 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Synthesize Motion Blur
Nov 27, 2018

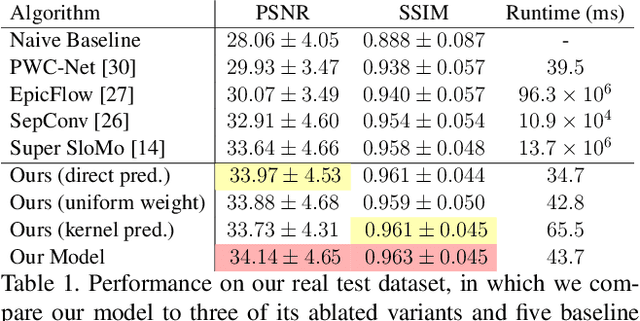


We present a technique for synthesizing a motion blurred image from a pair of unblurred images captured in succession. To build this system we motivate and design a differentiable "line prediction" layer to be used as part of a neural network architecture, with which we can learn a system to regress from image pairs to motion blurred images that span the capture time of the input image pair. Training this model requires an abundance of data, and so we design and execute a strategy for using frame interpolation techniques to generate a large-scale synthetic dataset of motion blurred images and their respective inputs. We additionally capture a high quality test set of real motion blurred images, synthesized from slow motion videos, with which we evaluate our model against several baseline techniques that can be used to synthesize motion blur. Our model produces higher accuracy output than our baselines, and is several orders of magnitude faster than those baselines with competitive accuracy.
Learning to Segment Brain Anatomy from 2D Ultrasound with Less Data
Dec 18, 2019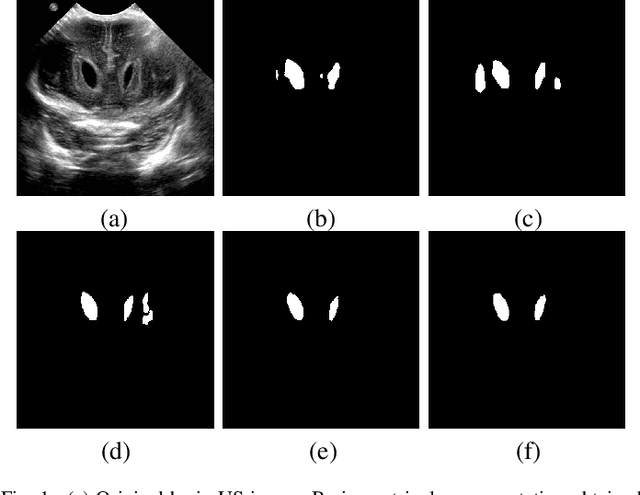
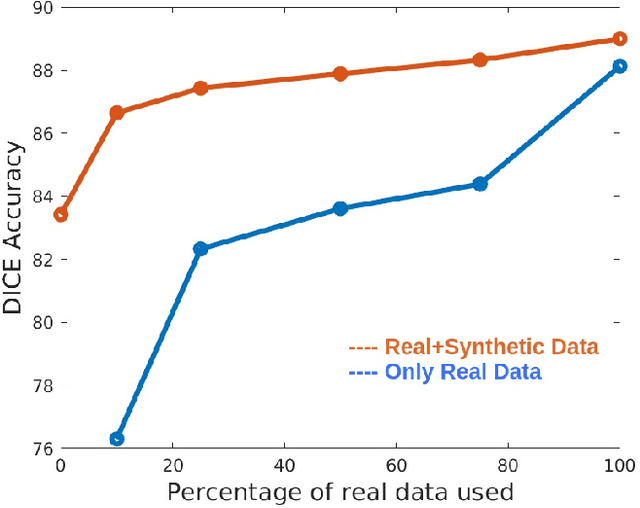
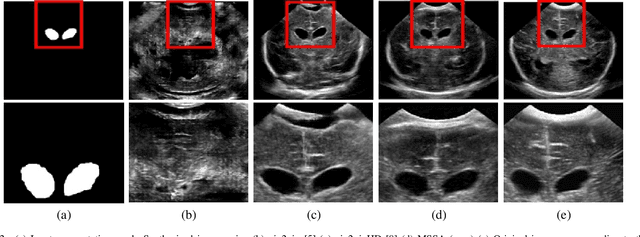
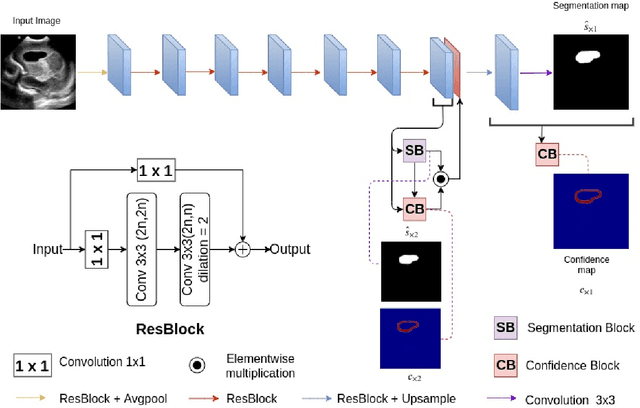
Automatic segmentation of anatomical landmarks from ultrasound (US) plays an important role in the management of preterm neonates with a very low birth weight due to the increased risk of developing intraventricular hemorrhage (IVH) or other complications. One major problem in developing an automatic segmentation method for this task is the limited availability of annotated data. To tackle this issue, we propose a novel image synthesis method using multi-scale self attention generator to synthesize US images from various segmentation masks. We show that our method can synthesize high-quality US images for every manipulated segmentation label with qualitative and quantitative improvements over the recent state-of-the-art synthesis methods. Furthermore, for the