 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Integrating large language models and active inference to understand eye movements in reading and dyslexia
Aug 09, 2023
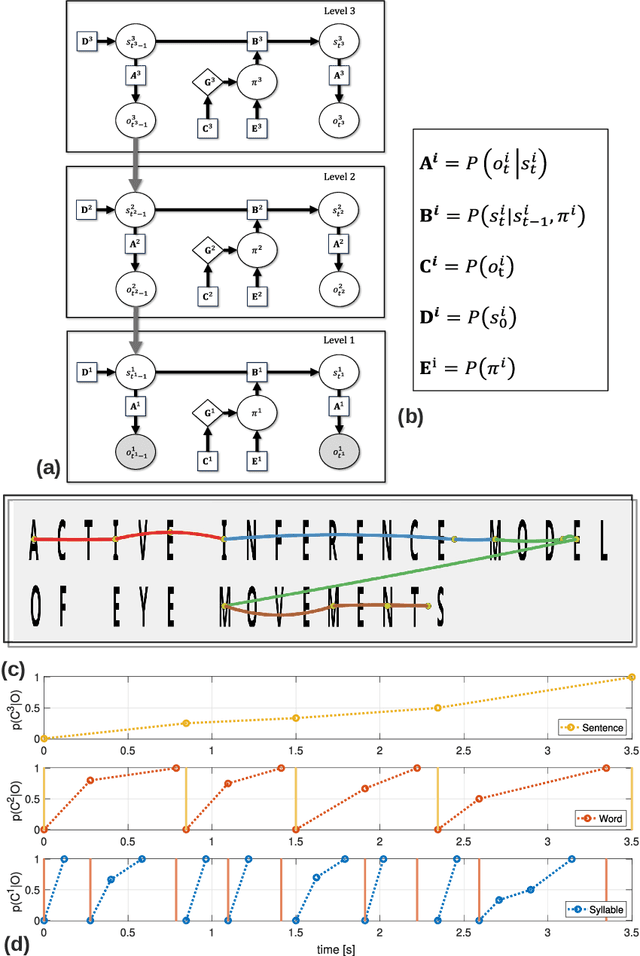
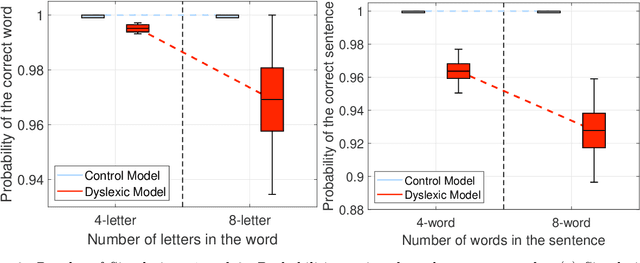
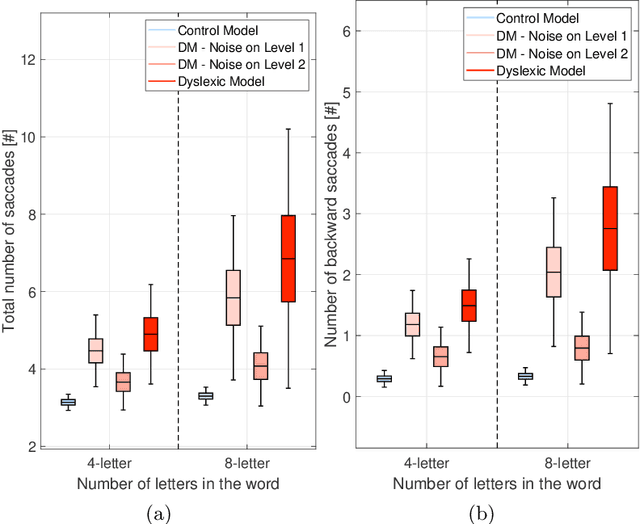
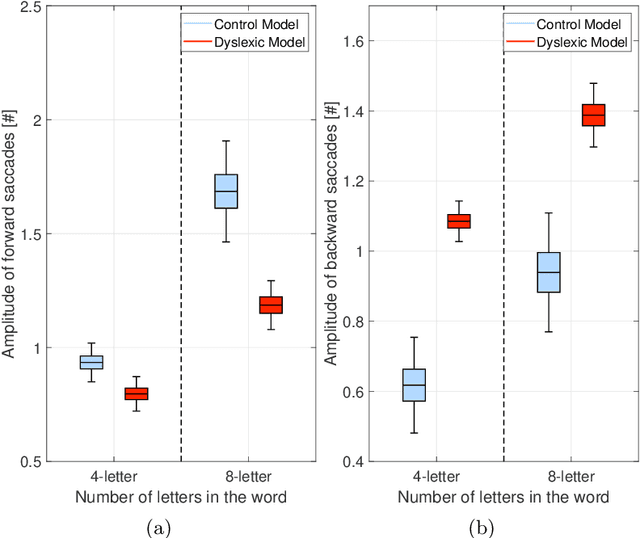
We present a novel computational model employing hierarchical active inference to simulate reading and eye movements. The model characterizes linguistic processing as inference over a hierarchical generative model, facilitating predictions and inferences at various levels of granularity, from syllables to sentences. Our approach combines the strengths of large language models for realistic textual predictions and active inference for guiding eye movements to informative textual information, enabling the testing of predictions. The model exhibits proficiency in reading both known and unknown words and sentences, adhering to the distinction between lexical and nonlexical routes in dual-route theories of reading. Notably, our model permits the exploration of maladaptive inference effects on eye movements during reading, such as in dyslexia. To simulate this condition, we attenuate the contribution of priors during the reading process, leading to incorrect inferences and a more fragmented reading style, characterized by a greater number of shorter saccades. This alignment with empirical findings regarding eye movements in dyslexic individuals highlights the model's potential to aid in understanding the cognitive processes underlying reading