 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Protective Self-Adaptive Pruning to Better Compress DNNs
Mar 21, 2023
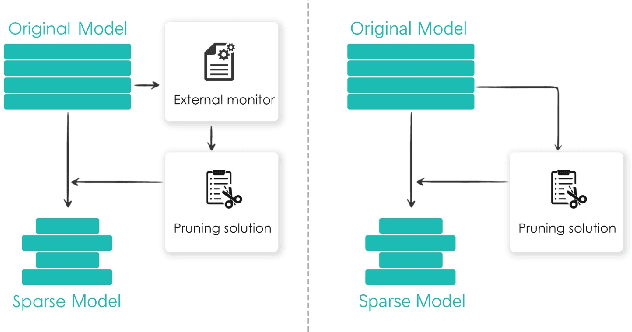
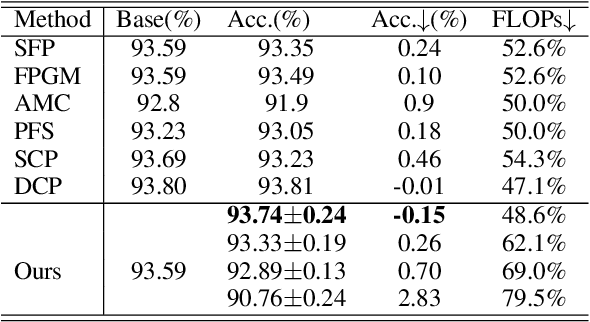
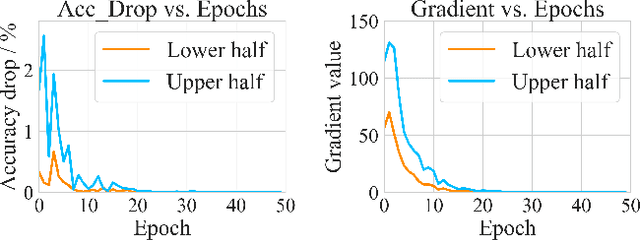
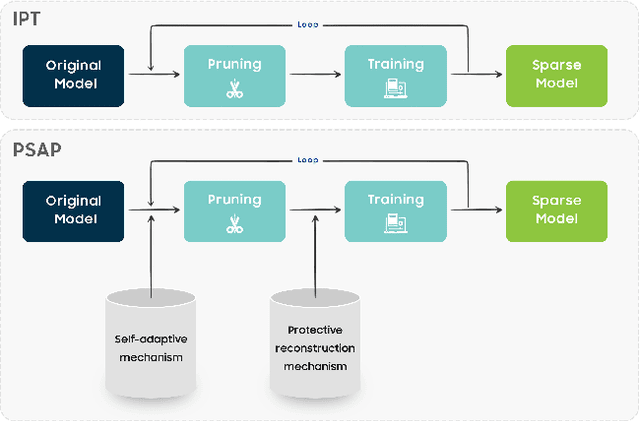
Adaptive network pruning approach has recently drawn significant attention due to its excellent capability to identify the importance and redundancy of layers and filters and customize a suitable pruning solution. However, it remains unsatisfactory since current adaptive pruning methods rely mostly on an additional monitor to score layer and filter importance, and thus faces high complexity and weak interpretability. To tackle these issues, we have deeply researched the weight reconstruction process in iterative prune-train process and propose a Protective Self-Adaptive Pruning (PSAP) method. First of all, PSAP can utilize its own information, weight sparsity ratio, to adaptively adjust pruning ratio of layers before each pruning step. Moreover, we propose a protective reconstruction mechanism to prevent important filters from being pruned through supervising gradients and to avoid unrecoverable information loss as well. Our PSAP is handy and explicit because it merely depends on weights and gradients of model itself, instead of requiring an additional monitor as in early works. Experiments on ImageNet and CIFAR-10 also demonstrate its superiority to current works in both accuracy and compression ratio, especially for compressing with a high ratio or pruning from scratch.
