 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Fragment Embeddings for Bidirectional Image Sentence Mapping
Jun 22, 2014
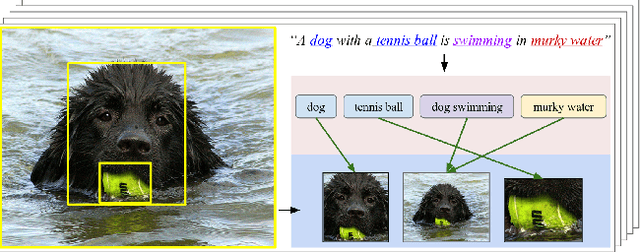
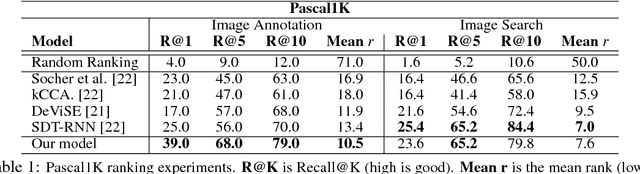
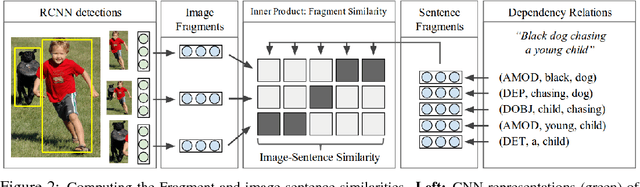
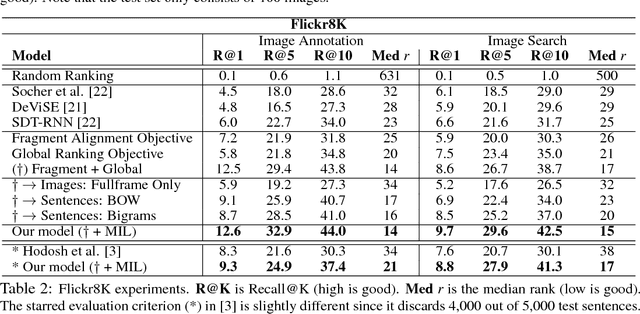
We introduce a model for bidirectional retrieval of images and sentences through a multi-modal embedding of visual and natural language data. Unlike previous models that directly map images or sentences into a common embedding space, our model works on a finer level and embeds fragments of images (objects) and fragments of sentences (typed dependency tree relations) into a common space. In addition to a ranking objective seen in previous work, this allows us to add a new fragment alignment objective that learns to directly associate these fragments across modalities. Extensive experimental evaluation shows that reasoning on both the global level of images and sentences and the finer level of their respective fragments significantly improves performance on image-sentence retrieval tasks. Additionally, our model provides interpretable predictions since the inferred inter-modal fragment alignment is explicit.
Sparse Representation Classification via Screening for Graphs
Jun 04, 2019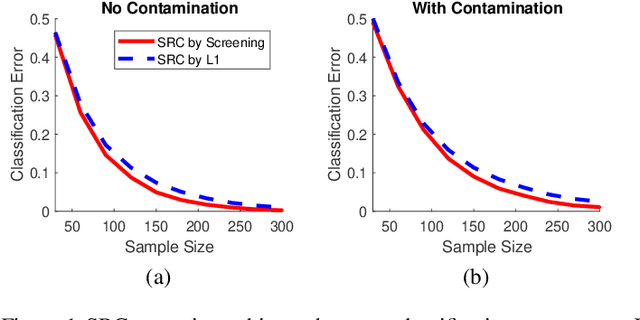
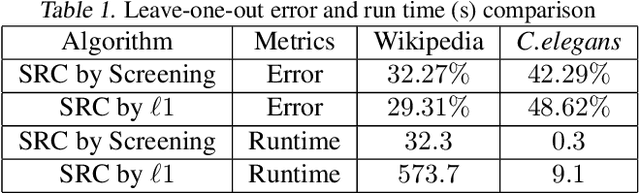
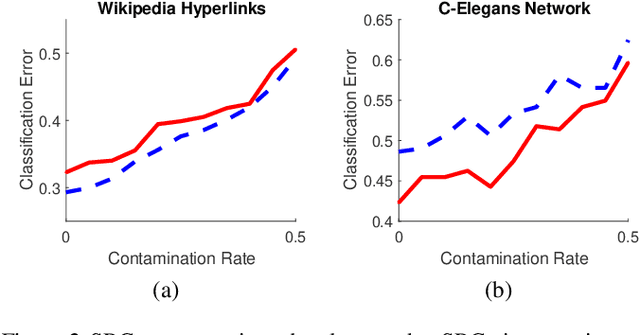
The sparse representation classifier (SRC) is shown to work well for image recognition problems that satisfy a subspace assumption. In this paper we propose a new implementation of SRC via screening, establish its equivalence to the original SRC under regularity conditions, and prove its classification consistency for random graphs drawn from stochastic blockmodels. The results are demonstrated via simulations and real data experiments, where the new algorithm achieves comparable numerical performance but significantly faster.
A Mask-RCNN Baseline for Probabilistic Object Detection
Aug 09, 2019