segmentation task, we propose a novel method, called Confidence-guided Brain Anatomy Segmentation (CBAS) network, where segmentation and corresponding confidence maps are estimated at different scales. In addition, we introduce a technique which guides CBAS to learn the weights based on the confidence measure about the estimate. Extensive experiments demonstrate that the proposed method for both synthesis and segmentation tasks achieve significant improvements over the recent state-of-the-art methods. In particular, we show that the new synthesis framework can be used to generate realistic US images which can be used to improve the performance of a segmentation algorithm.
Lesion Focused Super-Resolution
Oct 15, 2018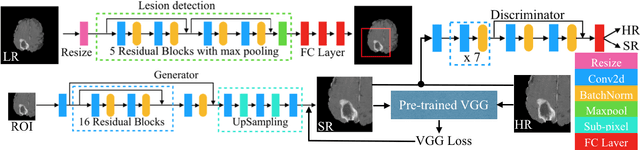
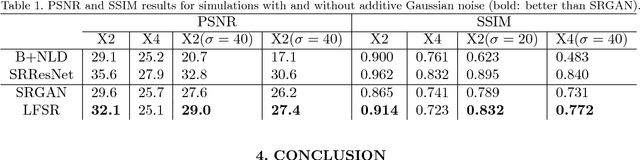
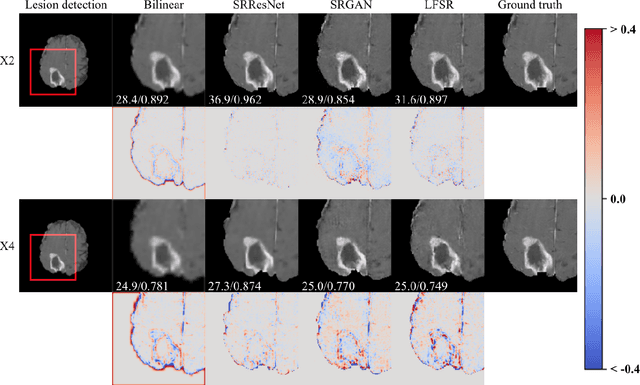
Super-resolution (SR) for image enhancement has great importance in medical image applications. Broadly speaking, there are two types of SR, one requires multiple low resolution (LR) images from different views of the same object to be reconstructed to the high resolution (HR) output, and the other one relies on the learning from a large amount of training datasets, i.e., LR-HR pairs. In real clinical environment, acquiring images from multi-views is expensive and sometimes infeasible. In this paper, we present a novel Generative Adversarial Networks (GAN) based learning framework to achieve SR from its LR version. By performing simulation based studies on the Multimodal Brain Tumor Segmentation Challenge (BraTS) datasets, we demonstrate the efficacy of our method in application of brain tumor MRI enhancement. Compared to bilinear interpolation and other state-of-the-art SR methods, our model is lesion focused, which is not only resulted in better perceptual image quality without blurring, but also more efficient and directly benefit for the following clinical tasks, e.g., lesion detection and abnormality enhancement. Therefore, we can envisage the application of our SR method to boost image spatial resolution while maintaining crucial diagnostic information for further clinical tasks.