Guided Slot Attention for Unsupervised Video Object Segmentation
Mar 15, 2023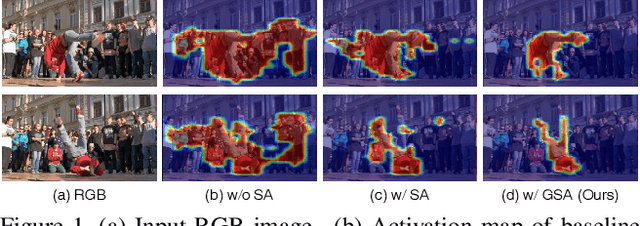
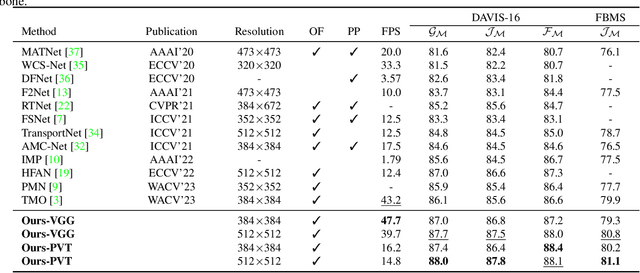
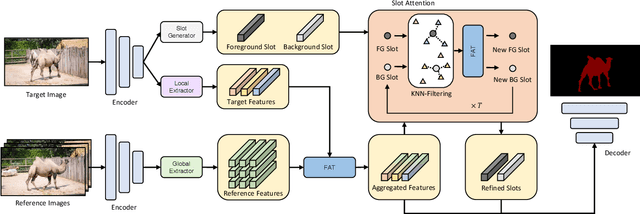
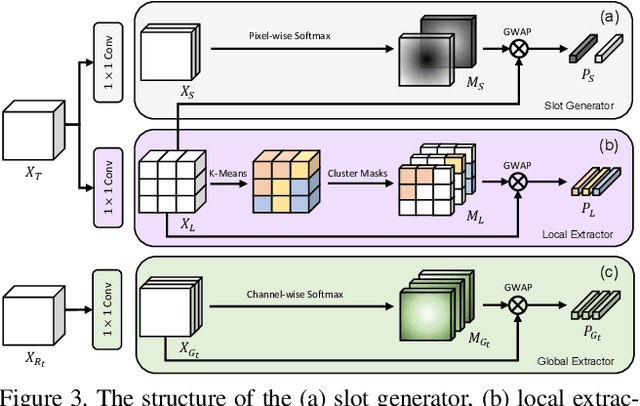
Unsupervised video object segmentation aims to segment the most prominent object in a video sequence. However, the existence of complex backgrounds and multiple foreground objects make this task challenging. To address this issue, we propose a guided slot attention network to reinforce spatial structural information and obtain better foreground--background separation. The foreground and background slots, which are initialized with query guidance, are iteratively refined based on interactions with template information. Furthermore, to improve slot--template interaction and effectively fuse global and local features in the target and reference frames, K-nearest neighbors filtering and a feature aggregation transformer are introduced. The proposed model achieves state-of-the-art performance on two popular datasets. Additionally, we demonstrate the robustness of the proposed model in challenging scenes through various comparative experiments.