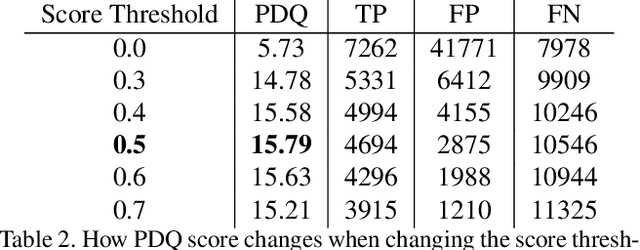
The Probabilistic Object Detection Challenge evaluates object detection methods using a new evaluation measure, Probability-based Detection Quality (PDQ), on a new synthetic image dataset. We present our submission to the challenge, a fine-tuned version of Mask-RCNN with some additional post-processing. Our method, submitted under username pammirato, is currently second on the leaderboard with a score of 21.432, while also achieving the highest spatial quality and average overall quality of detections. We hope this method can provide some insight into how detectors designed for mean average precision (mAP) evaluation behave under PDQ, as well as a strong baseline for future work.
Deep Q learning for fooling neural networks
Nov 13, 2018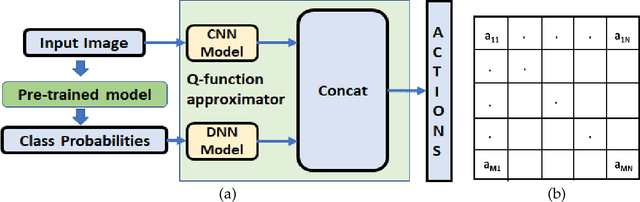