Data-Driven Microstructure Property Relations
Apr 01, 2019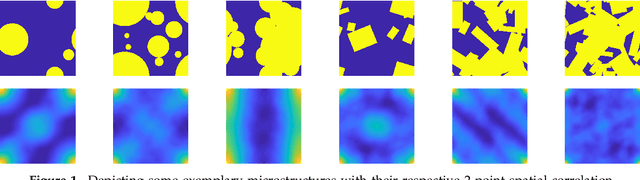
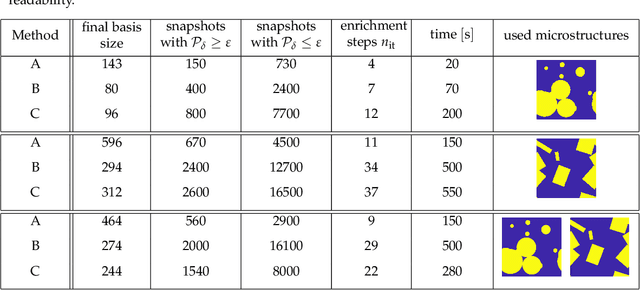
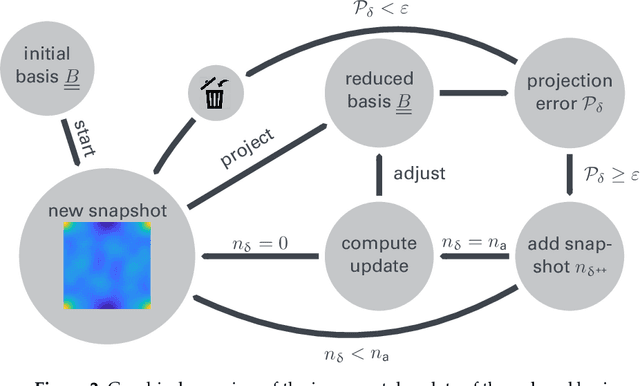
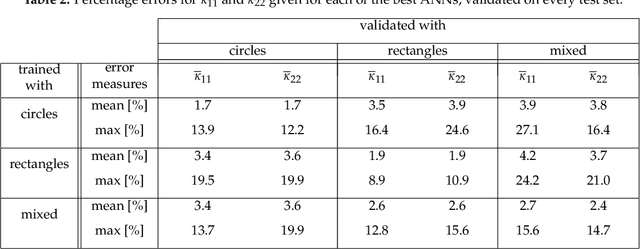
An image based prediction of the effective heat conductivity for highly heterogeneous microstructured materials is presented. The synthetic materials under consideration show different inclusion morphology, orientation, volume fraction and topology. The prediction of the effective property is made exclusively based on image data with the main emphasis being put on the 2-point spatial correlation function. This task is implemented using both unsupervised and supervised machine learning methods. First, a snapshot proper orthogonal decomposition (POD) is used to analyze big sets of random microstructures and thereafter compress significant characteristics of the microstructure into a low-dimensional feature vector. In order to manage the related amount of data and computations, three different incremental snapshot POD methods are proposed. In the second step, the obtained feature vector is used to predict the effective material property by using feed forward neural networks. Numerical examples regarding the incremental basis identification and the prediction accuracy of the approach are presented. A Python code illustrating the application of the surrogate is freely available.