Probabilistic Prompt Learning for Dense Prediction
Apr 03, 2023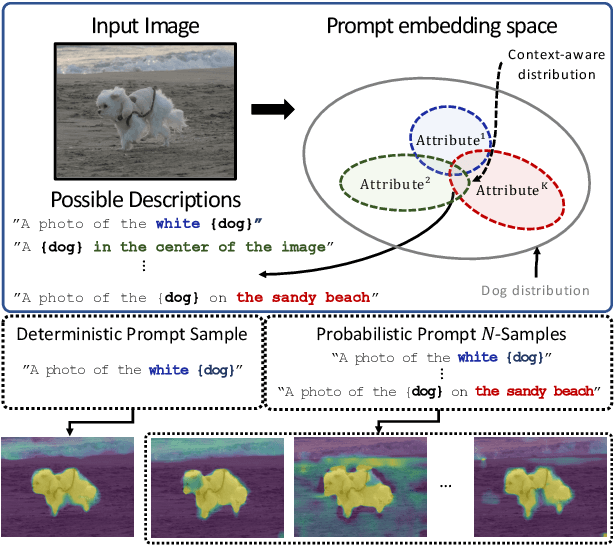
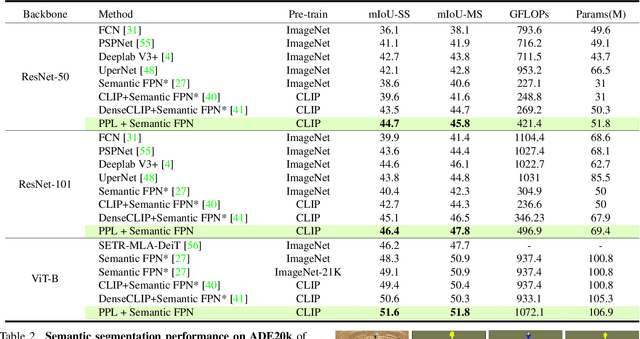
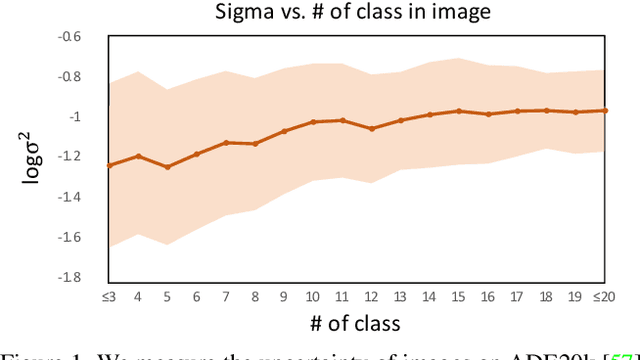

Recent progress in deterministic prompt learning has become a promising alternative to various downstream vision tasks, enabling models to learn powerful visual representations with the help of pre-trained vision-language models. However, this approach results in limited performance for dense prediction tasks that require handling more complex and diverse objects, since a single and deterministic description cannot sufficiently represent the entire image. In this paper, we present a novel probabilistic prompt learning to fully exploit the vision-language knowledge in dense prediction tasks. First, we introduce learnable class-agnostic attribute prompts to describe universal attributes across the object class. The attributes are combined with class information and visual-context knowledge to define the class-specific textual distribution. Text representations are sampled and used to guide the dense prediction task using the probabilistic pixel-text matching loss, enhancing the stability and generalization capability of the proposed method. Extensive experiments on different dense prediction tasks and ablation studies demonstrate the effectiveness of our proposed method.
Generative Multiplane Neural Radiance for 3D-Aware Image Generation
Apr 03, 2023
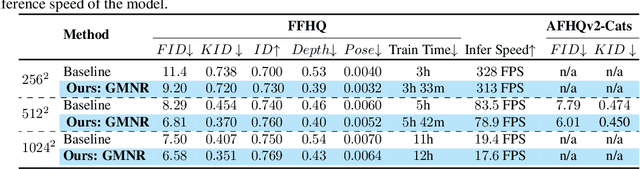


We present a method to efficiently generate 3D-aware high-resolution images that are view-consistent across multiple target views. The proposed multiplane neural radiance model, named GMNR, consists of a novel {\alpha}-guided view-dependent representation ({\alpha}-VdR) module for learning