 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mitigating Exposure Bias in Discriminator Guided Diffusion Models
Nov 18, 2023
Diffusion Models have demonstrated remarkable performance in image generation. However, their demanding computational requirements for training have prompted ongoing efforts to enhance the quality of generated images through modifications in the sampling process. A recent approach, known as Discriminator Guidance, seeks to bridge the gap between the model score and the data score by incorporating an auxiliary term, derived from a discriminator network. We show that despite significantly improving sample quality, this technique has not resolved the persistent issue of Exposure Bias and we propose SEDM-G++, which incorporates a modified sampling approach, combining Discriminator Guidance and Epsilon Scaling. Our proposed approach outperforms the current state-of-the-art, by achieving an FID score of 1.73 on the unconditional CIFAR-10 dataset.
Uni-paint: A Unified Framework for Multimodal Image Inpainting with Pretrained Diffusion Model
Oct 11, 2023Recently, text-to-image denoising diffusion probabilistic models (DDPMs) have demonstrated impressive image generation capabilities and have also been successfully applied to image inpainting. However, in practice, users often require more control over the inpainting process beyond textual guidance, especially when they want to composite objects with customized appearance, color, shape, and layout. Unfortunately, existing diffusion-based inpainting methods are limited to single-modal guidance and require task-specific training, hindering their cross-modal scalability. To address these limitations, we propose Uni-paint, a unified framework for multimodal inpainting that offers various modes of guidance, including unconditional, text-driven, stroke-driven, exemplar-driven inpainting, as well as a combination of these modes. Furthermore, our Uni-paint is based on pretrained Stable Diffusion and does not require task-specific training on specific datasets, enabling few-shot generalizability to customized images. We have conducted extensive qualitative and quantitative evaluations that show our approach achieves comparable results to existing single-modal methods while offering multimodal inpainting capabilities not available in other methods. Code will be available at https://github.com/ysy31415/unipaint.
Natural Disaster Analysis using Satellite Imagery and Social-Media Data for Emergency Response Situations
Nov 16, 2023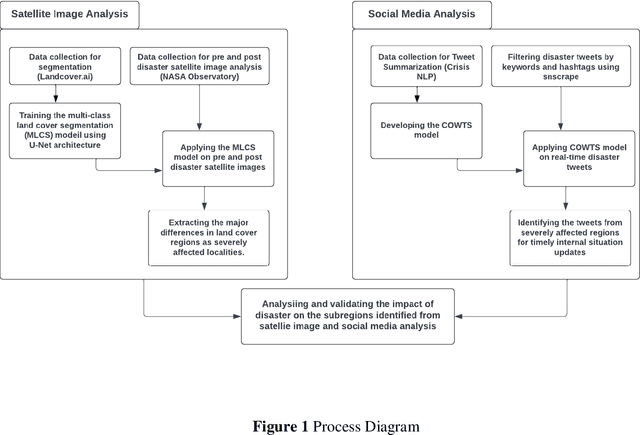


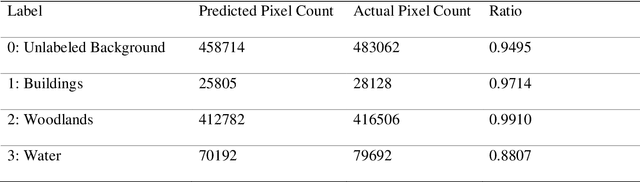
Disaster Management is one of the most promising research areas because of its significant economic, environmental and social repercussions. This research focuses on analyzing different types of data (pre and post satellite images and twitter data) related to disaster management for in-depth analysis of location-wise emergency requirements. This research has been divided into two stages, namely, satellite image analysis and twitter data analysis followed by integration using location. The first stage involves pre and post disaster satellite image analysis of the location using multi-class land cover segmentation technique based on U-Net architecture. The second stage focuses on mapping the region with essential information about the disaster situation and immediate requirements for relief operations. The severely affected regions are demarcated and twitter data is extracted using keywords respective to that location. The extraction of situational information from a large corpus of raw tweets adopts Content Word based Tweet Summarization (COWTS) technique. An integration of these modules using real-time location-based mapping and frequency analysis technique gathers multi-dimensional information in the advent of disaster occurrence such as the Kerala and Mississippi floods that were analyzed and validated as test cases. The novelty of this research lies in the application of segmented satellite images for disaster relief using highlighted land cover changes and integration of twitter data by mapping these region-specific filters for obtaining a complete overview of the disaster.