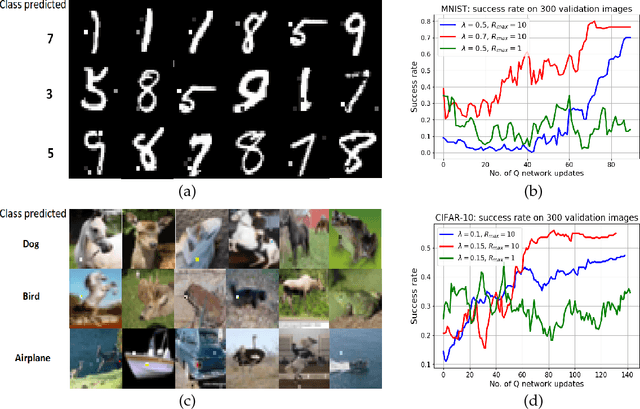
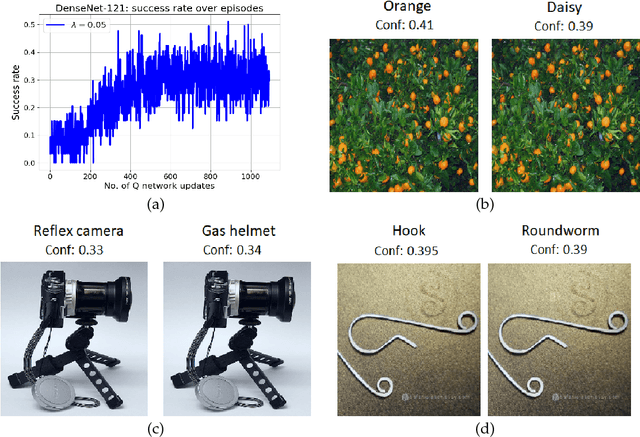
Deep learning models are vulnerable to external attacks. In this paper, we propose a Reinforcement Learning (RL) based approach to generate adversarial examples for the pre-trained (target) models. We assume a semi black-box setting where the only access an adversary has to the target model is the class probabilities obtained for the input queries. We train a Deep Q Network (DQN) agent which, with experience, learns to attack only a small portion of image pixels to generate non-targeted adversarial images. Initially, an agent explores an environment by sequentially modifying random sets of image pixels and observes its effect on the class probabilities. At the end of an episode, it receives a positive (negative) reward if it succeeds (fails) to alter the label of the image. Experimental results with MNIST, CIFAR-10 and Imagenet datasets demonstrate that our RL framework is able to learn an effective attack policy.
Fast image segmentation and restoration using parametric curve evolution with junctions and topology changes
Aug 10, 2013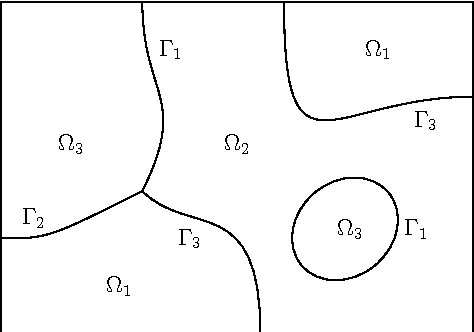
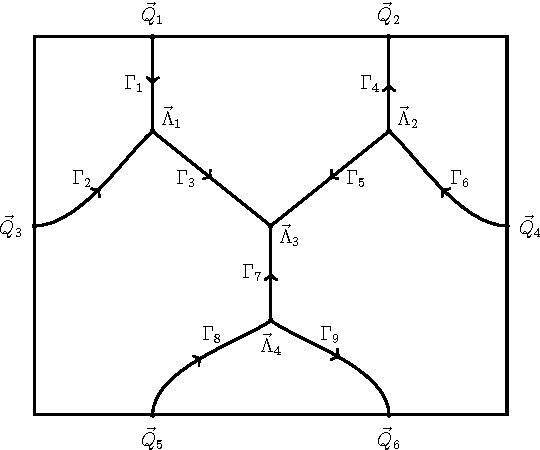
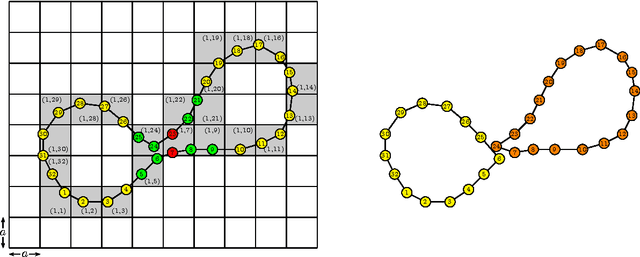
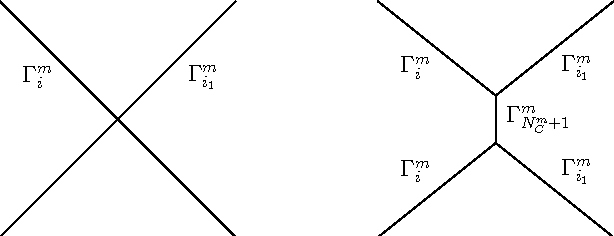
Curve evolution schemes for image segmentation based on a region based contour model allowing for junctions, vector-valued images and topology changes are introduced. Together with an a posteriori denoising in the segmented homogeneous regions this leads to a fast and efficient method for image segmentation and restoration. An uneven spread of mesh points is avoided by using the tangential degrees of freedom. Several numerical simulations on artificial test problems and on real images illustrate the performance of the method.
STEFANN: Scene Text Editor using Font Adaptive Neural Network
Mar 04, 2019
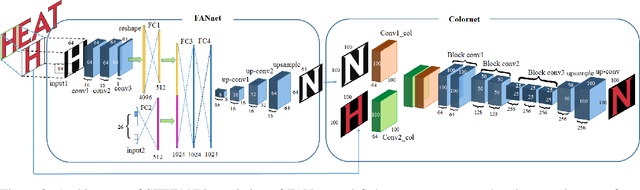