and eye movements, as well as how reading deficits associated with dyslexia may emerge from maladaptive predictive processing. In summary, our model represents a significant advancement in comprehending the intricate cognitive processes involved in reading and eye movements, with potential implications for understanding and addressing dyslexia through the simulation of maladaptive inference. It may offer valuable insights into this condition and contribute to the development of more effective interventions for treatment.
Quantifying Consistency and Information Loss for Causal Abstraction Learning
May 07, 2023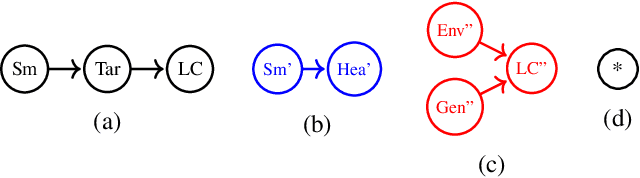
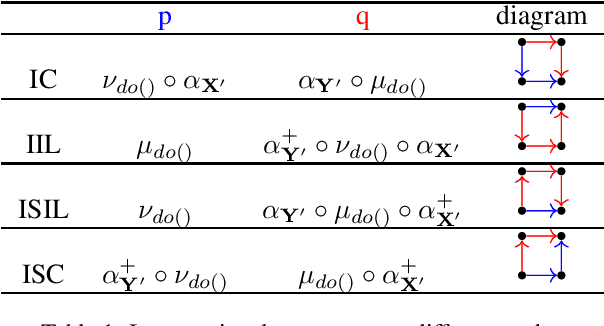
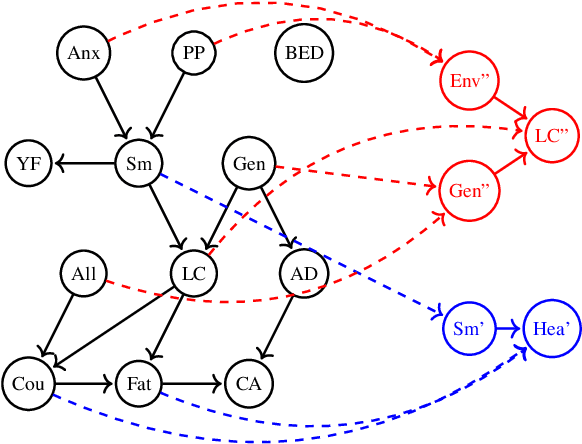

Structural causal models provide a formalism to express causal relations between variables of interest. Models and variables can represent a system at different levels of abstraction, whereby relations may be coarsened and refined according to the need of a modeller. However, switching between different levels of abstraction requires evaluating a trade-off between the consistency and the information loss among different models. In this paper we introduce a family of interventional measures that an agent may use to evaluate such a trade-off. We consider four measures suited for different tasks, analyze their properties, and propose algorithms to evaluate and learn causal abstractions. Finally, we illustrate the flexibility of our setup by empirically showing how different measures and algorithmic choices may lead to different abstractions.