Bridging Classical and Quantum Machine Learning: Knowledge Transfer From Classical to Quantum Neural Networks Using Knowledge Distillation
Nov 23, 2023Very recently, studies have shown that quantum neural networks surpass classical neural networks in tasks like image classification when a similar number of learnable parameters are used. However, the development and optimization of quantum models are currently hindered by issues such as qubit instability and limited qubit availability, leading to error-prone systems with weak performance. In contrast, classical models can exhibit high-performance owing to substantial resource availability. As a result, more studies have been focusing on hybrid classical-quantum integration. A line of research particularly focuses on transfer learning through classical-quantum integration or quantum-quantum approaches. Unlike previous studies, this paper introduces a new method to transfer knowledge from classical to quantum neural networks using knowledge distillation, effectively bridging the gap between classical machine learning and emergent quantum computing techniques. We adapt classical convolutional neural network (CNN) architectures like LeNet and AlexNet to serve as teacher networks, facilitating the training of student quantum models by sending supervisory signals during backpropagation through KL-divergence. The approach yields significant performance improvements for the quantum models by solely depending on classical CNNs, with quantum models achieving an average accuracy improvement of 0.80% on the MNIST dataset and 5.40% on the more complex Fashion MNIST dataset. Applying this technique eliminates the cumbersome training of huge quantum models for transfer learning in resource-constrained settings and enables re-using existing pre-trained classical models to improve performance.Thus, this study paves the way for future research in quantum machine learning (QML) by positioning knowledge distillation as a core technique for advancing QML applications.
MIFA: Metadata, Incentives, Formats, and Accessibility guidelines to improve the reuse of AI datasets for bioimage analysis
Nov 17, 2023Artificial Intelligence methods are powerful tools for biological image analysis and processing. High-quality annotated images are key to training and developing new methods, but access to such data is often hindered by the lack of standards for sharing datasets. We brought together community experts in a workshop to develop guidelines to improve the reuse of bioimages and annotations for AI applications. These include standards on data formats, metadata, data presentation and sharing, and incentives to generate new datasets. We are positive that the MIFA (Metadata, Incentives, Formats, and Accessibility) recommendations will accelerate the development of AI tools for bioimage analysis by facilitating access to high quality training data.
EviPrompt: A Training-Free Evidential Prompt Generation Method for Segment Anything Model in Medical Images
Nov 10, 2023Medical image segmentation has immense clinical applicability but remains a challenge despite advancements in deep learning. The Segment Anything Model (SAM) exhibits potential in this field, yet the requirement for expertise intervention and the domain gap between natural and medical images poses significant obstacles. This paper introduces a novel training-free evidential prompt generation method named EviPrompt to overcome these issues. The proposed method, built on the inherent similarities within medical images, requires only a single reference image-annotation pair, making it a training-free solution that significantly reduces the need for extensive labeling and computational resources. First, to automatically generate prompts for SAM in medical images, we introduce an evidential method based on uncertainty estimation without the interaction of clinical experts. Then, we incorporate the human prior into the prompts, which is vital for alleviating the domain gap between natural and medical images and enhancing the applicability and usefulness of SAM in medical scenarios. EviPrompt represents an efficient and robust approach to medical image segmentation, with evaluations across a broad range of tasks and modalities confirming its efficacy.