view-dependent information. The {\alpha}-VdR module, faciliated by an {\alpha}-guided pixel sampling technique, computes the view-dependent representation efficiently by learning viewing direction and position coefficients. Moreover, we propose a view-consistency loss to enforce photometric similarity across multiple views. The GMNR model can generate 3D-aware high-resolution images that are viewconsistent across multiple camera poses, while maintaining the computational efficiency in terms of both training and inference time. Experiments on three datasets demonstrate the effectiveness of the proposed modules, leading to favorable results in terms of both generation quality and inference time, compared to existing approaches. Our GMNR model generates 3D-aware images of 1024 X 1024 pixels with 17.6 FPS on a single V100. Code : https://github.com/VIROBO-15/GMNR
Is Stochastic Mirror Descent Vulnerable to Adversarial Delay Attacks? A Traffic Assignment Resilience Study
Apr 03, 2023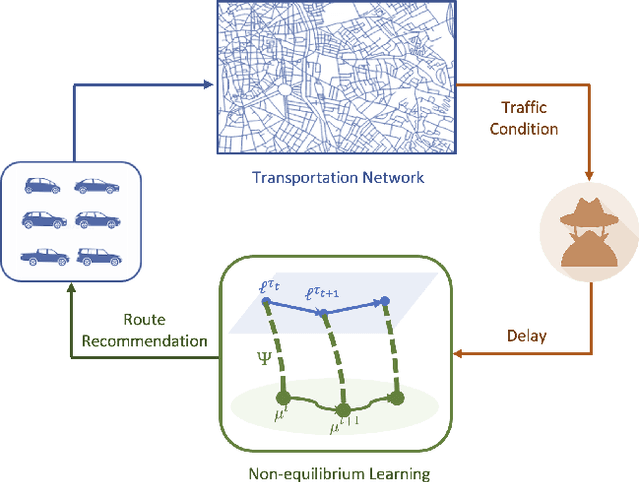
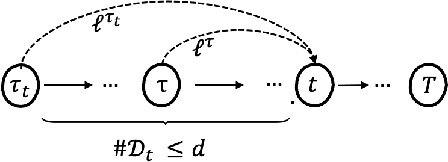
\textit{Intelligent Navigation Systems} (INS) are exposed to an increasing number of informational attack vectors, which often intercept through the communication channels between the INS and the transportation network during the data collecting process. To measure the resilience of INS, we use the concept of a Wardrop Non-Equilibrium Solution (WANES), which is characterized by the probabilistic outcome of learning within a bounded number of interactions. By using concentration arguments, we have discovered that any bounded feedback delaying attack only degrades the systematic performance up to order $\tilde{\mathcal{O}}(\sqrt{{d^3}{T^{-1}}})$ along the traffic flow trajectory within the Delayed Mirror