 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AIC-AB NET: A Neural Network for Image Captioning with Spatial Attention and Text Attributes
Jul 14, 2023
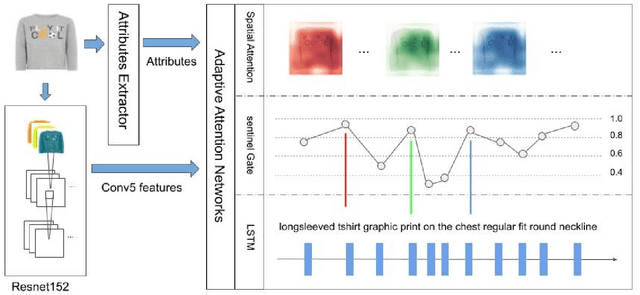
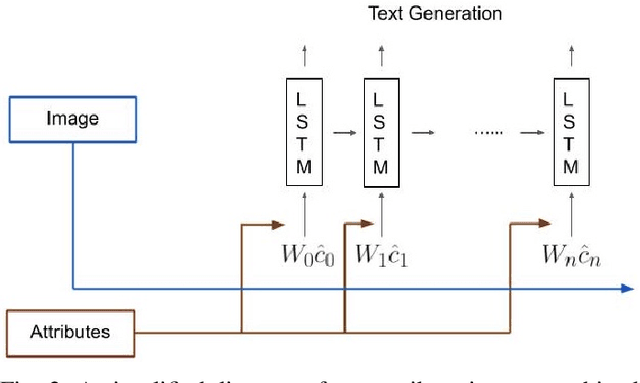
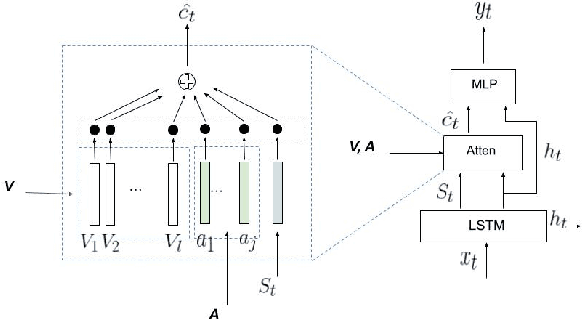

Image captioning is a significant field across computer vision and natural language processing. We propose and present AIC-AB NET, a novel Attribute-Information-Combined Attention-Based Network that combines spatial attention architecture and text attributes in an encoder-decoder. For caption generation, adaptive spatial attention determines which image region best represents the image and whether to attend to the visual features or the visual sentinel. Text attribute information is synchronously fed into the decoder to help image recognition and reduce uncertainty. We have tested and evaluated our AICAB NET on the MS COCO dataset and a new proposed Fashion dataset. The Fashion dataset is employed as a benchmark of single-object images. The results show the superior performance of the proposed model compared to the state-of-the-art baseline and ablated models on both the images from MSCOCO and our single-object images. Our AIC-AB NET outperforms the baseline adaptive attention network by 0.017 (CIDEr score) on the MS COCO dataset and 0.095 (CIDEr score) on the Fashion dataset.