Memory Encoding Model
Aug 02, 2023We explore a new class of brain encoding model by adding memory-related information as input. Memory is an essential brain mechanism that works alongside visual stimuli. During a vision-memory cognitive task, we found the non-visual brain is largely predictable using previously seen images. Our Memory Encoding Model (Mem) won the Algonauts 2023 visual brain competition even without model ensemble (single model score 66.8, ensemble score 70.8). Our ensemble model without memory input (61.4) can also stand a 3rd place. Furthermore, we observe periodic delayed brain response correlated to 6th-7th prior image, and hippocampus also showed correlated activity timed with this periodicity. We conjuncture that the periodic replay could be related to memory mechanism to enhance the working memory.
Complex Facial Expression Recognition Using Deep Knowledge Distillation of Basic Features
Aug 11, 2023
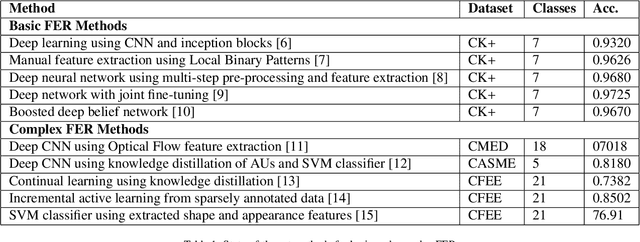
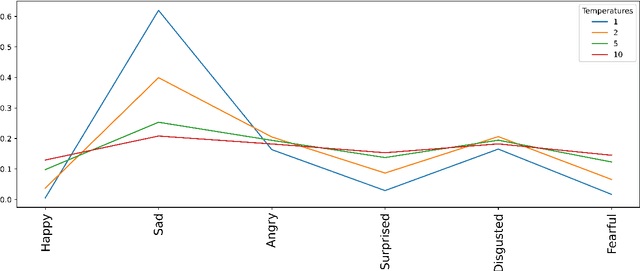
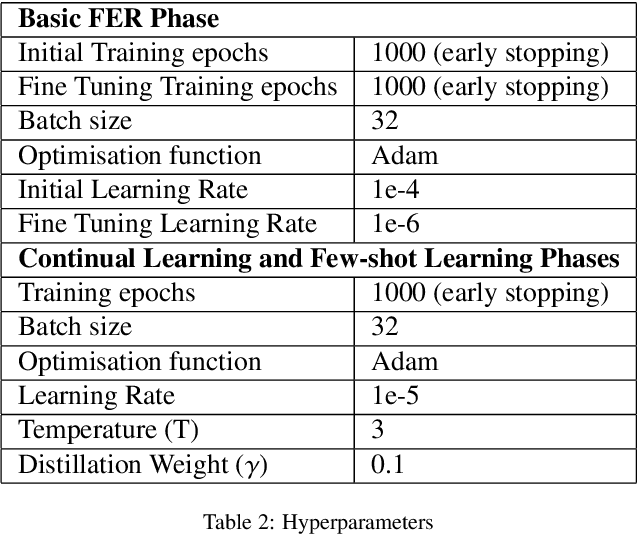
Complex emotion recognition is a cognitive task that has so far eluded the same excellent performance of other tasks that are at or above the level of human cognition. Emotion recognition through facial expressions is particularly difficult due to the complexity of emotions expressed by the human face. For a machine to approach the same level of performance in this domain as a human, it may need to synthesise knowledge and understand new concepts in real-time as humans do. Humans are able to learn new concepts using only few examples, by distilling the important information from memories and discarding the rest. Similarly, continual learning methods learn new classes whilst retaining the knowledge of known classes, whilst few-shot learning methods are able to learn new classes using very few training examples. We propose a novel continual learning method inspired by human cognition and learning that can accurately recognise new compound expression classes using few training samples, by building on and retaining its knowledge of basic expression classes. Using GradCAM visualisations, we demonstrate the relationship between basic and compound facial expressions, which our method leverages through knowledge distillation and a novel Predictive Sorting Memory Replay. Our method achieves the current state-of-the-art in continual learning for complex facial expression recognition with 74.28% Overall Accuracy on new classes. We also demonstrate that using continual learning for complex facial expression recognition achieves far better performance than non-continual learning methods, improving on state-of-the-art non-continual learning methods by 13.95%. To the best of our knowledge, our work is also the first to apply few-shot learning to complex facial expression recognition, achieving the state-of-the-art with 100% accuracy using a single training sample for each expression class.