Reversible Image Authentication with Tamper Localization Based on Integer Wavelet Transform
Dec 03, 2009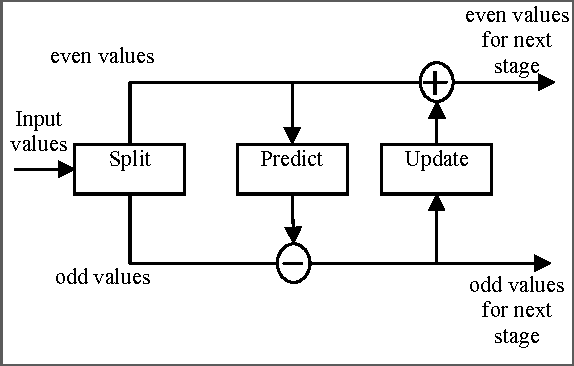
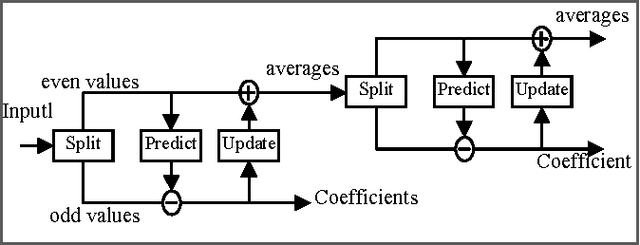
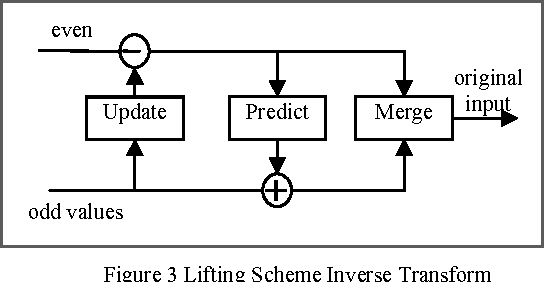
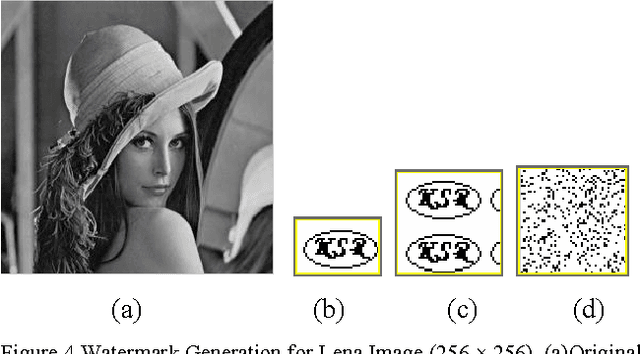
In this paper, a new reversible image authentication technique with tamper localization based on watermarking in integer wavelet transform is proposed. If the image authenticity is verified, then the distortion due to embedding the watermark can be completely removed from the watermarked image. If the image is tampered, then the tampering positions can also be localized. Two layers of watermarking are used. The first layer embedded in spatial domain verifies authenticity and the second layer embedded in transform domain provides reversibility. This technique utilizes selective LSB embedding and histogram characteristics of the difference images of the wavelet coefficients and modifies pixel values slightly to embed the watermark. Experimental results demonstrate that the proposed scheme can detect any modifications of the watermarked image.