Fine-grained Text-Video Retrieval with Frozen Image Encoders
Jul 14, 2023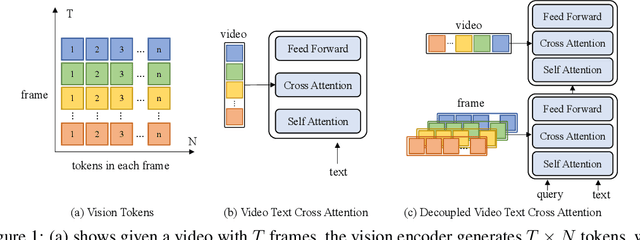
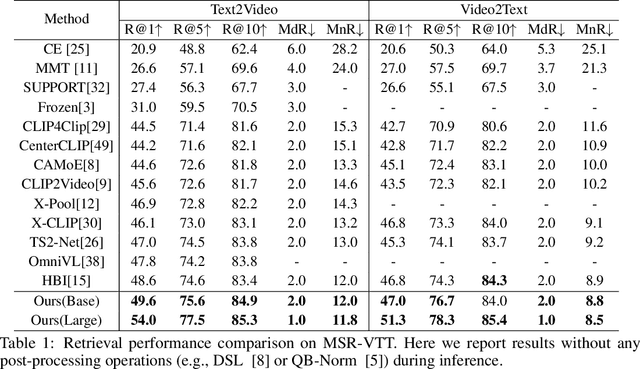
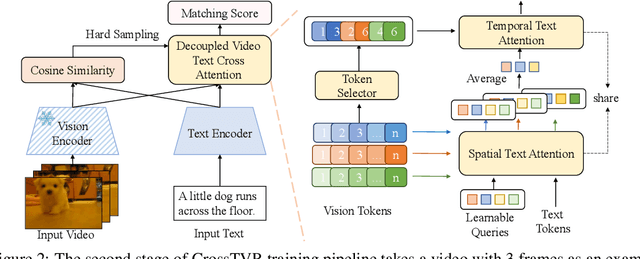

State-of-the-art text-video retrieval (TVR) methods typically utilize CLIP and cosine similarity for efficient retrieval. Meanwhile, cross attention methods, which employ a transformer decoder to compute attention between each text query and all frames in a video, offer a more comprehensive interaction between text and videos. However, these methods lack important fine-grained spatial information as they directly compute attention between text and video-level tokens. To address this issue, we propose CrossTVR, a two-stage text-video retrieval architecture. In the first stage, we leverage existing TVR methods with cosine similarity network for efficient text/video candidate selection. In the second stage, we propose a novel decoupled video text cross attention module to capture fine-grained multimodal information in spatial and temporal dimensions. Additionally, we employ the frozen CLIP model strategy in fine-grained retrieval, enabling scalability to larger pre-trained vision models like ViT-G, resulting in improved retrieval performance. Experiments on text video retrieval datasets demonstrate the effectiveness and scalability of our proposed CrossTVR compared to state-of-the-art approaches.
Gloss Attention for Gloss-free Sign Language Translation
Jul 14, 2023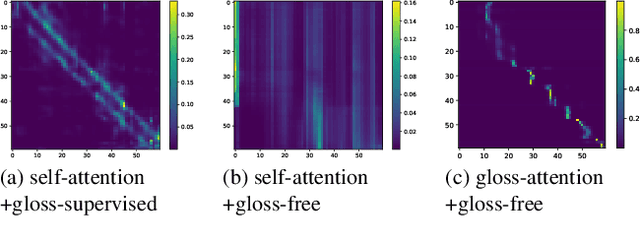
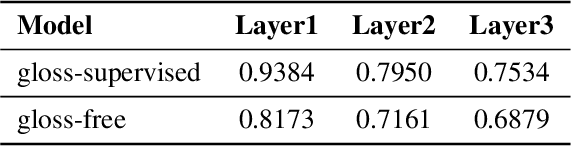

Most sign language translation (SLT) methods to date require the use of gloss annotations to provide additional supervision information, however, the acquisition of gloss is not easy. To solve this problem, we first perform an analysis of existing models to confirm how gloss annotations make SLT easier. We find that it can provide two aspects of information for the model, 1) it can help the model implicitly learn the location of semantic boundaries in continuous sign language videos, 2) it can help the model understand the sign language video globally. We then propose \emph{gloss attention}, which enables the model to keep its attention within video segments that have the same semantics locally, just as gloss helps existing models do. Furthermore, we transfer the knowledge of sentence-to-sentence similarity from the natural language model to our gloss attention SLT network (GASLT) to help it understand sign language videos at the sentence level. Experimental results on multiple large-scale sign language datasets show that our proposed GASLT model significantly outperforms existing methods. Our code is provided in \url{https://github.com/YinAoXiong/GASLT}.