KETM:A Knowledge-Enhanced Text Matching method
Aug 11, 2023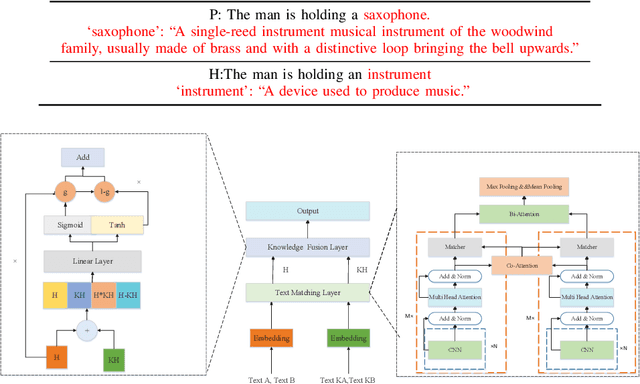
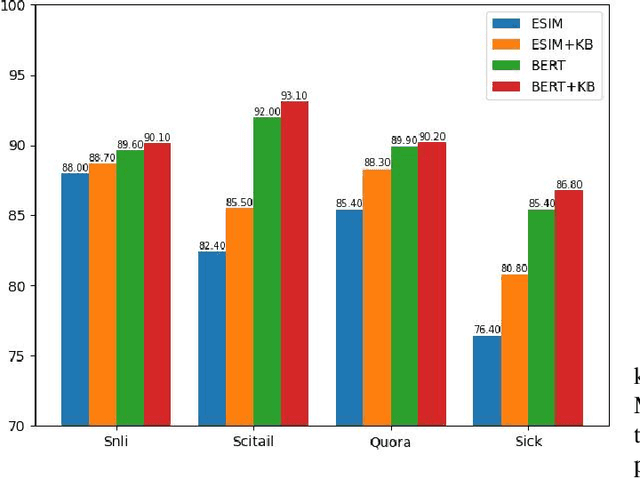
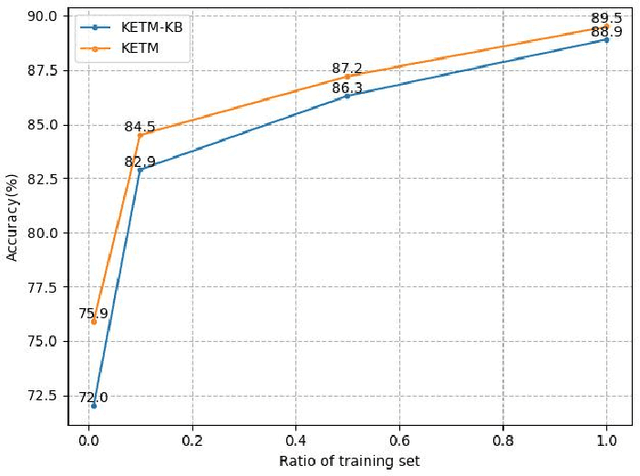
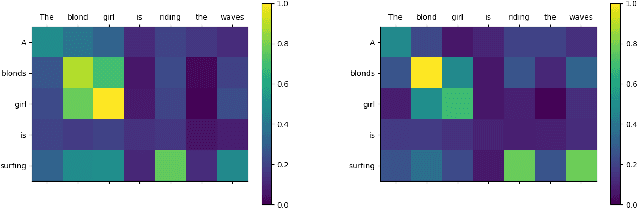
Text matching is the task of matching two texts and determining the relationship between them, which has extensive applications in natural language processing tasks such as reading comprehension, and Question-Answering systems. The mainstream approach is to compute text representations or to interact with the text through attention mechanism, which is effective in text matching tasks. However, the performance of these models is insufficient for texts that require commonsense knowledge-based reasoning. To this end, in this paper, We introduce a new model for text matching called the Knowledge Enhanced Text Matching model (KETM), to enrich contextual representations with real-world common-sense knowledge from external knowledge sources to enhance our model understanding and reasoning. First, we use Wiktionary to retrieve the text word definitions as our external knowledge. Secondly, we feed text and knowledge to the text matching module to extract their feature vectors. The text matching module is used as an interaction module by integrating the encoder layer, the co-attention layer, and the aggregation layer. Specifically, the interaction process is iterated several times to obtain in-depth interaction information and extract the feature vectors of text and knowledge by multi-angle pooling. Then, we fuse text and knowledge using a gating mechanism to learn the ratio of text and knowledge fusion by a neural network that prevents noise generated by knowledge. After that, experimental validation on four datasets are carried out, and the experimental results show that our proposed model performs well on all four datasets, and the performance of our method is improved compared to the base model without adding external knowledge, which validates the effectiveness of our proposed method. The code is available at https://github.com/1094701018/KETM