Descent (DMD) online-learning framework. This degradation in performance can occur with only mild assumptions imposed. Our result implies that learning-based INS infrastructures can achieve Wardrop Non-equilibrium even when experiencing a certain period of disruption in the information structure. These findings provide valuable insights for designing defense mechanisms against possible jamming attacks across different layers of the transportation ecosystem.
Imitation Learning from Nonlinear MPC via the Exact Q-Loss and its Gauss-Newton Approximation
Apr 03, 2023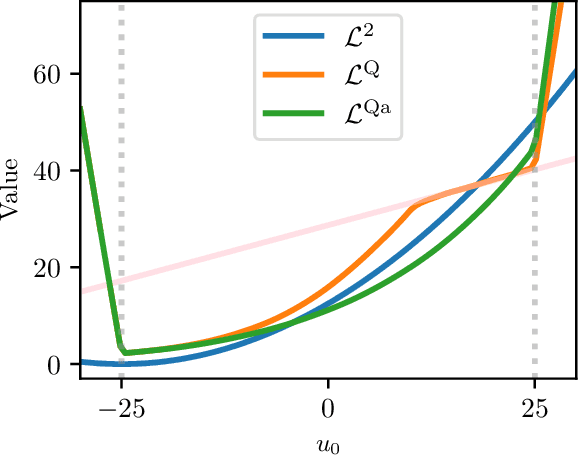
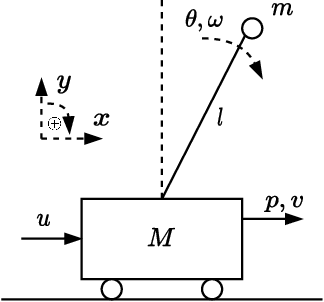
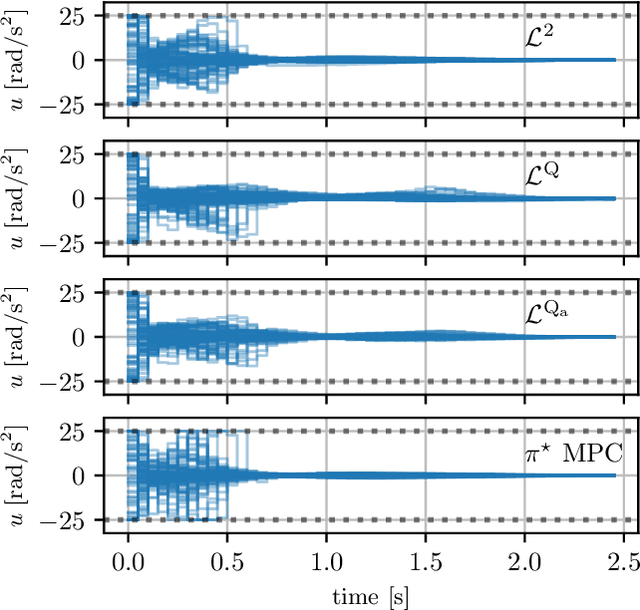
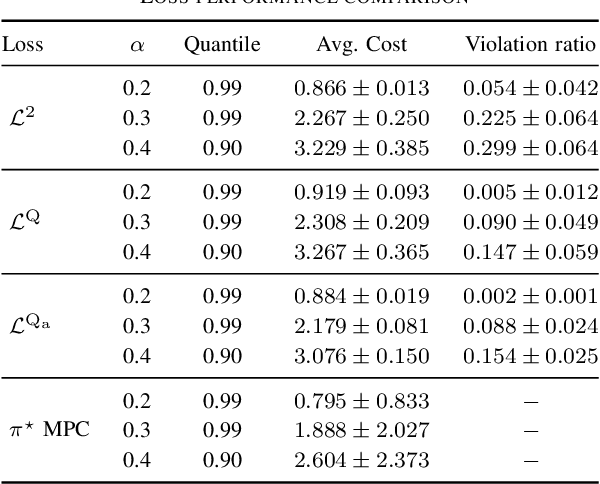
This work presents a novel loss function for learning nonlinear Model Predictive Control policies via Imitation Learning. Standard approaches to Imitation Learning neglect information about the expert and generally adopt a loss function based on the distance between expert and learned controls. In this work, we present a loss based on the Q-function directly embedding the performance objectives and constraint satisfaction of the associated Optimal Control Problem (OCP). However, training a Neural Network with the Q-loss requires solving the associated OCP for each new sample. To alleviate the computational burden, we derive a second Q-loss based on the Gauss-Newton approximation of the OCP resulting in a faster training time. We validate our losses against Behavioral Cloning, the standard approach to Imitation Learning, on the control of a nonlinear system with constraints. The final results show that the Q-function-based losses significantly reduce the amount of constraint violations while achieving comparable or better closed-loop costs.