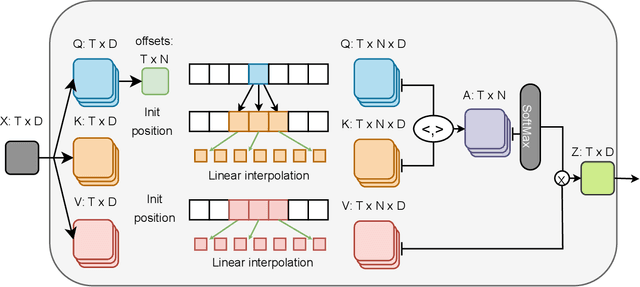
Generalized Weak Supervision for Neural Information Retrieval
Apr 18, 2023
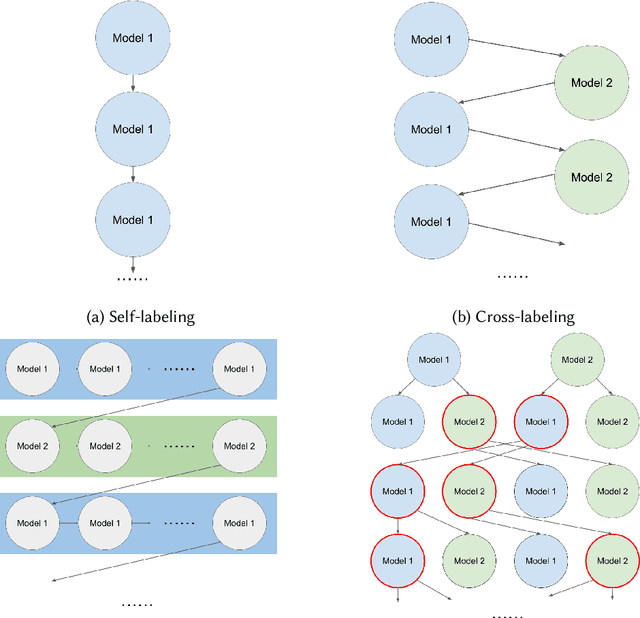
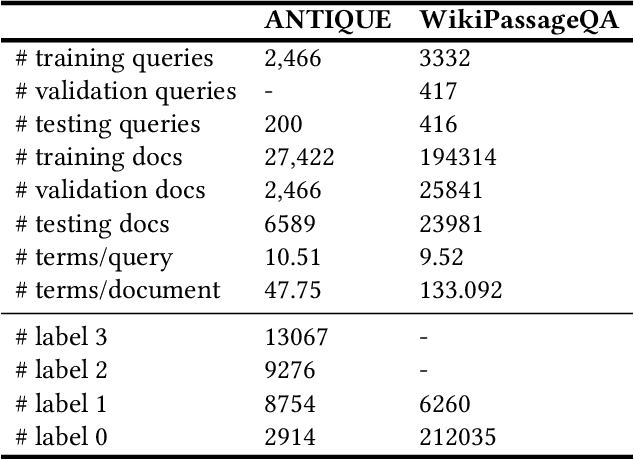
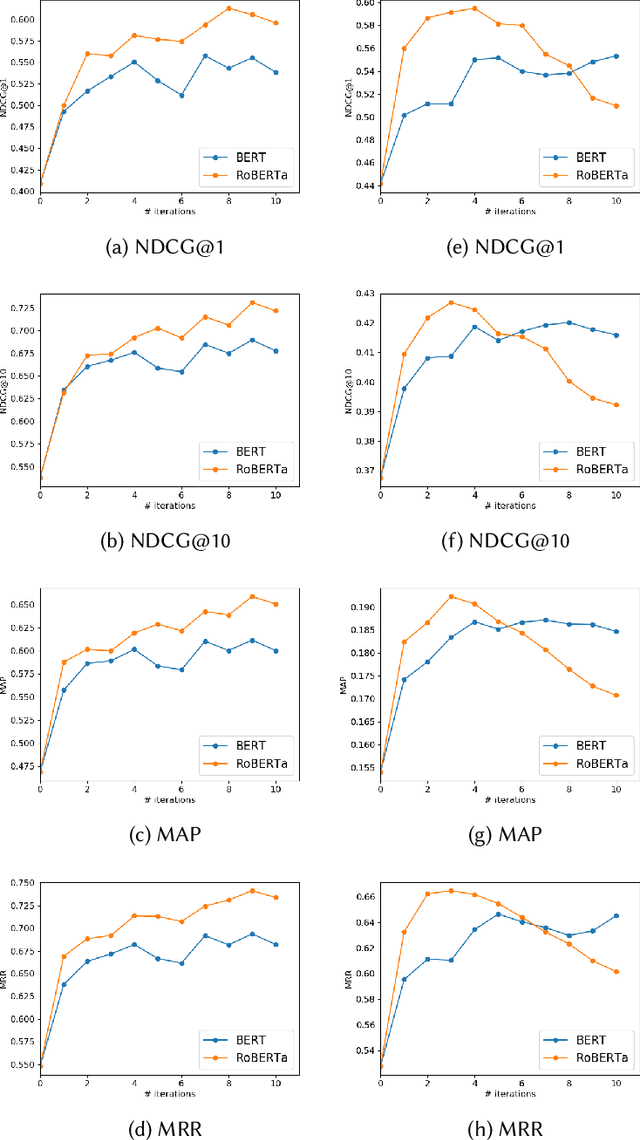
Neural ranking models (NRMs) have demonstrated effective performance in several information retrieval (IR) tasks. However, training NRMs often requires large-scale training data, which is difficult and expensive to obtain. To address this issue, one can train NRMs via weak supervision, where a large dataset is automatically generated using an existing ranking model (called the weak labeler) for training NRMs. Weakly supervised NRMs can generalize from the observed data and significantly outperform the weak labeler. This paper generalizes this idea through an iterative re-labeling process, demonstrating that weakly supervised models can iteratively play the role of weak labeler and significantly improve ranking performance without using manually labeled data. The proposed Generalized Weak Supervision (GWS) solution is generic and orthogonal to the ranking model architecture. This paper offers four implementations of GWS: self-labeling, cross-labeling, joint cross- and self-labeling, and greedy multi-labeling. GWS also benefits from a query importance weighting mechanism based on query performance prediction methods to reduce noise in the generated training data. We further draw a theoretical connection between self-labeling and Expectation-Maximization. Our experiments on two passage retrieval benchmarks suggest that all implementations of GWS lead to substantial improvements compared to weak supervision in all cases.