Change detection needs change information: improving deep 3D point cloud change detection
Apr 25, 2023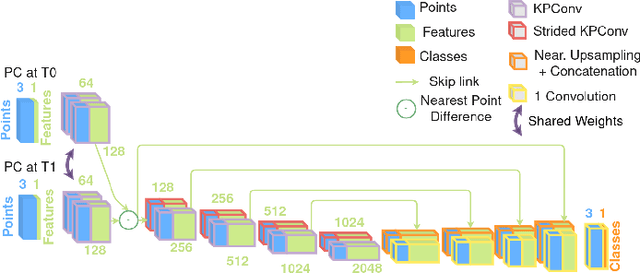
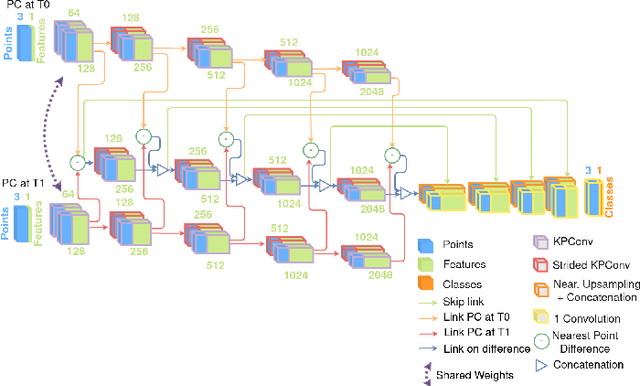
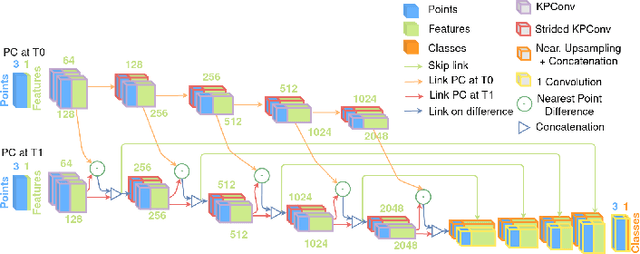
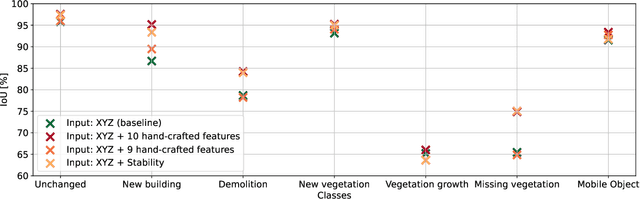
Change detection is an important task to rapidly identify modified areas, in particular when multi-temporal data are concerned. In landscapes with complex geometry such as urban environment, vertical information turn out to be a very useful knowledge not only to highlight changes but also to classify them into different categories. In this paper, we focus on change segmentation directly using raw 3D point clouds (PCs), to avoid any loss of information due to rasterization processes. While deep learning has recently proved its effectiveness for this particular task by encoding the information through Siamese networks, we investigate here the idea of also using change information in early steps of deep networks. To do this, we first propose to provide the Siamese KPConv State-of-The-Art (SoTA) network with hand-crafted features and especially a change-related one. This improves the mean of Intersection over Union (IoU) over classes of change by 4.70\%. Considering that the major improvement was obtained thanks to the change-related feature, we propose three new architectures to address 3D PCs change segmentation: OneConvFusion, Triplet KPConv, and Encoder Fusion SiamKPConv. All the three networks take into account change information in early steps and outperform SoTA methods. In particular, the last network, entitled Encoder Fusion SiamKPConv, overtakes SoTA with more than 5% of mean of IoU over classes of change emphasizing the value of having the network focus on change information for change detection task.