RePAST: Relative Pose Attention Scene Representation Transformer
Apr 03, 2023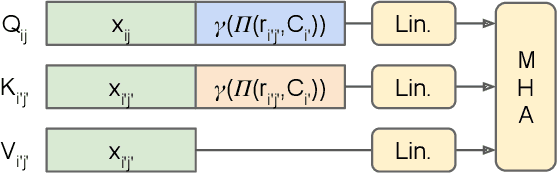
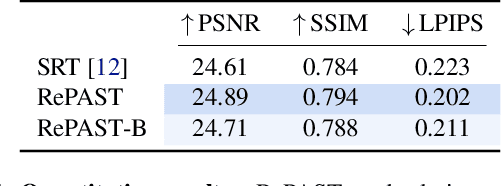
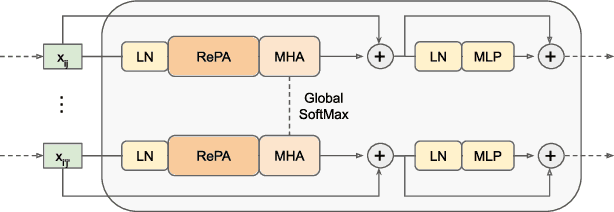
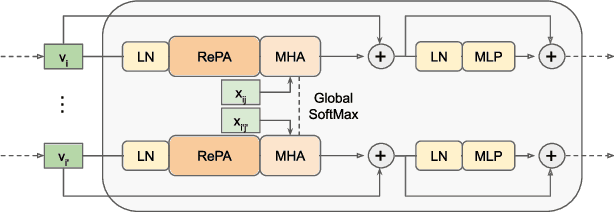
The Scene Representation Transformer (SRT) is a recent method to render novel views at interactive rates. Since SRT uses camera poses with respect to an arbitrarily chosen reference camera, it is not invariant to the order of the input views. As a result, SRT is not directly applicable to large-scale scenes where the reference frame would need to be changed regularly. In this work, we propose Relative Pose Attention SRT (RePAST): Instead of fixing a reference frame at the input, we inject pairwise relative camera pose information directly into the attention mechanism of the Transformers. This leads to a model that is by definition invariant to the choice of any global reference frame, while still retaining the full capabilities of the original method. Empirical results show that adding this invariance to the model does not lead to a loss in quality. We believe that this is a step towards applying fully latent transformer-based rendering methods to large-scale scenes.
Role of Transients in Two-Bounce Non-Line-of-Sight Imaging
Apr 03, 2023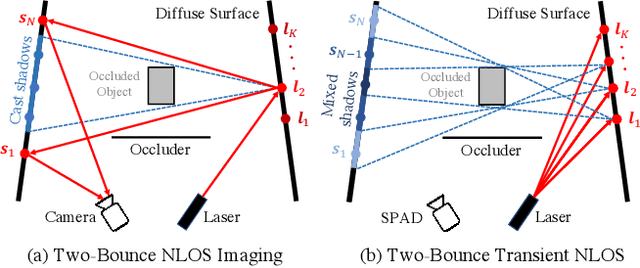
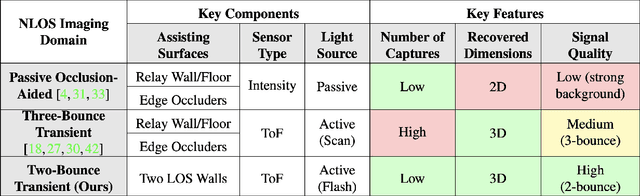
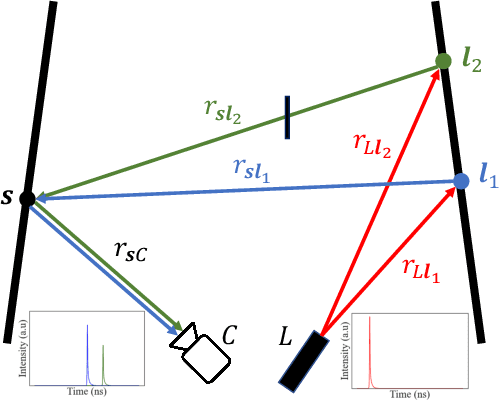
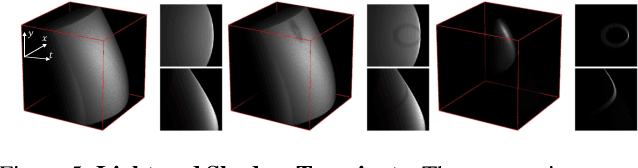
The goal of non-line-of-sight (NLOS) imaging is to image objects occluded from the camera's field of view using multiply scattered light. Recent works have demonstrated the feasibility of two-bounce (2B) NLOS imaging by scanning a laser and measuring cast shadows of occluded objects in scenes with two relay surfaces. In this work, we study the role of time-of-flight (ToF) measurements, \ie transients, in 2B-NLOS under multiplexed illumination. Specifically, we study how ToF information can reduce the number of measurements and spatial resolution needed for shape reconstruction. We present our findings with respect to tradeoffs in (1) temporal resolution, (2) spatial resolution, and (3) number of image captures by studying SNR and recoverability as functions of system parameters. This leads to a formal definition of the mathematical constraints for 2B lidar. We believe that our work lays an analytical groundwork for design of future NLOS imaging systems, especially as ToF sensors become increasingly ubiquitous.