Asymmetric $X$-Secure $T$-Private Information Retrieval: More Databases is Not Always Better
May 09, 2023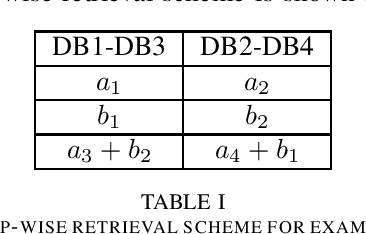
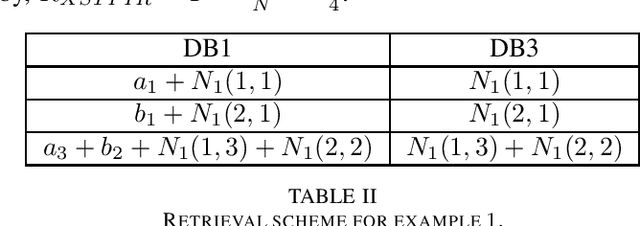
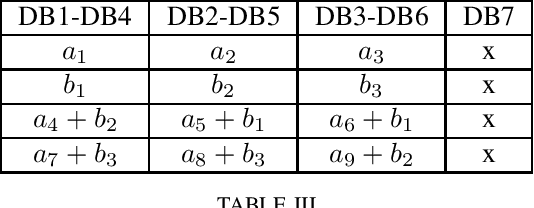

We consider a special case of $X$-secure $T$-private information retrieval (XSTPIR), where the security requirement is \emph{asymmetric} due to possible missing communication links between the $N$ databases considered in the system. We define the problem with a communication matrix that indicates all possible communications among the databases, and propose a database grouping mechanism that collects subsets of databases in an optimal manner, followed by a group-based PIR scheme to perform asymmetric XSTPIR with the goal of maximizing the communication rate (minimizing the download cost). We provide an upper bound on the general achievable rate of asymmetric XSTPIR, and show that the proposed scheme achieves this upper bound in some cases. The proposed approach outperforms classical XSTPIR under certain conditions, and the results of this work show that unlike in the symmetric case, some databases with certain properties can be dropped to achieve higher rates, concluding that more databases is not always better.