See More and Know More: Zero-shot Point Cloud Segmentation via Multi-modal Visual Data
Jul 20, 2023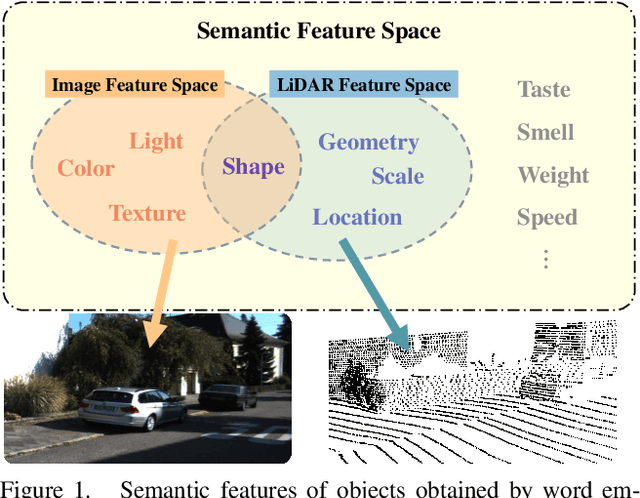
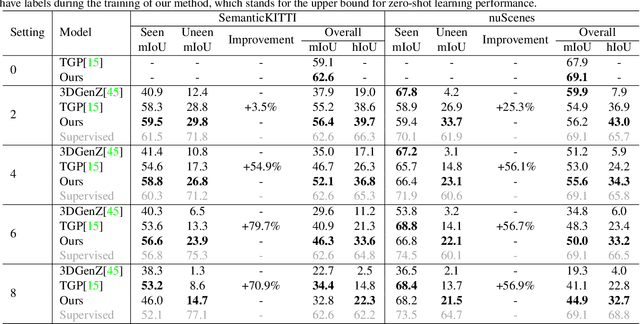
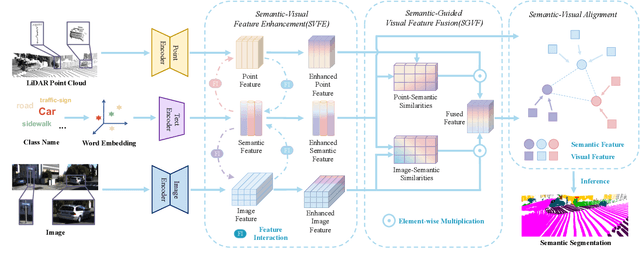
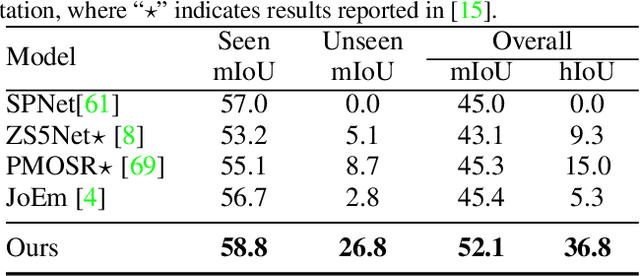
Zero-shot point cloud segmentation aims to make deep models capable of recognizing novel objects in point cloud that are unseen in the training phase. Recent trends favor the pipeline which transfers knowledge from seen classes with labels to unseen classes without labels. They typically align visual features with semantic features obtained from word embedding by the supervision of seen classes' annotations. However, point cloud contains limited information to fully match with semantic features. In fact, the rich appearance information of images is a natural complement to the textureless point cloud, which is not well explored in previous literature. Motivated by this, we propose a novel multi-modal zero-shot learning method to better utilize the complementary information of point clouds and images for more accurate visual-semantic alignment. Extensive experiments are performed in two popular benchmarks, i.e., SemanticKITTI and nuScenes, and our method outperforms current SOTA methods with 52% and 49% improvement on average for unseen class mIoU, respectively.