* 8 pages IEEE format, International Journal of Computer Science and Information Security, IJCSIS November 2009, ISSN 1947 5500, http://sites.google.com/site/ijcsis/
Visual Analytics of Image-Centric Cohort Studies in Epidemiology
Jan 15, 2015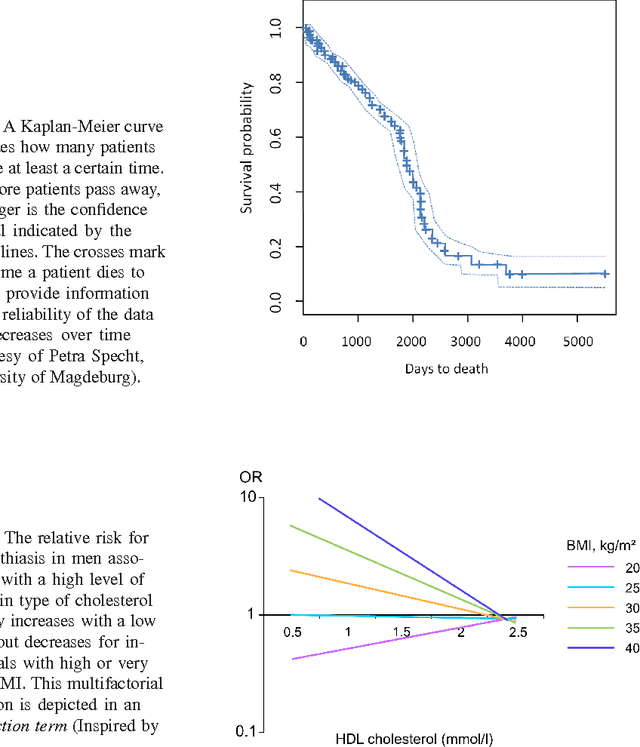


Epidemiology characterizes the influence of causes to disease and health conditions of defined populations. Cohort studies are population-based studies involving usually large numbers of randomly selected individuals and comprising numerous attributes, ranging from self-reported interview data to results from various medical examinations, e.g., blood and urine samples. Since recently, medical imaging has been used as an additional instrument to assess risk factors and potential prognostic information. In this chapter, we discuss such studies and how the evaluation may benefit from visual analytics. Cluster analysis to define groups, reliable image analysis of organs in medical imaging data and shape space exploration to characterize anatomical shapes are among the visual analytics tools that may enable epidemiologists to fully exploit the potential of their huge and complex data. To gain acceptance, visual analytics tools need to complement more classical epidemiologic tools, primarily hypothesis-driven statistical analysis.
Quantile Representation for Indirect Immunofluorescence Image Classification
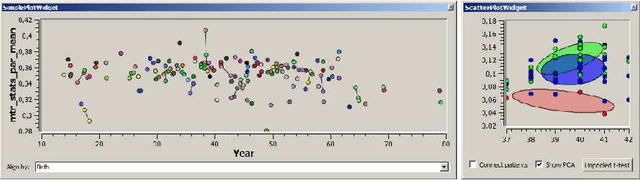
Feb 06, 2014
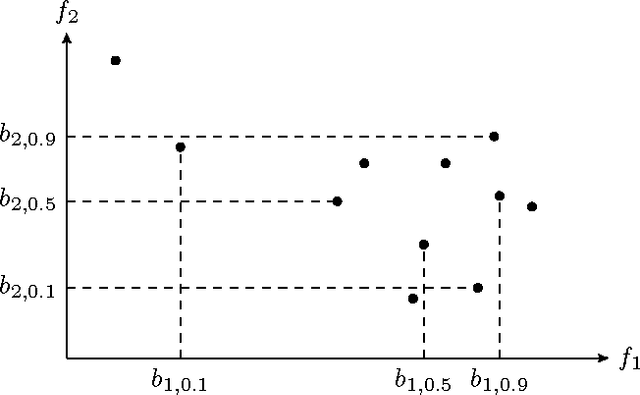
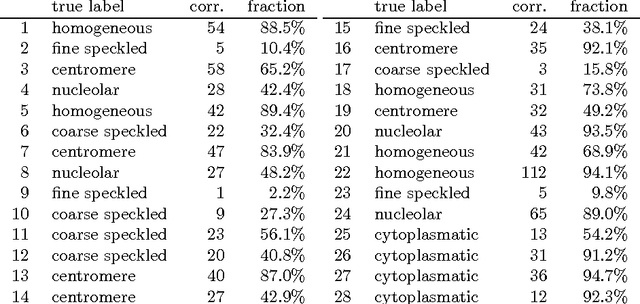