HybridMIM: A Hybrid Masked Image Modeling Framework for 3D Medical Image Segmentation
Mar 18, 2023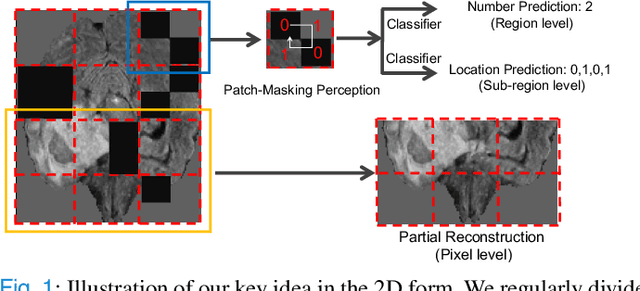
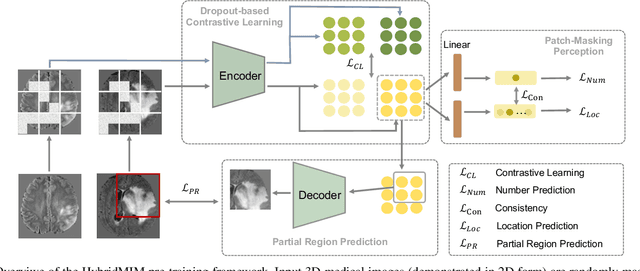
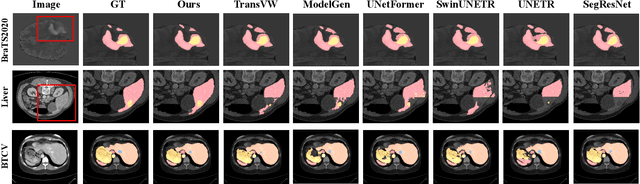
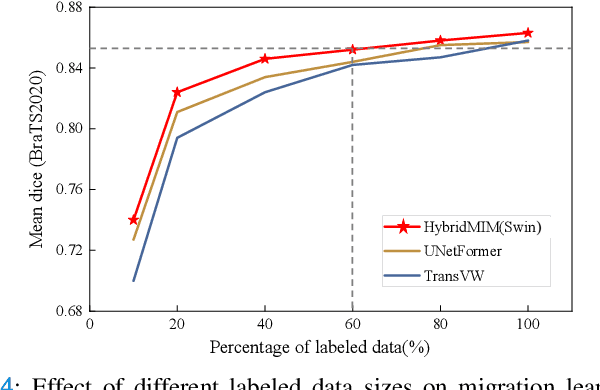
Masked image modeling (MIM) with transformer backbones has recently been exploited as a powerful self-supervised pre-training technique. The existing MIM methods adopt the strategy to mask random patches of the image and reconstruct the missing pixels, which only considers semantic information at a lower level, and causes a long pre-training time.This paper presents HybridMIM, a novel hybrid self-supervised learning method based on masked image modeling for 3D medical image segmentation.Specifically, we design a two-level masking hierarchy to specify which and how patches in sub-volumes are masked, effectively providing the constraints of higher level semantic information. Then we learn the semantic information of medical images at three levels, including:1) partial region prediction to reconstruct key contents of the 3D image, which largely reduces the pre-training time burden (pixel-level); 2) patch-masking perception to learn the spatial relationship between the patches in each sub-volume (region-level).and 3) drop-out-based contrastive learning between samples within a mini-batch, which further improves the generalization ability of the framework (sample-level). The proposed framework is versatile to support both CNN and transformer as encoder backbones, and also enables to pre-train decoders for image segmentation. We conduct