Of Models and Tin Men -- a behavioural economics study of principal-agent problems in AI alignment using large-language models
Jul 20, 2023AI Alignment is often presented as an interaction between a single designer and an artificial agent in which the designer attempts to ensure the agent's behavior is consistent with its purpose, and risks arise solely because of conflicts caused by inadvertent misalignment between the utility function intended by the designer and the resulting internal utility function of the agent. With the advent of agents instantiated with large-language models (LLMs), which are typically pre-trained, we argue this does not capture the essential aspects of AI safety because in the real world there is not a one-to-one correspondence between designer and agent, and the many agents, both artificial and human, have heterogeneous values. Therefore, there is an economic aspect to AI safety and the principal-agent problem is likely to arise. In a principal-agent problem conflict arises because of information asymmetry together with inherent misalignment between the utility of the agent and its principal, and this inherent misalignment cannot be overcome by coercing the agent into adopting a desired utility function through training. We argue the assumptions underlying principal-agent problems are crucial to capturing the essence of safety problems involving pre-trained AI models in real-world situations. Taking an empirical approach to AI safety, we investigate how GPT models respond in principal-agent conflicts. We find that agents based on both GPT-3.5 and GPT-4 override their principal's objectives in a simple online shopping task, showing clear evidence of principal-agent conflict. Surprisingly, the earlier GPT-3.5 model exhibits more nuanced behaviour in response to changes in information asymmetry, whereas the later GPT-4 model is more rigid in adhering to its prior alignment. Our results highlight the importance of incorporating principles from economics into the alignment process.