In the diagnosis of autoimmune diseases, an important task is to classify images of slides containing several HEp-2 cells. All cells from one slide share the same label, and by classifying cells from one slide independently, some information on the global image quality and intensity is lost. Considering one whole slide as a collection (a bag) of feature vectors, however, poses the problem of how to handle this bag. A simple, and surprisingly effective, approach is to summarize the bag of feature vectors by a few quantile values per feature. This characterizes the full distribution of all instances, thereby assuming that all instances in a bag are informative. This representation is particularly useful when each bag contains many feature vectors, which is the case in the classification of the immunofluorescence images. Experiments on the classification of indirect immunofluorescence images show the usefulness of this approach.
Deep Learning for Power System Security Assessment
Mar 31, 2019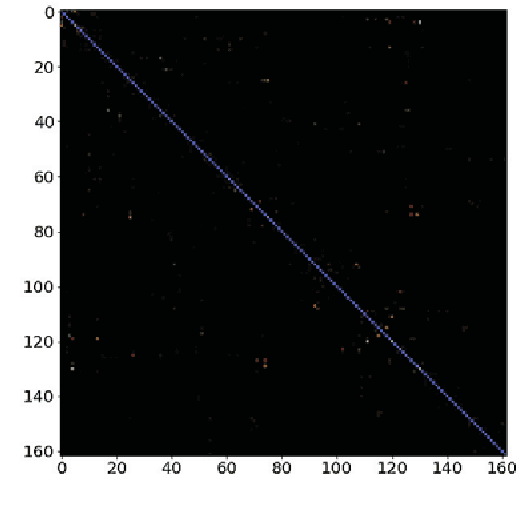
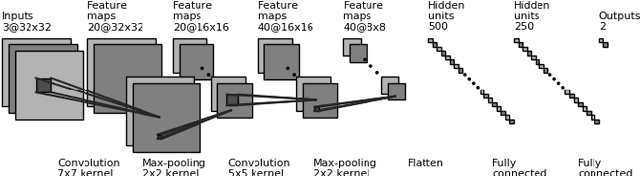
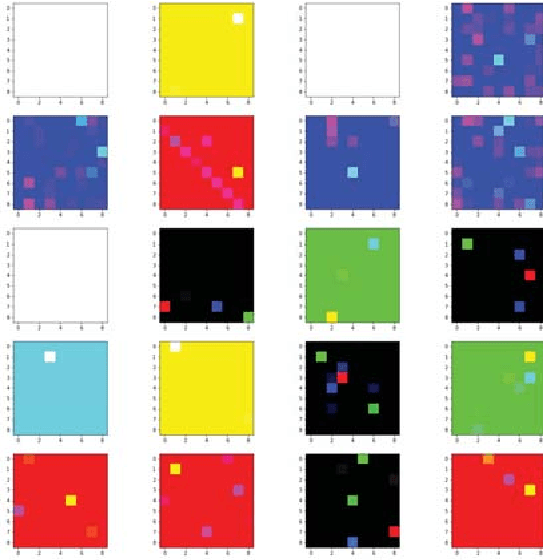
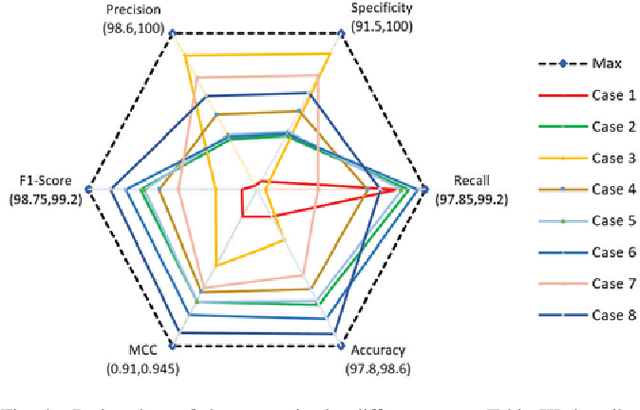
Security assessment is among the most fundamental functions of power system operator. The sheer complexity of power systems exceeding a few buses, however, makes it an extremely computationally demanding task. The emergence of deep learning methods that are able to handle immense amounts of data, and infer valuable information appears as a promising alternative. This paper has two main contributions. First, inspired by the remarkable performance of convolutional neural networks for image processing, we represent for the first time power system snapshots as 2-dimensional images, thus taking advantage of the wide range of deep learning methods available for image processing. Second, we train deep neural networks on a large database for the NESTA 162-bus system to assess both N-1 security and small-signal stability. We find that our approach is over 255 times faster than a standard small-signal stability assessment, and it can correctly determine unsafe points with over 99% accuracy.