Textual information in a captured scene play important role in scene interpretation and decision making. Pieces of dedicated research work are going on to detect and recognize textual data accurately in images. Though there exist methods that can successfully detect complex text regions present in a scene, to the best of our knowledge there is no work to modify the textual information in an image. This paper deals with a simple text editor that can edit/modify the textual part in an image. Apart from error correction in the text part of the image, this work can directly increase the reusability of images drastically. In this work, at first, we focus on the problem to generate unobserved characters with the similar font and color of an observed text character present in a natural scene with minimum user intervention. To generate the characters, we propose a multi-input neural network that adapts the font-characteristics of a given characters (source), and generate desired characters (target) with similar font features. We also propose a network that transfers color from source to target character without any visible distortion. Next, we place the generated character in a word for its modification maintaining the visual consistency with the other characters in the word. The proposed method is a unified platform that can work like a simple text editor and edit texts in images. We tested our methodology on popular ICDAR 2011 and ICDAR 2013 datasets and results are reported here.
Nested Network with Two-Stream Pyramid for Salient Object Detection in Optical Remote Sensing Images
Jun 20, 2019
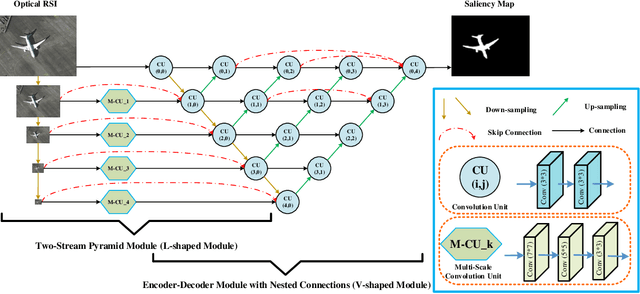


Arising from the various object types and scales, diverse imaging orientations, and cluttered backgrounds in optical remote sensing image (RSI), it is difficult to directly extend the success of salient object detection for nature scene image to the optical RSI. In this paper, we propose an end-to-end deep network called LV-Net based on the shape of network architecture, which detects salient objects from optical RSIs in a purely data-driven fashion. The proposed LV-Net consists of two key modules, i.e., a two-stream pyramid module (L-shaped module) and an encoder-decoder module with nested connections (V-shaped module). Specifically, the L-shaped module extracts a set of complementary information hierarchically by using a two-stream pyramid structure, which is beneficial to perceiving the diverse scales and local details of salient objects. The V-shaped module gradually integrates encoder detail features with decoder semantic features through nested connections, which aims at suppressing the cluttered backgrounds and highlighting the salient objects. In addition, we construct the first publicly available optical RSI dataset for salient object detection, including 800 images with varying spatial resolutions, diverse saliency types, and pixel-wise ground truth. Experiments on this benchmark dataset demonstrate that the proposed method outperforms the state-of-the-art salient object detection methods both qualitatively and quantitatively.
Modeling Realistic Degradations in Non-blind Deconvolution
Jun 04, 2018

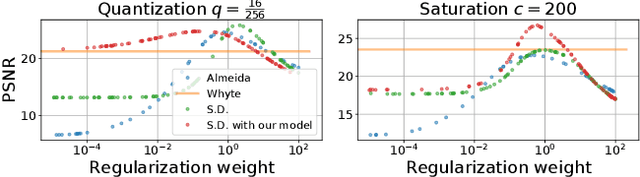

Most image deblurring methods assume an over-simplistic image formation model and as a result are sensitive to more realistic image degradations. We propose a novel variational framework, that explicitly handles pixel saturation, noise, quantization, as well as non-linear camera response function due to e.g., gamma correction. We show that accurately modeling a more realistic image acquisition pipeline leads to significant improvements, both in terms of image quality and PSNR. Furthermore, we show that incorporating the non-linear response in both the data and the regularization terms of the proposed energy leads to a more detailed restoration than a naive inversion of the non-linear curve. The minimization of the proposed energy is performed using stochastic optimization. A dataset consisting of realistically degraded images is created in order to evaluate the method.
Programmable Spectrometry -- Per-pixel Classification of Materials using Learned Spectral Filters
May 13, 2019