Privacy-Preserving Graph Machine Learning from Data to Computation: A Survey
Jul 10, 2023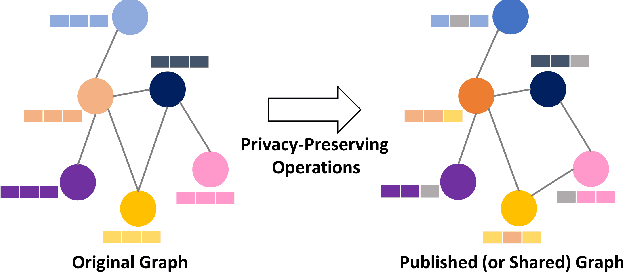
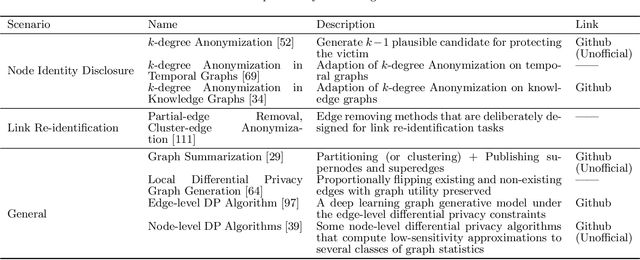
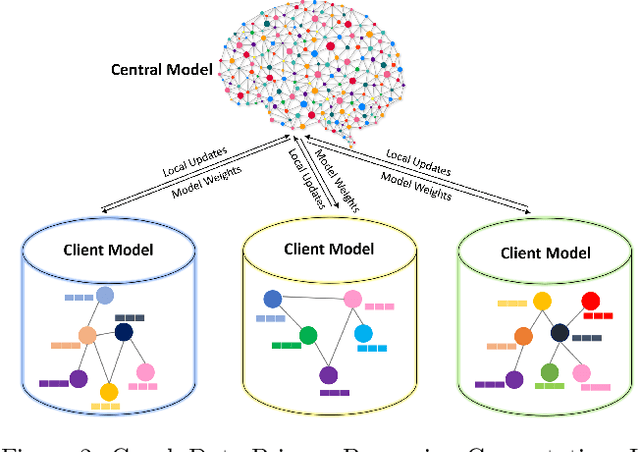
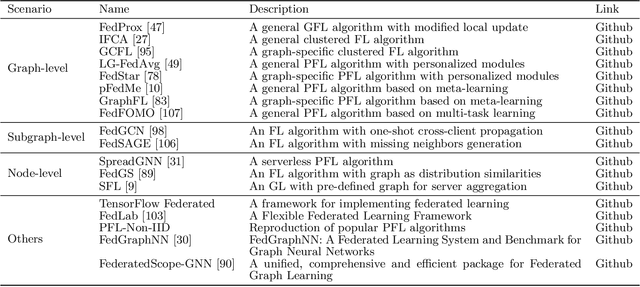
In graph machine learning, data collection, sharing, and analysis often involve multiple parties, each of which may require varying levels of data security and privacy. To this end, preserving privacy is of great importance in protecting sensitive information. In the era of big data, the relationships among data entities have become unprecedentedly complex, and more applications utilize advanced data structures (i.e., graphs) that can support network structures and relevant attribute information. To date, many graph-based AI models have been proposed (e.g., graph neural networks) for various domain tasks, like computer vision and natural language processing. In this paper, we focus on reviewing privacy-preserving techniques of graph machine learning. We systematically review related works from the data to the computational aspects. We first review methods for generating privacy-preserving graph data. Then we describe methods for transmitting privacy-preserved information (e.g., graph model parameters) to realize the optimization-based computation when data sharing among multiple parties is risky or impossible. In addition to discussing relevant theoretical methodology and software tools, we also discuss current challenges and highlight several possible future research opportunities for privacy-preserving graph machine learning. Finally, we envision a unified and comprehensive secure graph machine learning system.
Transformers are Universal Predictors
Jul 15, 2023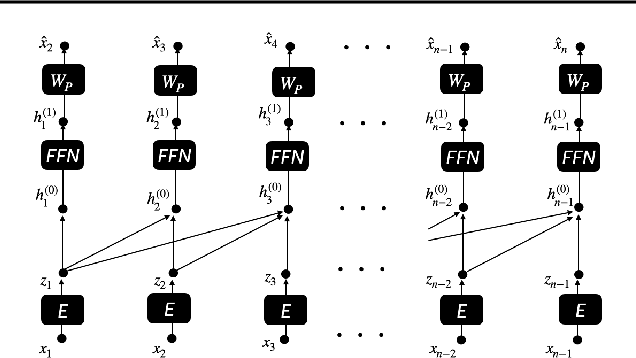
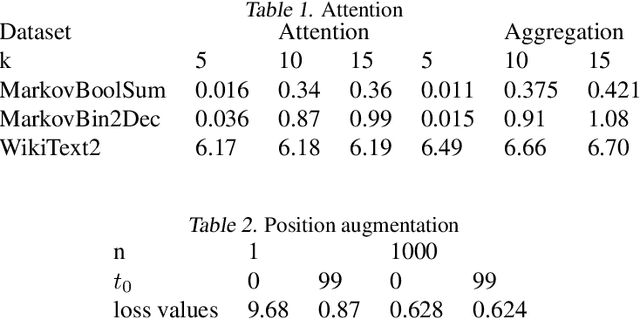
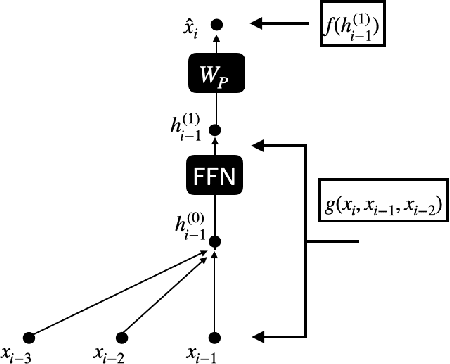
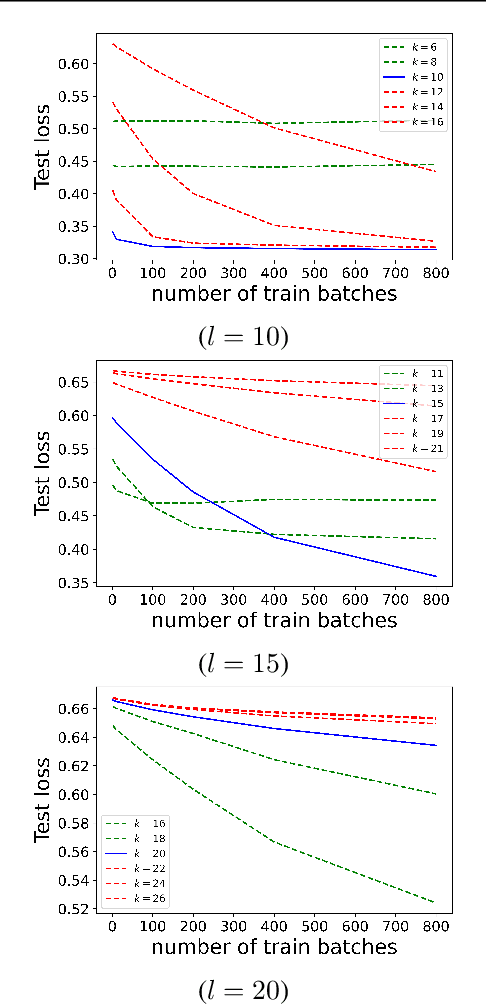