Causality matters in medical imaging
Dec 17, 2019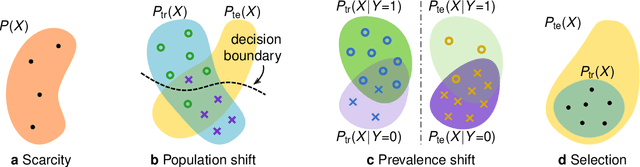

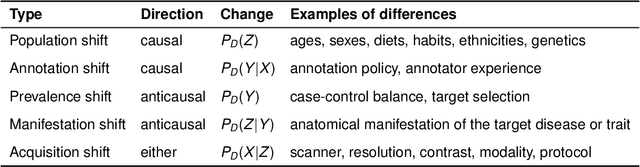
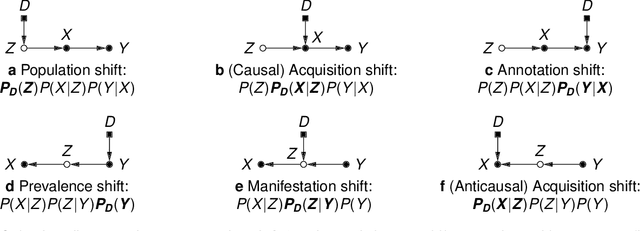
This article discusses how the language of causality can shed new light on the major challenges in machine learning for medical imaging: 1) data scarcity, which is the limited availability of high-quality annotations, and 2) data mismatch, whereby a trained algorithm may fail to generalize in clinical practice. Looking at these challenges through the lens of causality allows decisions about data collection, annotation procedures, and learning strategies to be made (and scrutinized) more transparently. We discuss how causal relationships between images and annotations can not only have profound effects on the performance of predictive models, but may even dictate which learning strategies should be considered in the first place. For example, we conclude that semi-supervision may be unsuitable for image segmentation---one of the possibly surprising insights from our causal analysis, which is illustrated with representative real-world examples of computer-aided diagnosis (skin lesion classification in dermatology) and radiotherapy (automated contouring of tumours). We highlight that being aware of and accounting for the causal relationships in medical imaging data is important for the safe development of machine learning and essential for regulation and responsible reporting. To facilitate this we provide step-by-step recommendations for future studies.