How Curvature Enhance the Adaptation Power of Framelet GCNs
Jul 19, 2023
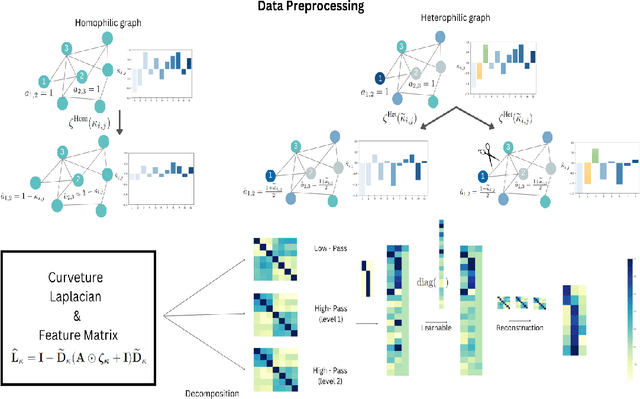
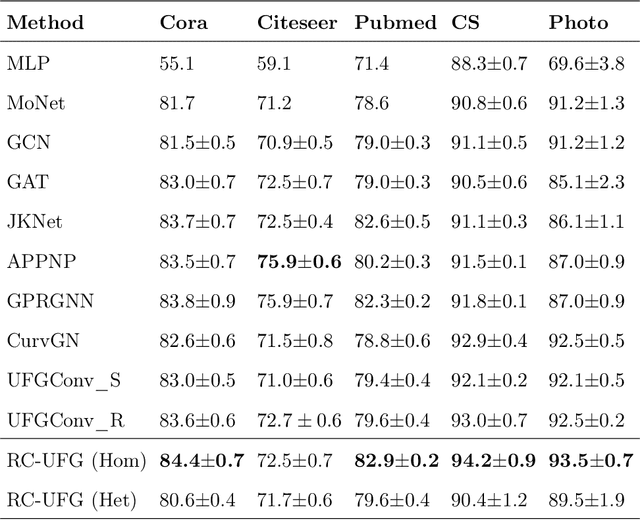
Graph neural network (GNN) has been demonstrated powerful in modeling graph-structured data. However, despite many successful cases of applying GNNs to various graph classification and prediction tasks, whether the graph geometrical information has been fully exploited to enhance the learning performance of GNNs is not yet well understood. This paper introduces a new approach to enhance GNN by discrete graph Ricci curvature. Specifically, the graph Ricci curvature defined on the edges of a graph measures how difficult the information transits on one edge from one node to another based on their neighborhoods. Motivated by the geometric analogy of Ricci curvature in the graph setting, we prove that by inserting the curvature information with different carefully designed transformation function $\zeta$, several known computational issues in GNN such as over-smoothing can be alleviated in our proposed model. Furthermore, we verified that edges with very positive Ricci curvature (i.e., $\kappa_{i,j} \approx 1$) are preferred to be dropped to enhance model's adaption to heterophily graph and one curvature based graph edge drop algorithm is proposed. Comprehensive experiments show that our curvature-based GNN model outperforms the state-of-the-art baselines in both homophily and heterophily graph datasets, indicating the effectiveness of involving graph geometric information in GNNs.