HEALNet -- Hybrid Multi-Modal Fusion for Heterogeneous Biomedical Data
Nov 20, 2023Technological advances in medical data collection such as high-resolution histopathology and high-throughput genomic sequencing have contributed to the rising requirement for multi-modal biomedical modelling, specifically for image, tabular, and graph data. Most multi-modal deep learning approaches use modality-specific architectures that are trained separately and cannot capture the crucial cross-modal information that motivates the integration of different data sources. This paper presents the Hybrid Early-fusion Attention Learning Network (HEALNet): a flexible multi-modal fusion architecture, which a) preserves modality-specific structural information, b) captures the cross-modal interactions and structural information in a shared latent space, c) can effectively handle missing modalities during training and inference, and d) enables intuitive model inspection by learning on the raw data input instead of opaque embeddings. We conduct multi-modal survival analysis on Whole Slide Images and Multi-omic data on four cancer cohorts of The Cancer Genome Atlas (TCGA). HEALNet achieves state-of-the-art performance, substantially improving over both uni-modal and recent multi-modal baselines, whilst being robust in scenarios with missing modalities.
USLR: an open-source tool for unbiased and smooth longitudinal registration of brain MR
Nov 14, 2023We present USLR, a computational framework for longitudinal registration of brain MRI scans to estimate nonlinear image trajectories that are smooth across time, unbiased to any timepoint, and robust to imaging artefacts. It operates on the Lie algebra parameterisation of spatial transforms (which is compatible with rigid transforms and stationary velocity fields for nonlinear deformation) and takes advantage of log-domain properties to solve the problem using Bayesian inference. USRL estimates rigid and nonlinear registrations that: (i) bring all timepoints to an unbiased subject-specific space; and (i) compute a smooth trajectory across the imaging time-series. We capitalise on learning-based registration algorithms and closed-form expressions for fast inference. A use-case Alzheimer's disease study is used to showcase the benefits of the pipeline in multiple fronts, such as time-consistent image segmentation to reduce intra-subject variability, subject-specific prediction or population analysis using tensor-based morphometry. We demonstrate that such approach improves upon cross-sectional methods in identifying group differences, which can be helpful in detecting more subtle atrophy levels or in reducing sample sizes in clinical trials. The code is publicly available in https://github.com/acasamitjana/uslr
Diffusion-based generation of Histopathological Whole Slide Images at a Gigapixel scale
Nov 14, 2023We present a novel diffusion-based approach to generate synthetic histopathological Whole Slide Images (WSIs) at an unprecedented gigapixel scale. Synthetic WSIs have many potential applications: They can augment training datasets to enhance the performance of many computational pathology applications. They allow the creation of synthesized copies of datasets that can be shared without violating privacy regulations. Or they can facilitate learning representations of WSIs without requiring data annotations. Despite this variety of applications, no existing deep-learning-based method generates WSIs at their typically high resolutions. Mainly due to the high computational complexity. Therefore, we propose a novel coarse-to-fine sampling scheme to tackle image generation of high-resolution WSIs. In this scheme, we increase the resolution of an initial low-resolution image to a high-resolution WSI. Particularly, a diffusion model sequentially adds fine details to images and increases their resolution. In our experiments, we train our method with WSIs from the TCGA-BRCA dataset. Additionally to quantitative evaluations, we also performed a user study with pathologists. The study results suggest that our generated WSIs resemble the structure of real WSIs.
Volcano: Mitigating Multimodal Hallucination through Self-Feedback Guided Revision
Nov 14, 2023Large multimodal models (LMMs) suffer from multimodal hallucination, where they provide incorrect responses misaligned with the given visual information. Recent works have conjectured that one of the reasons behind multimodal hallucination might be due to the vision encoder failing to ground on the image properly. To mitigate this issue, we propose a novel approach that leverages self-feedback as visual cues. Building on this approach, we introduce Volcano, a multimodal self-feedback guided revision model. Volcano generates natural language feedback to its initial response based on the provided visual information and utilizes this feedback to self-revise its initial response. Volcano effectively reduces multimodal hallucination and achieves state-of-the-art on MMHal-Bench, POPE, and GAVIE. It also improves on general multimodal abilities and outperforms previous models on MM-Vet and MMBench. Through a qualitative analysis, we show that Volcano's feedback is properly grounded on the image than the initial response. This indicates that Volcano can provide itself with richer visual information, helping alleviate multimodal hallucination. We publicly release Volcano models of 7B and 13B sizes along with the data and code at https://github.com/kaistAI/Volcano.