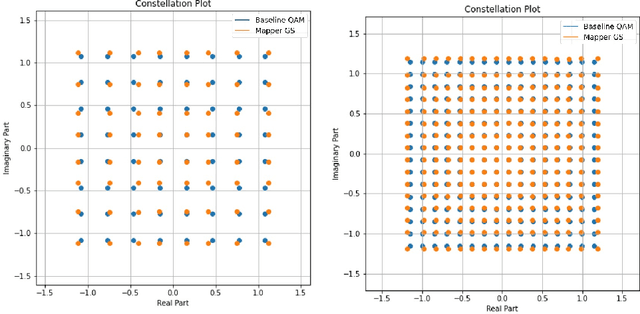
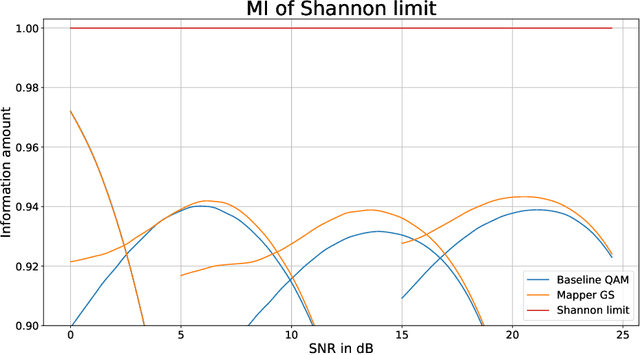
In wireless communication systems, there are many stages for signal transmission. Among them, mapping and demapping convert a sequence of bits into a sequence of complex numbers and vice versa. This operation is performed by a system of constellations~ -- by a set of labeled points on the complex plane. Usually, the geometry of the constellation is fixed, and constellation points are uniformly spaced, e.g., the same quadrature amplitude modulation (QAM) is used in a wide range of signal-to-noise ratio (SNR). By eliminating the uniformity of constellations, it is possible to achieve greater values of capacity. Due to the current standard restrictions, it is difficult to change the constellation both on the mapper or demapper side. In this case, one can optimize the constellation only on the mapper or the demapper side using original methodology. By the numerical calculating of capacity, we show that the optimal geometric constellation depends on SNR. Optimization is carried out by maximizing mutual information (MI). The MI function describes the amount of information being transmitted through the channel with the optimal encoding. To prove the effectiveness of this approach we provide numerical experiments in the modern physical level Sionna simulator using the realistic LDPC codes and the MIMO 5G OFDM channels.
Saliency-Driven Hierarchical Learned Image Coding for Machines
Feb 27, 2023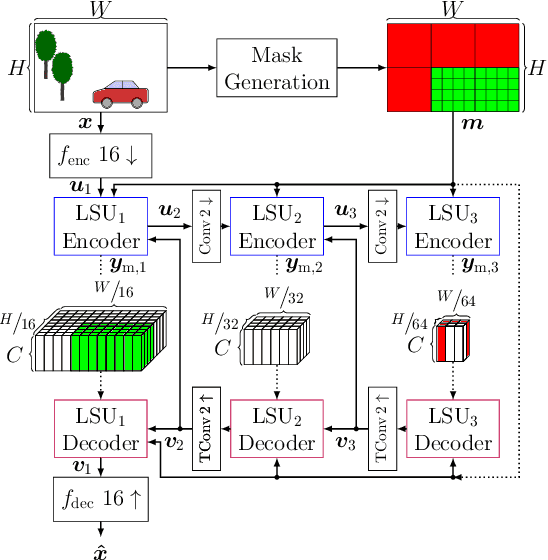
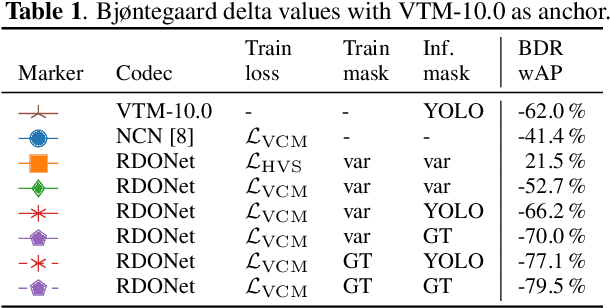
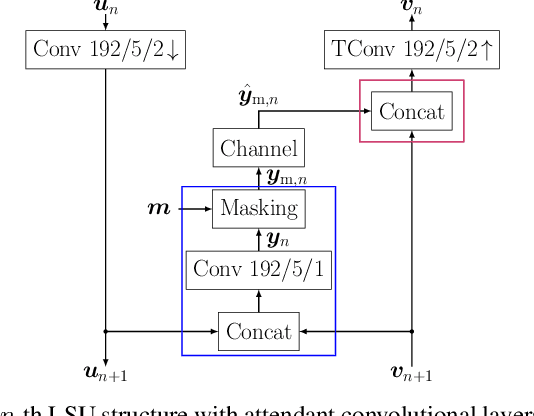

We propose to employ a saliency-driven hierarchical neural image compression network for a machine-to-machine communication scenario following the compress-then-analyze paradigm. By that, different areas of the image are coded at different qualities depending on whether salient objects are located in the corresponding area. Areas without saliency are transmitted in latent spaces of lower spatial resolution in order to reduce the bitrate. The saliency information is explicitly derived from the detections of an object detection network. Furthermore, we propose to add saliency information to the training process in order to further specialize the different latent spaces. All in all, our hierarchical model with all proposed optimizations achieves 77.1 % bitrate savings over the latest video coding standard VVC on the Cityscapes dataset and with Mask R-CNN as analysis network at the decoder side. Thereby, it also outperforms traditional, non-hierarchical compression networks.