comprehensive experiments on four widely-used public medical image segmentation datasets, including BraTS2020, BTCV, MSD Liver, and MSD Spleen. The experimental results show the clear superiority of HybridMIM against competing supervised methods, masked pre-training approaches, and other self-supervised methods, in terms of quantitative metrics, timing performance and qualitative observations. The codes of HybridMIM are available at https://github.com/ge-xing/HybridMIM
Impact of NOMA on Age of Information: A Grant-Free Transmission Perspective
Nov 24, 2022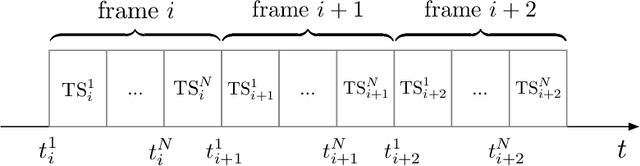
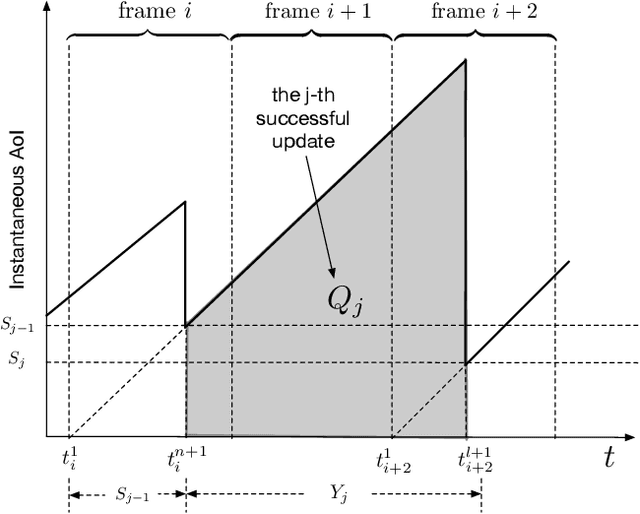
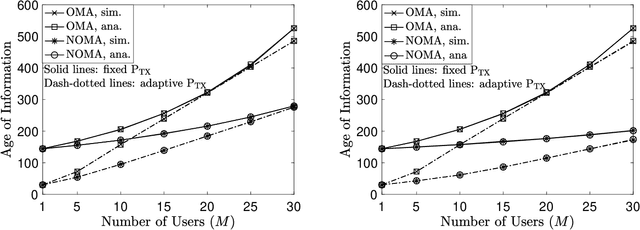
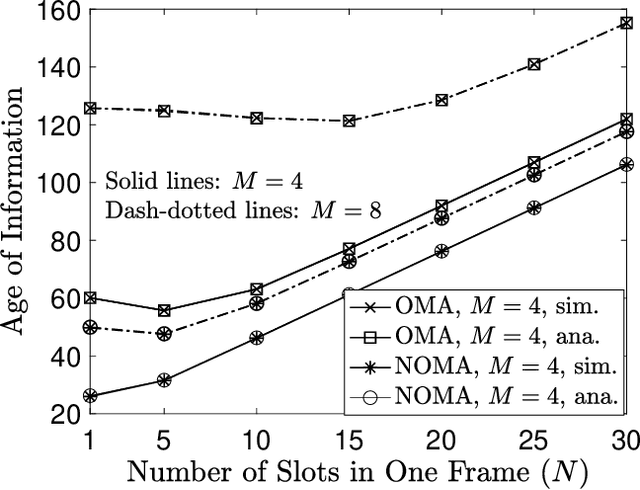
The aim of this paper is to characterize the impact of non-orthogonal multiple access (NOMA) on the age of information (AoI) of grant-free transmission. In particular, a low-complexity form of NOMA, termed NOMA-assisted random access, is applied to grant-free transmission in order to illustrate the two benefits of NOMA for AoI reduction, namely increasing channel access and reducing user collisions. Closed-form analytical expressions for the AoI achieved by NOMA assisted grant-free transmission are obtained, and asymptotic studies are carried out to demonstrate that the use of the simplest form of NOMA is already sufficient to reduce the AoI of orthogonal multiple access (OMA) by more than 40%. In addition, the developed analytical expressions are also shown to be useful for optimizing the users' transmission attempt probabilities, which are key parameters for grant-free transmission.