A Comprehensive guide to Bayesian Convolutional Neural Network with Variational Inference
Jan 08, 2019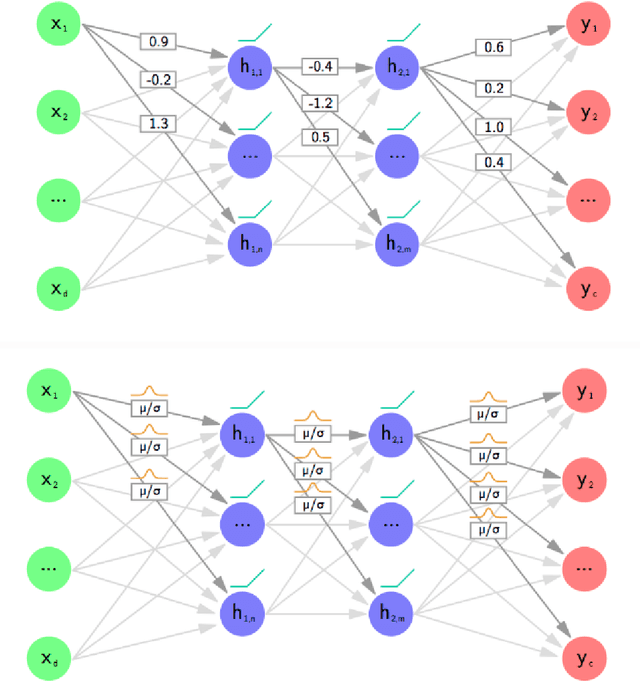
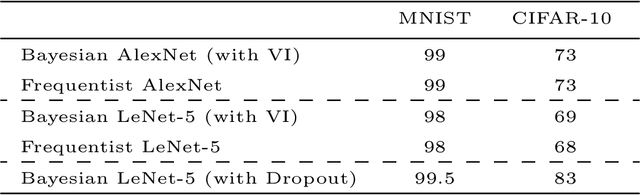
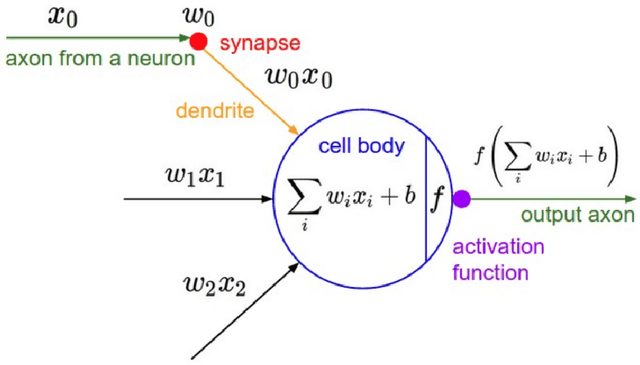

Artificial Neural Networks are connectionist systems that perform a given task by learning on examples without having prior knowledge about the task. This is done by finding an optimal point estimate for the weights in every node. Generally, the network using point estimates as weights perform well with large datasets, but they fail to express uncertainty in regions with little or no data, leading to overconfident decisions. In this paper, Bayesian Convolutional Neural Network (BayesCNN) using Variational Inference is proposed, that introduces probability distribution over the weights. Furthermore, the proposed BayesCNN architecture is applied to tasks like Image Classification, Image Super-Resolution and Generative Adversarial Networks. The results are compared to point-estimates based architectures on MNIST, CIFAR-10 and CIFAR-100 datasets for Image CLassification task, on BSD300 dataset for Image Super Resolution task and on CIFAR10 dataset again for Generative Adversarial Network task. BayesCNN is based on Bayes by Backprop which derives a variational approximation to the true posterior. We, therefore, introduce the idea of applying two convolutional operations, one for the mean and one for the variance. Our proposed method not only achieves performances equivalent to frequentist inference in identical architectures but also incorporate a measurement for uncertainties and regularisation. It further eliminates the use of dropout in the model. Moreover, we predict how certain the model prediction is based on the epistemic and aleatoric uncertainties and empirically show how the uncertainty can decrease, allowing the decisions made by the network to become more deterministic as the training accuracy increases. Finally, we propose ways to prune the Bayesian architecture and to make it more computational and time effective.