Information Geometrically Generalized Covariate Shift Adaptation
Apr 19, 2023Many machine learning methods assume that the training and test data follow the same distribution. However, in the real world, this assumption is very often violated. In particular, the phenomenon that the marginal distribution of the data changes is called covariate shift, one of the most important research topics in machine learning. We show that the well-known family of covariate shift adaptation methods is unified in the framework of information geometry. Furthermore, we show that parameter search for geometrically generalized covariate shift adaptation method can be achieved efficiently. Numerical experiments show that our generalization can achieve better performance than the existing methods it encompasses.
GeneMask: Fast Pretraining of Gene Sequences to Enable Few-Shot Learning
Jul 29, 2023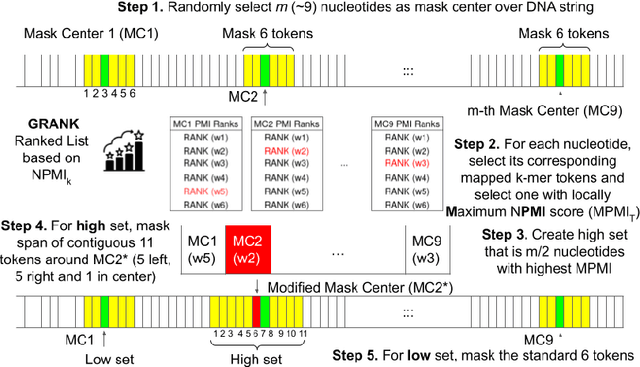
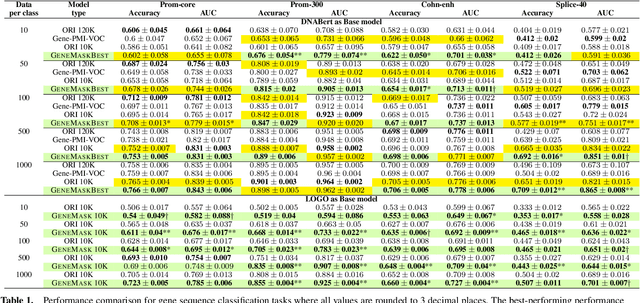
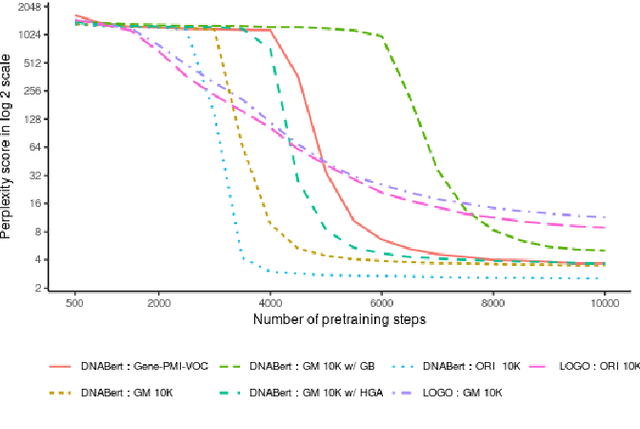

Large-scale language models such as DNABert and LOGO aim to learn optimal gene representations and are trained on the entire Human Reference Genome. However, standard tokenization schemes involve a simple sliding window of tokens like k-mers that do not leverage any gene-based semantics and thus may lead to (trivial) masking of easily predictable sequences and subsequently inefficient Masked Language Modeling (MLM) training. Therefore, we propose a novel masking algorithm, GeneMask, for MLM training of gene sequences, where we randomly identify positions in a gene sequence as mask centers and locally select the span around the mask center with the highest Normalized Pointwise Mutual Information (NPMI) to mask. We observe that in the absence of human-understandable semantics in the genomics domain (in contrast, semantic units like words and phrases are inherently available in NLP), GeneMask-based models substantially outperform the SOTA models (DNABert and LOGO) over four benchmark gene sequence classification datasets in five few-shot settings (10 to 1000-shot). More significantly, the GeneMask-based DNABert model is trained for less than one-tenth of the number of epochs of the original SOTA model. We also observe a strong correlation between top-ranked PMI tokens and conserved DNA sequence motifs, which may indicate the incorporation of latent genomic information. The codes (including trained models) and datasets are made publicly available at https://github.com/roysoumya/GeneMask.