We find limits to the Transformer architecture for language modeling and show it has a universal prediction property in an information-theoretic sense. We further analyze performance in non-asymptotic data regimes to understand the role of various components of the Transformer architecture, especially in the context of data-efficient training. We validate our theoretical analysis with experiments on both synthetic and real datasets.
A Personalized Recommender System Based-on Knowledge Graph Embeddings
Jul 20, 2023Knowledge graphs have proven to be effective for modeling entities and their relationships through the use of ontologies. The recent emergence in interest for using knowledge graphs as a form of information modeling has led to their increased adoption in recommender systems. By incorporating users and items into the knowledge graph, these systems can better capture the implicit connections between them and provide more accurate recommendations. In this paper, we investigate and propose the construction of a personalized recommender system via knowledge graphs embedding applied to the vehicle purchase/sale domain. The results of our experimentation demonstrate the efficacy of the proposed method in providing relevant recommendations that are consistent with individual users.
Depth from Defocus Technique: A Simple Calibration-Free Approach for Dispersion Size Measurement
Jul 20, 2023Dispersed particle size measurement is crucial in a variety of applications, be it in the sizing of spray droplets, tracking of particulate matter in multiphase flows, or the detection of target markers in machine vision systems. Further to sizing, such systems are characterised by extracting quantitative information like spatial position and associated velocity of the dispersed phase particles. In the present study we propose an imaging based volumetric measurement approach for estimating the size and position of spherically dispersed particles. The approach builds on the 'Depth from Defocus' (DFD) technique using a single camera approach. The simple optical configuration, consisting of a shadowgraph setup and a straightforward calibration procedure, makes this method readily deployable and accessible for broader applications.