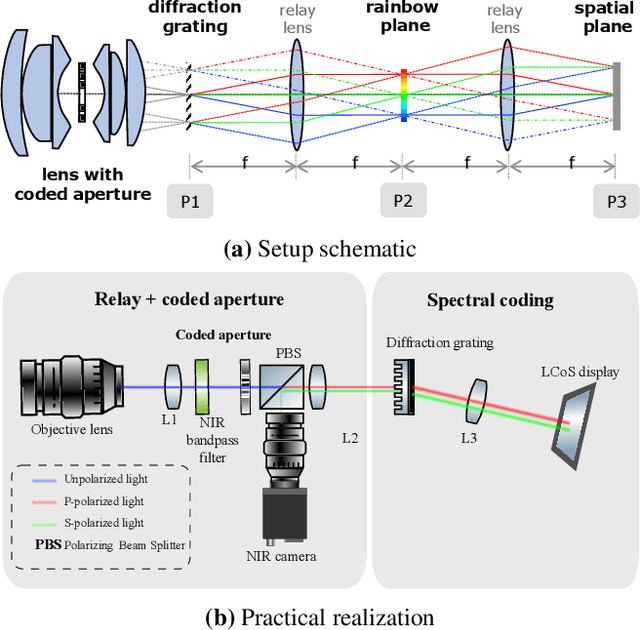

Many materials have distinct spectral profiles. This facilitates estimation of the material composition of a scene at each pixel by first acquiring its hyperspectral image, and subsequently filtering it using a bank of spectral profiles. This process is inherently wasteful since only a set of linear projections of the acquired measurements contribute to the classification task. We propose a novel programmable camera that is capable of producing images of a scene with an arbitrary spectral filter. We use this camera to optically implement the spectral filtering of the scene's hyperspectral image with the bank of spectral profiles needed to perform per-pixel material classification. This provides gains both in terms of acquisition speed --- since only the relevant measurements are acquired --- and in signal-to-noise ratio --- since we invariably avoid narrowband filters that are light inefficient. Given training data, we use a range of classical and modern techniques including SVMs and neural networks to identify the bank of spectral profiles that facilitate material classification. We verify the method in simulations on standard datasets as well as real data using a lab prototype of the camera.
Building Task-Oriented Visual Dialog Systems Through Alternative Optimization Between Dialog Policy and Language Generation
Sep 06, 2019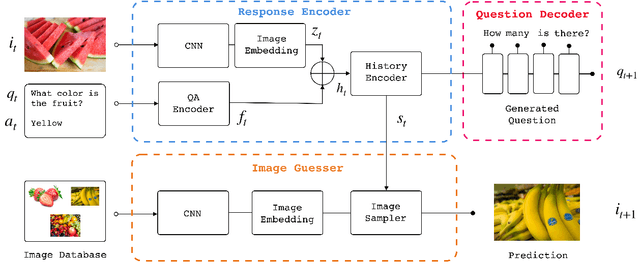

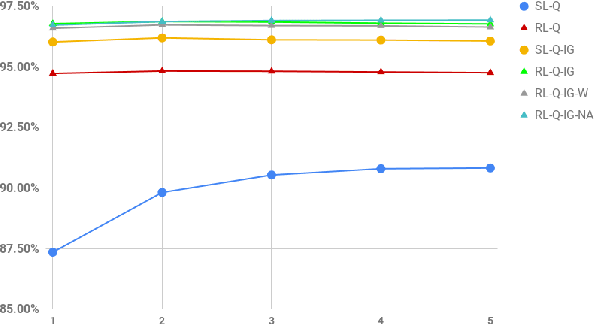
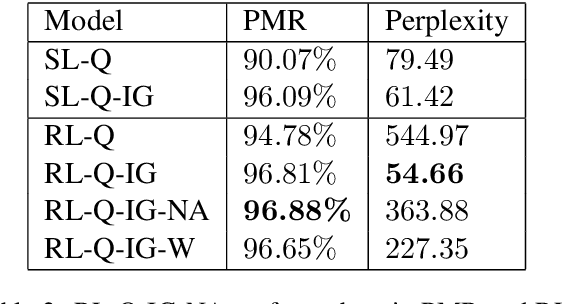
Reinforcement learning (RL) is an effective approach to learn an optimal dialog policy for task-oriented visual dialog systems. A common practice is to apply RL on a neural sequence-to-sequence (seq2seq) framework with the action space being the output vocabulary in the decoder. However, it is difficult to design a reward function that can achieve a balance between learning an effective policy and generating a natural dialog response. This paper proposes a novel framework that alternatively trains a RL policy for image guessing and a supervised seq2seq model to improve dialog generation quality. We evaluate our framework on the GuessWhich task and the framework achieves the state-of-the-art performance in both task completion and dialog quality.